Data? – Ja, z.B. ein googol* Datensätze pro Tag • Muss es Hadoop sein? – Ja, da die Antwortzeit skalieren muss • Handelt es sich um Echtzeitdaten? – Nein, es werden Deltas zum Vortag impor%ert • Ist die Datenquelle ein RDBMS? – Ja, ein SQL Server wird angebunden *hUp://en.wikipedia.org/wiki/Googol
große Zahl 1 mit 100 Nullen • Erfunden 1938 vom 9 jährigen Milton SiroUa – Neffe des Mathema%kers Edward Kasner – Kasner benö%gte einen Ausdruck für eine sehr große Zahl. – Der Ausdruck wurde 1940 im Buch Mathema'cs and the Imagina'on verwendet
• Hive ist SELECT * FROM Hadoop • Entwickelt von Facebook, jetzt Apache • Ein SQL-‐basierte Abfragesprache (HiveQL) • Erweiterung durch map/reduce Code in Java möglich • Hat mit HCatalog und WebHCat einen Datenstore in Tabellenform • Daher auch als „Datawarehouse von Hadoop“ bekannt.
• Import der Daten in eine Hive-‐Tabelle • Abfragen/Aggrega%on der Daten durch Hive • Export in ein CSV Format • Import der CSV in das RDBMS • Vorteil: einfacher Vorgang • Nachteil: dateibasierter Austausch der Daten
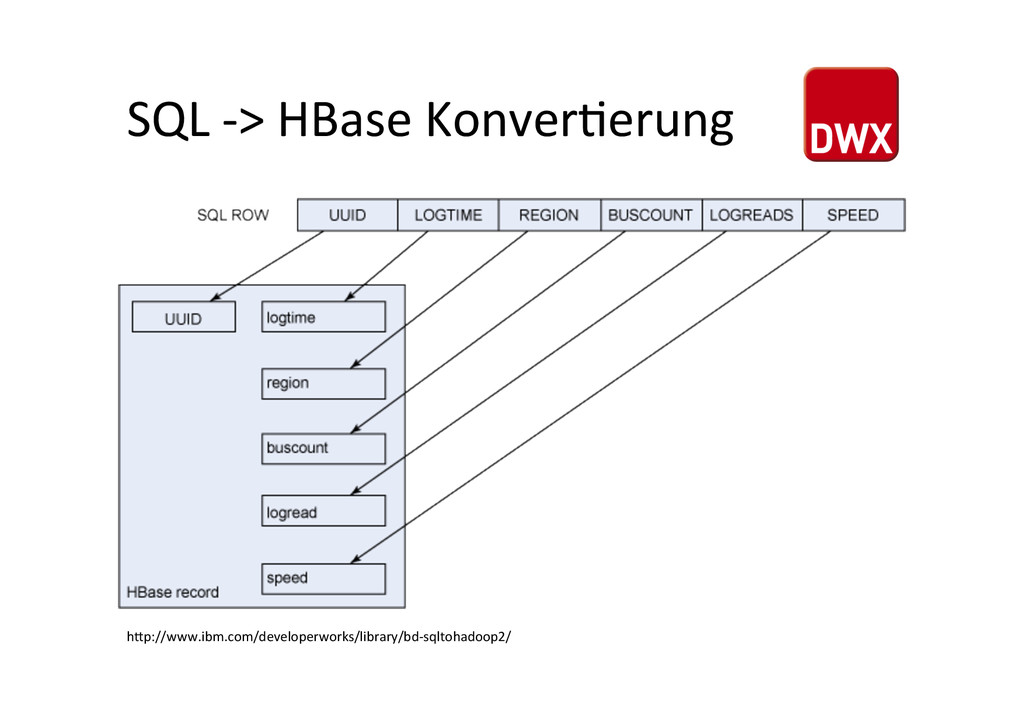
Datei mit den Daten – mysql> select * into outfile 'chicago.csv' fields terminated by ',' lines terminated by '\n' from chicago; • Erstellen der Tabelle in Hive – hive> create table chicago_bus (timelog timestamp, region int, buscount int, logreads int, speed float) row format delimited fields terminated by ',' lines terminated by "\n";
Boolean • Float/Double • String – CHAR, VARCHAR, SET, ENUM, TEXT, and BLOB • Timestamp – EPOCH oder YYYY-‐MM-‐DD hh:mm:ss.fffffffff • Binary -‐ für BLOBs die kein TEXT sind *hUps://cwiki.apache.org/confluence/display/Hive/LanguageManual+Types
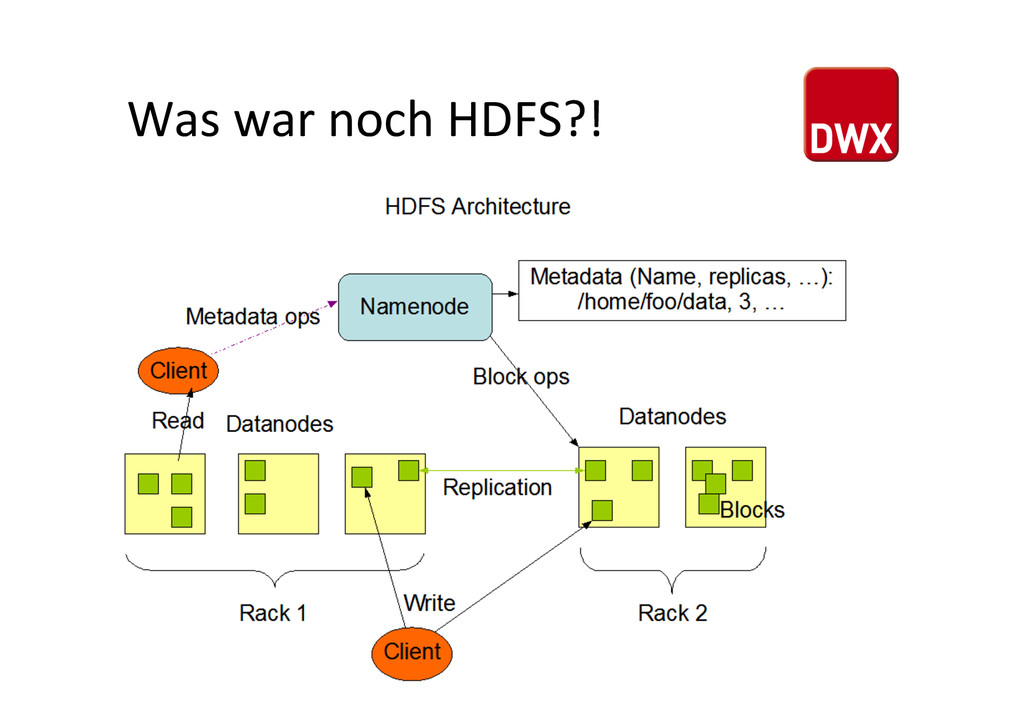
Datenbank • offene Implemen%erung von Google Bigtable • nutzbar für Billionen von Zeilen mit Millionen von Spalten • Betrieb im Cluster auf commodity Hardware • Abstrak%on des HDFS auf Bigtable
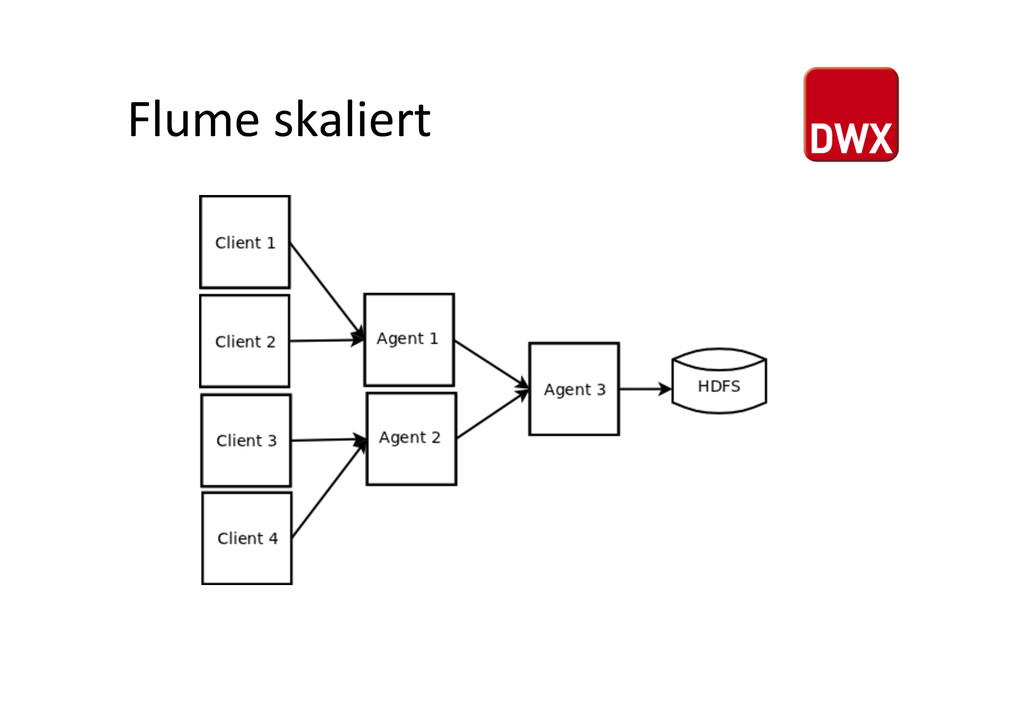
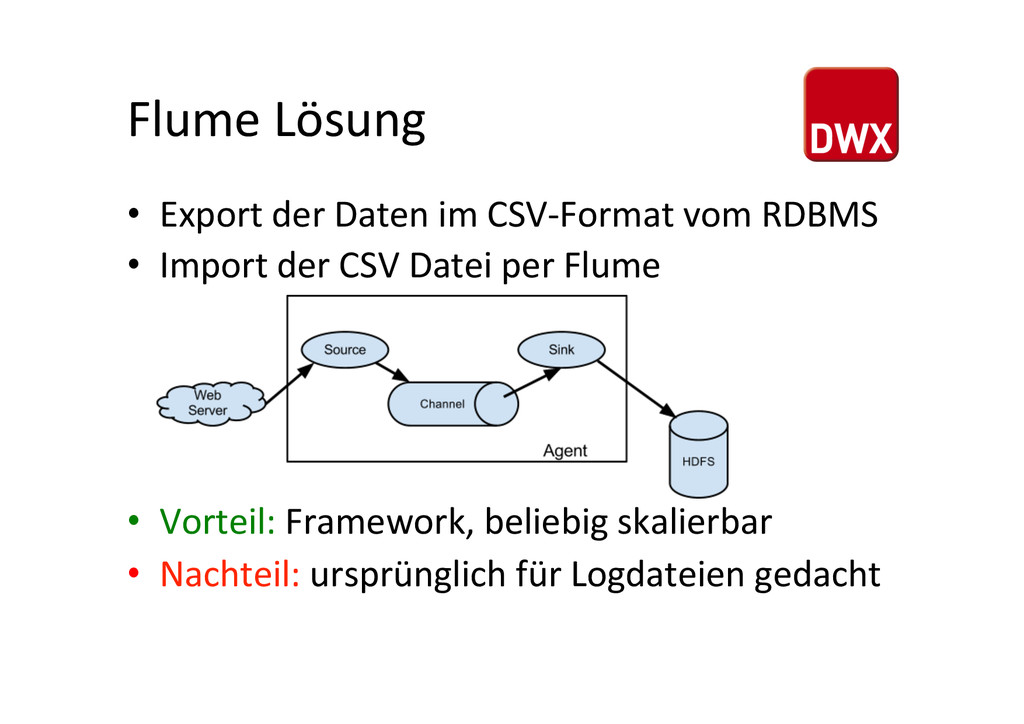
um Daten zu – sammeln – aggregieren – bewegen • besteht daher aus drei Teilen – Agent (liest Daten aus einer Anwendung/Logfile) – Processor (direkte Verarbeitung) – Collector (schreibt die Daten auf ein Storage) • Ist damit eine Frameworkalterna%ve für den Import von Dateien hUp://www.mendorailhistory.org/1_logging/flumes.htm Brennan Creek 1918
eine Datei sein tier1.sources.source1.type = netcat tier1.sources.source1.bind = 127.0.0.1 tier1.sources.source1.port = 9999 • Channel kann Speicher oder Datei sein tier1.channels.channel1.type = memory • Sink ist die Verarbeitung und das Ziel tier1.sinks.sink1.hdfs.path = /user/flume/year=%Y/month=%m/day=%d tier1.sinks.sink1.serializer = de.data2day.flume.serializer.CSVSerializer$Builder
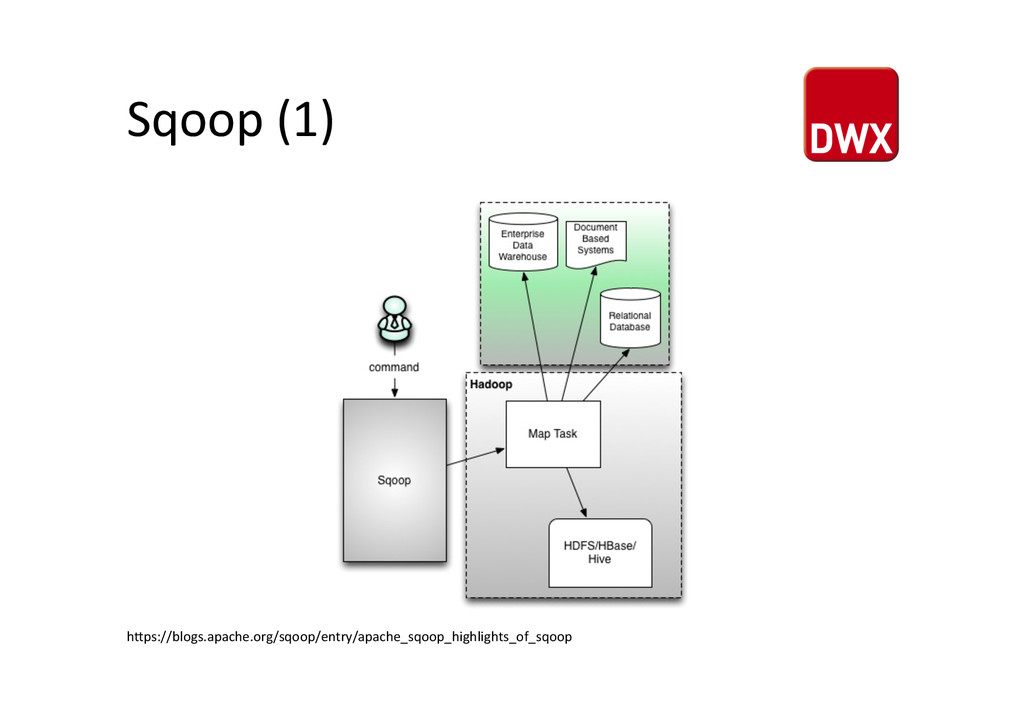
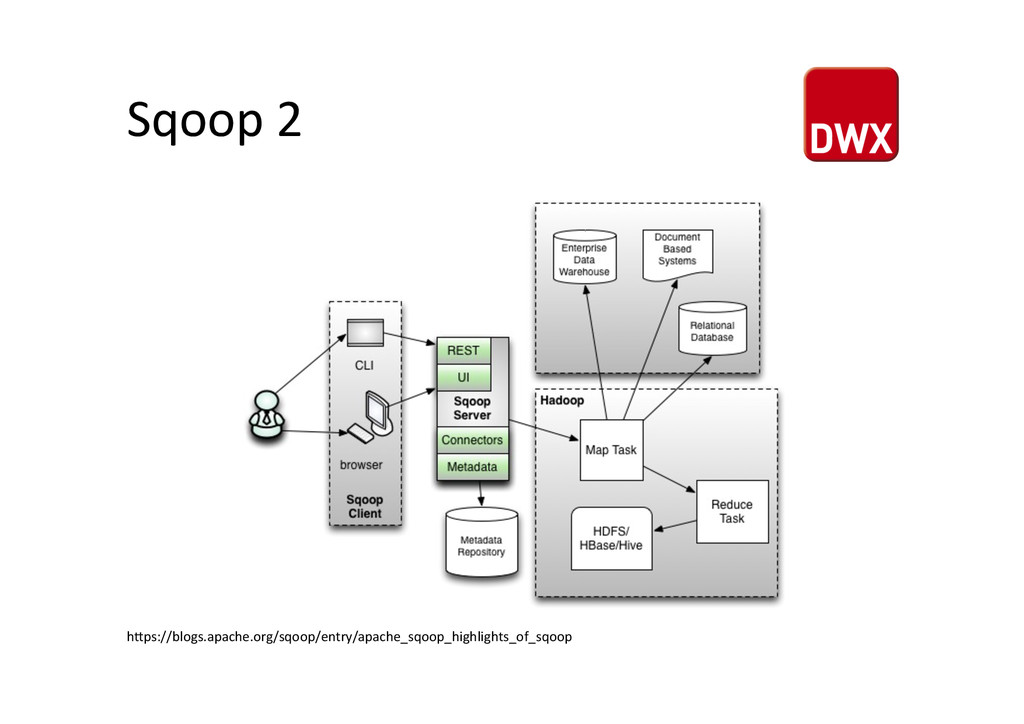
(2) • SQL to Hadoop • ein Prozess für Import/Export • keine Analyse von Daten • kein Filtern von Daten • direkter Zugriff per JDBC • wird häufig in Oozie Workflows genutzt hUp://integralnet.co.uk/tag/apache-‐hadoop/
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
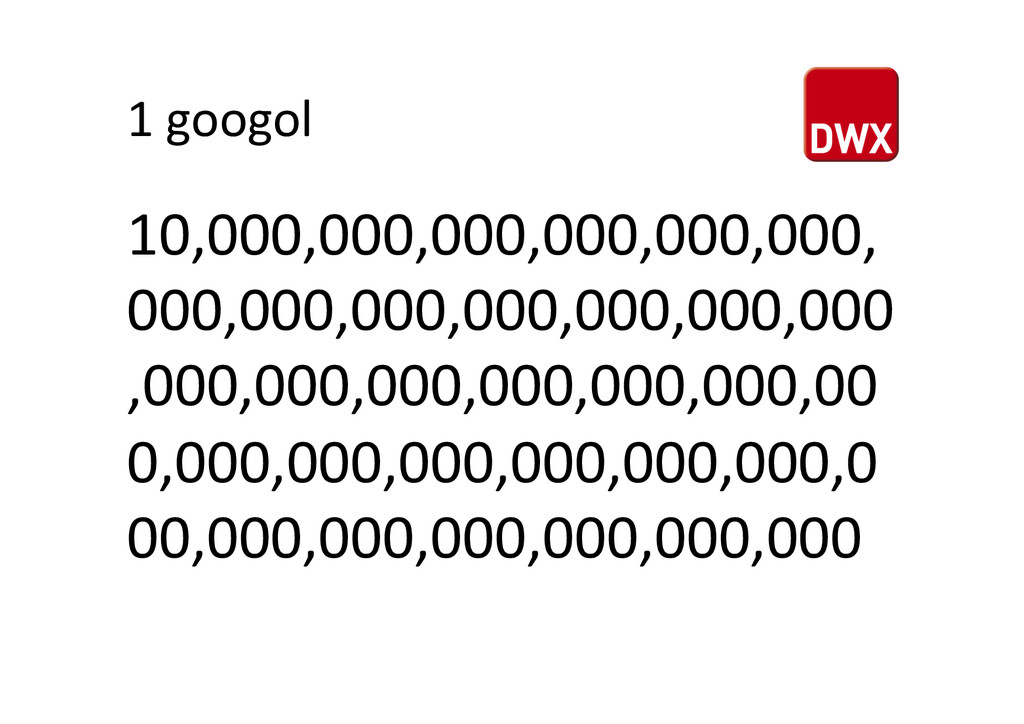{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}