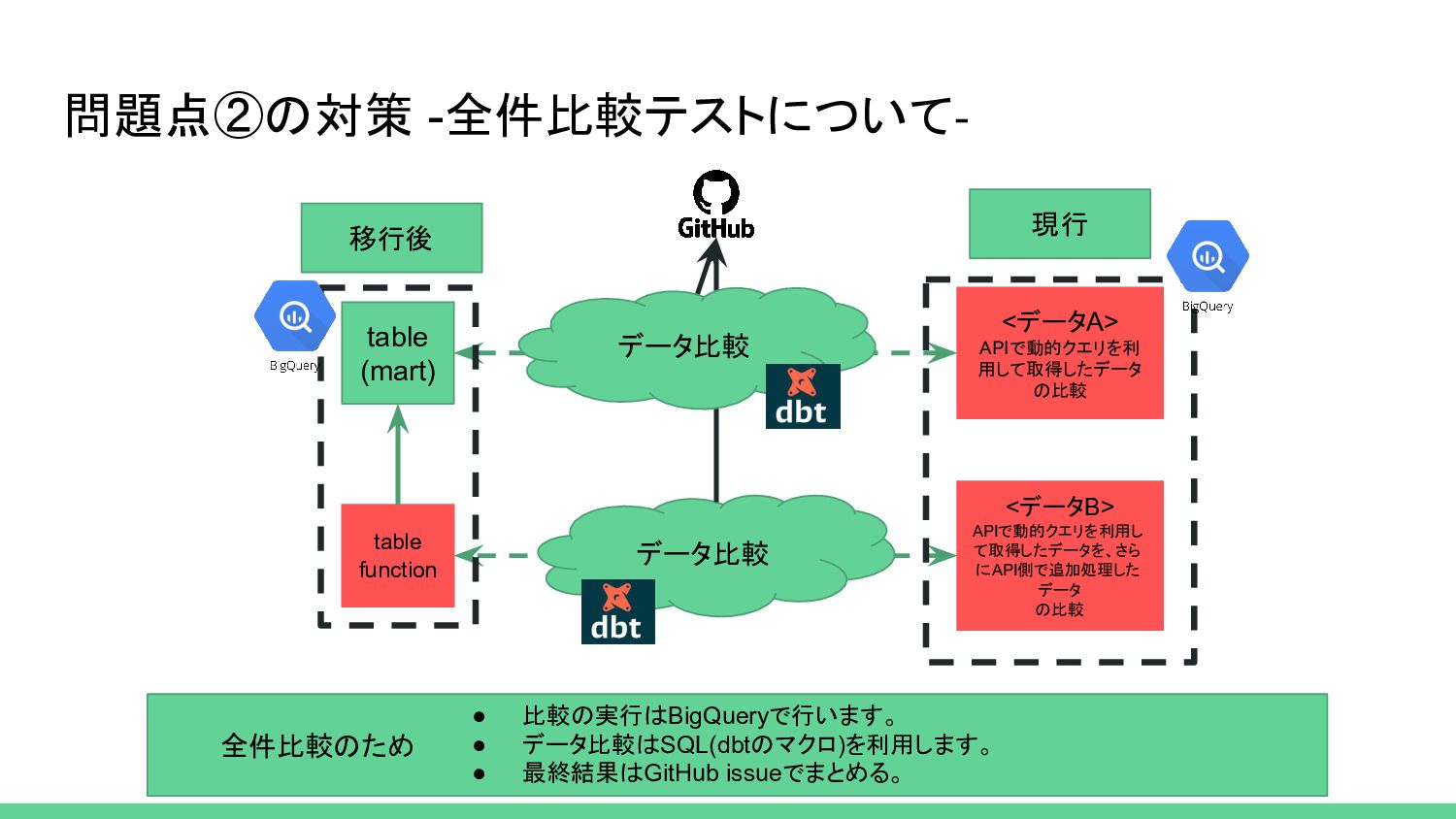
[渡したい引数] %} {% for arg in args %} {% set query %} WITH a AS ( 比較クエリ ), b AS ( 比較クエリ ), a_intersect_b AS (SELECT * FROM a INTERSECT DISTINCT SELECT * FROM b ), a_except_b AS (SELECT * FROM a EXCEPT DISTINCT SELECT * FROM b ), b_except_a AS (SELECT * FROM b EXCEPT DISTINCT SELECT * FROM a ), {# all_records AS ( SELECT *, TRUE AS in_a, TRUE AS in_b FROM a_intersect_b UNION ALL SELECT *, TRUE AS in_a, FALSE AS in_b FROM a_except_b UNION ALL SELECT *, FALSE AS in_a, TRUE AS in_b FROM b_except_a ), summary_stats AS ( SELECT in_a, in_b, COUNT(*) AS count FROM all_records GROUP BY 1,2 ) SELECT *, ROUND(100.0 * count / SUM(count) OVER (), 2) AS percent_of_total FROM summary_stats ORDER BY in_a DESC, in_b DESC #} all_records AS ( SELECT "a_intersect_b" as name, *, TRUE AS in_a, TRUE AS in_b FROM a_intersect_b UNION ALL SELECT "a_except_b" as name, *, TRUE AS in_a, FALSE AS in_b FROM a_except_b UNION ALL SELECT "b_except_a" as name, *, FALSE AS in_a, TRUE AS in_b FROM b_except_a ) select * from all_records {% endset %} {% do querys.append(query) %} {% endfor %} {{ return(querys) }} {% endmacro %} {% macro test_sample() %} {%- set ns = namespace() -%} {%- set ns.all = 0 -%} {%- set ns.error = 0 -%} {%- set ns.success = 0 -%} {%- set ns.empty = 0 -%} {%- set ns.a_except_b = 0 -%} {%- set ns.b_except_a = 0 -%} {%- set ns.no_problem = 0 -%} {%- set ns.problem = 0 -%} {%- set ns.dict_a_except_b = {} -%} {%- set ns.dict_b_except_a = {} -%} {{ log('テスト開始', true) }} {% for query in get_query() %} {%- set ns.all = ns.all + 1 -%} {% set results = run_query(query) %} {% if not results.rows[0] %} {# {{ log("戻り値なし---------------------", true) }} #} {%- set ns.empty = ns.empty + 1 -%} {% else %} {% for row in results.rows %} {% if row[0] == "a_except_b" %} {%- set ns.a_except_b = ns.a_except_b + 1 -%} {%- set id = row[1] -%} {%- do ns.dict_a_except_b.update({id:[row[2], row[3], row[4], row[5],row[6]]}) -%} {% elif row[0] == "b_except_a" %} {%- set ns.b_except_a = ns.b_except_a + 1 -%} {%- set id = row[1] -%} {%- do ns.dict_b_except_a.update({id:[row[2], row[3], row[4], row[5],row[6]]}) -%} {% else %} {%- set ns.success = ns.success + 1 -%} {% endif %} {% endfor %} {% endif %} {% endfor %} {% if ns.a_except_b == ns.b_except_a %} {% for k,v in ns.dict_a_except_b.items() %} {% if ns.dict_b_except_a[k][0] - v[0] <= 0.1 and ns.dict_b_except_a[k][1] - v[1] <= 0.1 and ns.dict_b_except_a[k][2] - v[2] <= 0.1 and ns.dict_b_except_a[k][3] - v[3] <= 0.1 and ns.dict_b_except_a[k][4] - v[4] <= 0.1 %} {%- set ns.no_problem = ns.no_problem + 1 -%} {% else %} {%- set ns.problem = ns.problem + 1 -%} {% endif %} {% endfor %} {% else %} {%- set ns.problem = ns.problem + 1 -%} {{ log('a_except_b と ns.b_except_a の不一致数が同じではないので、クエリの見直しをしてください。', true) }} {% endif %} {% set message %} テスト終了(test_{{ arg_target_month }}_3_atinsight_tvf_grows_sales_merchant_site) a_intersect_b[{{ ns.success }}] : a_except_b[{{ ns.a_except_b }}] : b_except_a[{{ ns.b_except_a }}] : empty[{{ ns.empty }}] 詳細 ::: 問題なし(カラムのいずれかに四捨五入誤差あり**それ以外の値は全て一致**)[{{ ns.no_problem }}] 問題あり(調査しましょう)[{{ ns.problem }}] {% endset %} {{ log(message, true) }} {% endmacro %} 実行は下記コマンドをshellで並列実行 *Liftのみで利用のため、実行環境は作り込みしない dbt run-operation test_sample & dbt run-operation test_sample1 & dbt run-operation test_sample2 & dbt-audit-helper を参考にクエリを作成 *取得データが用途によって異 なるため、dbt-audit-helperをそ のまま利用することができなかっ たです。 *マクロでテストができるので、 テストをすることが非常に楽にな りました。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
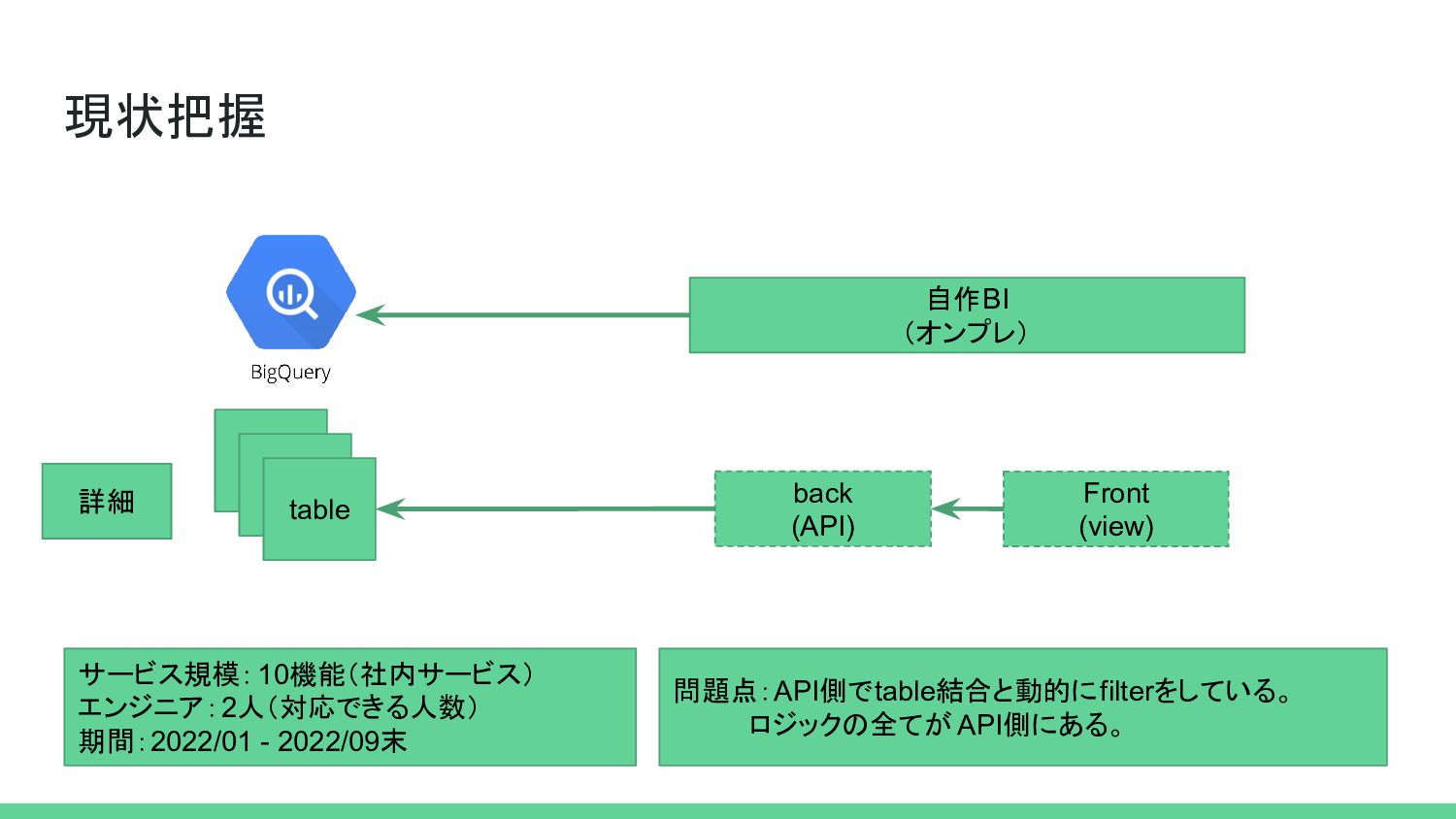{kind=link}
{kind=link}
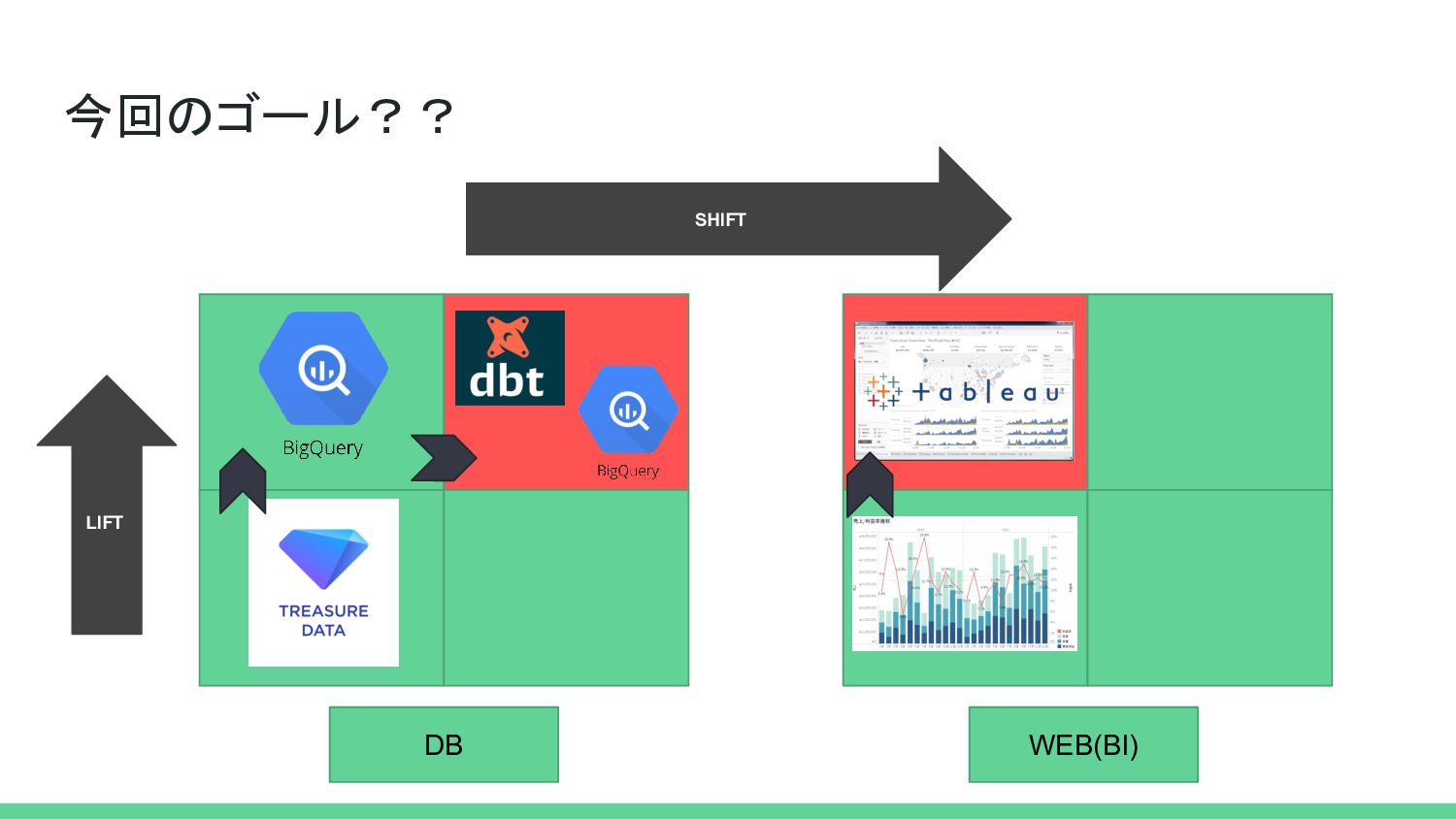{kind=link}
{kind=link}
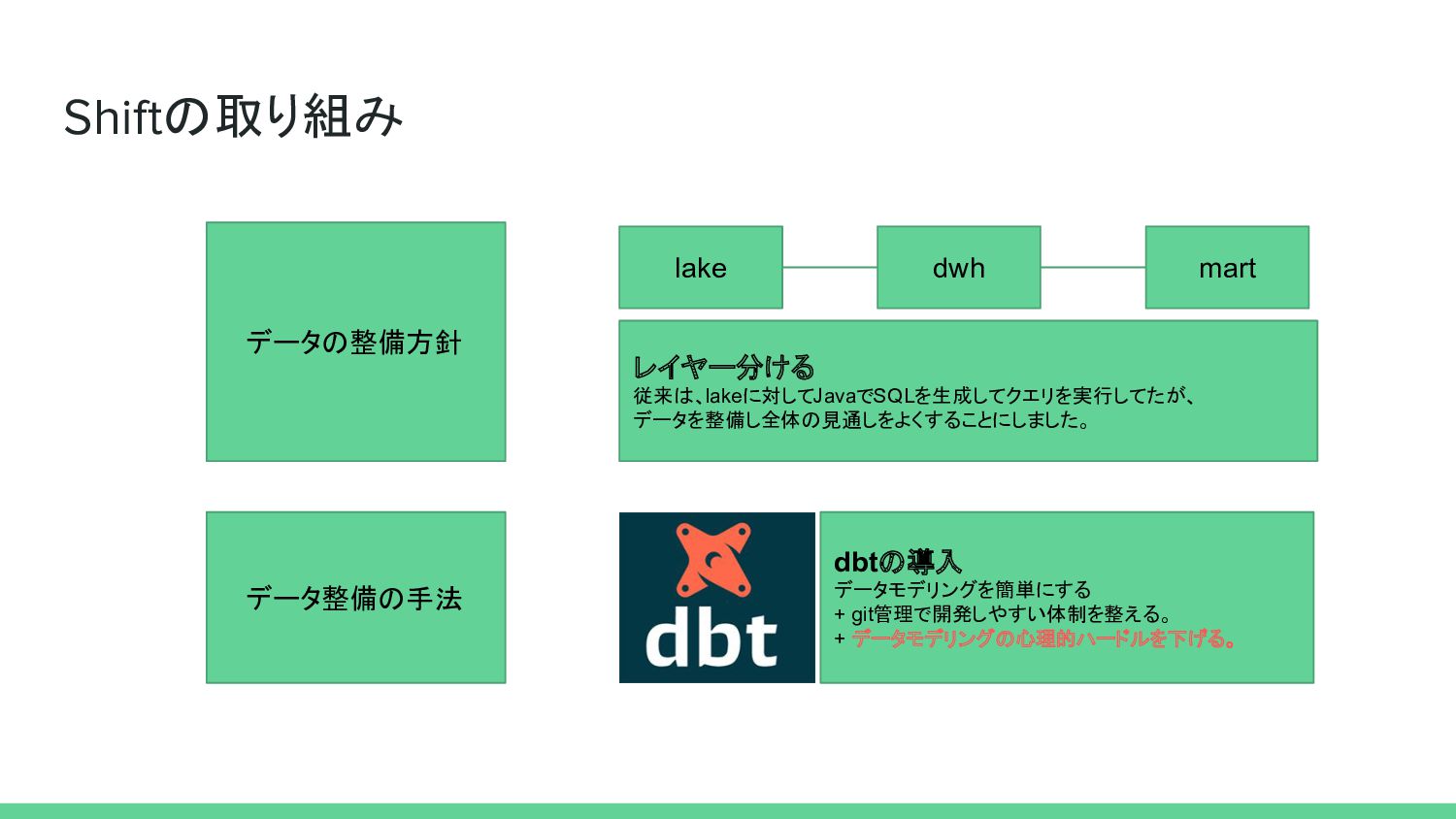{kind=link}
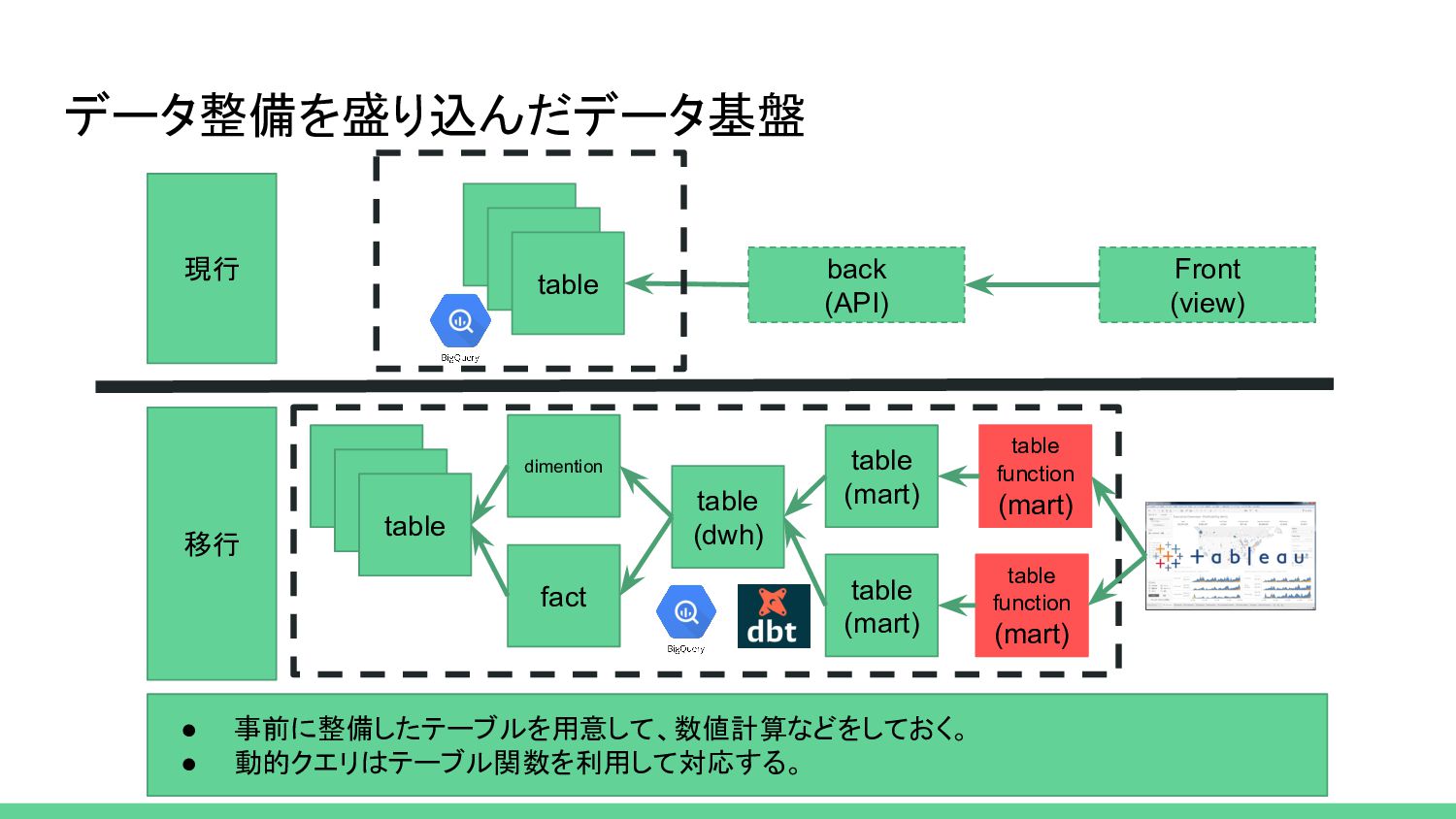{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}