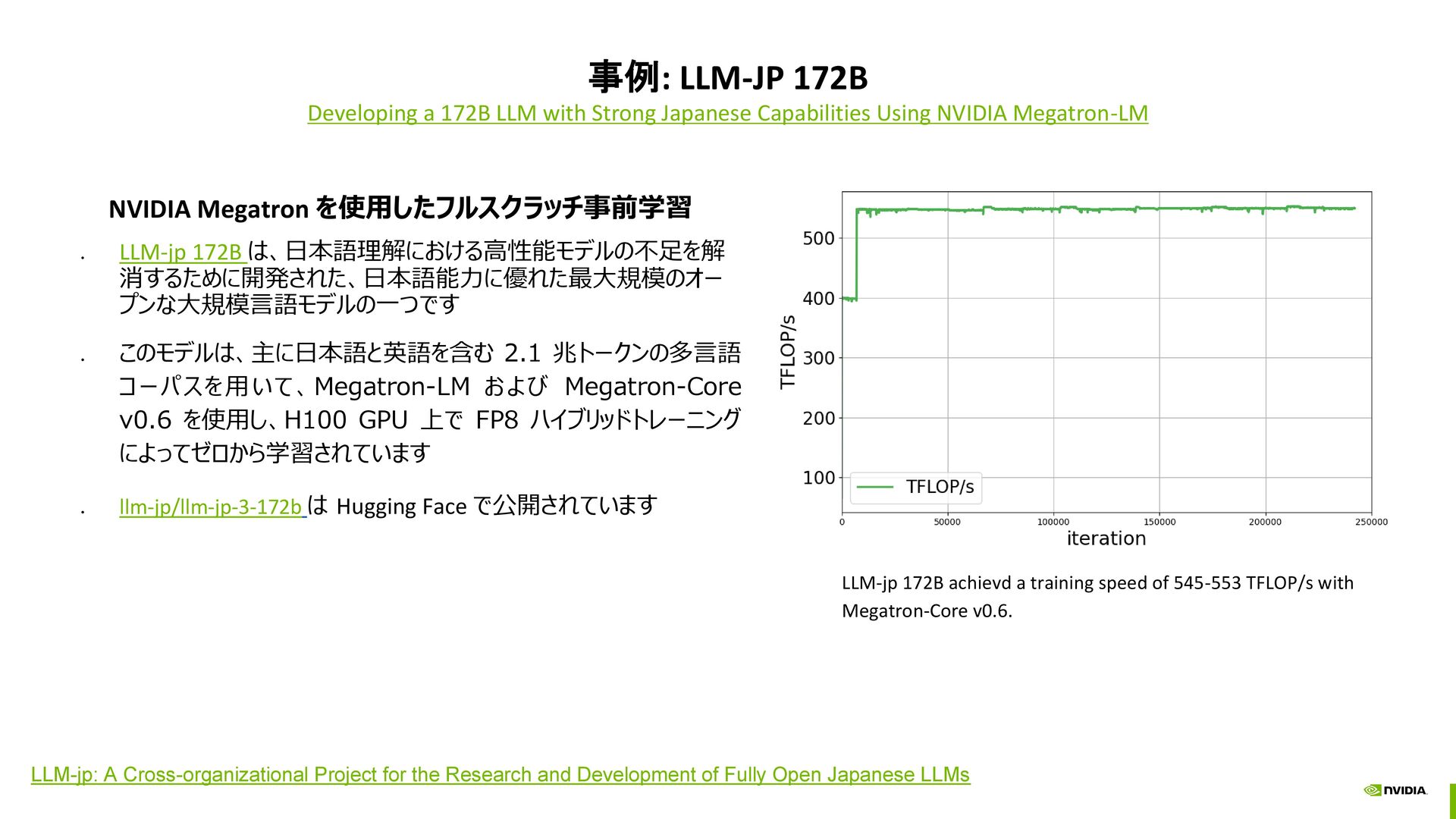
Capabilities Using NVIDIA Megatron-LM NVIDIA Megatron を使用したフルスクラッチ事前学習 • LLM-jp 172B は、日本語理解における高性能モデルの不足を解 消するために開発された、日本語能力に優れた最大規模のオー プンな大規模言語モデルの一つです • このモデルは、主に日本語と英語を含む 2.1 兆トークンの多言語 コーパスを用いて、Megatron-LM および Megatron-Core v0.6 を使用し、H100 GPU 上で FP8 ハイブリッドトレーニング によってゼロから学習されています • llm-jp/llm-jp-3-172b は Hugging Face で公開されています LLM-jp: A Cross-organizational Project for the Research and Development of Fully Open Japanese LLMs LLM-jp 172B achievd a training speed of 545-553 TFLOP/s with Megatron-Core v0.6.
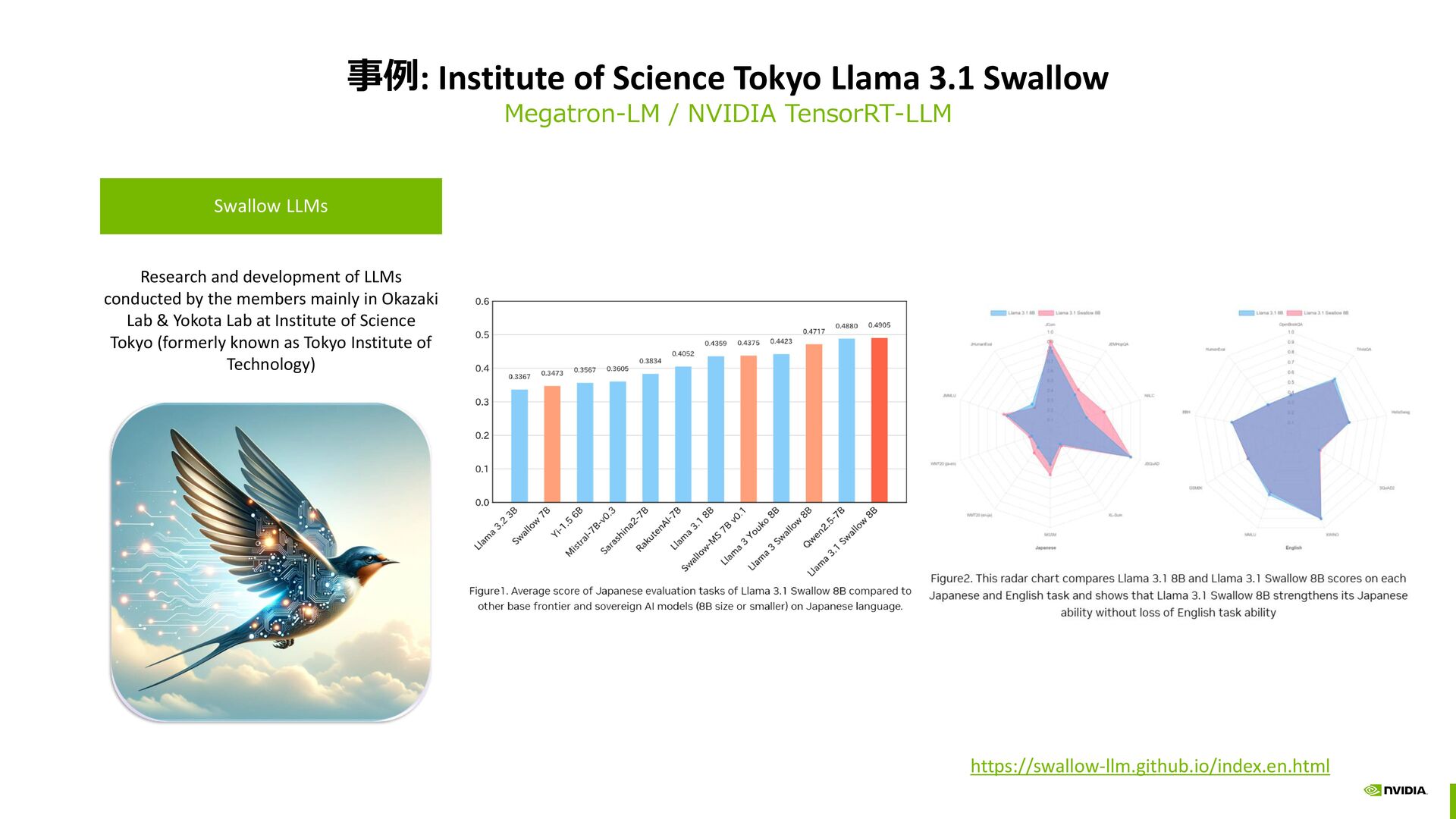
NVIDIA TensorRT-LLM Swallow LLMs Research and development of LLMs conducted by the members mainly in Okazaki Lab & Yokota Lab at Institute of Science Tokyo (formerly known as Tokyo Institute of Technology) https://swallow-llm.github.io/index.en.html
{kind=link}
{kind=link}
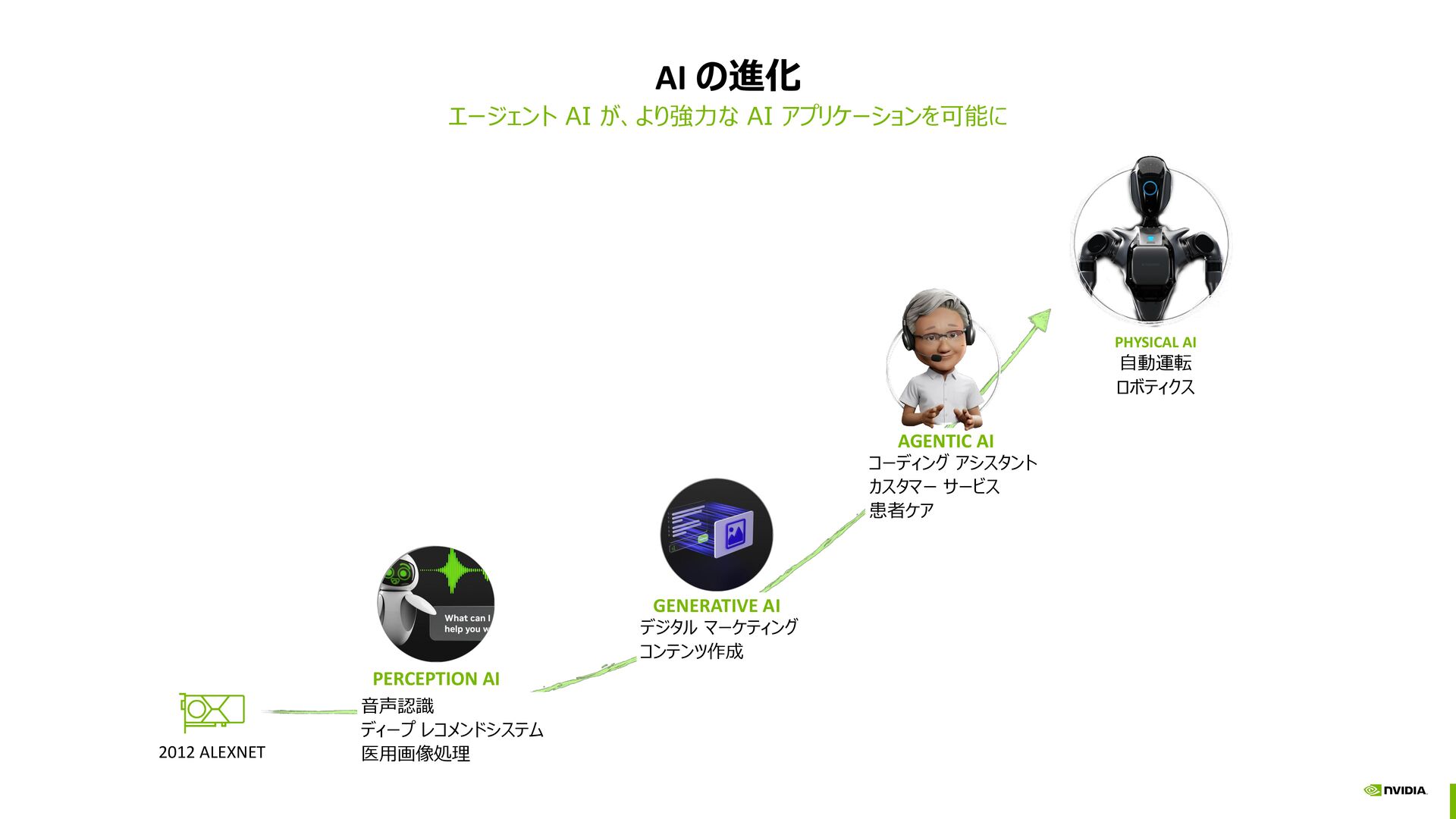{kind=link}
{kind=link}
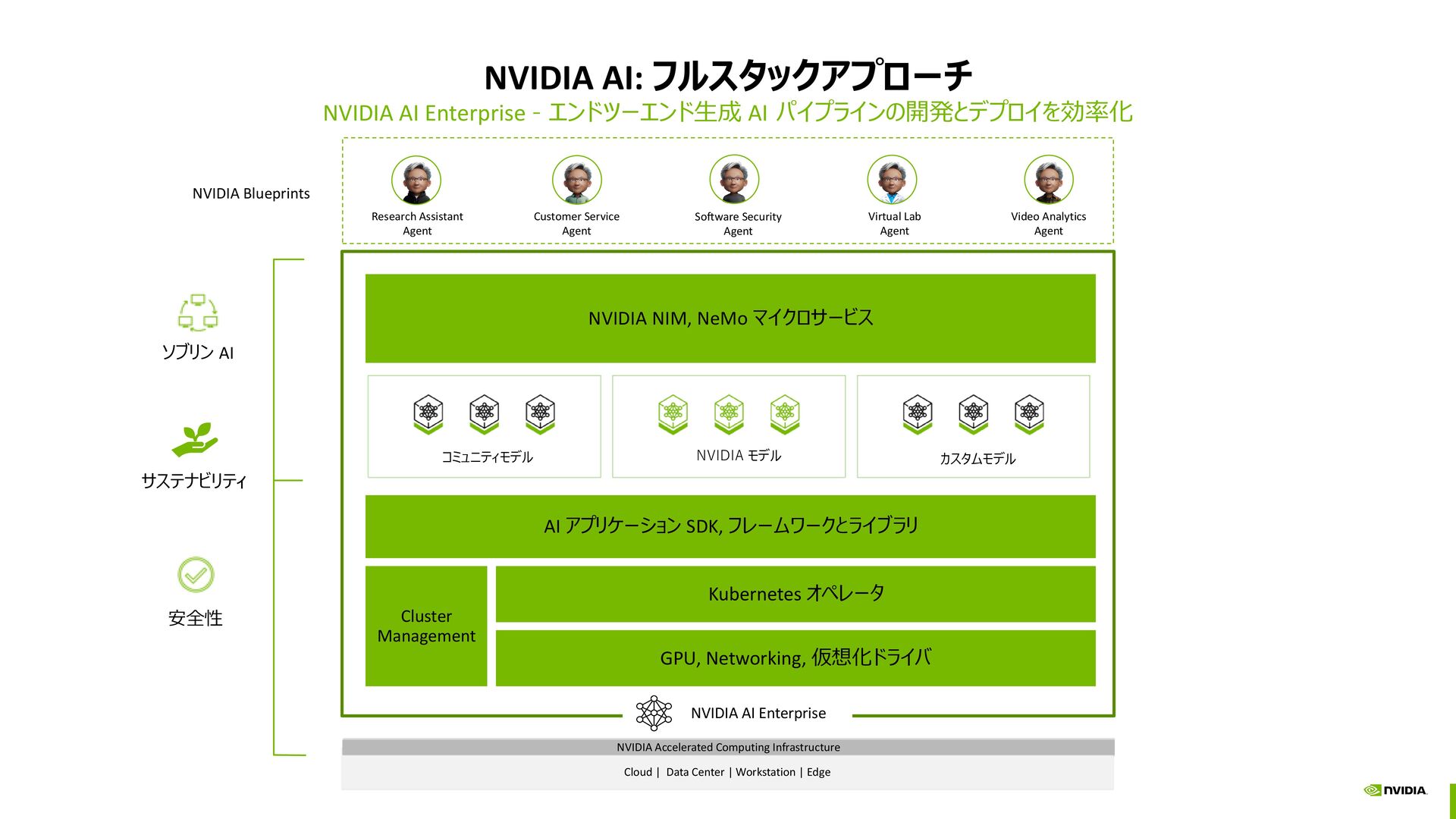{kind=link}
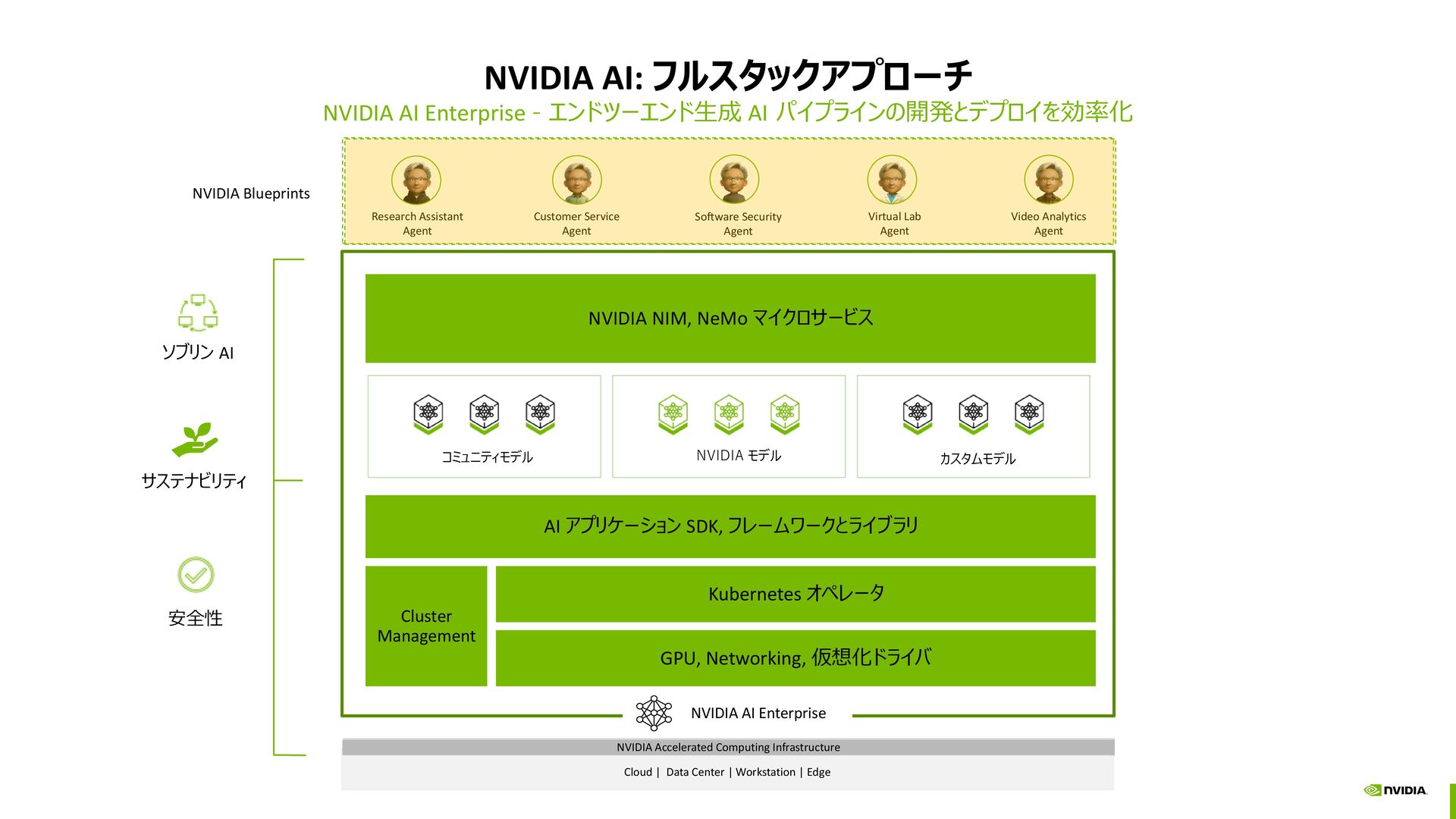{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}