Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
ピグパーティにおけるMongoDB CommunityバージョンからAtlasへの移行事例
Search
Hotaka Matsuoka
July 16, 2024
Programming
550
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
ピグパーティにおけるMongoDB CommunityバージョンからAtlasへの移行事例
db tech showcase 2024 Tokyo PC14 の登壇内容になります。
https://www.db-tech-showcase.com/2024/
Hotaka Matsuoka
July 16, 2024
Other Decks in Programming
See All in Programming
SLOをサービス品質の共通言語にするために 取り組んできたこと
wakana0222
0
480
音楽のための関数型プログラミング言語mimiumにおける多段階計算の活用
tomoyanonymous
1
300
分散システム、なんですぐ死んでしまうん?耐障害性を高めたいあなたのためのレジリエンスパターン入門
mshibuya
7
5.6k
過去最大のMCPアップデート! 2026-07-28 RC版の謎に迫る
licux
6
460
えっ!!コードを読まずに開発を!?
hananouchi
0
180
Vue × Nuxt × Oxc どこまで使える?実運用の現在地
andpad
0
370
ビデオ通話が繋がる0.2秒で何が起きているのか
supurazako
2
130
そのテスト、説明できますか?~LWテスト戦略FW~のご紹介
nakahara
0
200
例外の正しい扱い方 そのエラー try-catchして大丈夫?
jinwatanabe
0
360
任せる範囲はこう広がった / How the Scope of AI Delegation Has Expanded
nrslib
1
250
スマートグラスで並列バイブコーディング
hyshu
0
290
1B+ /day規模のログを管理する技術
broadleaf
0
130
Featured
See All Featured
Building a A Zero-Code AI SEO Workflow
portentint
PRO
0
630
Done Done
chrislema
186
16k
Building Applications with DynamoDB
mza
96
7.1k
Music & Morning Musume
bryan
47
7.3k
The Cost Of JavaScript in 2023
addyosmani
55
10k
個人開発の失敗を避けるイケてる考え方 / tips for indie hackers
panda_program
123
22k
The agentic SEO stack - context over prompts
schlessera
0
840
[SF Ruby Conf 2025] Rails X
palkan
2
1.2k
Leading Effective Engineering Teams in the AI Era
addyosmani
9
2.1k
How to Create Impact in a Changing Tech Landscape [PerfNow 2023]
tammyeverts
55
3.4k
Java REST API Framework Comparison - PWX 2021
mraible
34
9.5k
Building an army of robots
kneath
306
46k
Transcript
ピグパーティにおけるMongoDB Community バージョンから Atlasへの移⾏事例 株式会社サイバーエージェント 松岡 穂⾼ / サーバーサイドエンジニア PIGG
PARTY
松岡 穂⾼ 株式会社サイバーエージェント 2022年新卒⼊社 サーバーサイドエンジニア AmebaLIFE事業本部 ピグパーティ 主にインフラ運⽤からアプリのバックエンド開発を担当 ⾃⼰紹介
アジェンダ 01. ピグパーティの説明 02. MongoDBの選定理由 03. MongoDB Atlasへ移⾏するにあたった背景 04. データベース移⾏の流れと移⾏戦略
05. まとめ
ピグパーティの説明
ピグパーティの説明 「ピグパーティ」とは、仮想空間内でなりきりたいアバター(ピグ)を使って、 ピグのきせかえやお部屋のもようがえをしながら楽しむ、アバターSNSサービスです。
MongoDBの選定理由
MongoDBの選定理由 サーバーサイドはNode.jsを採⽤しており、MongoDBとの親和性が⾼い • データ構造がJSONなのでJavaScript/TypeScriptと相性が良い 柔軟なスキーマ設計 • MongoDBはスキーマレスであり、柔軟なデータモデル設計が可能 • 仕様変更が多いゲーム開発にマッチしている ⾼い性能とスケーラビリティ
• シャーディングによる負荷分散やレプリケーションによる⾼可⽤性 • ⼤量の同時接続ユーザーを持つオンラインゲームでも安⼼したパフォーマンスが提供できる 過去のピグサービスで実績がある • これまでのピグのサービスでもMongoDBを採⽤してきており、知⾒が豊富
MongoDB Atlas へ移⾏するにあたった背景
MongoDB Atlasへ移⾏するにあたった背景 インフラ運⽤コストの増⼤と属⼈化 • GCPのCompute Engine上にMongoDBをセルフホストしており、管理している • しかし、定期的に開催されるイベントの負荷対策の度にインフラのスペックアップ作業を⼿動で⾏っており、 運⽤コストが増⼤していた OSのサポート終了
• CentOS 7のサポート終了に伴い、セキュリティリスクやサポートの⽋如の懸念 今後のサービス成⻑を⾒据えた拡張性と安定性の確保 • サービスの利⽤者が増加する中で、より⾼い可⽤性とパフォーマンスを維持する必要があった • 短期間でのリソースのスケーリングが求められるため、柔軟なインフラが必要である
MongoDB Atlasへ移⾏するにあたった背景 そのためMongoDB Atlasへ移⾏し以下を実現させる 運⽤コスト削減と属⼈化の解消 サービス成⻑にも柔軟に対応できるインフラ
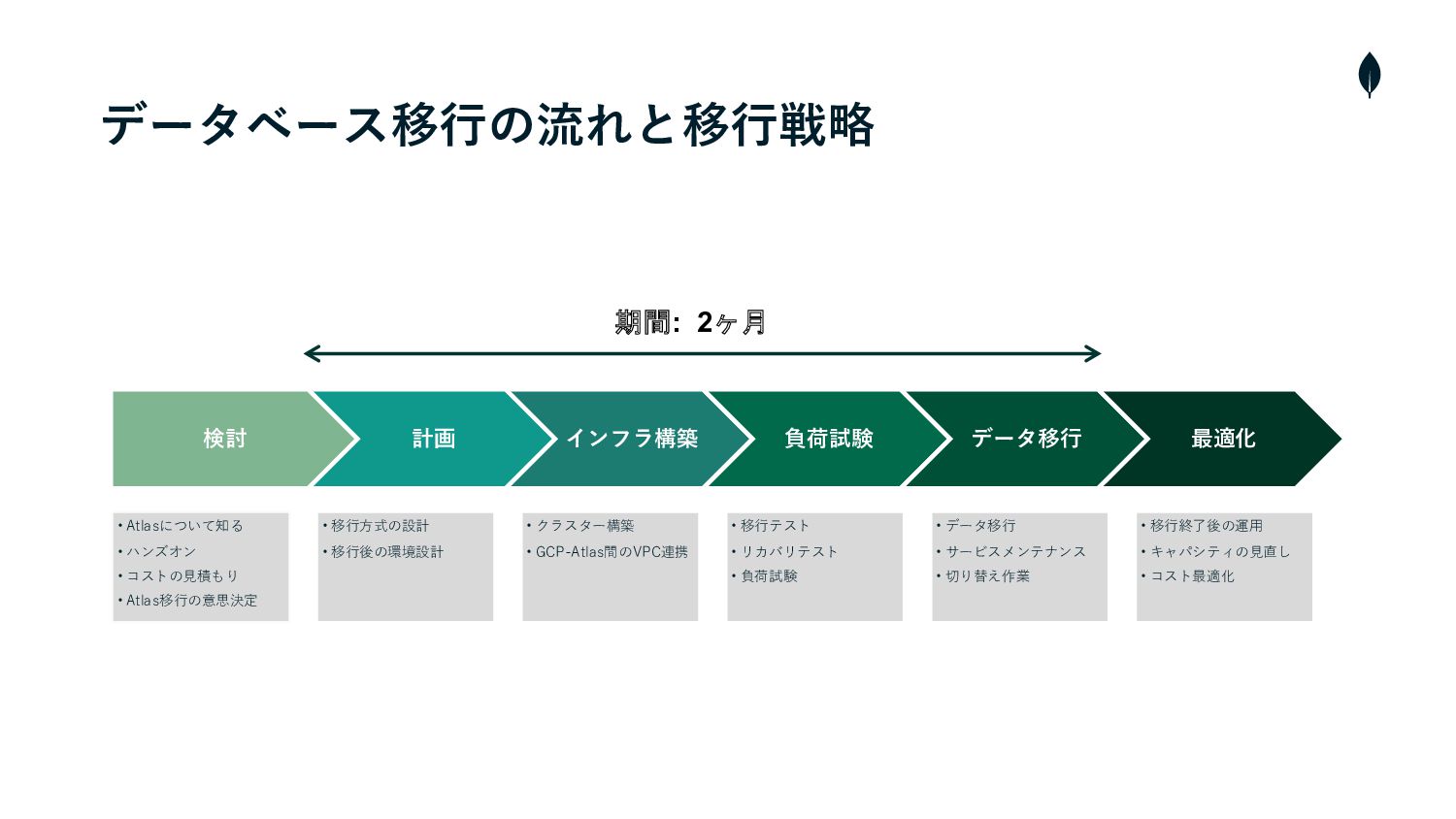
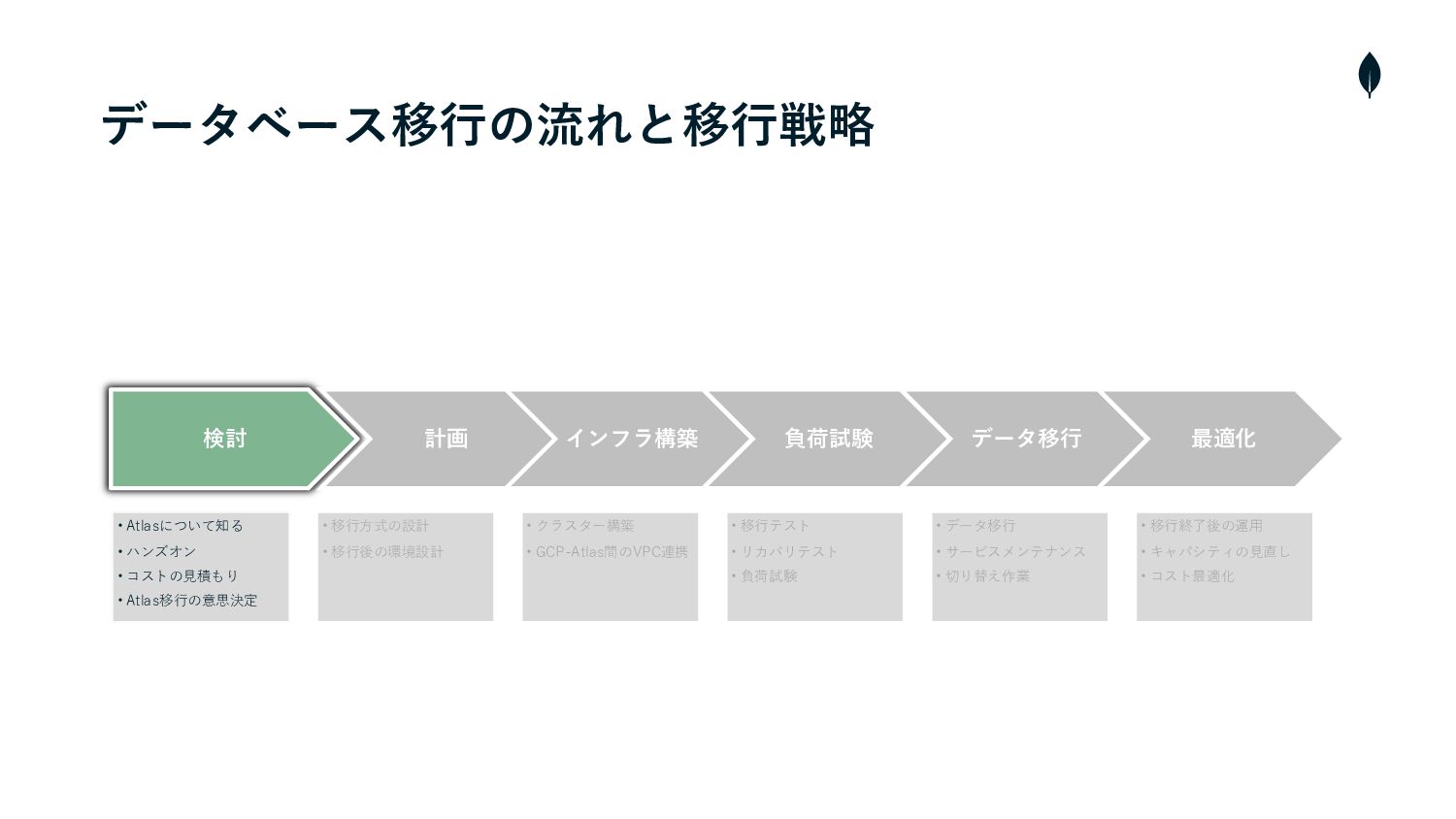
データベース移⾏の流れと戦略
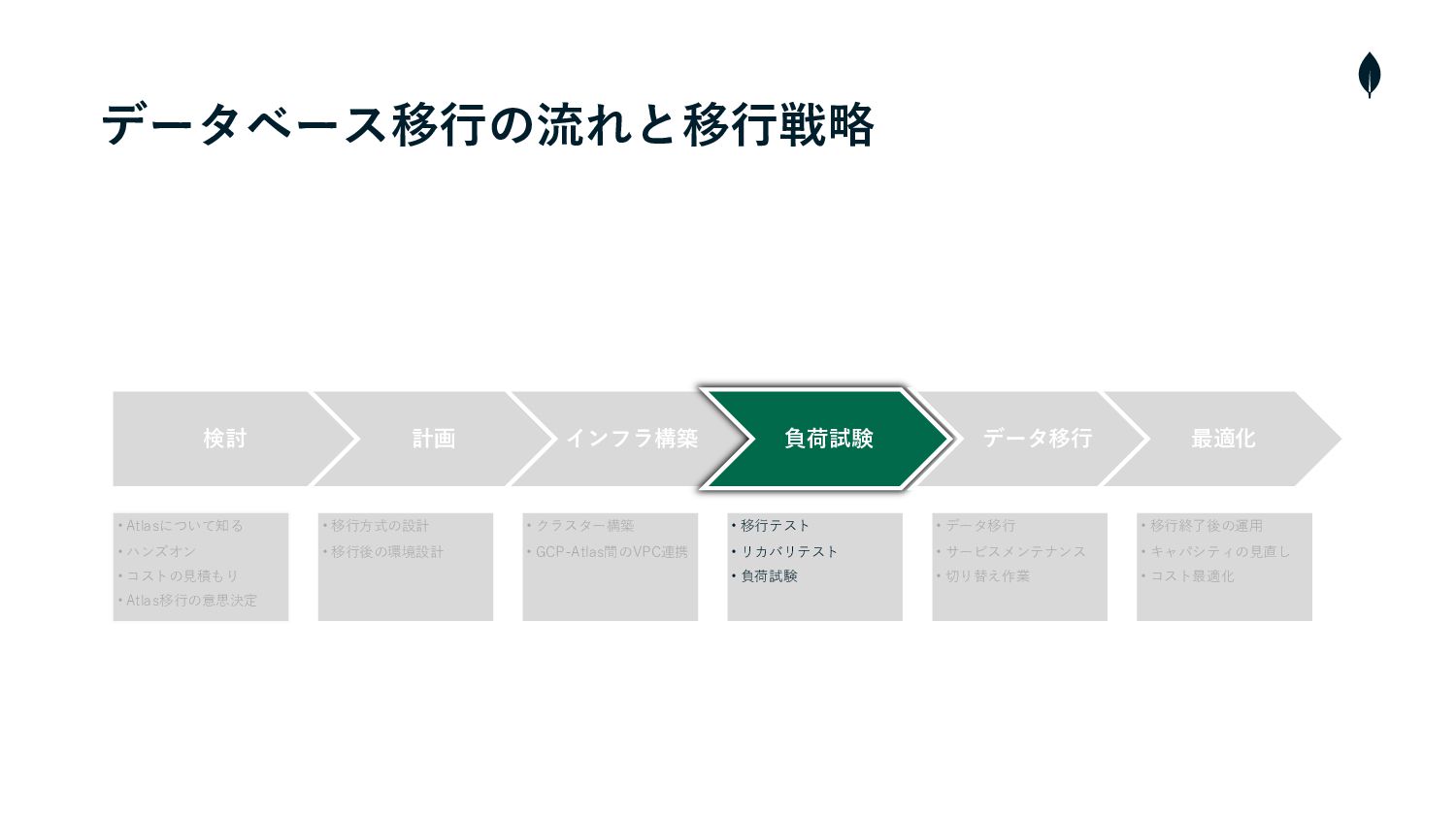
データベース移⾏の流れと移⾏戦略 検討 計画 インフラ構築 負荷試験 データ移⾏ 最適化 • Atlasについて知る •
ハンズオン • コストの⾒積もり • Atlas移⾏の意思決定 • 移⾏⽅式の設計 • 移⾏後の環境設計 • クラスター構築 • GCP-Atlas間のVPC連携 • 移⾏テスト • リカバリテスト • 負荷試験 • データ移⾏ • サービスメンテナンス • 切り替え作業 • 移⾏終了後の運⽤ • キャパシティの⾒直し • コスト最適化 期間: 2ヶ月
データベース移⾏の流れと移⾏戦略 検討 計画 インフラ構築 負荷試験 データ移⾏ 最適化 • Atlasについて知る •
ハンズオン • コストの⾒積もり • Atlas移⾏の意思決定 • 移⾏⽅式の設計 • 移⾏後の環境設計 • クラスター構築 • GCP-Atlas間のVPC連携 • 移⾏テスト • リカバリテスト • 負荷試験 • データ移⾏ • サービスメンテナンス • 切り替え作業 • 移⾏終了後の運⽤ • キャパシティの⾒直し • コスト最適化
1. 検討 MongoDB Atlasに乗り換えるか検討する 検討ポイント 決め⼿のポイント ü 導⼊によって運⽤課題が解決できるか ü Atlasで提供されている機能が活⽤できるか
ü 安全に移⾏ができるか ü 簡単にDBの設定変更が可能で、運⽤コストを削減できる ü オートスケール・アーカイブなど活⽤できる機能がある ü Professional Servicesを活⽤したサポート体制がある
1. 検討 簡単にDBの設定変更が可能で、運⽤コストを削減できる • DBの設定変更がAtlas UIから変更可能 • ダウンタイムを最⼩限にしてスペック変更ができる • 今まではデータベースとインスタンスを停⽌して、マシン
タイプを変更して、再度起動という作業を各インスタンス ごとに⼿動で⾏なっていた... • mongodが12台、mongosが5台あるので全てスペックアッ プをしようとすると半⽇費やすことも
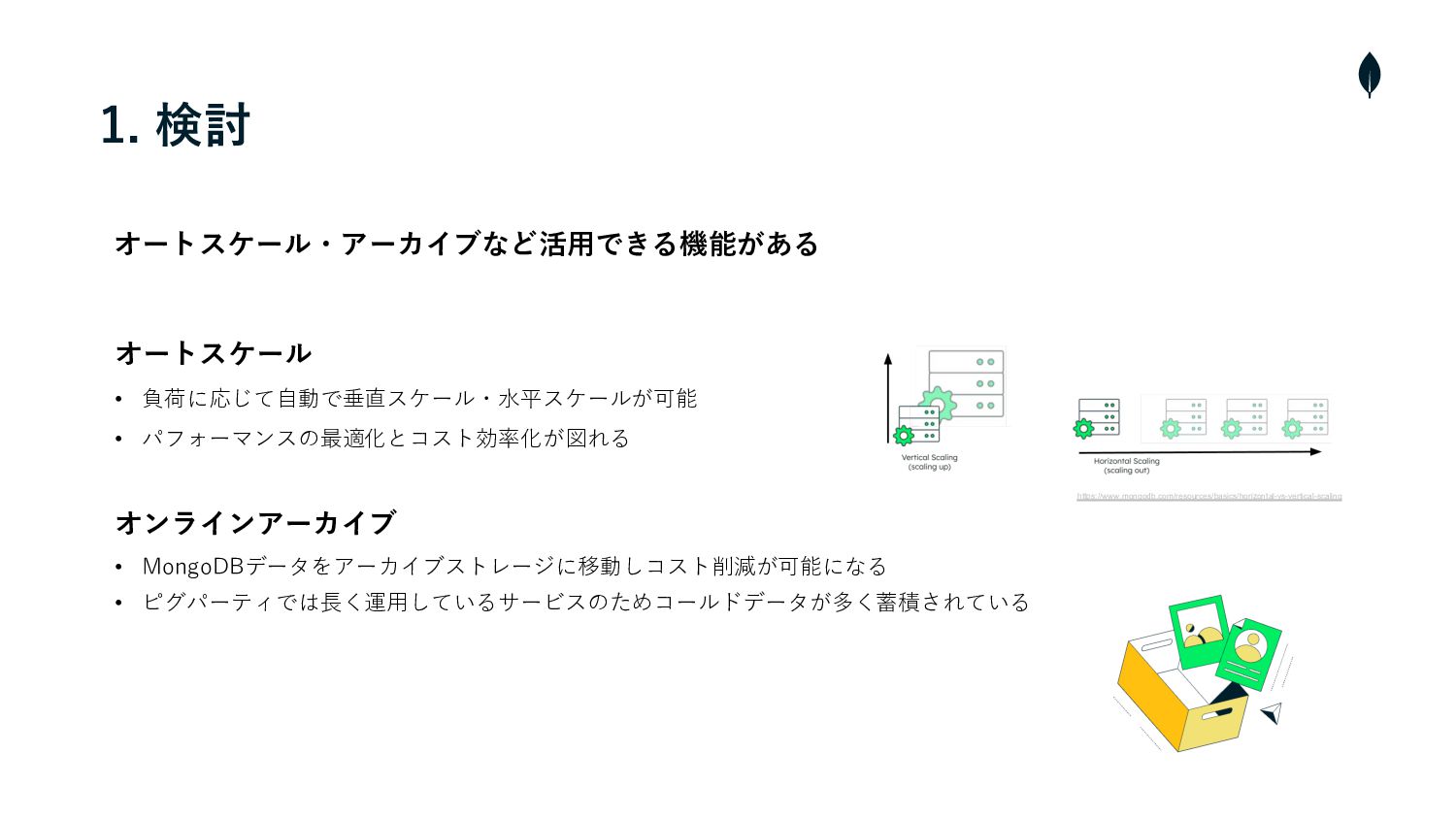
1. 検討 オートスケール・アーカイブなど活⽤できる機能がある オートスケール • 負荷に応じて⾃動で垂直スケール・⽔平スケールが可能 • パフォーマンスの最適化とコスト効率化が図れる https://www.mongodb.com/resources/basics/horizontal-vs-vertical-scaling オンラインアーカイブ
• MongoDBデータをアーカイブストレージに移動しコスト削減が可能になる • ピグパーティでは⻑く運⽤しているサービスのためコールドデータが多く蓄積されている
1. 検討 Professional Servicesを活⽤したサポート体制がある Professional Servicesとは • MongoDBが提供する専⾨的なサポートサービス • MongoDBのデプロイメント、運⽤、パフォーマンスチューニング、マイグレーションなどを⽀援してくれる
実際に使⽤した例 • MongoDB社のエンジニアと常時質問できる体制の⽤意 • 移⾏⽅法やリカバリ・バックアップ戦略についてのレビューとベストプラクティスの提案
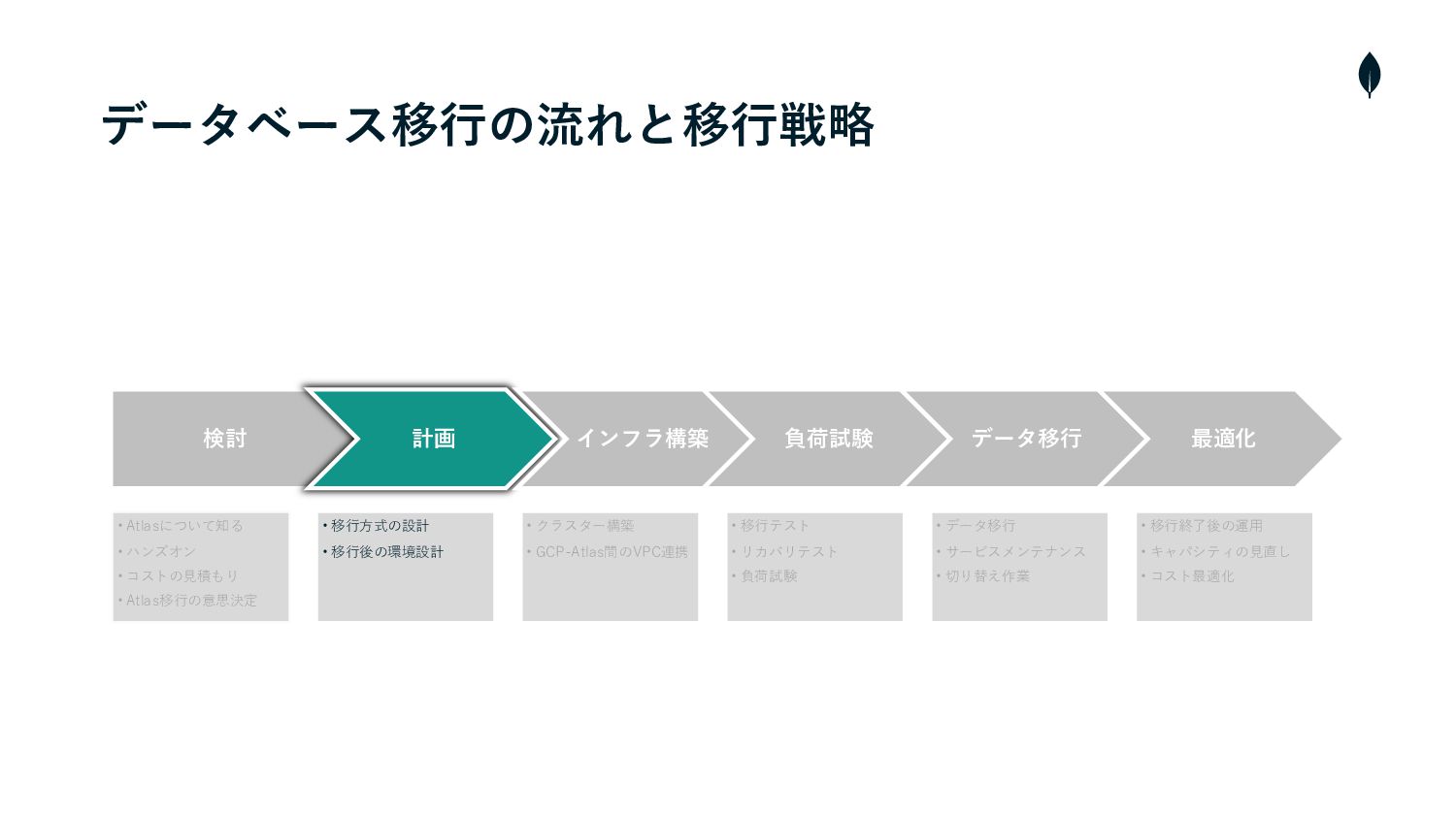
データベース移⾏の流れと移⾏戦略 検討 計画 インフラ構築 負荷試験 データ移⾏ 最適化 • Atlasについて知る •
ハンズオン • コストの⾒積もり • Atlas移⾏の意思決定 • 移⾏⽅式の設計 • 移⾏後の環境設計 • クラスター構築 • GCP-Atlas間のVPC連携 • 移⾏テスト • リカバリテスト • 負荷試験 • データ移⾏ • サービスメンテナンス • 切り替え作業 • 移⾏終了後の運⽤ • キャパシティの⾒直し • コスト最適化
2. 計画 構成 • 既存の構成は、特に負荷的なボトルネックはなかったため、シャード数やレプリカセットの数は変えない スペック • CPUのコア数が同じTierを選択
2. 計画 移⾏⽅法について検討 • MongoDBから移⾏⼿段がいくつか提供されている • その中でもCloud Managerを使⽤したPush⽅式のLive Migrateを採⽤
2. 計画 Cloud Managerとは • MongoDBが提供する運⽤・監視・⾃動化をするためのGUI管理ツール • こちらのツールはメトリクスチェックやバージョン管理として以前から利⽤していた • また、Cloud
ManagerとAtlasを連携させることができ、GUIで移⾏作業が可能になる
2. 計画 Live Migrateとは • 既存のMongoDBのデータを、最⼩限のダウンタイムでAtlasに移⾏するための機能 • この機能を利⽤することで、オンプレミスやクラウドプロバイダのMongoDBをAtlasに迅速かつ効率的に移⾏できる • 内部ではmongosyncというクラスタ間の同期プロセスを⾏なっており、この機能を使⽤することで、サービスを稼働した
ままでも、新しいクラスタに対し継続的なデータ同期が可能になる • またVPCピアリングとプライベートエンドポイントに対応しており、安全にデータ移⾏ができる (※シャード構成の場合は、プライベートエンドポイントのみ)
2. 計画 VPCピアリングとは • 2つのVPC間でトラフィックをルーティングを可能にす るネットワーク接続 プライベートエンドポイントとは • クラウド環境において特定のリソースのアクセスをイ ンターネット経由ではなく、内部ネットワーク経由で
⾏うもの • データを外部インターネットで経由することなくセキ ュリティも担保できる • AWS, GCP, Azureで使⽤可能 https://www.mongodb.com/docs/atlas/security-private-endpoint/
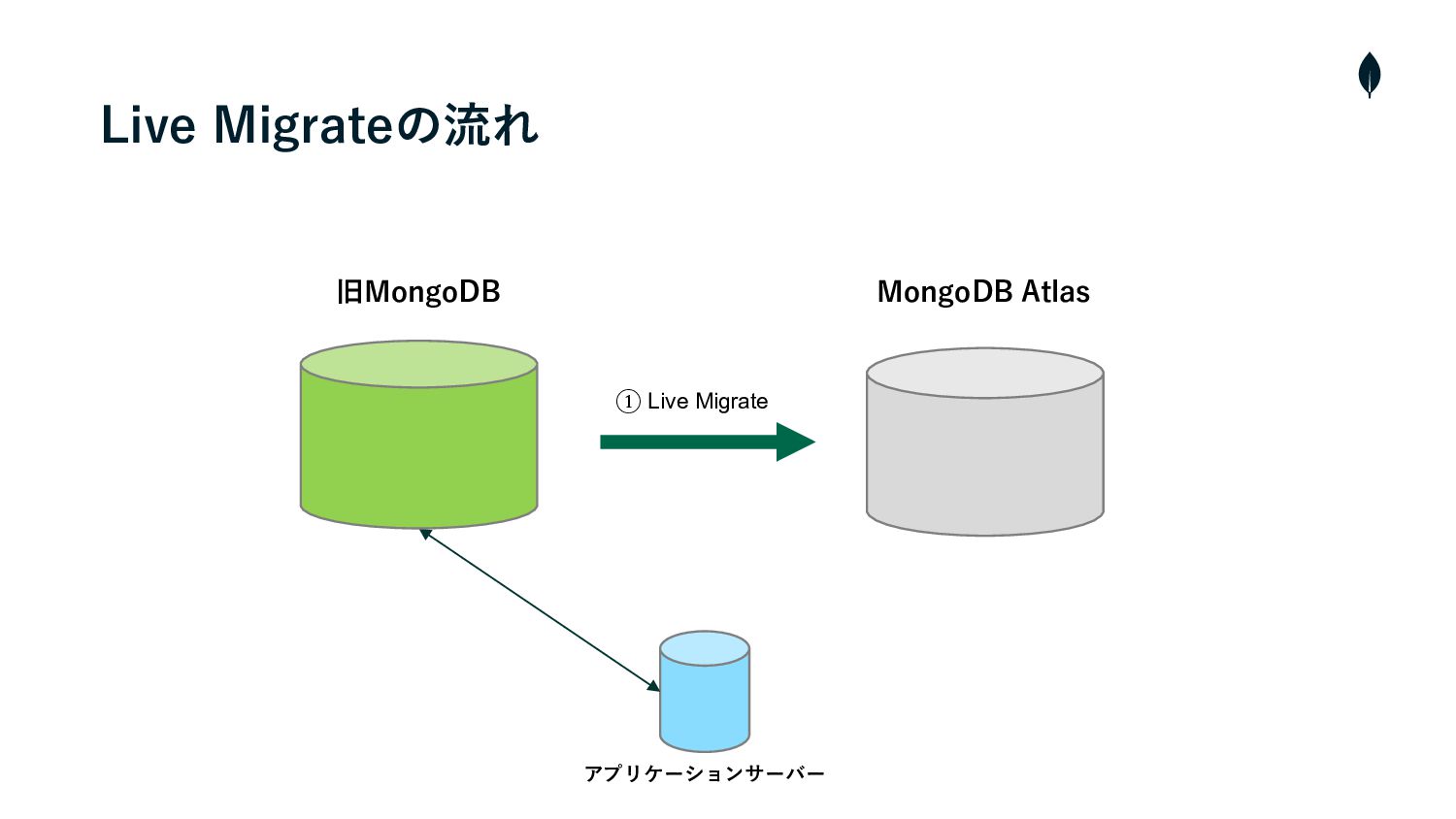
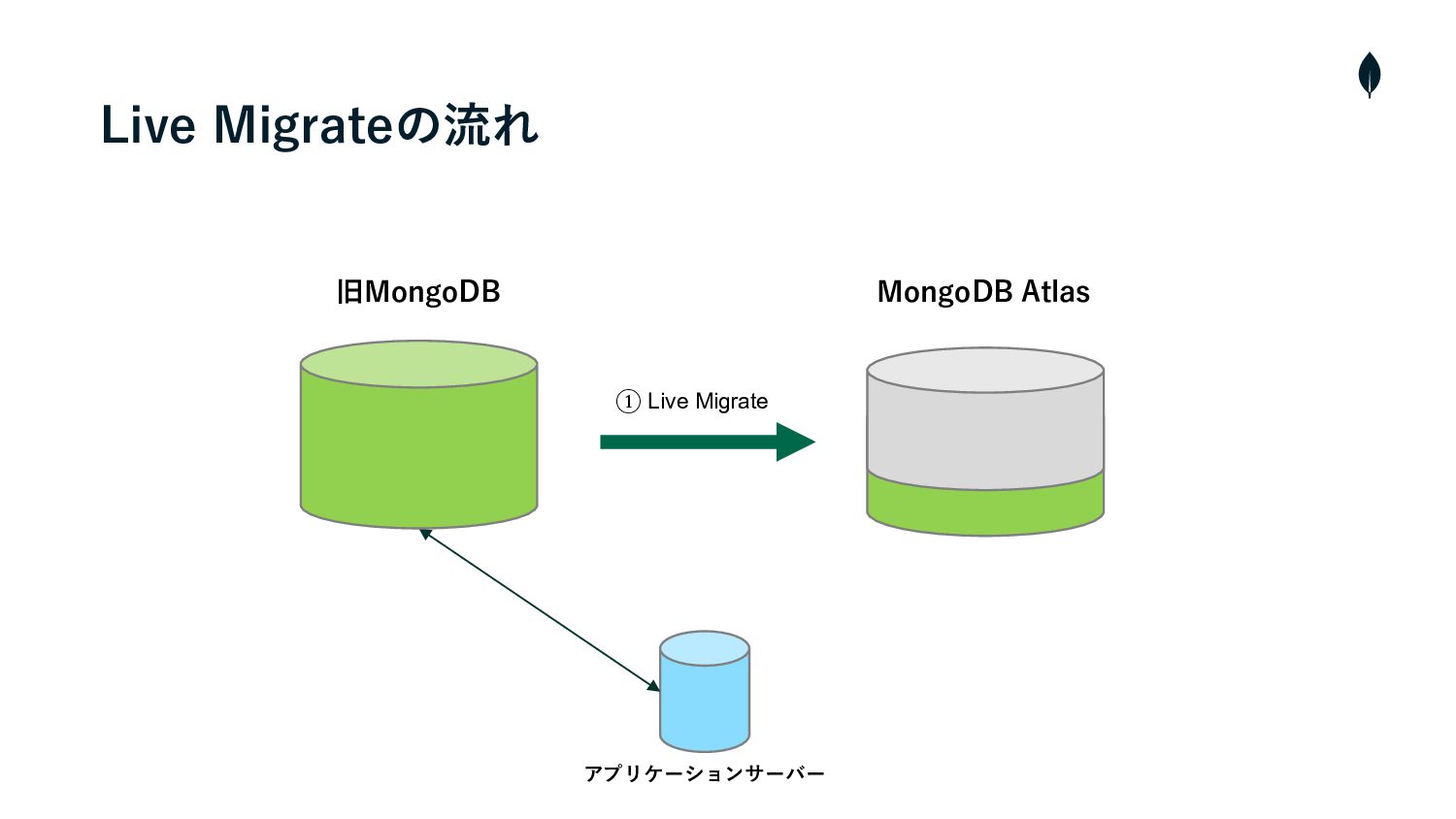
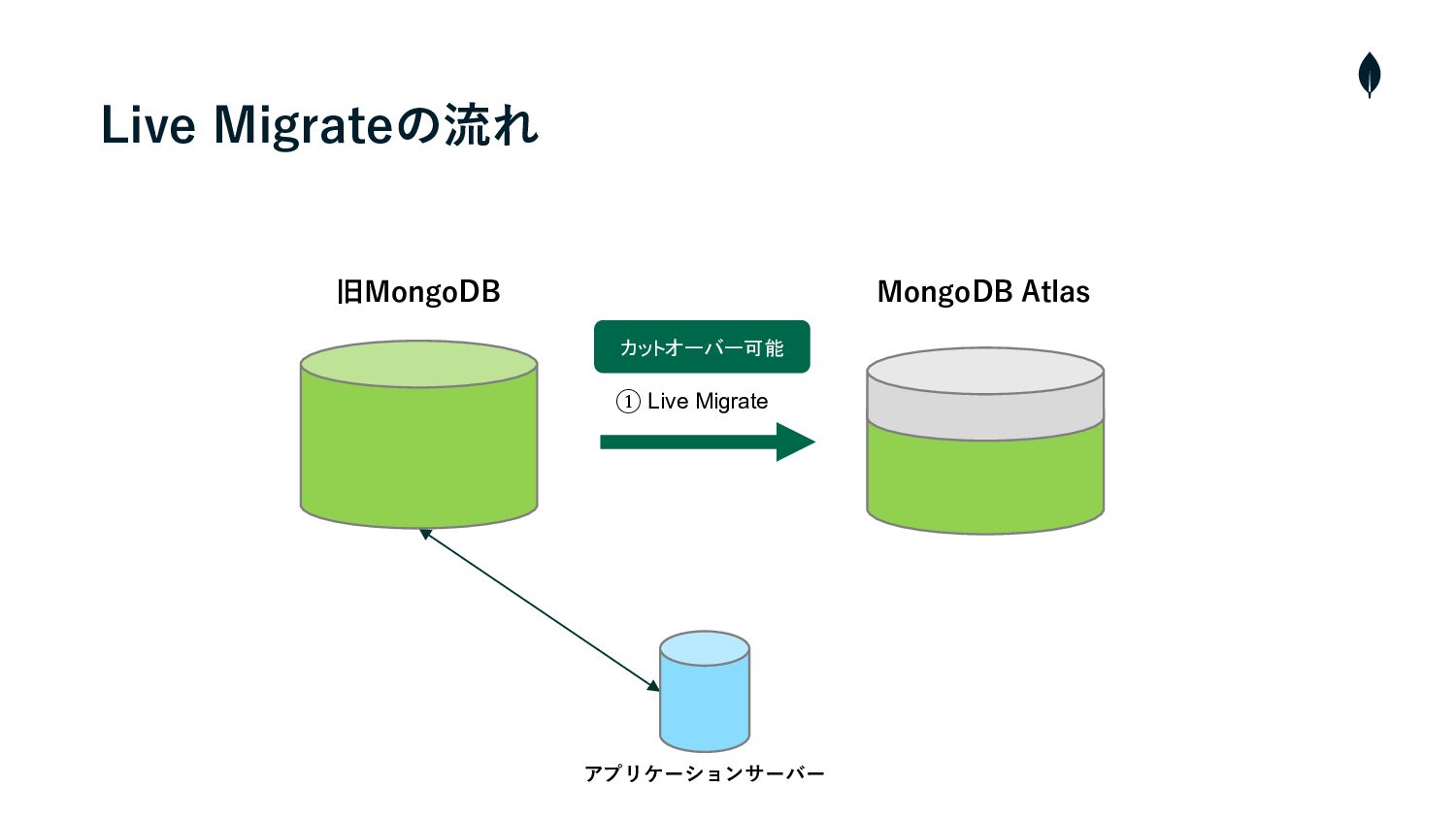
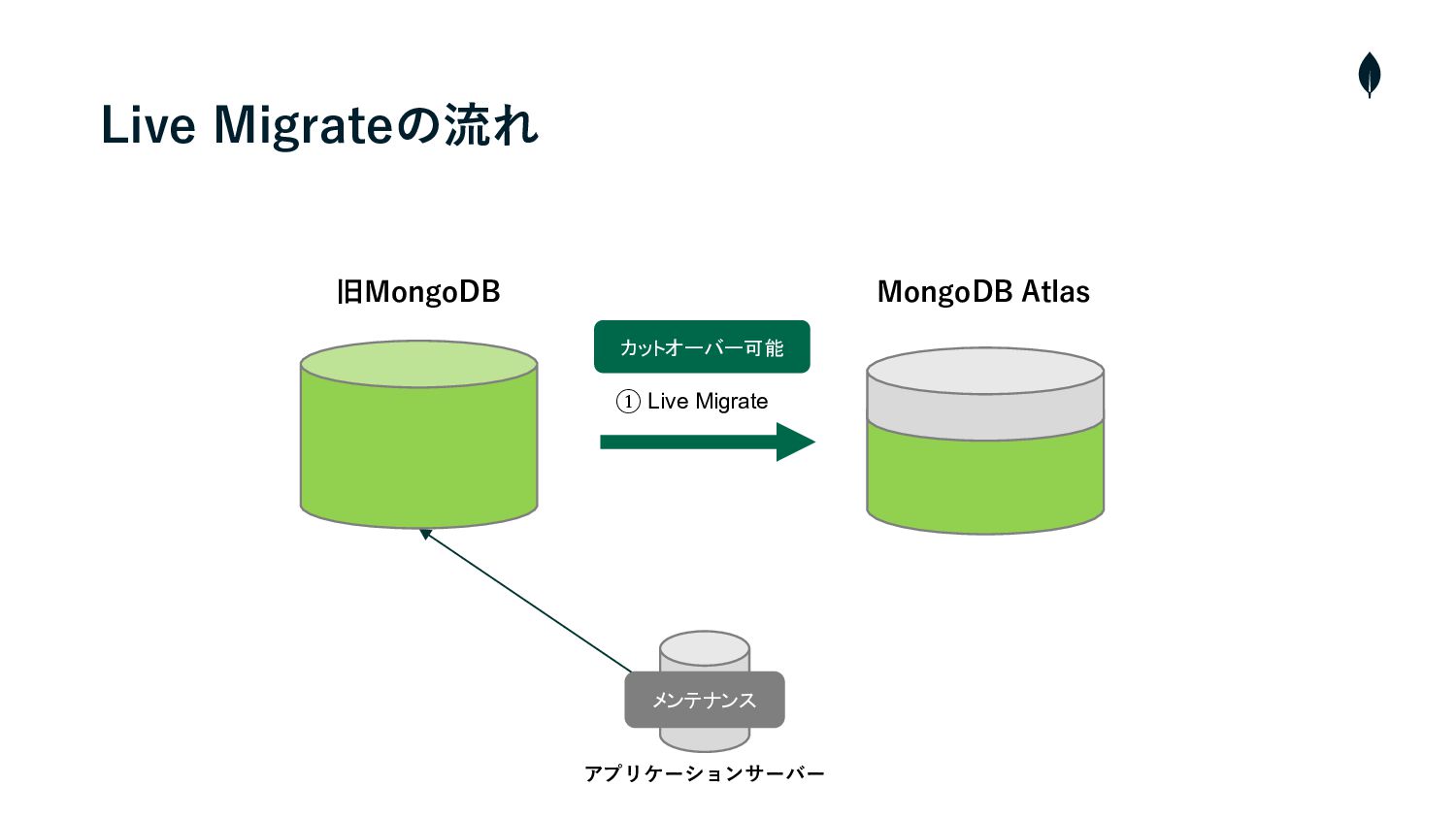
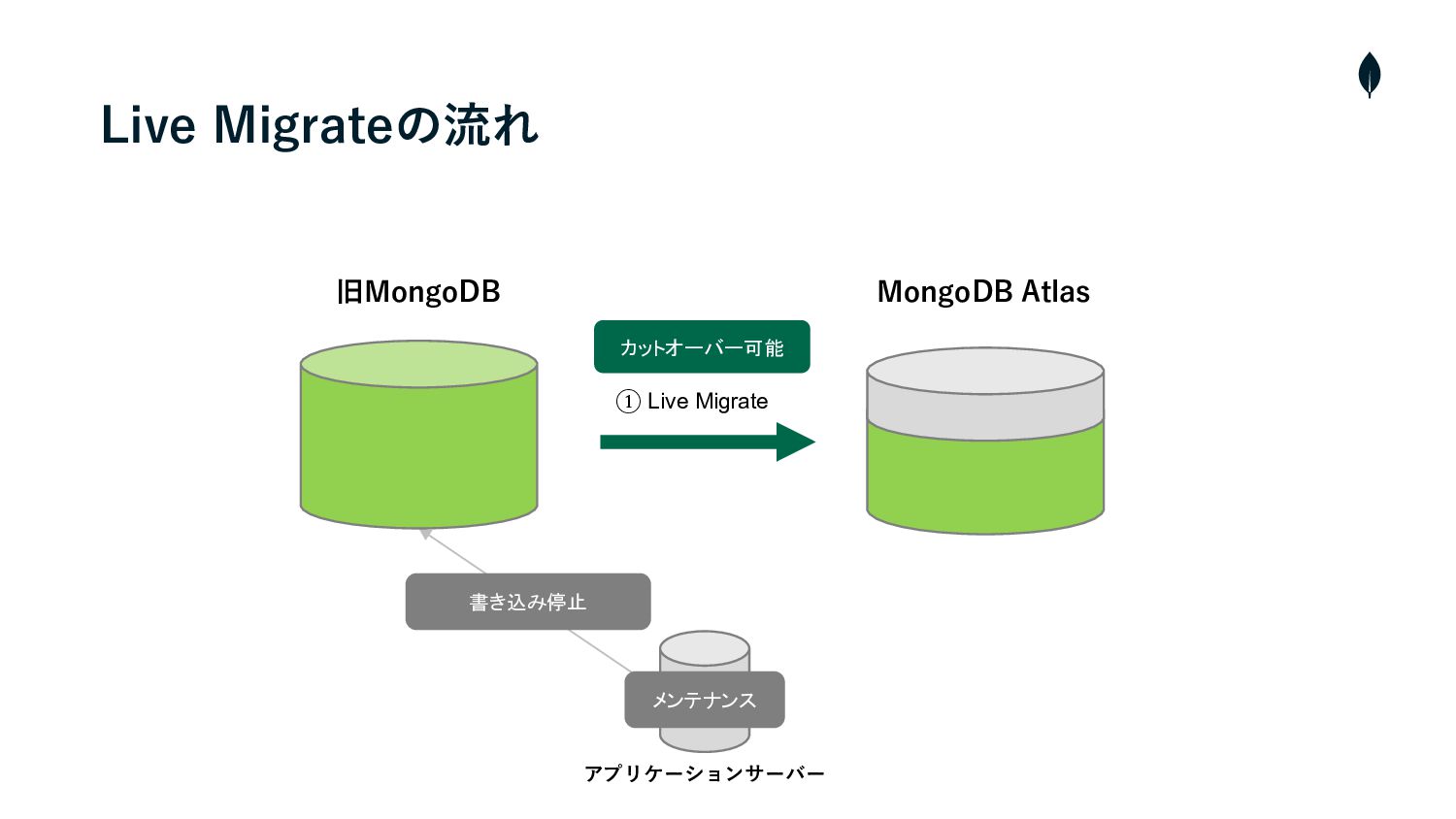
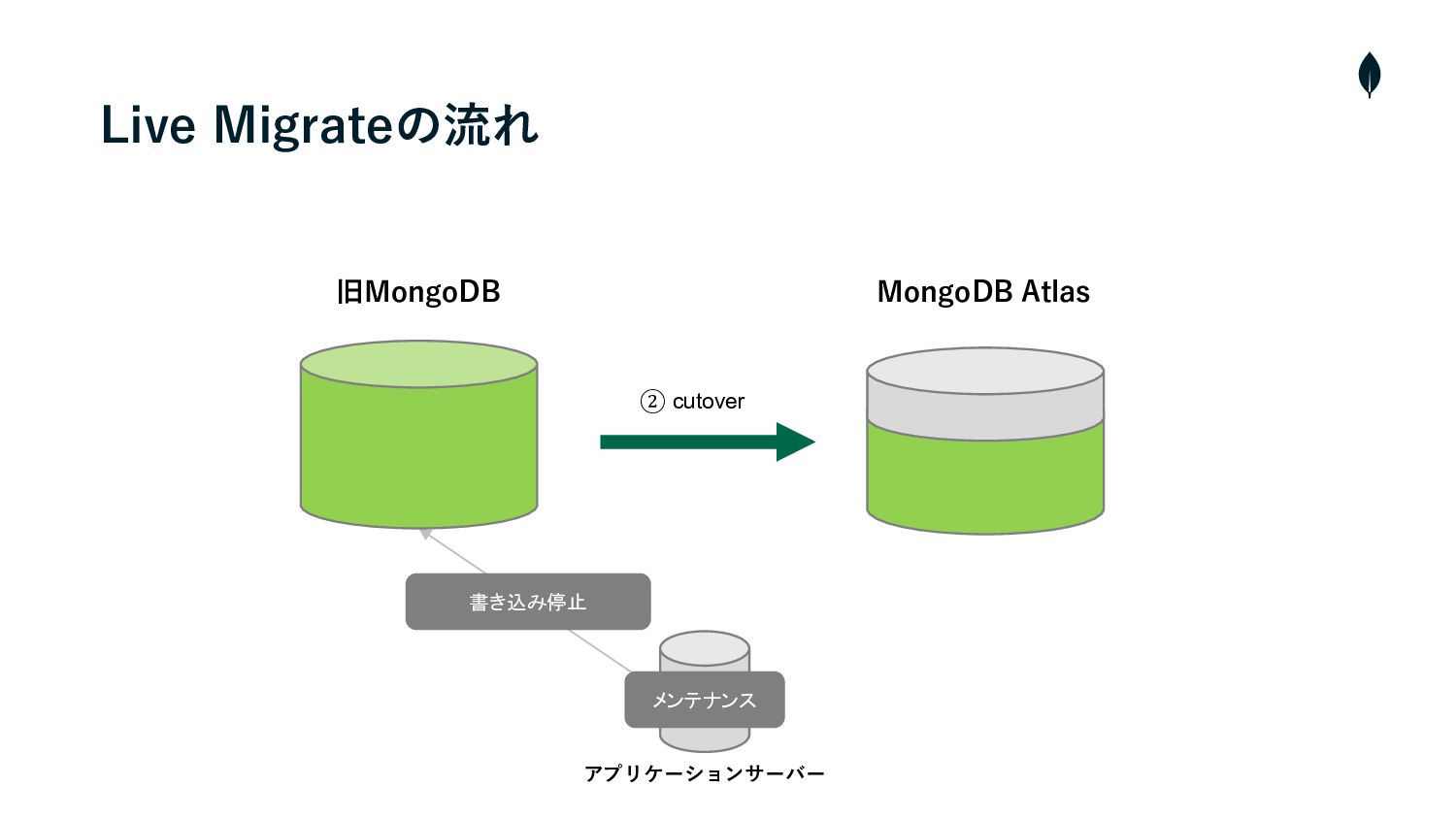
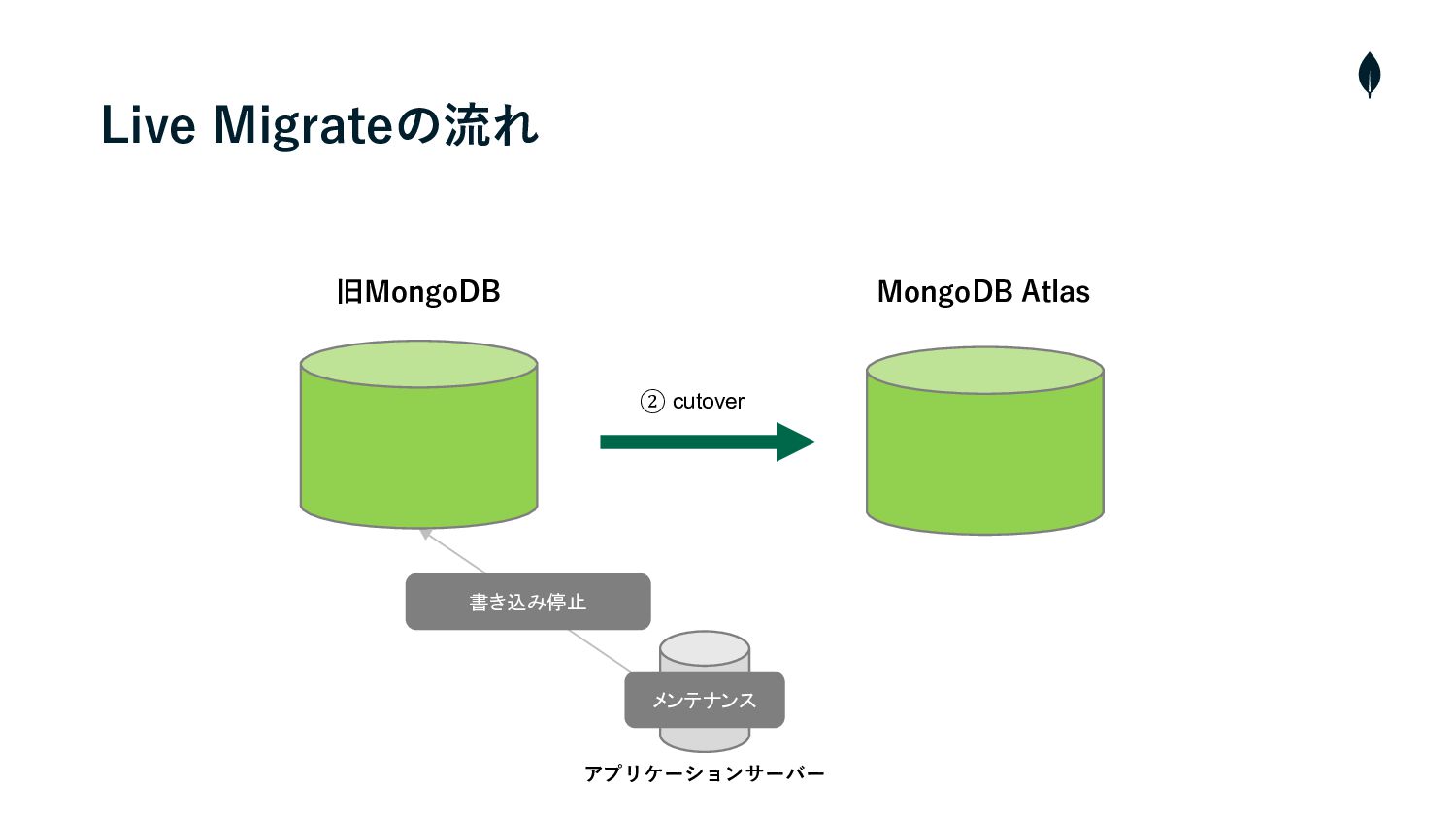
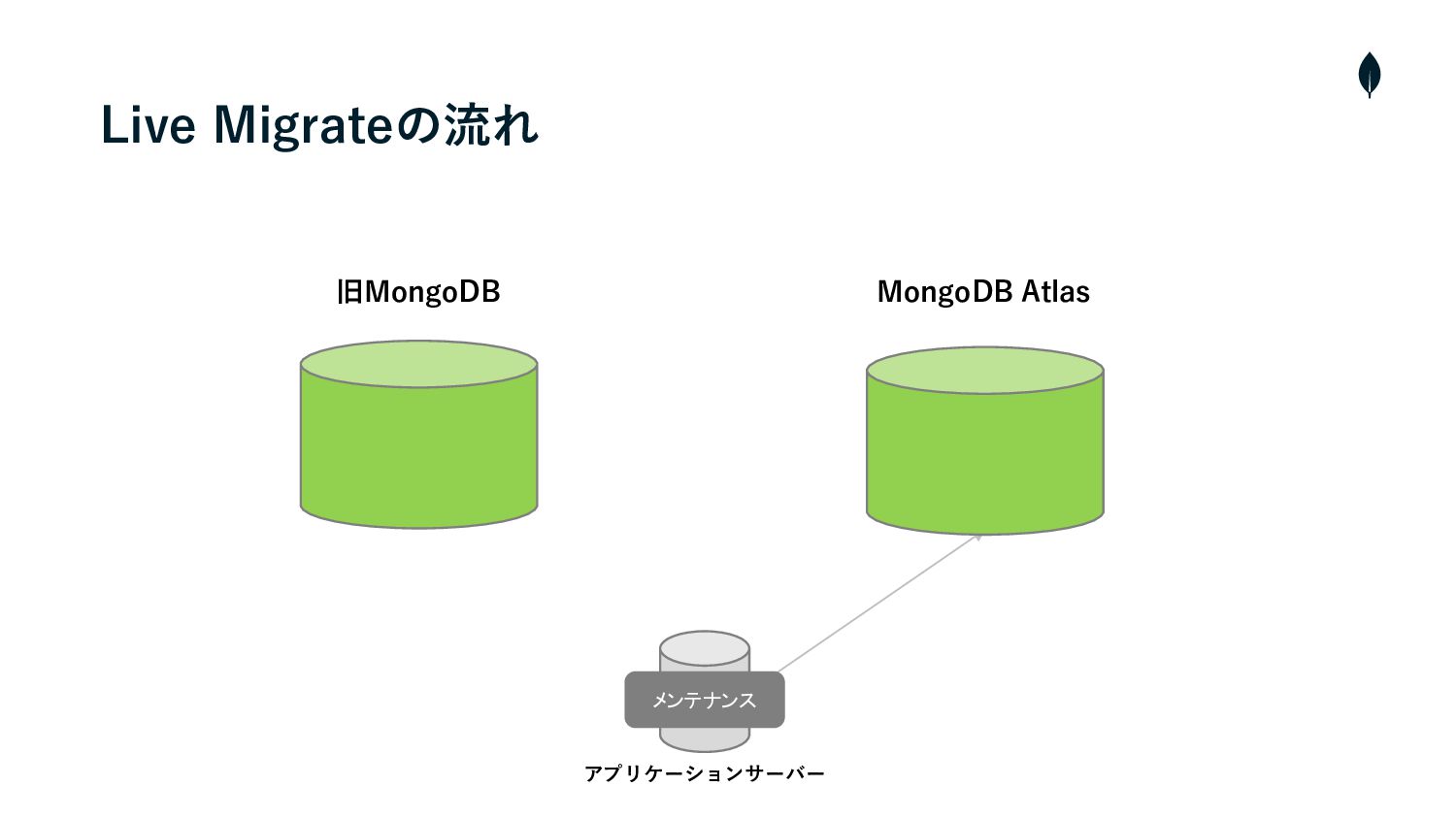
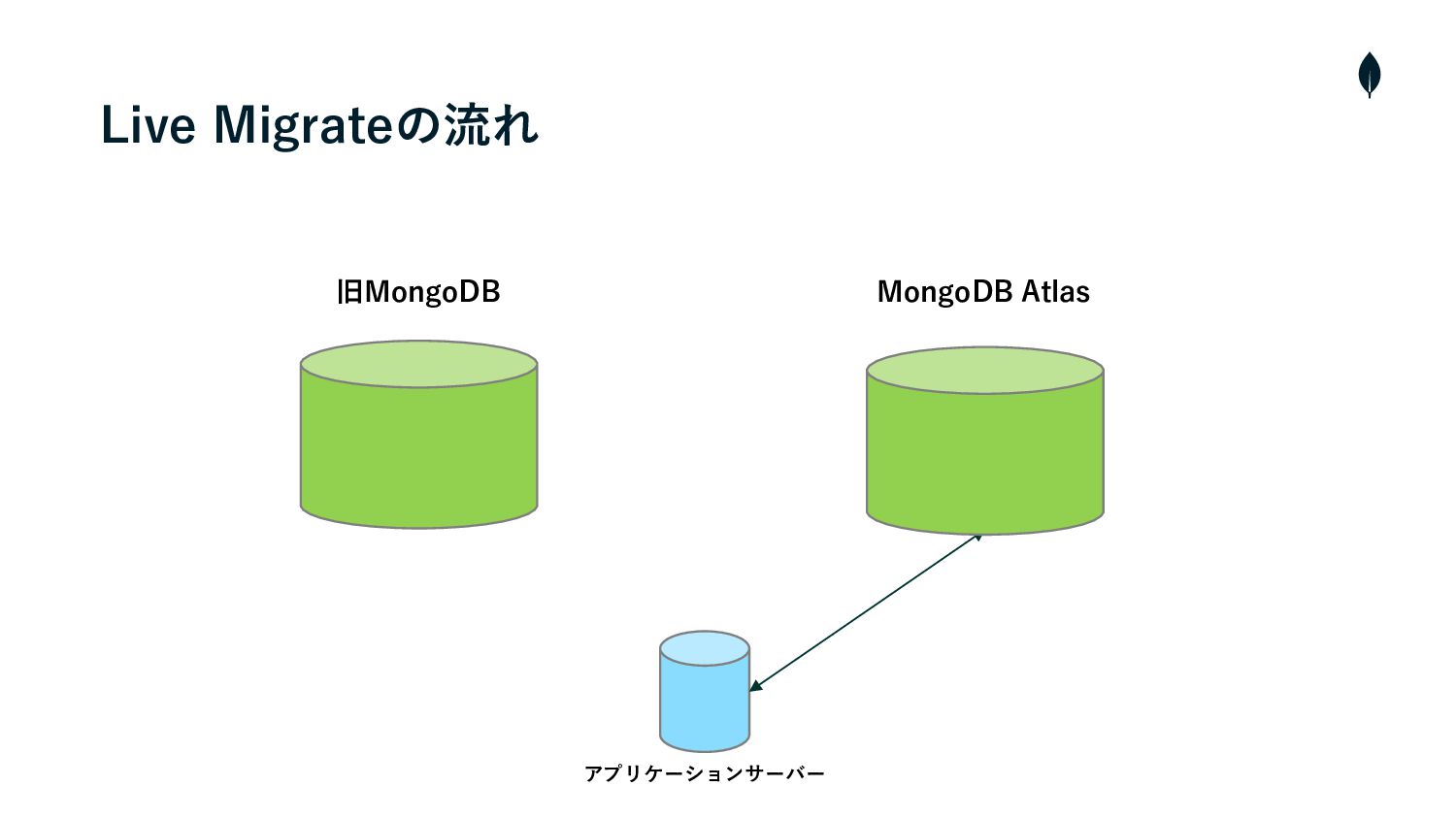
Live Migrateの流れ • クラスターの構築・Cloud ManagerとAtlasを連携 • プライベートエンドポイントを使⽤して、AtlasとソースクラスターのVMと接続 1 2 •
Live Migrateを実⾏し、ソースクラスターからAtlasへデータの初期同期を開始 3 • 両クラスター間のラグが短くなれば、メンテナンスを⼊れて、ソースクラスターへの書き込みを停⽌ 4 • カットオーバーを実⾏し、残りの増分データを同期 5 • Atlasへ接続先を変更 6 • メンテナンスを終了し、サービスを再開
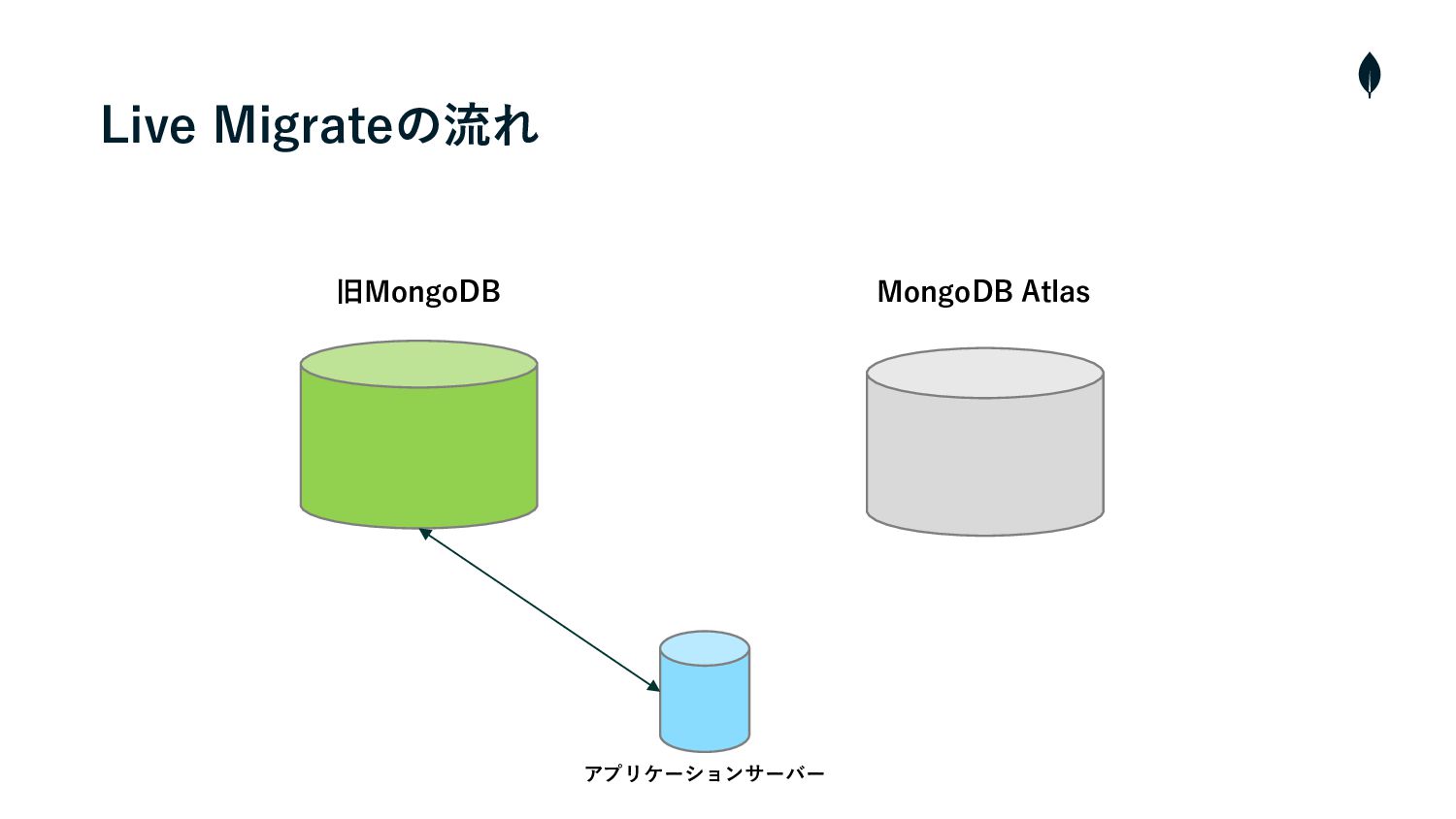
旧MongoDB MongoDB Atlas アプリケーションサーバー Live Migrateの流れ
旧MongoDB MongoDB Atlas アプリケーションサーバー Live Migrateの流れ ① Live Migrate
旧MongoDB MongoDB Atlas アプリケーションサーバー Live Migrateの流れ ① Live Migrate
① Live Migrate Live Migrateの流れ 旧MongoDB MongoDB Atlas アプリケーションサーバー カットオーバー可能
① Live Migrate Live Migrateの流れ メンテナンス 旧MongoDB MongoDB Atlas アプリケーションサーバー
カットオーバー可能
① Live Migrate Live Migrateの流れ 書き込み停止 メンテナンス 旧MongoDB MongoDB Atlas
アプリケーションサーバー カットオーバー可能
② cutover Live Migrateの流れ 書き込み停止 メンテナンス 旧MongoDB MongoDB Atlas アプリケーションサーバー
② cutover Live Migrateの流れ 書き込み停止 メンテナンス 旧MongoDB MongoDB Atlas アプリケーションサーバー
Live Migrateの流れ メンテナンス 旧MongoDB MongoDB Atlas アプリケーションサーバー
Live Migrateの流れ 旧MongoDB MongoDB Atlas アプリケーションサーバー
2. 計画 リカバリ戦略について • Atlasに何かしらの問題が発覚した時に備え、元のデータベースに切り戻すプランも考慮しないといけない • Atlasから元のMongoDBへデータ移⾏する場合は、mongosyncを逆⽅向に実⾏することで同じ要領で同期ができる • しかし、逆⽅向の同期は現在UI上での操作がサポートされていないのでCLIで⾏う必要があった •
後に説明する、負荷試験の時に逆同期の検証を⾏った
データベース移⾏の流れと移⾏戦略 検討 計画 インフラ構築 負荷試験 データ移⾏ 最適化 • Atlasについて知る •
ハンズオン • コストの⾒積もり • Atlas移⾏の意思決定 • 移⾏⽅式の設計 • 移⾏後の環境設計 • クラスター構築 • GCP-Atlas間のVPC連携 • 移⾏テスト • リカバリテスト • 負荷試験 • データ移⾏ • サービスメンテナンス • 切り替え作業 • 移⾏終了後の運⽤ • キャパシティの⾒直し • コスト最適化
3. インフラ構築 インフラはTerraformを使⽤して構築・管理 • MongoDB Atlasのプロバイダーが提供されている(https://registry.terraform.io/providers/mongodb/mongodbatlas/latest) • 後からIaC化する場合は、⼿間がかかるので初めからTerraformで作るのがおすすめ チーム内の⽅針 •
基本は全てTerraformで管理する • しかし、期間限定のスペック変更などは⼿動変更
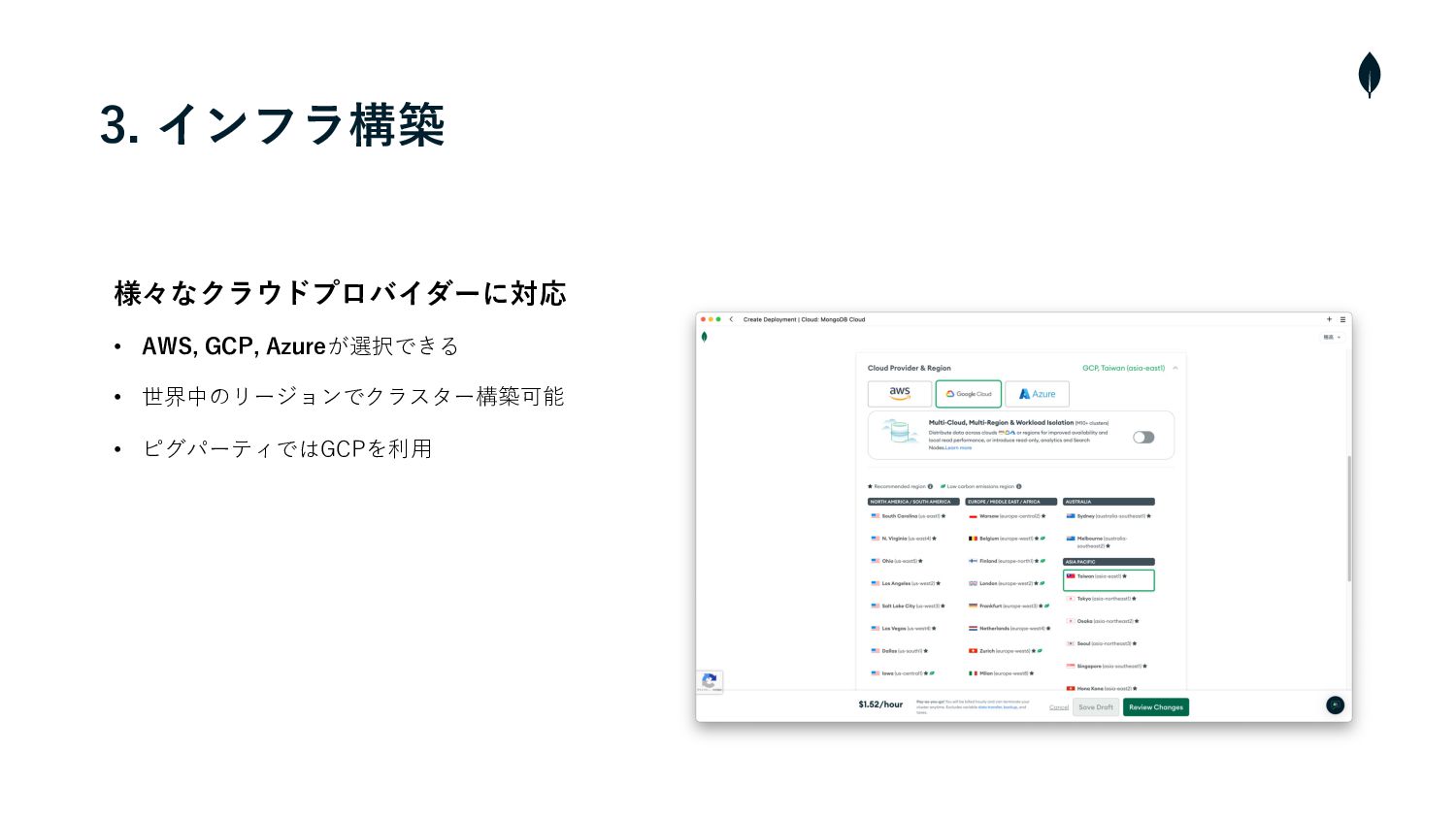
3. インフラ構築 様々なクラウドプロバイダーに対応 • AWS, GCP, Azureが選択できる • 世界中のリージョンでクラスター構築可能 •
ピグパーティではGCPを利⽤
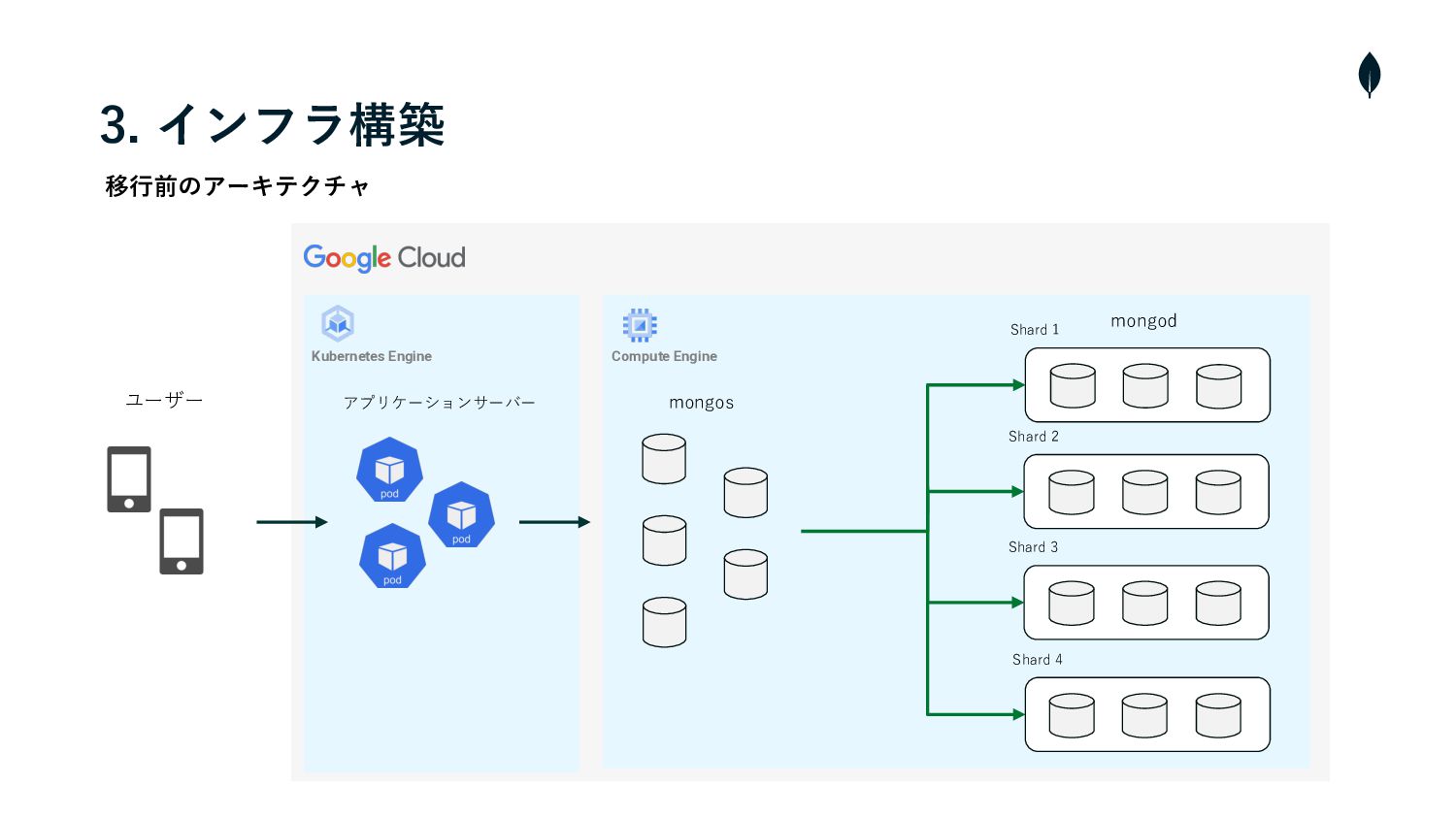
3. インフラ構築 移⾏前のアーキテクチャ Shard 1 mongos ユーザー Shard 2 Shard
3 Shard 4 Compute Engine アプリケーションサーバー Kubernetes Engine mongod
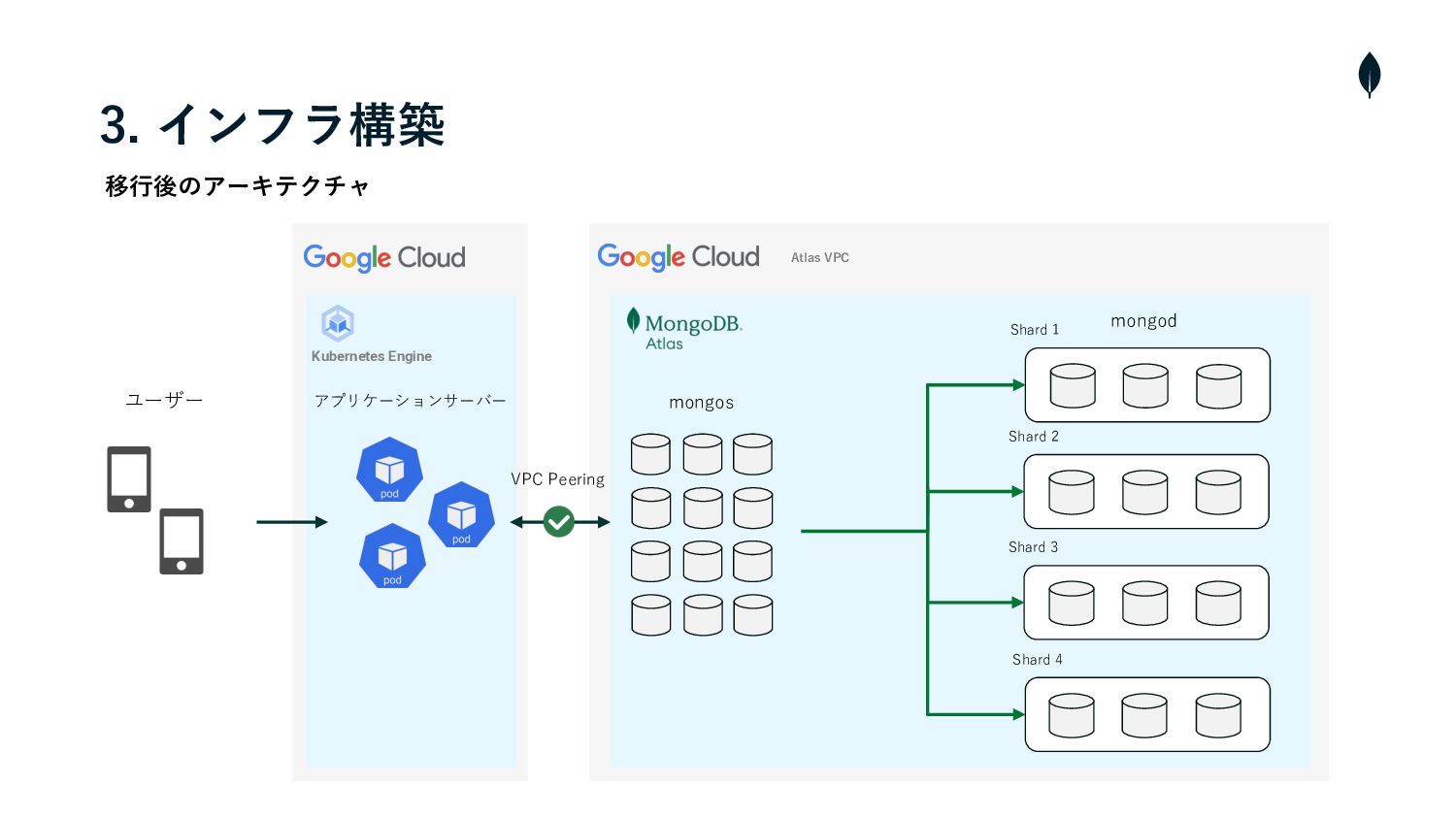
check_24.png 3. インフラ構築 移⾏後のアーキテクチャ Shard 1 Shard 2 Shard 3
Shard 4 Atlas VPC mongos Kubernetes Engine アプリケーションサーバー ユーザー mongod VPC Peering
データベース移⾏の流れと移⾏戦略 検討 計画 インフラ構築 負荷試験 データ移⾏ 最適化 • Atlasについて知る •
ハンズオン • コストの⾒積もり • Atlas移⾏の意思決定 • 移⾏⽅式の設計 • 移⾏後の環境設計 • クラスター構築 • GCP-Atlas間のVPC連携 • 移⾏テスト • リカバリテスト • 負荷試験 • データ移⾏ • サービスメンテナンス • 切り替え作業 • 移⾏終了後の運⽤ • キャパシティの⾒直し • コスト最適化
4. 負荷試験 移⾏テスト • 実際にLive Migrateがどれくらい時間かかるかを調べておく必要がある • 例えDev環境やStg環境でデータ移⾏を⾏なったとしても、本番環境とはサーバー負荷もネットワーク帯域も異なるため机上 の⾒積もりが難しい •
そのため、負荷試験環境のAtlasクラスターを⽤意し本番環境のデータからのLive Migrateを実⾏して事前検証を⾏った
4. 負荷試験 結果 • 失敗 原因 • ソースクラスタのOplogサイズが⼩さかった • Live
MigrateはOplogをもとにデータを同期するため、⼗分なOplogサイズを確保する必要がある 解消 • Oplogサイズを拡⼤する → しかし、ディスク容量にも上限があるため限界があった • 書き込みが多いバッチ処理を停⽌させる → Oplogサイズが100GB/HRが10GB/HRに短縮することができた
4. 負荷試験 結果(2回⽬) • 成功 • 1.6TBのデータ量でおよそ3時間半くらいでカットオーバーができる状態になることを確認 • 本番環境はサーバーの負荷も異なるため同じ結果になる保証はないが、実⾏時間の参考指標になった
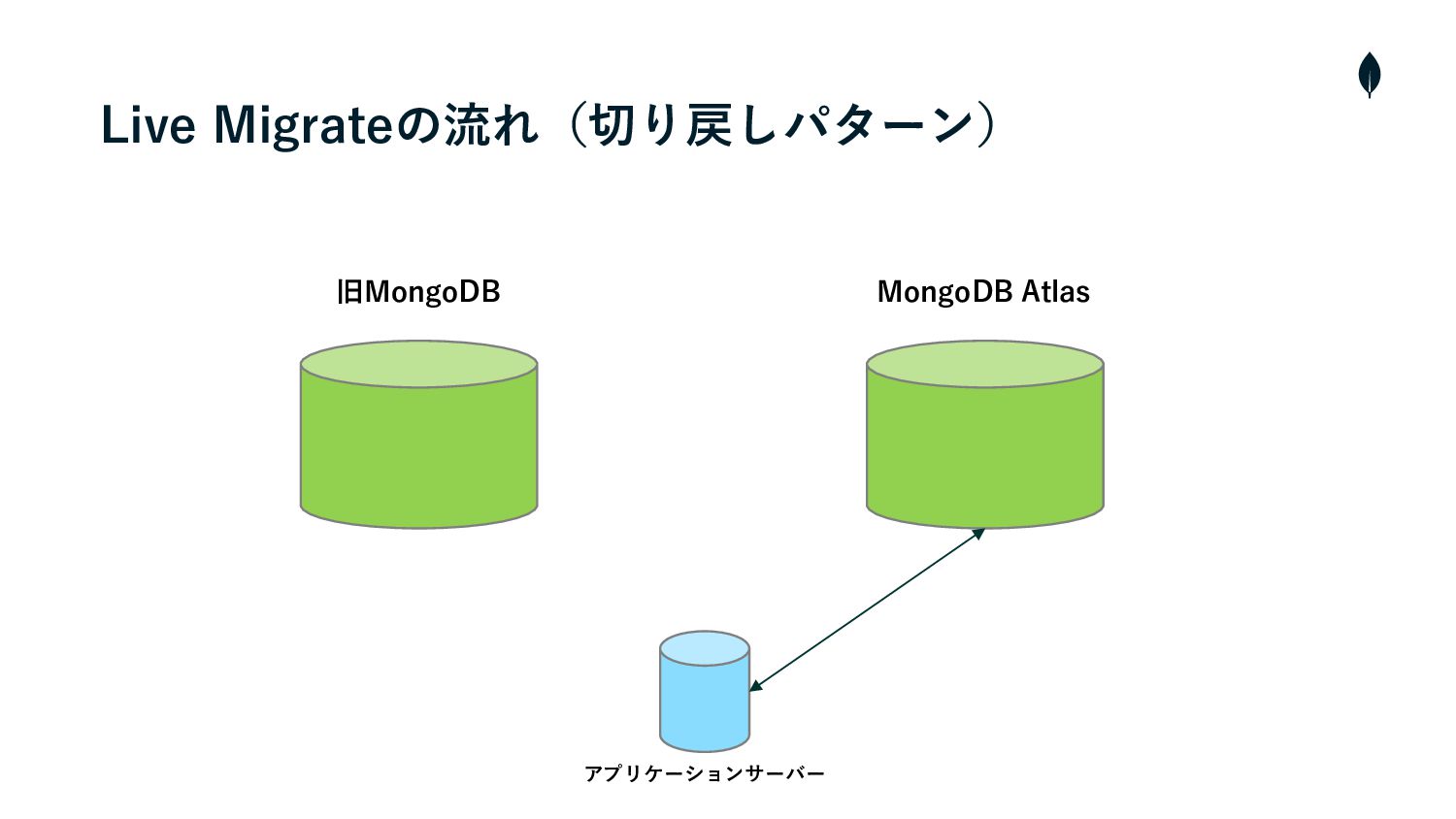
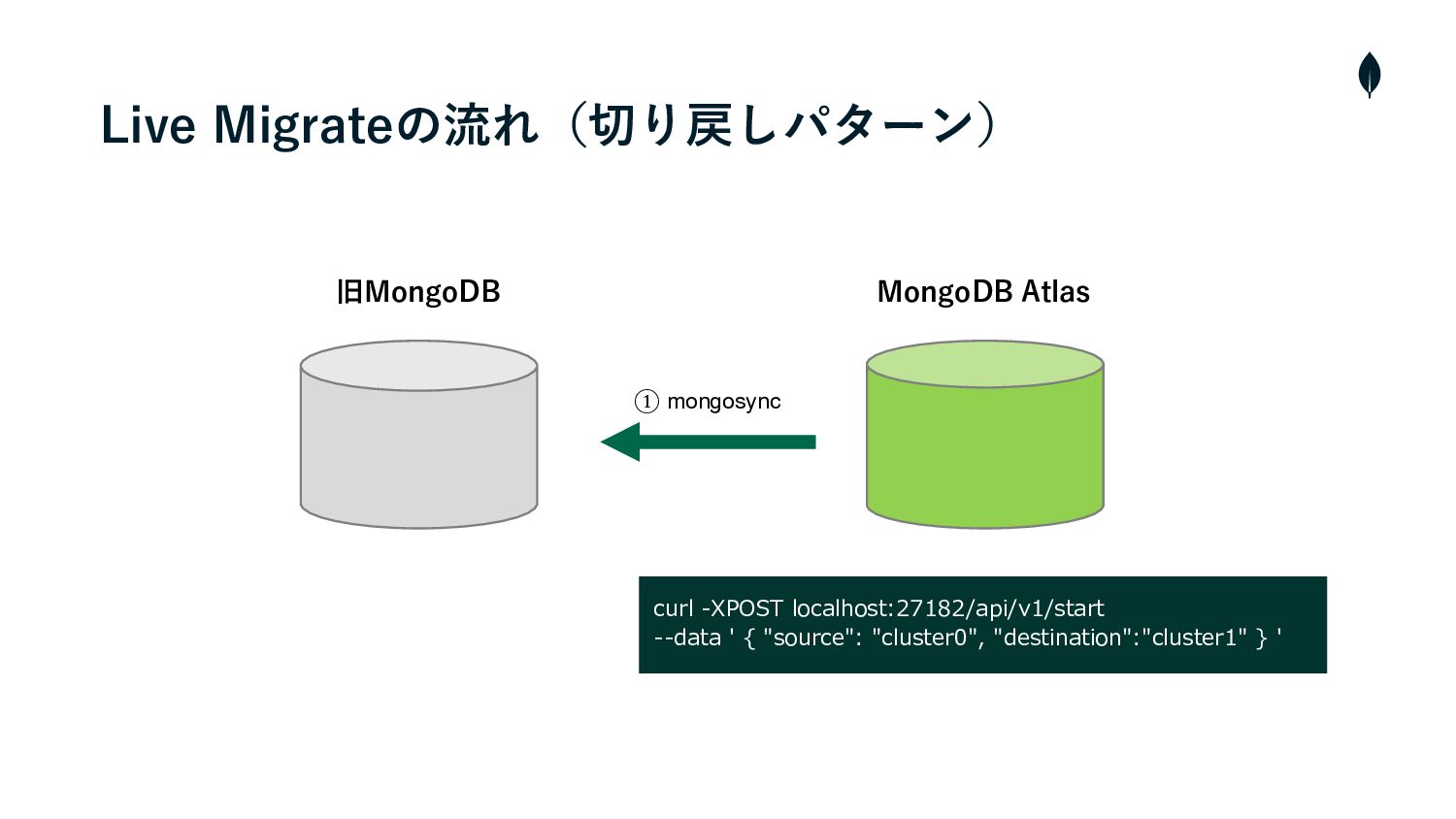
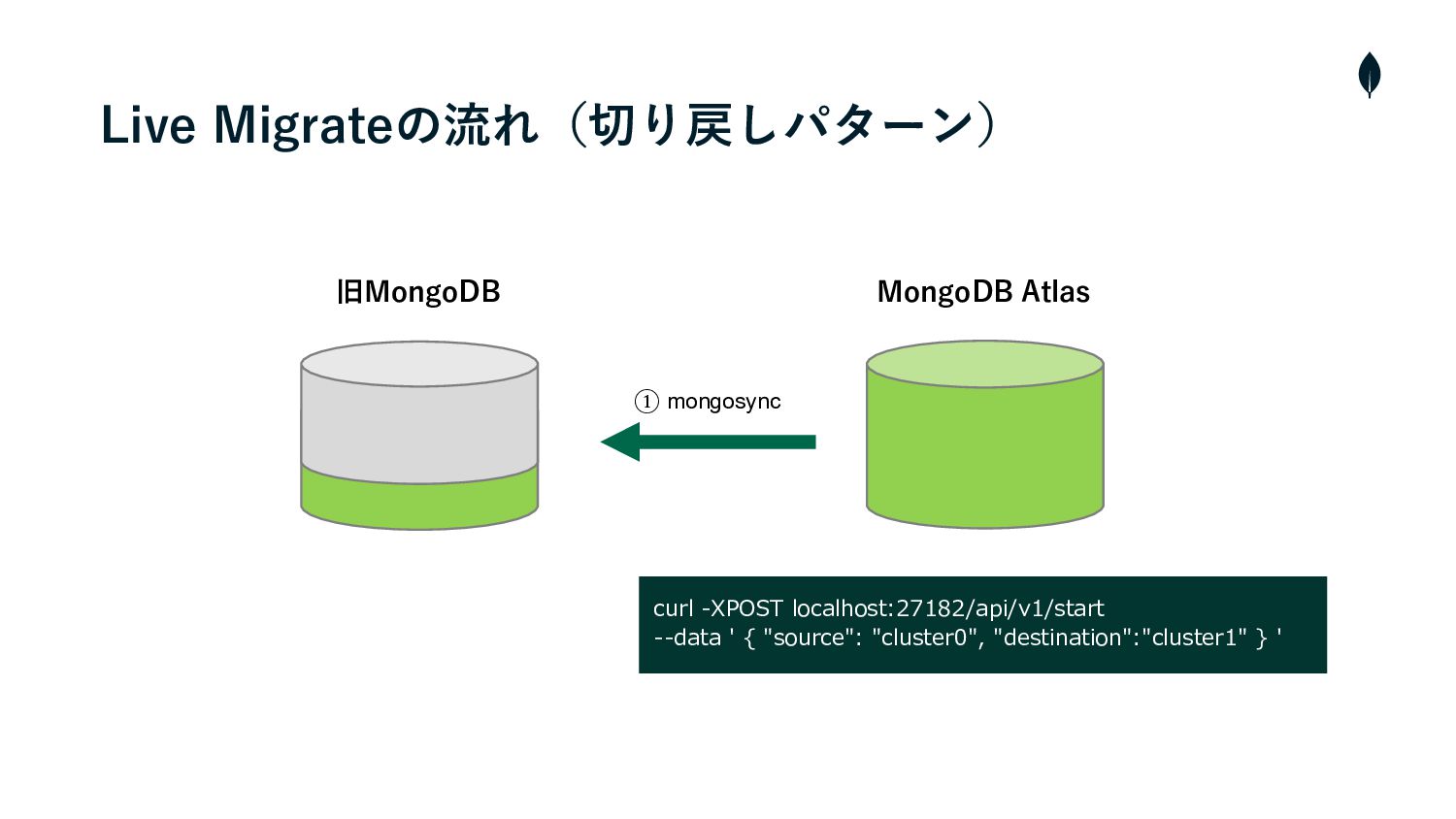
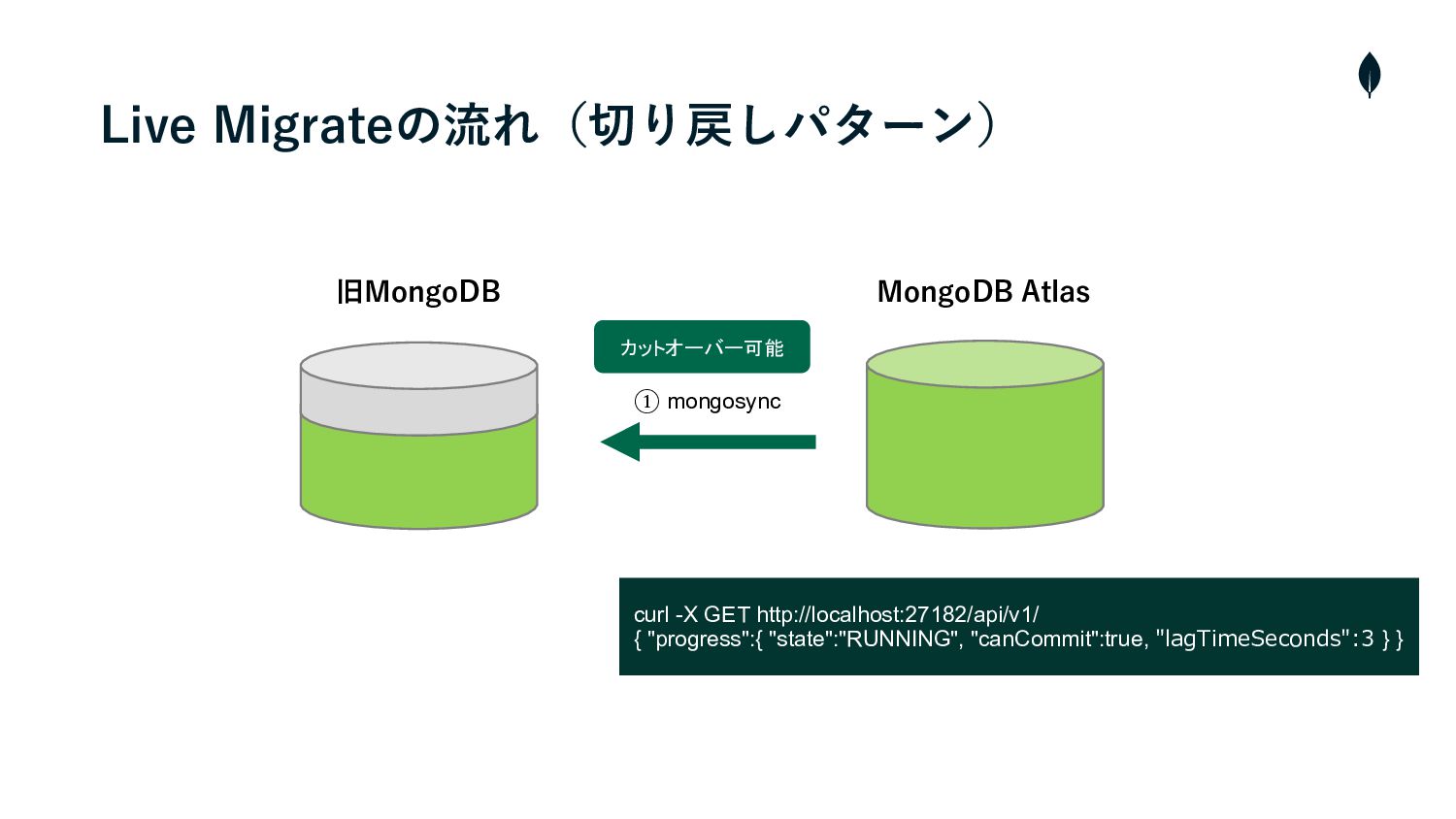
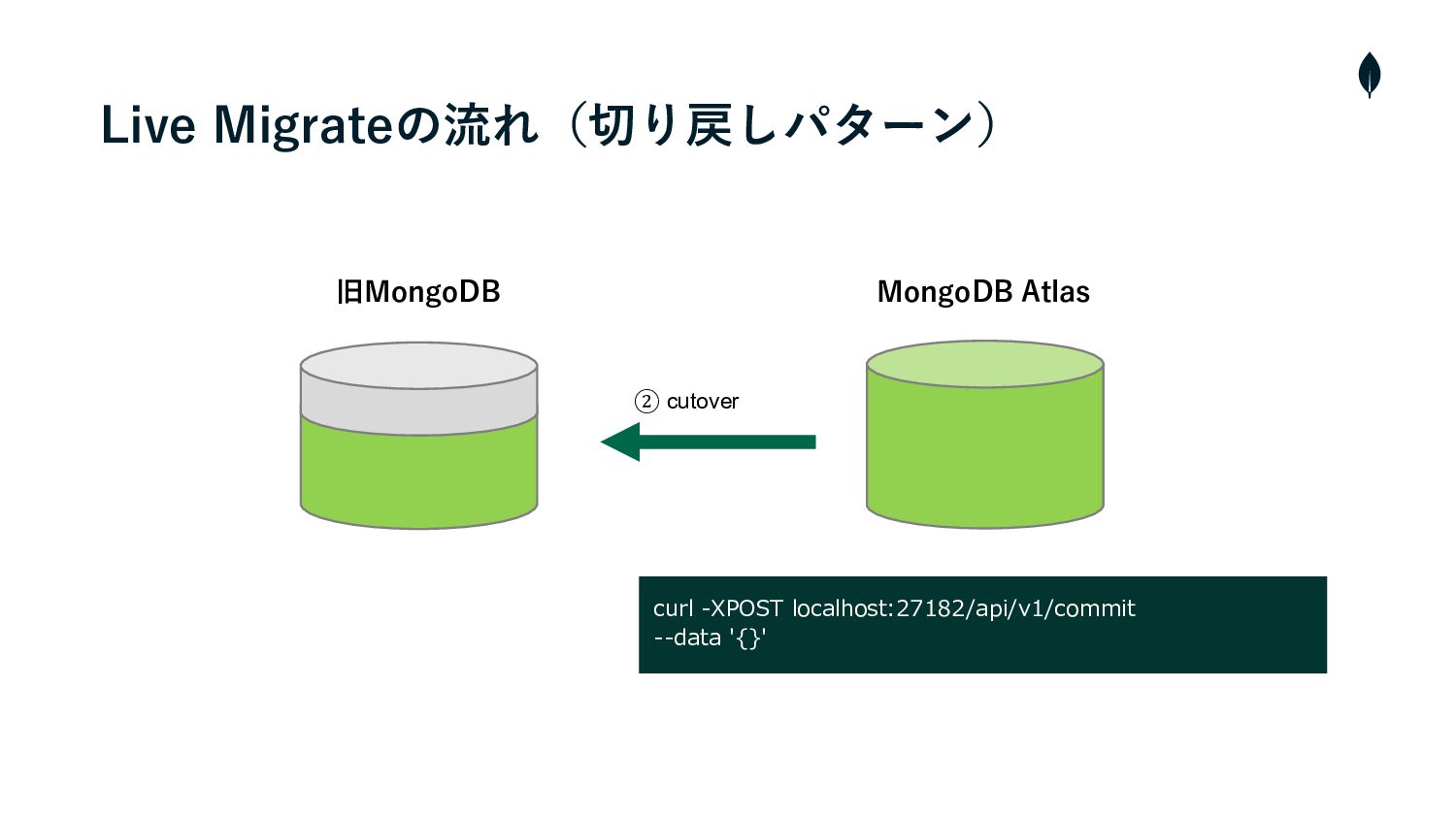
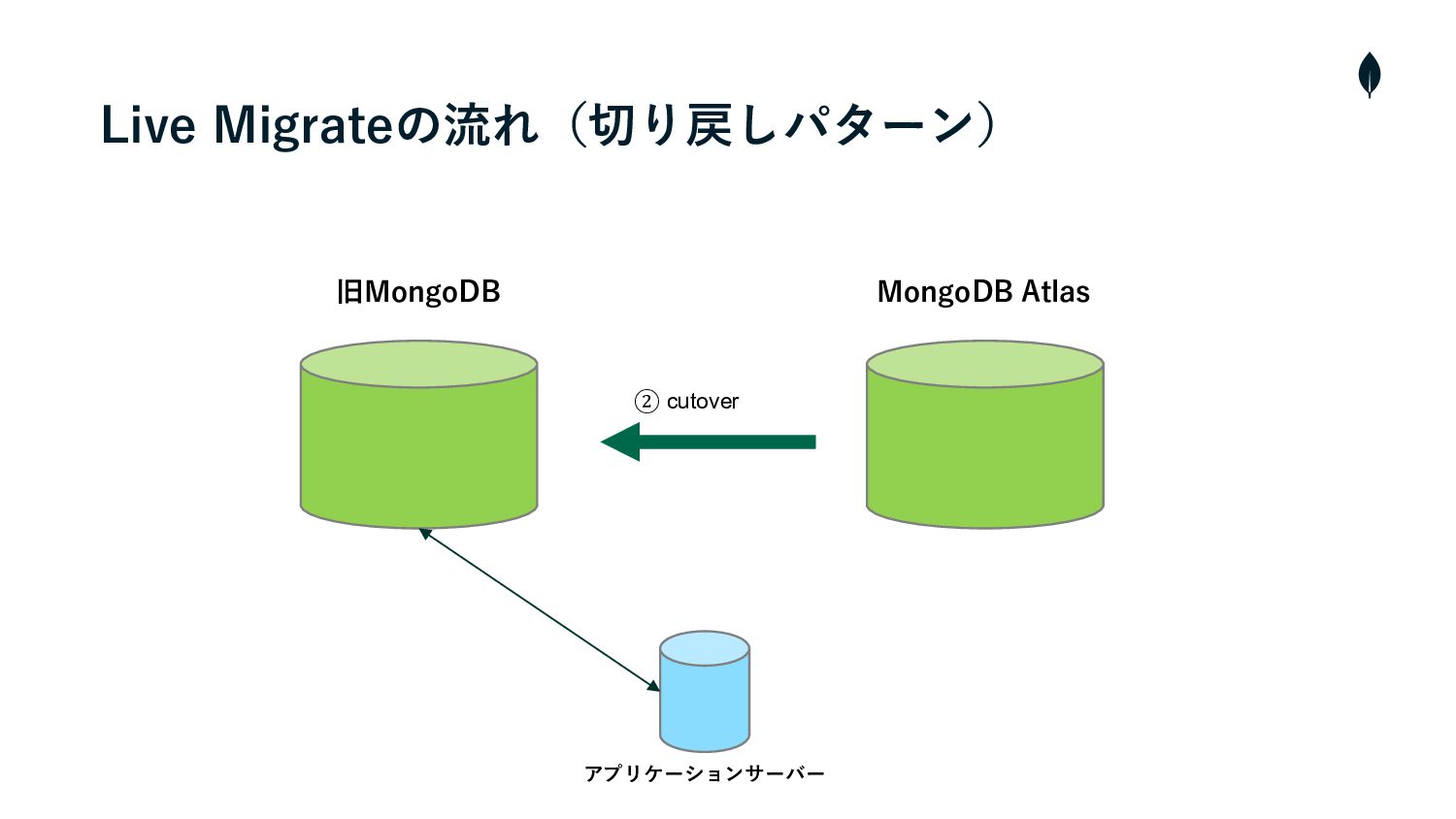
4. 負荷試験 切り戻しパターンの移⾏テスト • 切り戻しはAtlasから旧MongoDBのインスタンスに対しmongosyncをCLIから操作する必要があった • そのため、事前に負荷試験環境を使⽤してシュミレーションを⾏い操作の流れを把握しておく • また、移⾏の実⾏時間を計測しRTOを算出する •
RTO(Recovery Time Objective)とは障害発⽣時にどれくらいの時間で復旧させるかを定めた⽬標値
旧MongoDB MongoDB Atlas Live Migrateの流れ(切り戻しパターン) アプリケーションサーバー
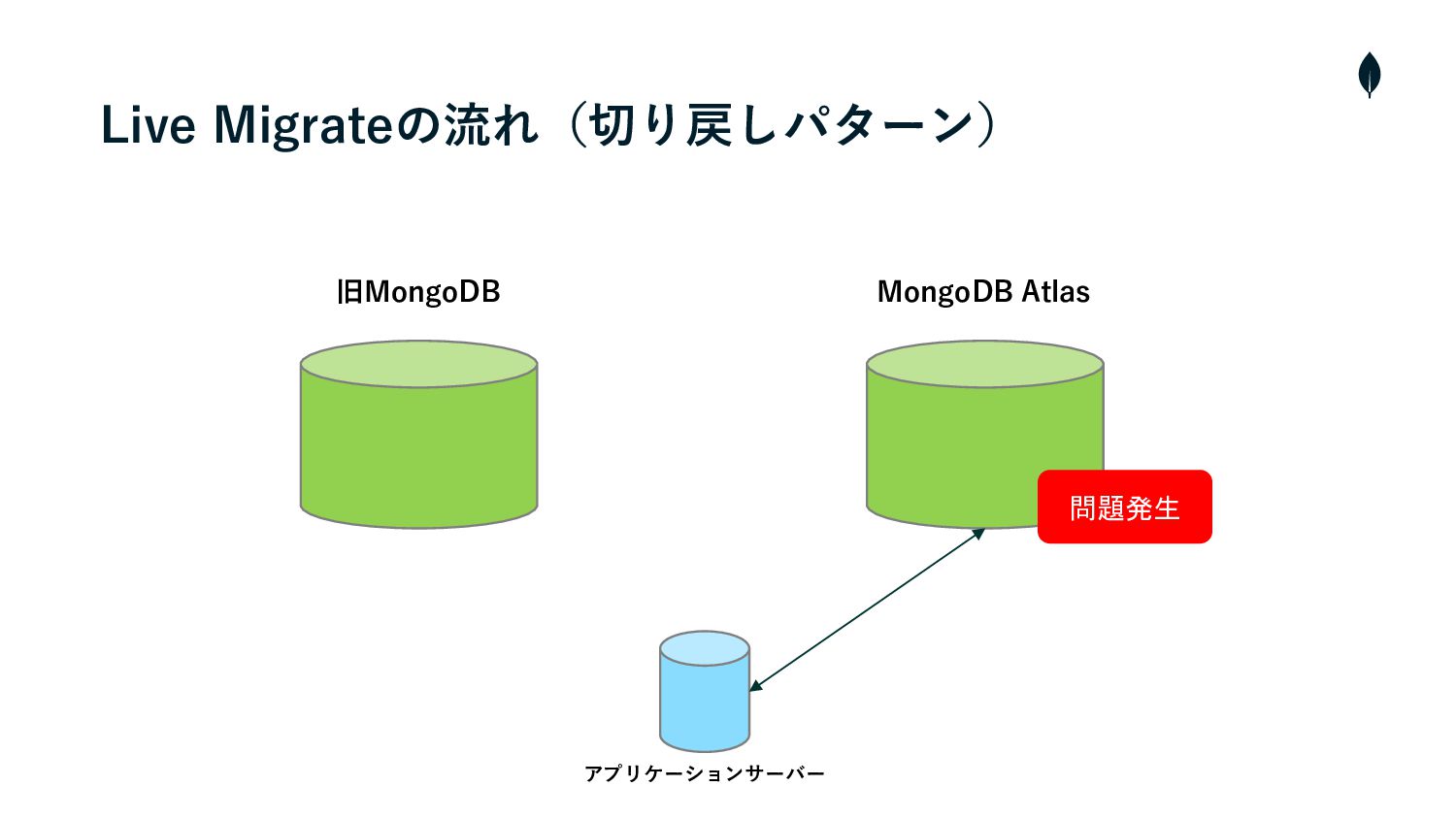
旧MongoDB MongoDB Atlas Live Migrateの流れ(切り戻しパターン) アプリケーションサーバー 問題発生
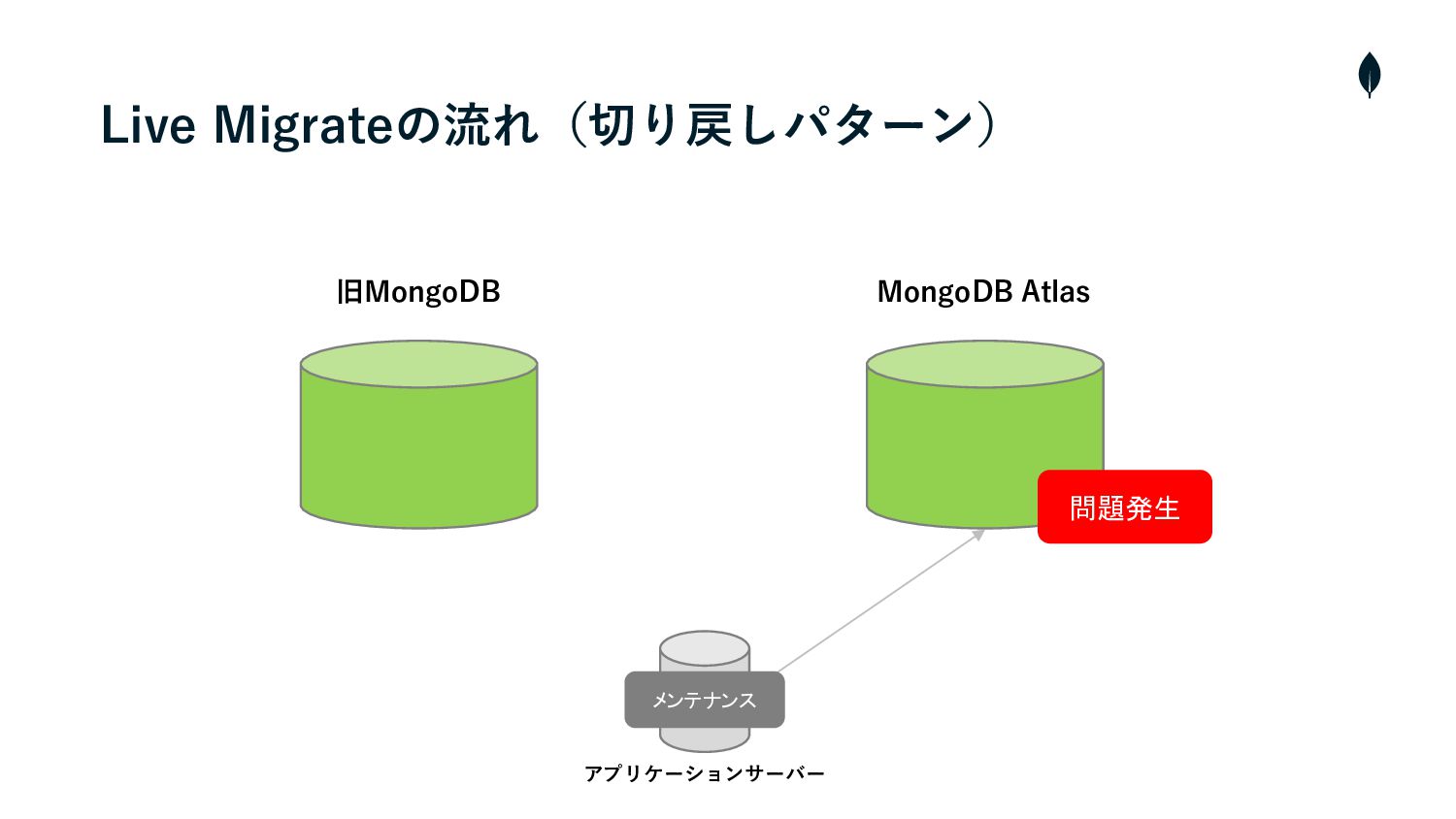
旧MongoDB MongoDB Atlas Live Migrateの流れ(切り戻しパターン) アプリケーションサーバー 問題発生 メンテナンス
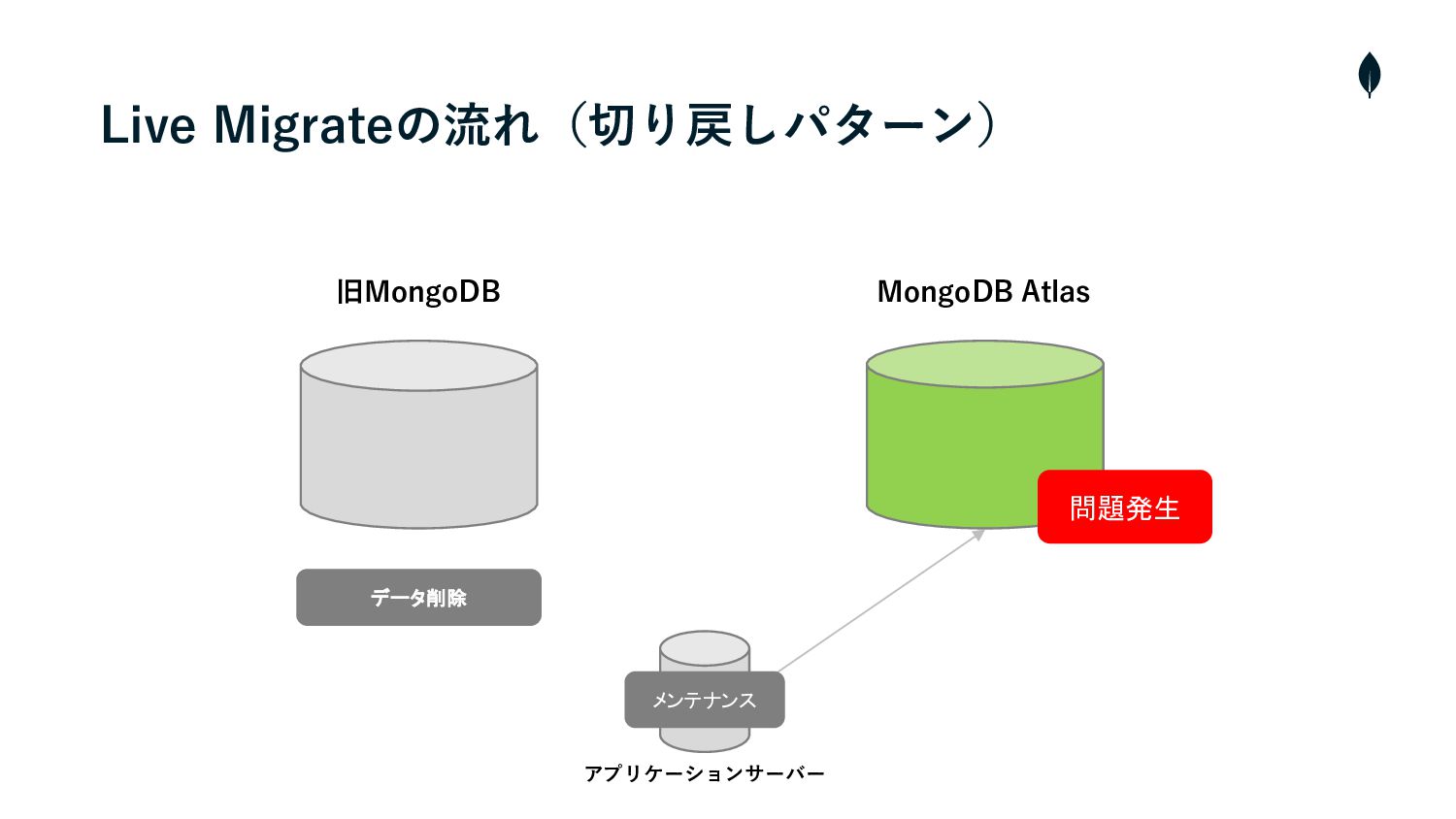
旧MongoDB MongoDB Atlas データ削除 Live Migrateの流れ(切り戻しパターン) アプリケーションサーバー メンテナンス 問題発生
旧MongoDB MongoDB Atlas ① mongosync curl -XPOST localhost:27182/api/v1/start --data '
{ "source": "cluster0", "destination":"cluster1" } ' Live Migrateの流れ(切り戻しパターン)
旧MongoDB MongoDB Atlas ① mongosync curl -XPOST localhost:27182/api/v1/start --data '
{ "source": "cluster0", "destination":"cluster1" } ' Live Migrateの流れ(切り戻しパターン)
旧MongoDB MongoDB Atlas カットオーバー可能 ① mongosync curl -X GET http://localhost:27182/api/v1/
{ "progress":{ "state":"RUNNING", "canCommit":true, "lagTimeSeconds":3 } } Live Migrateの流れ(切り戻しパターン)
旧MongoDB MongoDB Atlas ② cutover curl -XPOST localhost:27182/api/v1/commit --data '{}'
Live Migrateの流れ(切り戻しパターン)
旧MongoDB MongoDB Atlas ② cutover Live Migrateの流れ(切り戻しパターン) アプリケーションサーバー
4. 負荷試験 切り戻しパターンの移⾏テストを通して • 逆移⾏のmongosyncもおよそ3時間半ほどで完了した • つまりRTOは4時間ほどで、これがサービス影響⾯から許容できるかどうか判断する必要がありました • 移⾏前の最新バックアップからデータを復元するという⼿段もあったが、RPO(Recovery Point
Objective)、 つまり復旧時間よりもデータの⽋損をさせないことの⽅が優先度が⾼いため、切り戻しの際はサービスメンテナンスを⼊れて 再度同期し直すという⽅針に決めた • 幸い本番移⾏後は⼤きな障害がなかったため切り戻すことはなかったが、リカバリ戦略はしっかり計画しておくのが安全
4. 負荷試験 負荷試験 • ピグパーティには本番同等の構成・スペックを再現した負荷試験環境がある • Atlasに移⾏した後でも、移⾏前の同等のパフォーマンスが満たせるかどうか検証する必要があった • 旧MongoDBとAtlasのスペック・シャード数は同じ条件で⾏う •
負荷試験ツールはGatlingを使⽤ 負荷試験のパターン 1. 本番のピーク帯想定のスループットを再現したシナリオで負荷をかけて要件を満たすかどうか確認する性能テスト 2. 徐々にスループットを上げて、システムキャパシティを確認する限界テスト
4. 負荷試験 負荷試験を通してわかったこと l 旧MongoDBとAtlasの性能差 • 以前のDBとほとんど性能差はあまり無かった l コネクション数が枯渇しないようなサーバー台数とmaxPoolSizeの最適な値の確認 •
MongoDB AtlasはTierごとに最⼤コネクション数が決まっている • Node.jsはシングルスレッドでスペックアップが難しいため、負荷対策は⽔平スケールアウトを⾏う必要がある • そのため、maxPoolSizeで最⼤接続数を調整しつつ、サーバースケールの限界値も確認した
データベース移⾏の流れと移⾏戦略 検討 計画 インフラ構築 負荷試験 データ移⾏ 最適化 • Atlasについて知る •
ハンズオン • コストの⾒積もり • Atlas移⾏の意思決定 • 移⾏⽅式の設計 • 移⾏後の環境設計 • クラスター構築 • GCP-Atlas間のVPC連携 • 移⾏テスト • リカバリテスト • 負荷試験 • データ移⾏ • サービスメンテナンス • 切り替え作業 • 移⾏終了後の運⽤ • キャパシティの⾒直し • コスト最適化
Live Migrateの流れ • クラスターの構築・Cloud ManagerとAtlasを連携 • プライベートエンドポイントを使⽤して、AtlasとソースクラスターのVMと接続 1 2 •
Live Migrateを実⾏し、ソースクラスターからAtlasへデータの初期同期を開始 3 • 両クラスター間のラグが短くなれば、メンテナンスを⼊れて、ソースクラスターへの書き込みを停⽌ 4 • カットオーバーを実⾏し、残りの増分データを同期 5 • アプリケーションサーバーのDB接続先をAtlasへ変更 6 • メンテナンスを終了し、サービスを再開
Live Migrateの流れ • クラスターの構築・Cloud ManagerとAtlasを連携 • プライベートエンドポイントを使⽤して、AtlasとソースクラスターのVMと接続 1 2 •
Live Migrateを実⾏し、ソースクラスターからAtlasへデータの初期同期を開始 3 • 両クラスター間のラグが短くなれば、メンテナンスを⼊れて、ソースクラスターへの書き込みを停⽌ 4 • カットオーバーを実⾏し、残りの増分データを同期 5 • アプリケーションサーバーのDB接続先をAtlasへ変更 6 • メンテナンスを終了し、サービスを再開 メンテナンス前⽇
Live Migrateの流れ • クラスターの構築・Cloud ManagerとAtlasを連携 • プライベートエンドポイントを使⽤して、AtlasとソースクラスターのVMと接続 1 2 •
Live Migrateを実⾏し、ソースクラスターからAtlasへデータの初期同期を開始 3 • 両クラスター間のラグが短くなれば、メンテナンスを⼊れて、ソースクラスターへの書き込みを停⽌ 4 • カットオーバーを実⾏し、残りの増分データを同期 5 • アプリケーションサーバーのDB接続先をAtlasへ変更 6 • メンテナンスを終了し、サービスを再開 メンテナンス当⽇
5. データ移⾏ メンテナンス前⽇ • ⾼負荷のバッチ処理は停⽌ • Live Migrateを実施 メンテナンス当⽇ •
メンテナンスを⼊れてcutoverを実⾏ • Professional Servicesを活⽤し、メンテナンスの前⽇と当⽇でAtlasのエンジニアとのサポート体制も取るようにした 具体的なサポート内容 • メンテナンス⼿順のレビュー • Atlasクラスターのストレージサイズのベストプラクティス(マイグレーションでOplogサイズが増えるため) • バックアップ頻度のベストプラクティス • メトリクスの監視 • 常時、slackとzoomで連携できる環境
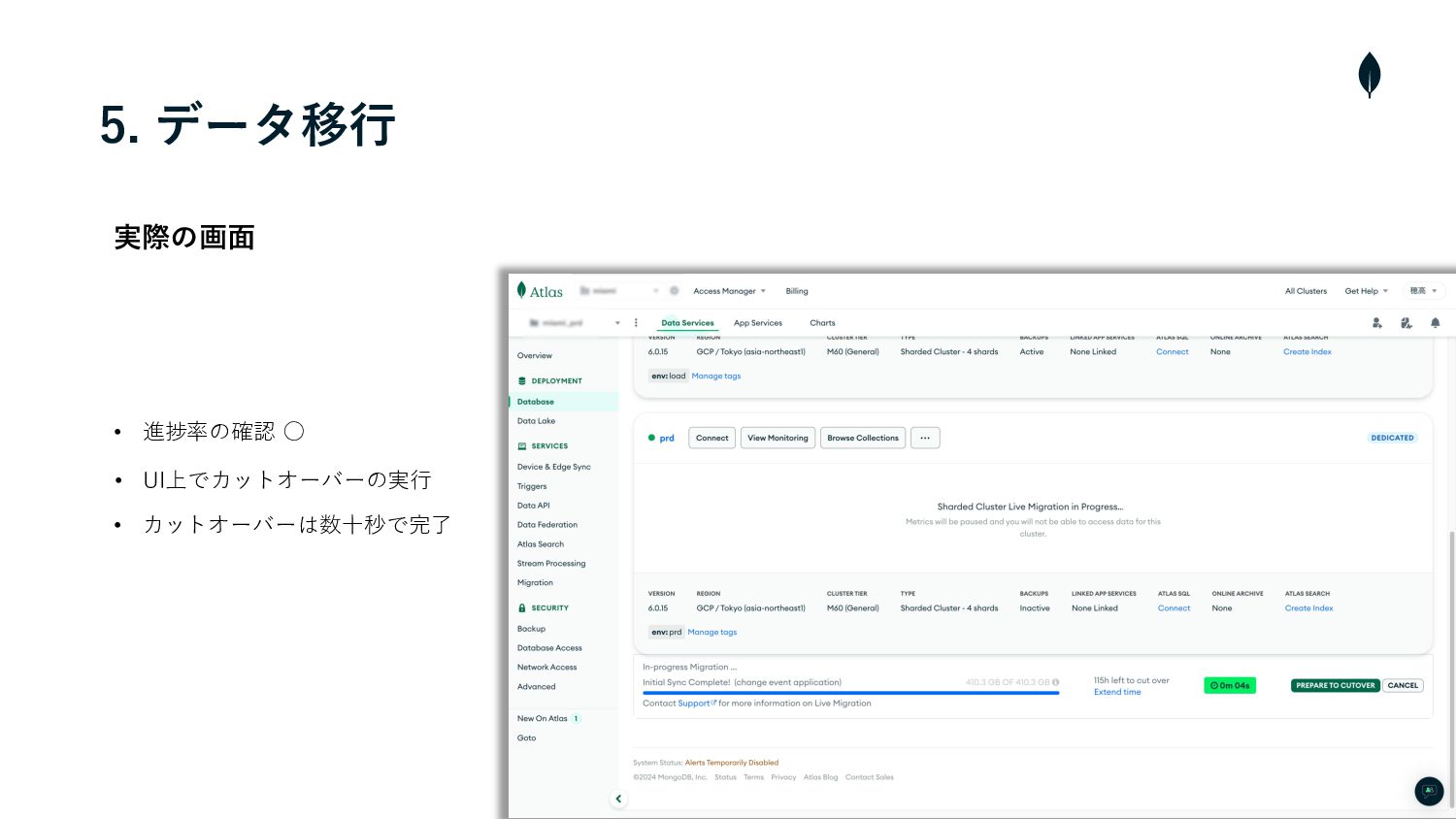
5. データ移⾏ 実際の画⾯ • 進捗率の確認 ◦ • UI上でカットオーバーの実⾏ • カットオーバーは数⼗秒で完了
データベース移⾏の流れと移⾏戦略 検討 計画 インフラ構築 負荷試験 データ移⾏ 最適化 • Atlasについて知る •
ハンズオン • コストの⾒積もり • Atlas移⾏の意思決定 • 移⾏⽅式の設計 • 移⾏後の環境設計 • クラスター構築 • GCP-Atlas間のVPC連携 • 移⾏テスト • リカバリテスト • 負荷試験 • データ移⾏ • サービスメンテナンス • 切り替え作業 • 移⾏終了後の運⽤ • キャパシティの⾒直し • コスト最適化
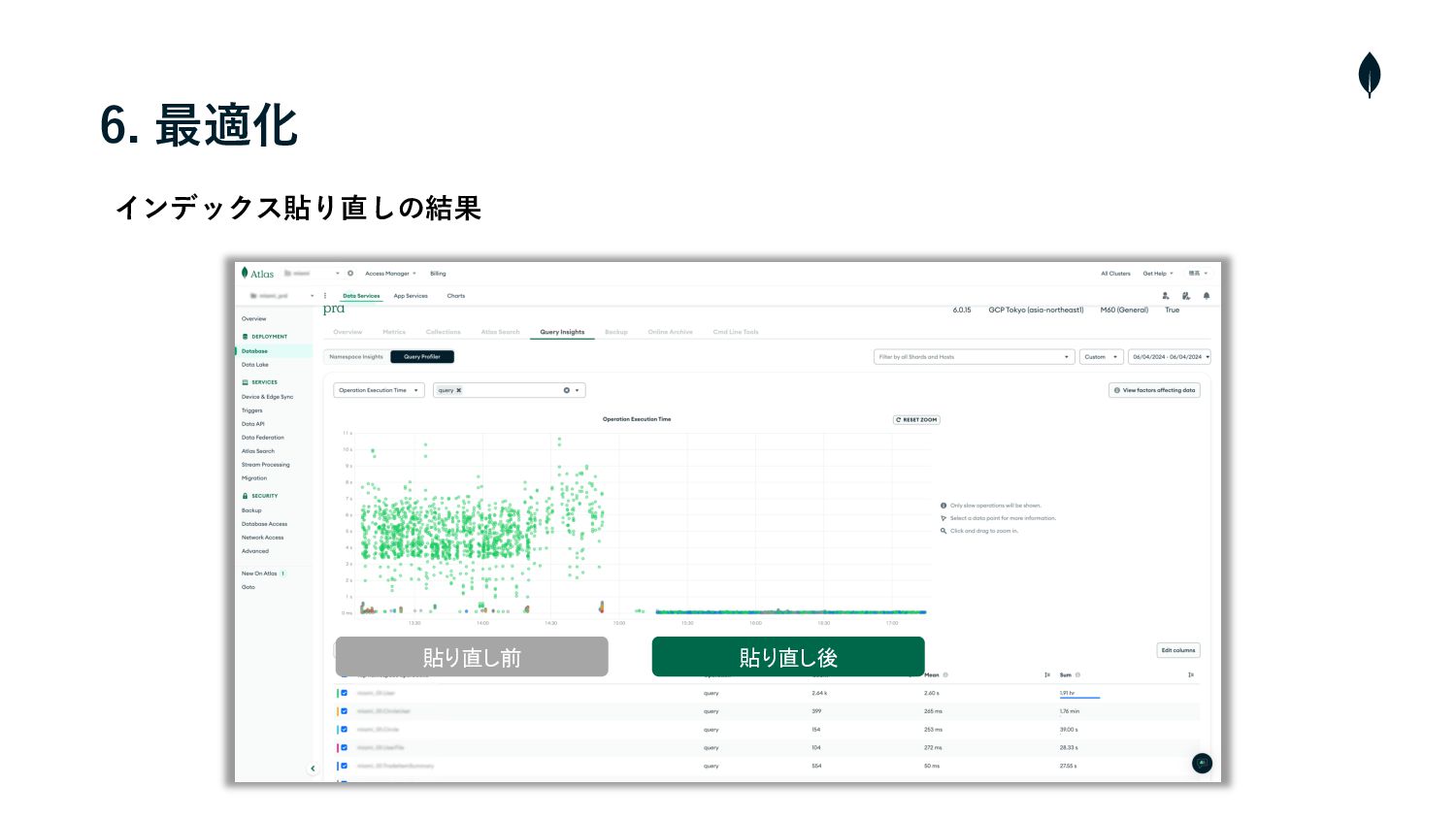
6. 最適化 最適化したこと • Atlasの機能でQuery Profilerというものがある • それを活⽤してスロークエリが発⽣しているコレクションがわかり、インデックスの貼り直しを⾏った 改善の余地がまだあるもの •
コレクションのデータサイズの⾒直し • オートスケールの活⽤によるCPUリソース配分の効率化 • クエリの呼び出し頻度の改善など...
6. 最適化 貼り直し前 貼り直し後 インデックス貼り直しの結果
まとめ
まとめ Professional Servicesを使⽤してみて ベストプラクティスの提供 • MongoDBのエンジニアの⽅とデータベースの設定やチューニングに関する最適案の提案・フィードバックが受けられる • Atlasについて何か疑問や困ったことがあれば、基本的には公式ドキュメントか過去のサポートケースから似たような事象を 探すしかなかったので、正しい情報の収集ができる 安全にマイグレーションが⾏える
• 移⾏時のメトリクス監視をリアルタイムで監視 • 課題発⽣時の迅速なトラブルシューティング
まとめ MongoDB Atlasへ移⾏してみてよかったこと 運⽤管理コストの削減 • ⼿動で⾏なっていた作業によるヒューマンエラーの防⽌ • スケールアップ、バックアップなどをAtlas側が⾃動で⾏なってくれるため、管理に費やす時間とリソースを⼤幅削減 • mongod12台
+ mongos5台のスペックアップに5時間費やしていたのが30分に短縮(操作⾃体は1分) パフォーマンスの最適化 • オートスケーリングが可能なので、パフォーマンス最適化とコスト効率が向上に繋がる • ピグパーティは時間帯によって同接数がかなり変動するサービスであるため、導⼊メリットは ◎ • プロファイル機能を活⽤しスロークエリの特定が可視化しやすくなった
まとめ 今後の課題 コストの最適化 • ピグパーティではスペックも構成も同じ状態で移⾏したので、現在の環境に合わせた最適化が求められる • また、データベース側だけでなくアプリケーション側の⾒直しを⾏い、システム全体の効率化を図っていきたい • Atlasが提供する機能やプロフェッショナルサービス活⽤しながら、今後も継続的に最適化を⾏なっていきたい
ご清聴ありがとうございました
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}