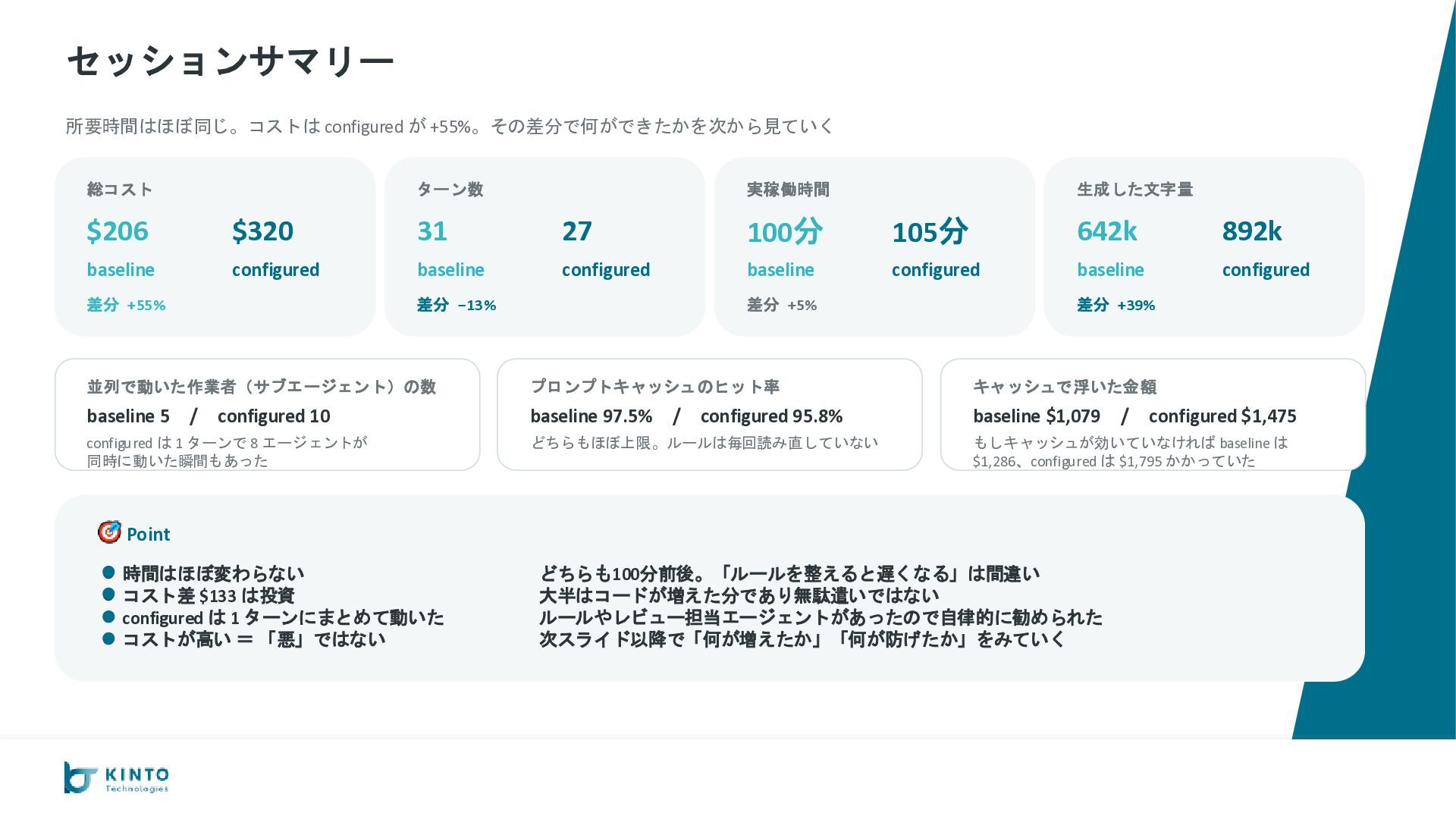
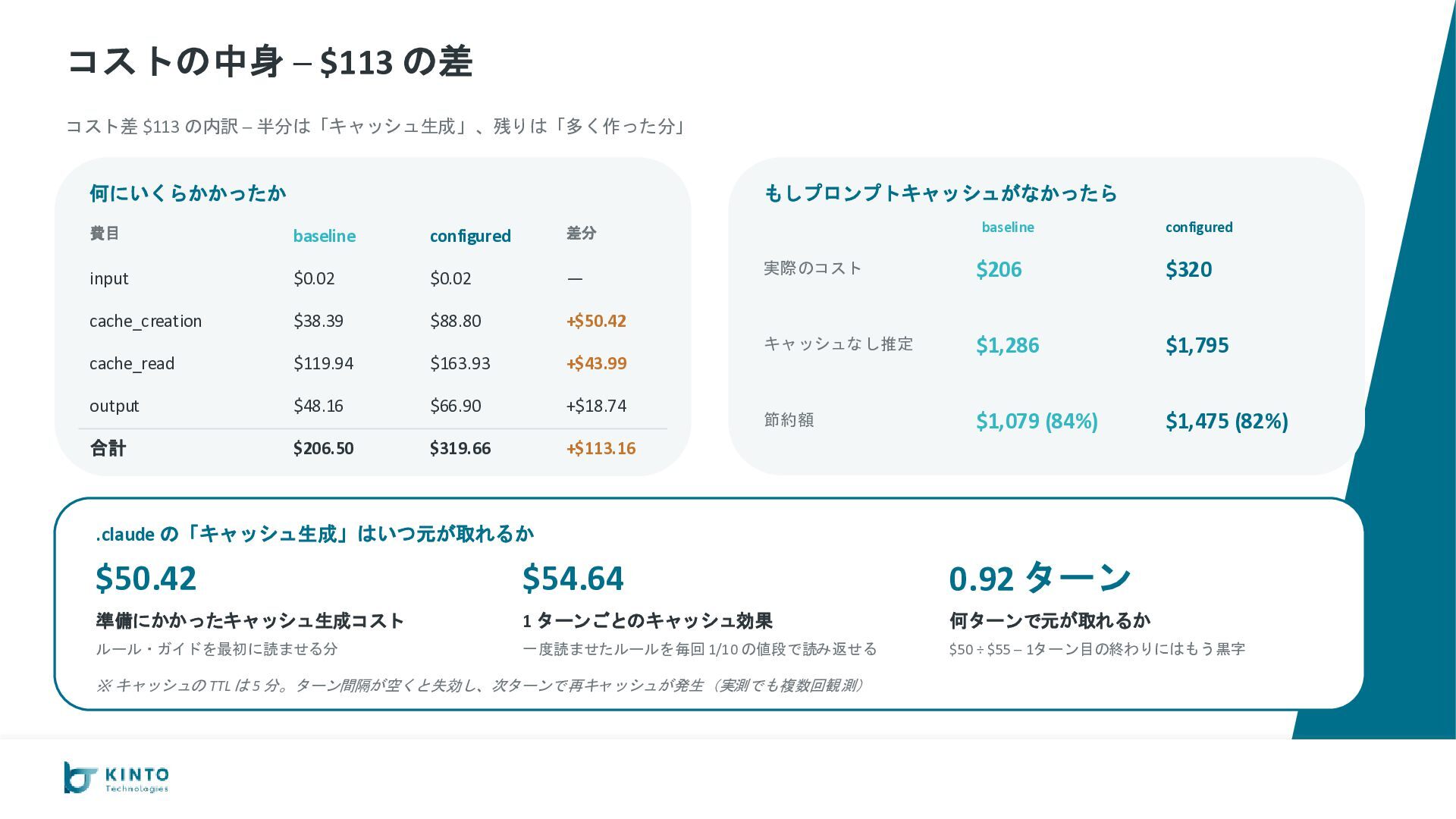
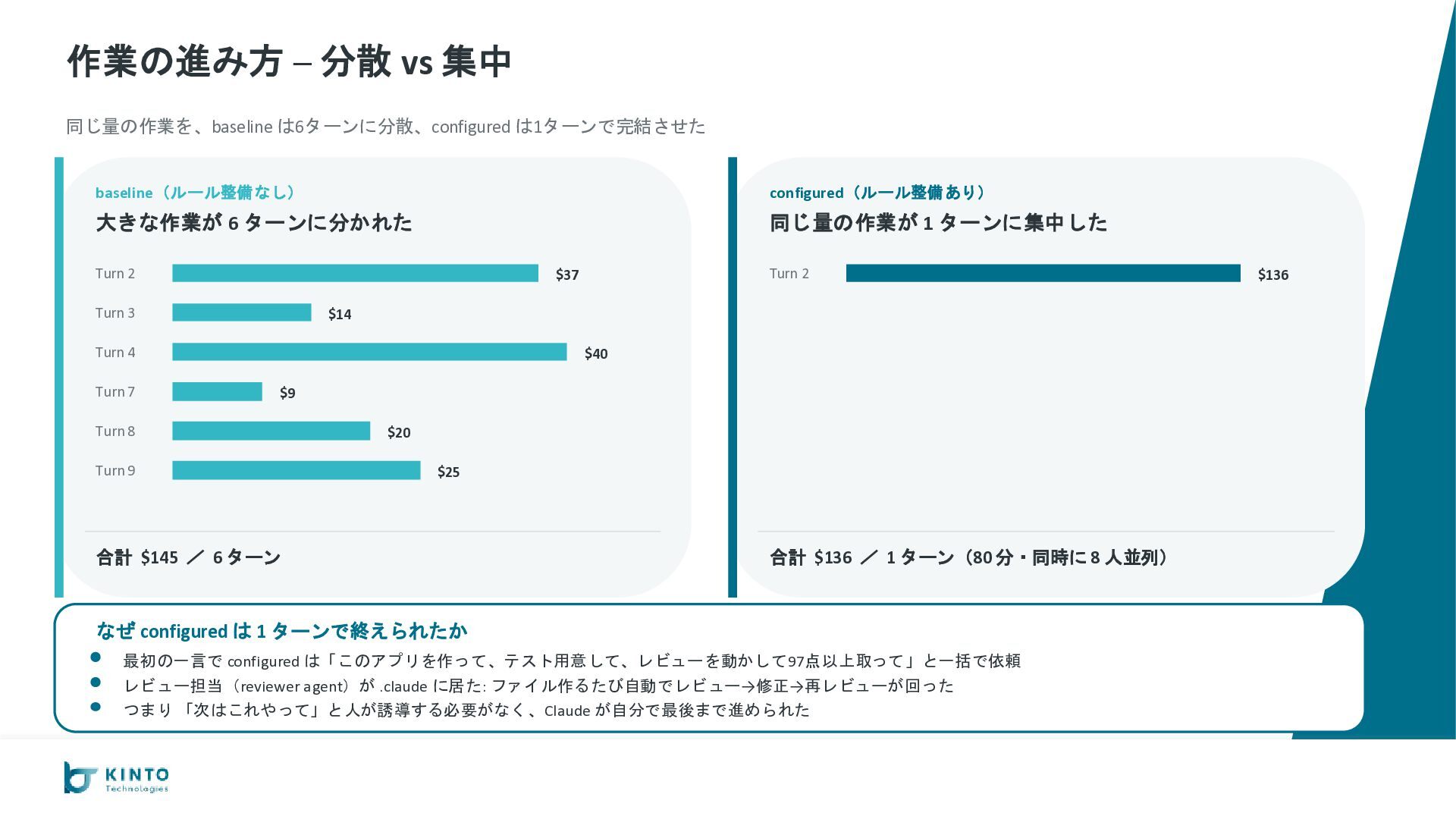
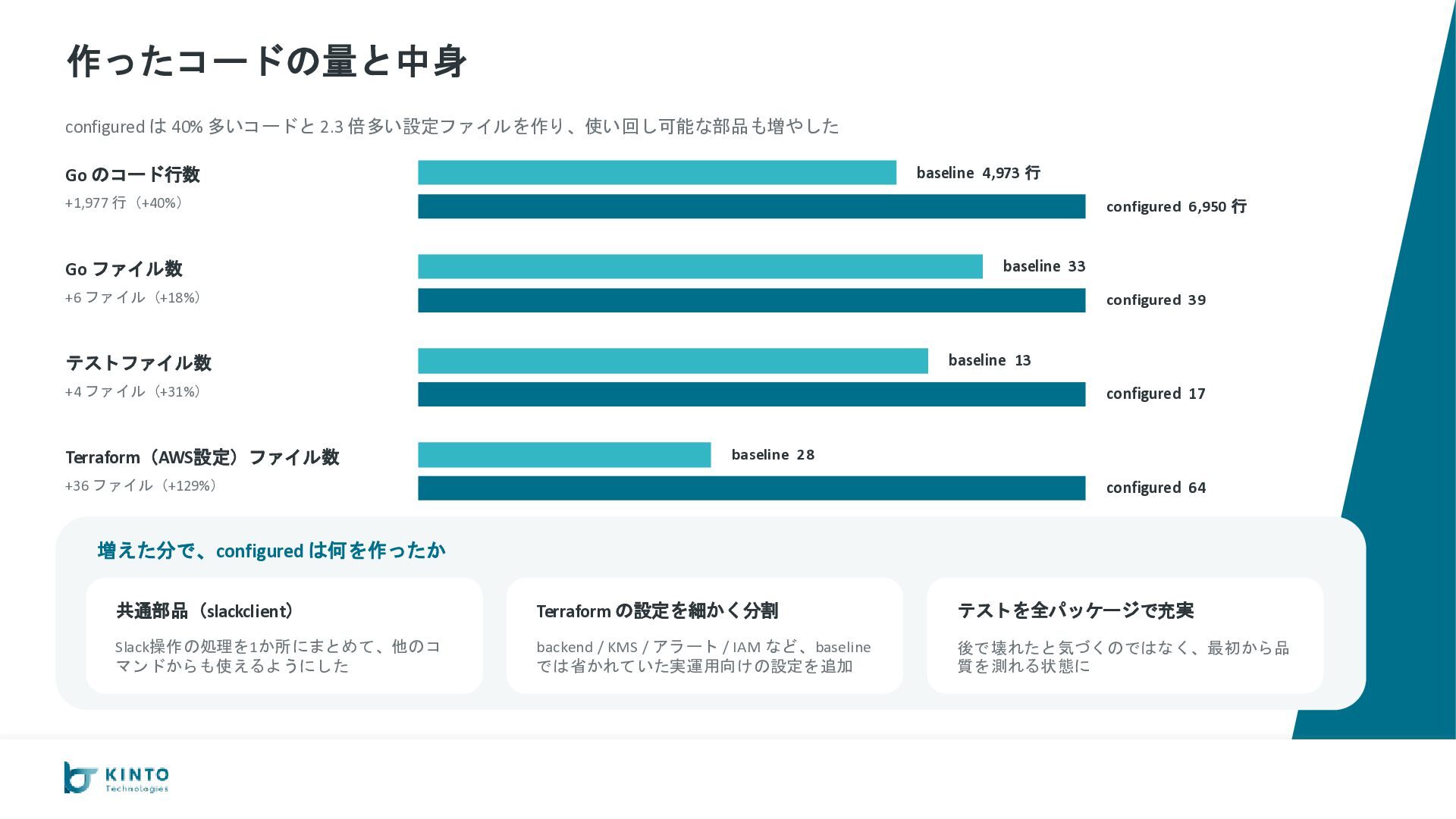
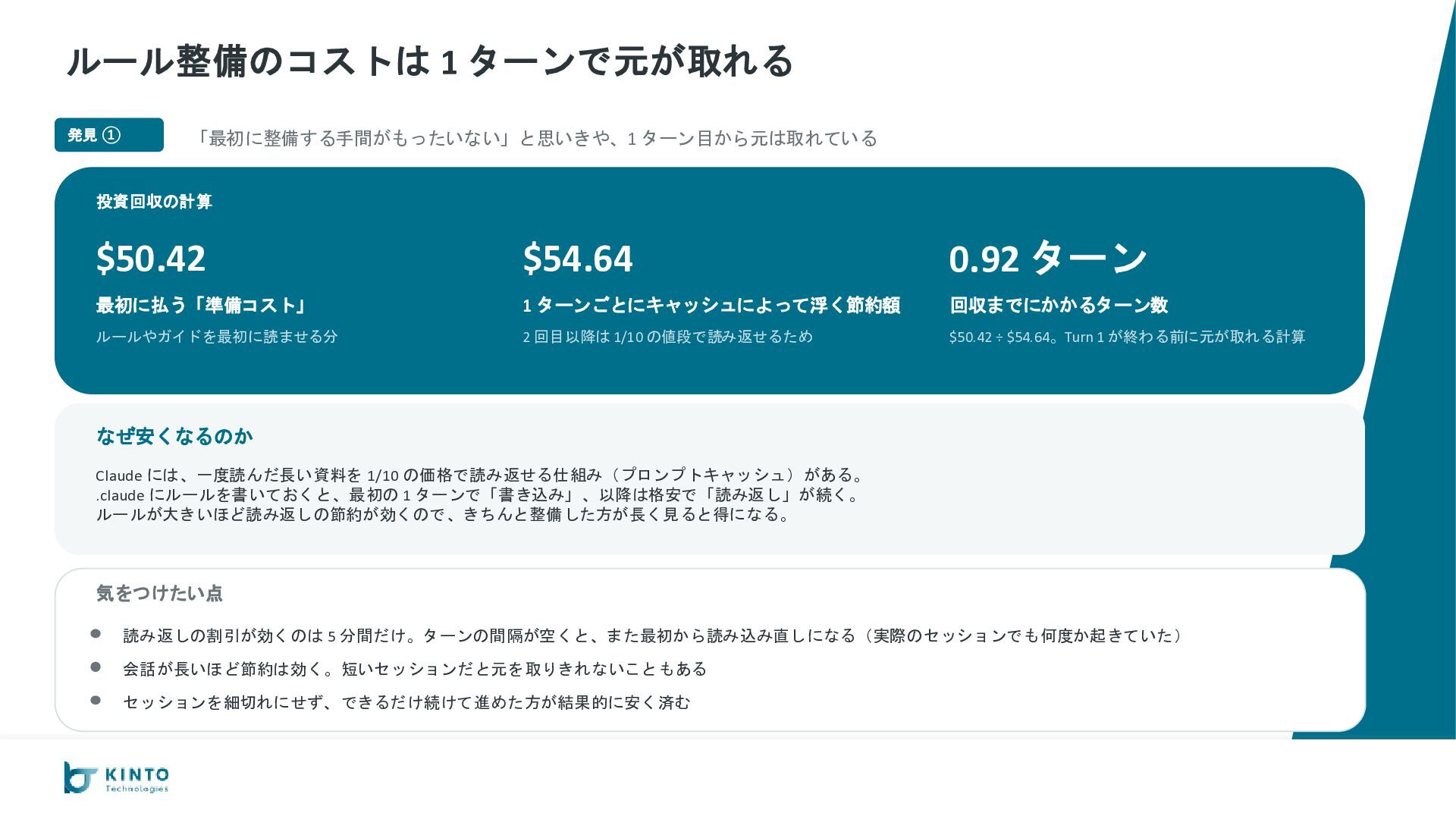
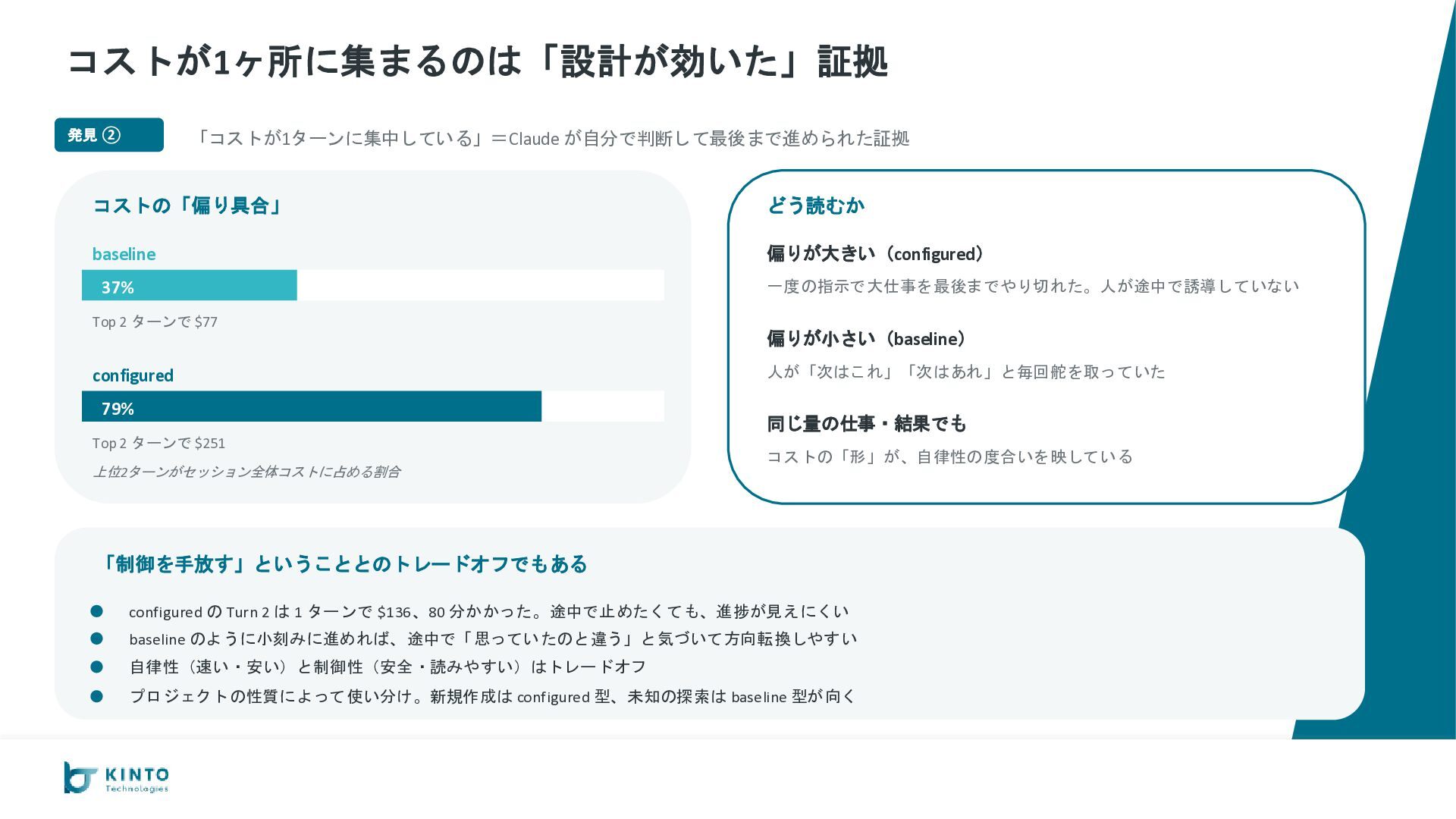
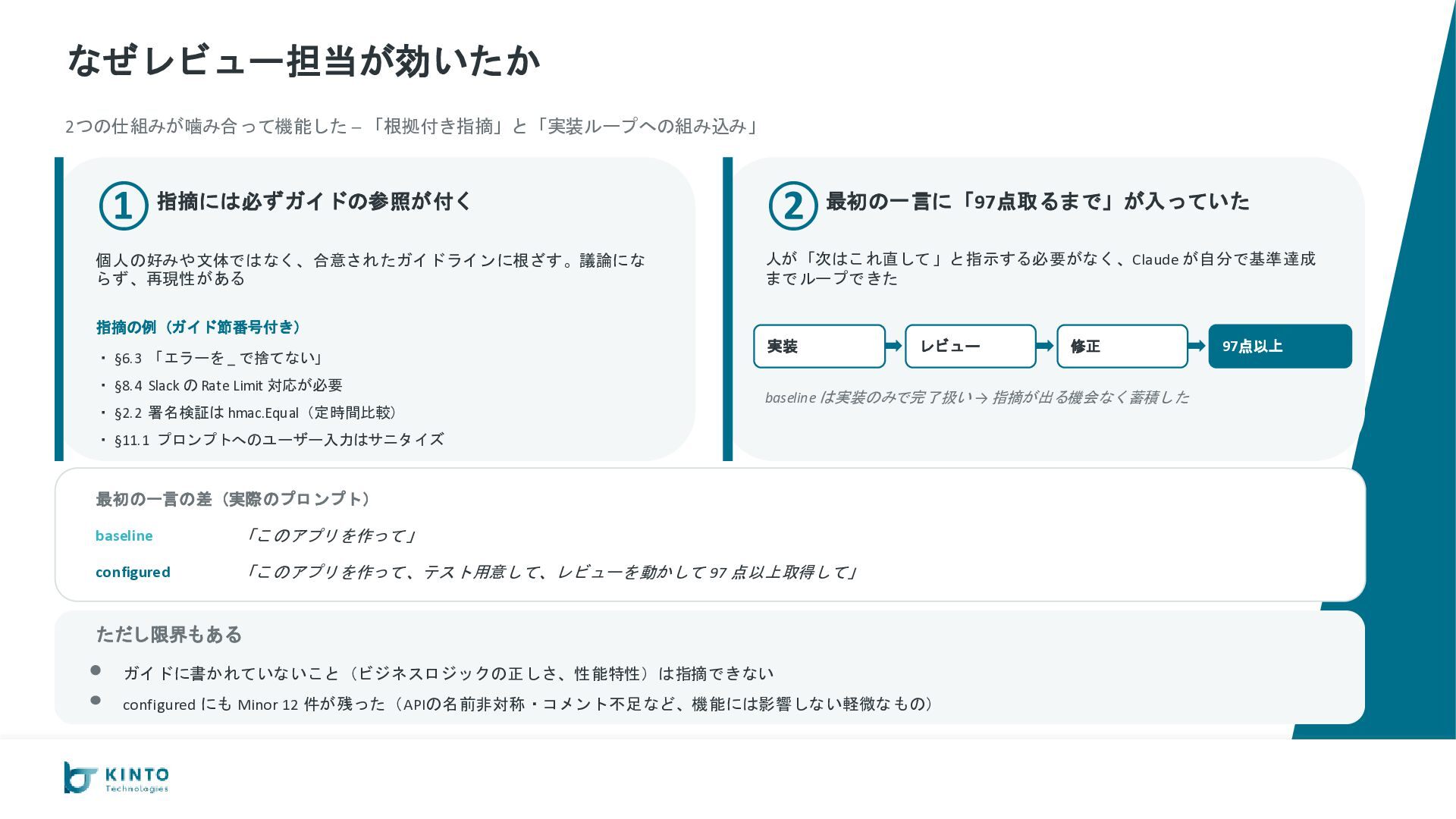
が −35%($206 vs $320) やり取りの回数 36 vs 27 完成までの時間 100分 vs 105分 総コスト $206 vs $320 キャッシュなし換算 $1,286 vs $1,795 configured 優勢 B. コードの品質 configured がカバレッジで大差 go vet エラー 0 vs 0 テスト通過率 100% vs 100% カバレッジ平均 約82% vs 約95% configured 優勢 C. 出力としての完成度 運用に必要な要素が configured だけ揃っている AI 呼び出し実装 ◦ vs ◦ 使ったトークン数の記録 なし vs あり 会話の継続(スレッド) ◦ vs ◦ Slack App 設定の自動生成 なし vs あり configured 優勢 D. 安定性・運用耐性 ルール違反ゼロ、本番向け設定も揃う 命名ミス 1件(やり直し) vs 0件 設定ファイルの置き場 ローカル vs S3で共有可 暗号化(KMS) AWS管理キー vs 自前キー CloudWatch アラーム なし vs あり
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}