posix_fadvise(fd, 0, s.st_size, POSIX_FADV_DONTNEED); gettimeofday(&begin, NULL); base = (char*)mmap(0, s.st_size, PROT_READ, MAP_SHARED, fd, 0); readall(fd, buffer); visitall(base, s.st_size); gettimeofday(&end, NULL); cout<<"user read time used:"<<int(get_elapse_time(&begin, &end))<<" ms"<<endl; munmap(base, s.st_size); posix_fadvise(fd, 0, s.st_size, POSIX_FADV_DONTNEED); base = (char*)mmap(0, s.st_size, PROT_READ, MAP_SHARED, fd, 0); gettimeofday(&begin, NULL); visitall(base, s.st_size); gettimeofday(&end, NULL); cout<<"sequntial page fault time used:"<<int(get_elapse_time(&begin, &end))<<" ms"<<endl; munmap(base, s.st_size); posix_fadvise(fd, 0, s.st_size, POSIX_FADV_DONTNEED); gettimeofday(&begin, NULL); base = (char*)mmap(0, s.st_size, PROT_READ, MAP_SHARED|MAP_POPULATE, fd, 0); gettimeofday(&end, NULL); cout<<"map populate time used:"<<int(get_elapse_time(&begin, &end))<<" ms"<<endl; munmap(base, s.st_size); posix_fadvise(fd, 0, s.st_size, POSIX_FADV_DONTNEED); gettimeofday(&begin, NULL); base = (char*)mmap(0, s.st_size, PROT_READ, MAP_SHARED|MAP_LOCKED, fd, 0); gettimeofday(&end, NULL); cout<<"map locked time used:"<<int(get_elapse_time(&begin, &end))<<" ms"<<endl; munmap(base, s.st_size); posix_fadvise(fd, 0, s.st_size, POSIX_FADV_DONTNEED); gettimeofday(&begin, NULL); base = (char*)mmap(0, s.st_size, PROT_READ, MAP_SHARED, fd, 0); posix_fadvise(fd, 0, s.st_size, POSIX_FADV_WILLNEED);
![Mmap 详解 --powered by [email protected] 1, 函数定义 void *mmap(void *start,](https://files.speakerdeck.com/presentations/e1605bd0b16d01307a5c126342c0a680/slide_0.jpg){kind=link}
![if(argc<4){ cout<<"error parameter"<<endl; exit(-1); } char *filename = argv[1]; int](https://files.speakerdeck.com/presentations/e1605bd0b16d01307a5c126342c0a680/slide_1.jpg){kind=link}
![base[i] = '\0'; } */ cout<<"mmap region 0x"<<hex<<(long)base<<" "<<strerror(errno)<<endl; sleep(1000);](https://files.speakerdeck.com/presentations/e1605bd0b16d01307a5c126342c0a680/slide_2.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
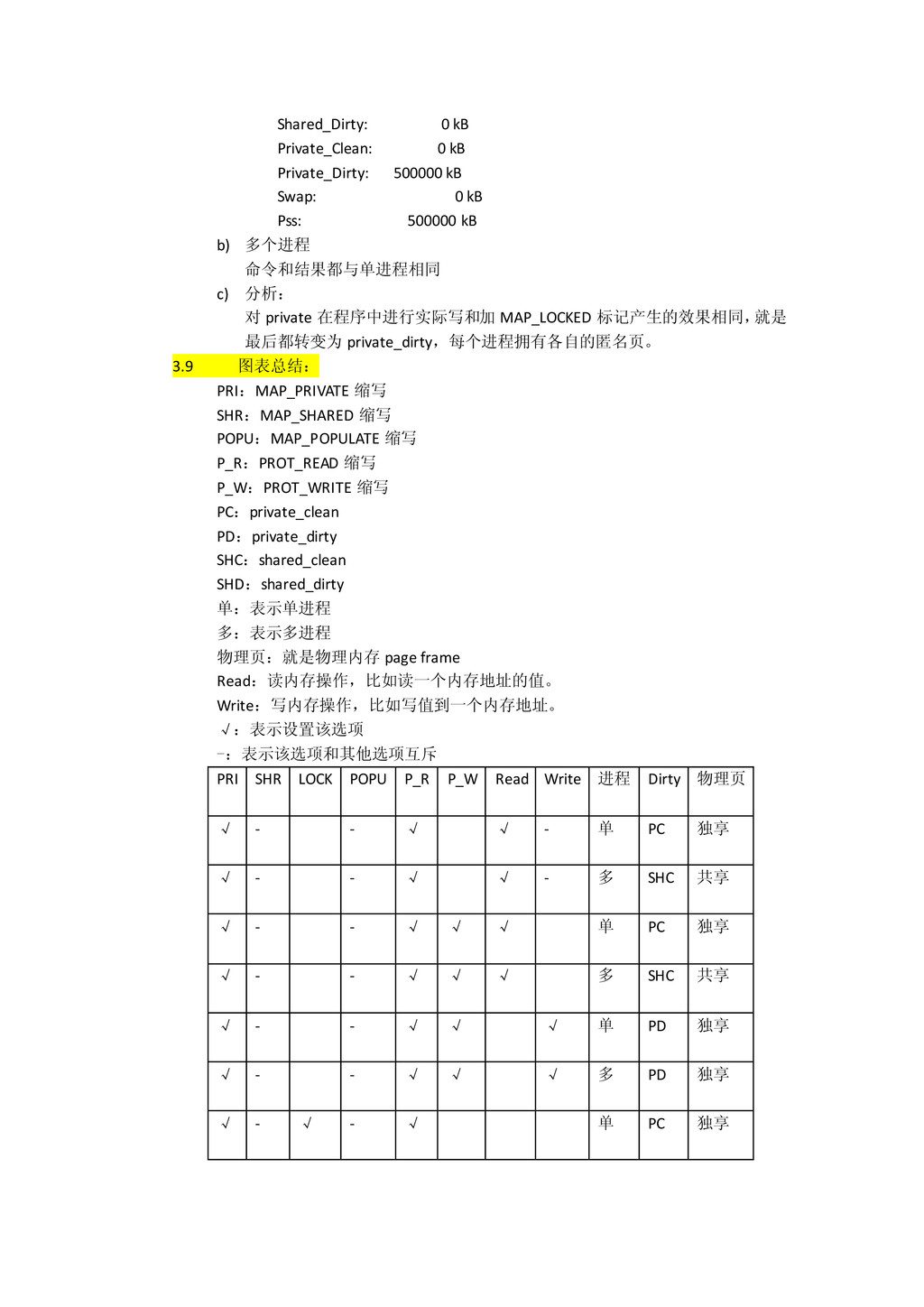{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![char *base = NULL; char buffer[READ_BUF_SIZE]; struct timeval begin, end;](https://files.speakerdeck.com/presentations/e1605bd0b16d01307a5c126342c0a680/slide_14.jpg){kind=link}
{kind=link}