Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
ローカルLLM基礎知識 / local LLM basics 2025
Search
Sponsored
·
Ship Features Fearlessly
Turn features on and off without deploys. Used by thousands of Ruby developers.
→
Naoki Kishida
November 22, 2025
Technology
17k
30
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
ローカルLLM基礎知識 / local LLM basics 2025
2025-11-22に開催された「第1回 ローカルLLMなんでも勉強会」での登壇資料です。
Naoki Kishida
November 22, 2025
More Decks by Naoki Kishida
See All by Naoki Kishida
ローカルLLMでどこまでコードが書けるか -縮小版 / How much code can be written on a local LLM Shortened
kishida
2
200
ローカルLLMでどこまでコードが書けるか -拡張版 / How much code can be written on a local LLM Extended
kishida
12
4.8k
Javaの型とAI時代に型が大事な理由 / java types and type in AI era
kishida
2
180
ローカルLLMでどこまでコードが書けるか / How much code can be written on a local LLM
kishida
2
530
AIエージェントでのJava開発がはかどるMCPをAIを使って開発してみた / java mcp for jjug
kishida
5
1.2k
AIの弱点、やっぱりプログラミングは人間が(も)勉強しよう / YAPC AI and Programming
kishida
13
6.9k
海外登壇の心構え - コワクナイヨ - / how to prepare for a presentation abroad
kishida
2
190
Current States of Java Web Frameworks at JCConf 2025
kishida
0
1.8k
AIを活用し、今後に備えるための技術知識 / Basic Knowledge to Utilize AI
kishida
28
7.5k
Other Decks in Technology
See All in Technology
なぜ、あなたのエージェントは言うことを聞かないのか
segavvy
1
160
複数プロダクトで進めるAI機能実装 ── 実践から得たリアルな学びとロードマップ実現への挑戦 / AICon2026_yanari
rakus_dev
0
250
【公開用】AI_Dev_Ex2026_AI_登壇資料
matsuritechnologies
PRO
1
420
ファミコンでPHPを動かす / PHP on the Famicom
tomzoh
2
570
AI時代におけるテストの基礎の再定義 / Rethinking the Fundamentals of Testing in the AI Era
mineo_matsuya
3
820
AI時代のPlaywright活用(システムテストを自動化する ー 実行エンジンにPla ywrightを選んだ理由)
ynisqa1988
2
900
AmplifyHostingConstructからSSRフレームワークのためのホスティング設計を考察する/amplify-hosting-construct
fossamagna
1
280
AI時代におけるエンジニアの新たな役割──FDEとクオリアの探求/登壇資料(戸井田 裕貴)
hacobu
PRO
0
270
穢れた技術選定について
watany
19
5.9k
ここは地獄!つらい朝会を体験することで、チームとしてのより良い振る舞いに気づくワークショップ / The stand-up meeting from hell in the game industry
scrummasudar
0
200
Amazon Quick 入門!
ysuzuki
2
120
LLM/Agent評価:トップ営業の発言を「正解」にする 〜暗黙的正解による評価を営業資産に変える〜
takkuhiro
1
240
Featured
See All Featured
A Tale of Four Properties
chriscoyier
163
24k
How To Stay Up To Date on Web Technology
chriscoyier
790
250k
Tell your own story through comics
letsgokoyo
1
1k
YesSQL, Process and Tooling at Scale
rocio
174
15k
SEOcharity - Dark patterns in SEO and UX: How to avoid them and build a more ethical web
sarafernandez
0
220
How to train your dragon (web standard)
notwaldorf
97
6.7k
Visualization
eitanlees
152
17k
Breaking role norms: Why Content Design is so much more than writing copy - Taylor Woolridge
uxyall
0
350
Stewardship and Sustainability of Urban and Community Forests
pwiseman
0
370
Speed Design
sergeychernyshev
33
1.9k
Designing for humans not robots
tammielis
254
26k
Organizational Design Perspectives: An Ontology of Organizational Design Elements
kimpetersen
PRO
1
770
Transcript
ローカルLLM基礎知識 2025-11-22 ローカルLLM勉強会 きしだ なおき 11/23 ※ 各モデルの説明も追記しました
2025/11/23 2 自己紹介 • きしだ なおき • LINEヤフー • X(twitter):
@kis • blog: きしだのHatena • (nowokay.hatenablog.com) • 「プロになるJava」というJavaの本を書いてます
3 ローカルLLMとは • 自分(たち)のために動かすLLM • 今回は、個人が手元のPCで動かす前提 • 大人数で使う場合には様々な管理が必要 • 今回はスコープ外
ローカルLLMのメリット • ネットがなくても使える • 自分でコントロールできる • データを外に送らない • カスタマイズできる •
勉強になる • かわいい
LLMの仕組み • LLM=大規模言語モデル • 言語を扱う大規模なニューラルネットワーク • Transformerを基本とする • 仕組み的には、文章の続きを生成 •
AI = LLMを中心とした応答システム
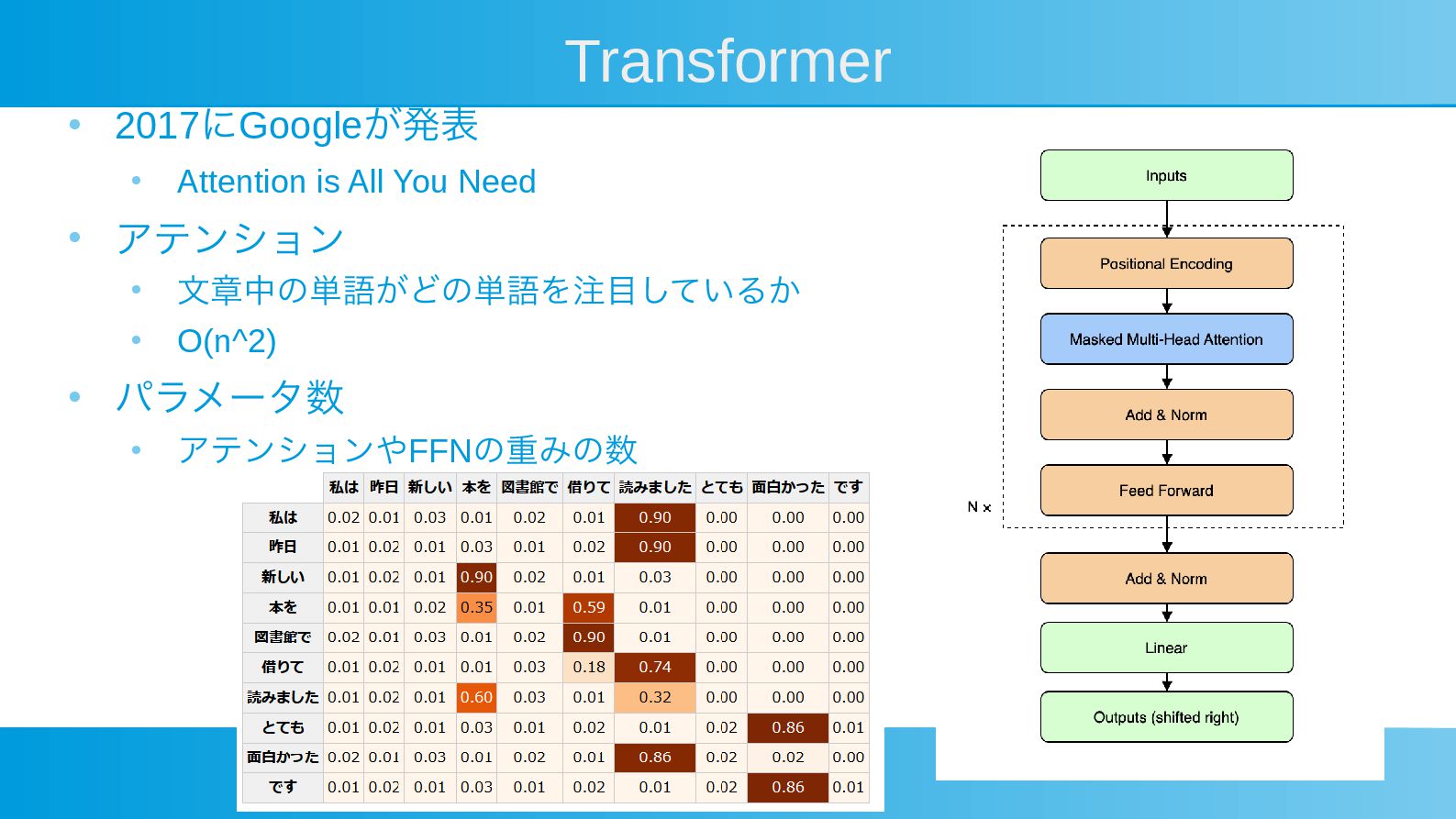
Transformer • 2017にGoogleが発表 • Attention is All You Need •
アテンション • 文章中の単語がどの単語を注目しているか • O(n^2) • パラメータ数 • アテンションやFFNの重みの数
LLMを動かすのに必要なメモリ • 16bit floatの場合、1パラメータにつき2バイト • 7Bモデル(70億パラメータ)なら14GB • 8bit量子化 • 8bitにまるめても性能があまり変わらない
• 7Bモデルなら7GB • 4bit量子化 • 4bitでも案外性能が落ちない • 7Bモデルなら3.5GB
MoE(Mixture of Experts) (GPT-4) • FFNは知識をうけもつ • すべての知識を同時に使うことはない • 多数の専門家モデルを持っておいて、
推論時に必要なモデルだけを呼び出 すことでリソースを節約 • GPT-oss 120B • エキスパート数 128 • アクティブパラメータ数5.1B
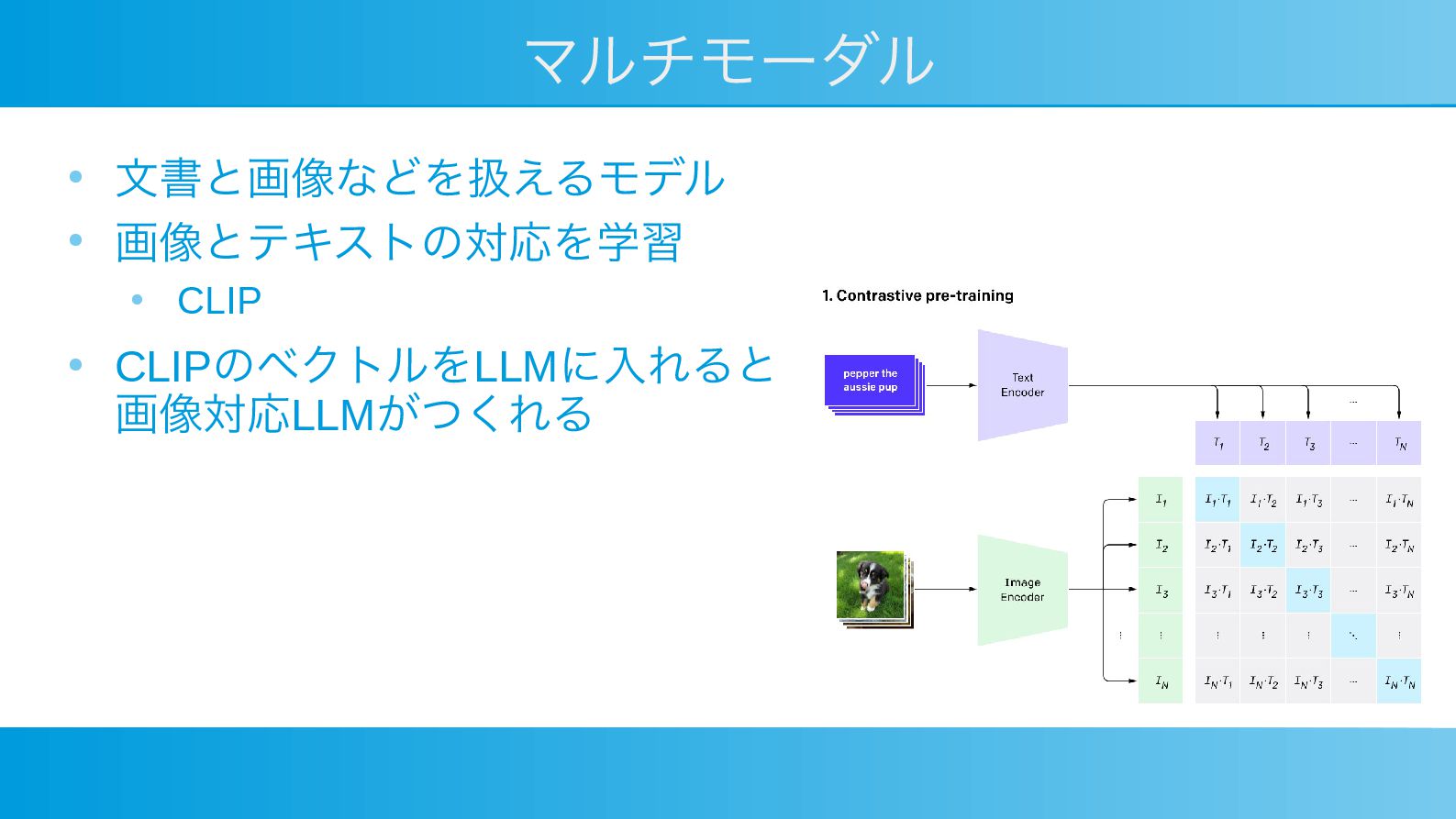
マルチモーダル • 文書と画像などを扱えるモデル • 画像とテキストの対応を学習 • CLIP • CLIPのベクトルをLLMに入れると 画像対応LLMがつくれる
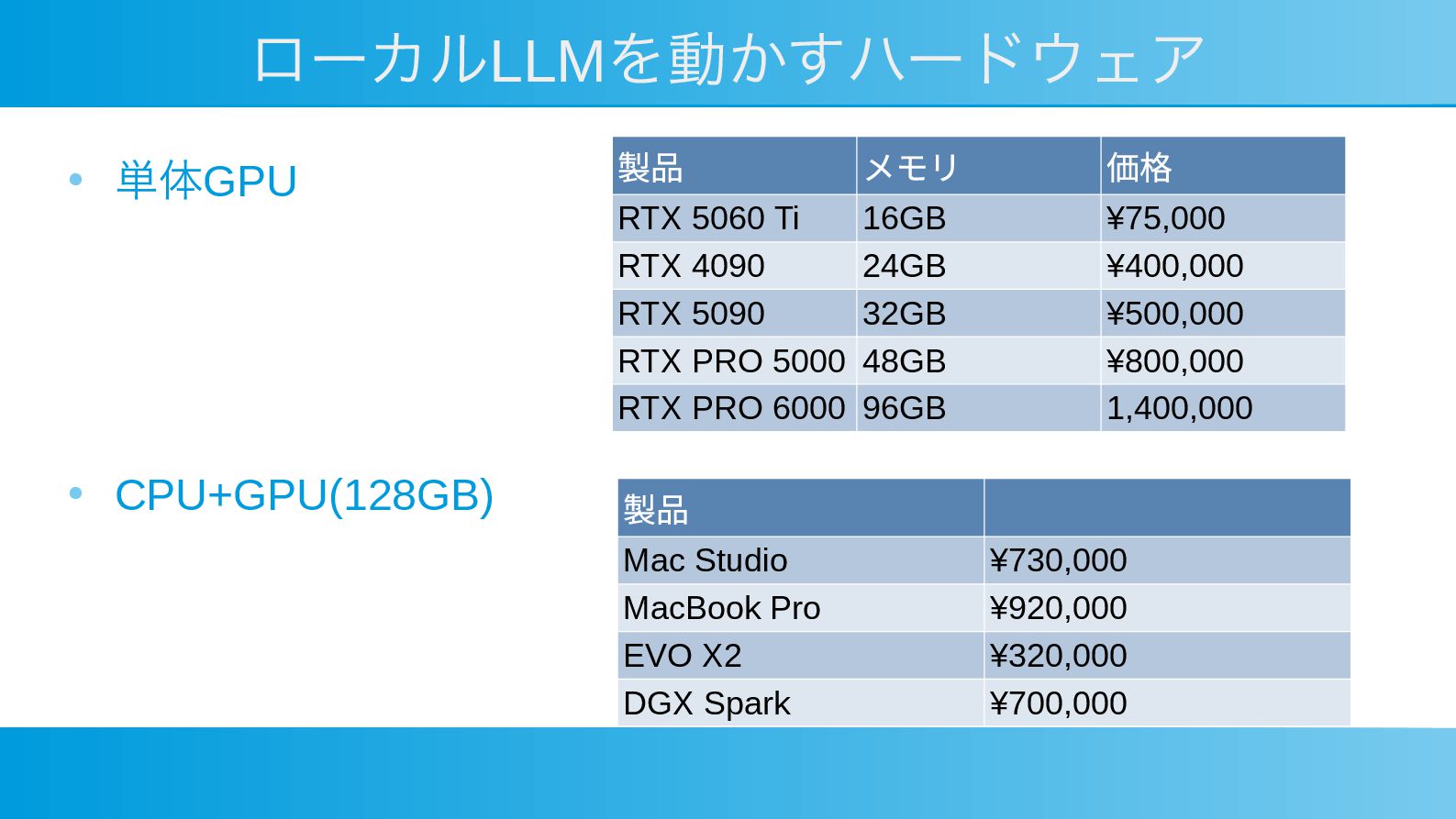
ローカルLLMを動かすハードウェア • 単体GPU • CPU+GPU(128GB) 製品 メモリ 価格 RTX 5060
Ti 16GB ¥75,000 RTX 4090 24GB ¥400,000 RTX 5090 32GB ¥500,000 RTX PRO 5000 48GB ¥800,000 RTX PRO 6000 96GB 1,400,000 製品 Mac Studio ¥730,000 MacBook Pro ¥920,000 EVO X2 ¥320,000 DGX Spark ¥700,000
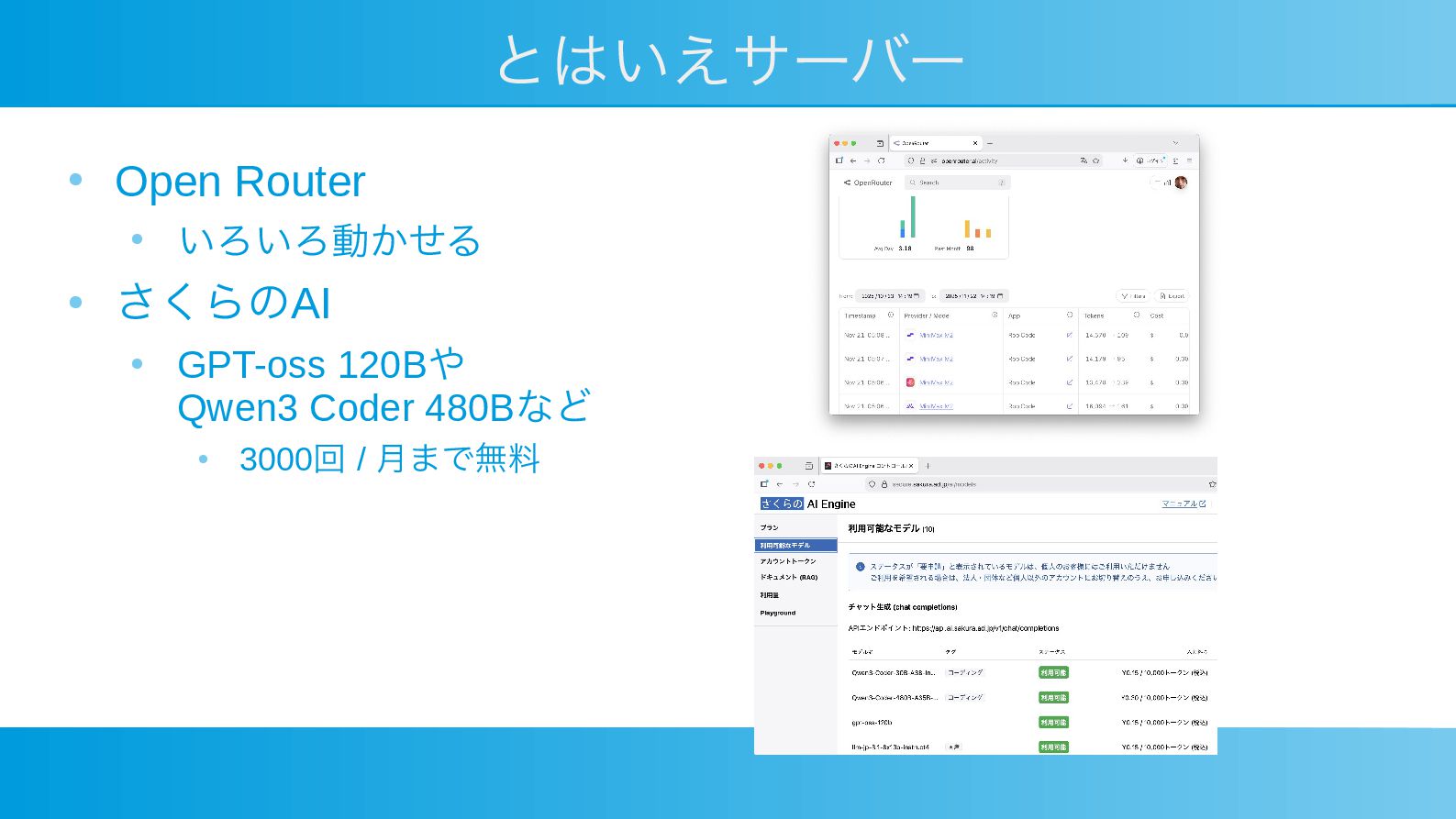
とはいえサーバー • Open Router • いろいろ動かせる • さくらのAI • GPT-oss
120Bや Qwen3 Coder 480Bなど • 3000回 / 月まで無料
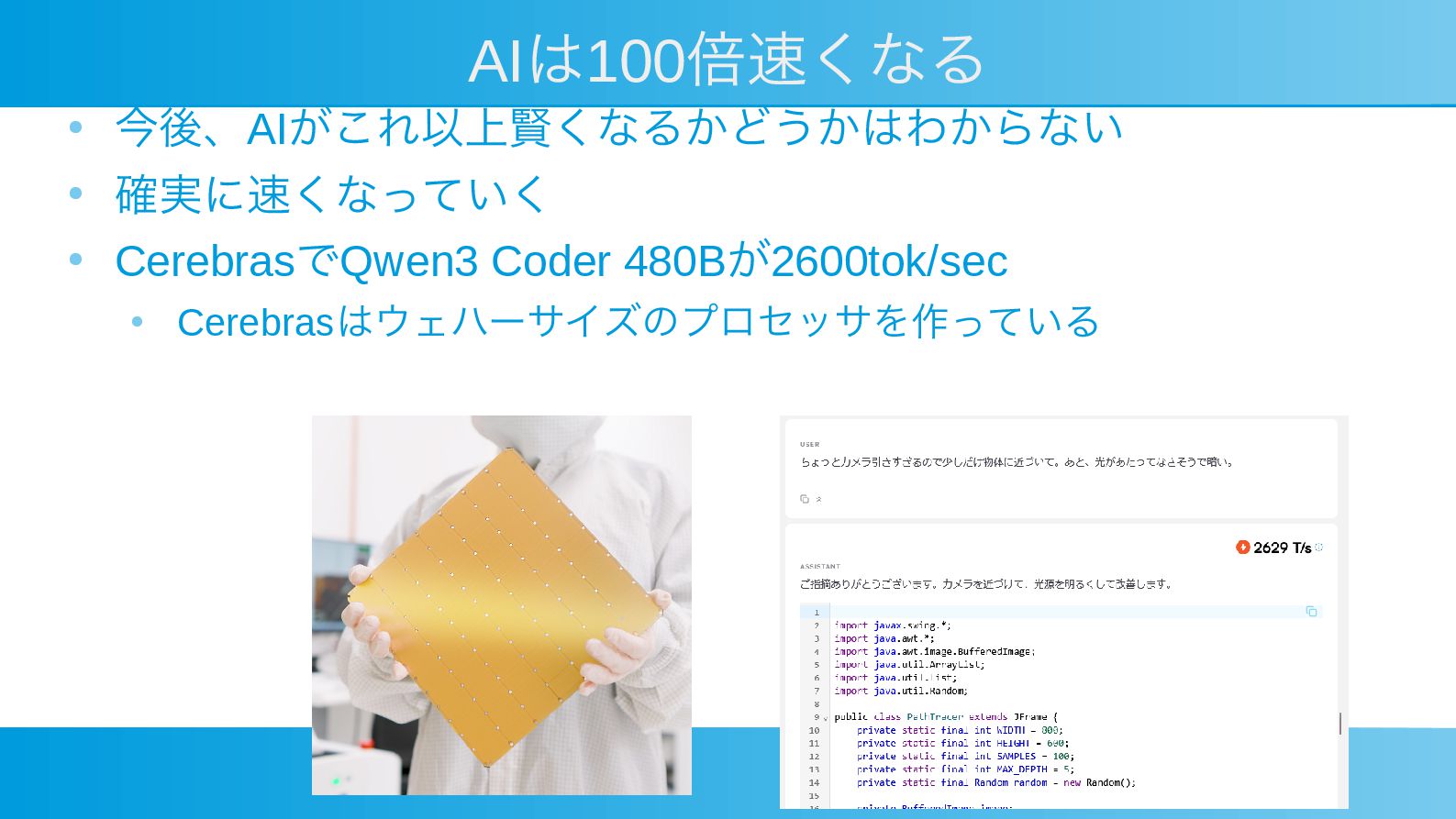
AIは100倍速くなる • 今後、AIがこれ以上賢くなるかどうかはわからない • 確実に速くなっていく • CerebrasでQwen3 Coder 480Bが2600tok/sec •
Cerebrasはウェハーサイズのプロセッサを作っている
ローカルLLMのモデル • お手頃 〜32B • Qwen3 (0.6~32B), Gemma 3(0.6〜27B), GPT-oss
20B • 大きめ 〜120B • Qwen3-Next 80B, GPT-oss 120B, GLM 4.5 Air(106B) • 大きい 〜300B • MiniMax M2(230B), Qwen3 235B, GLM 4.6(355B) • 巨大 〜1T • Kimi K2(1T), DeepSeek R2(671B)
お手頃モデル • ふつうのPCで動かせる。 • チャットをまともにやろうとしたら8B以上 • 商用AIの簡易版として使うならGPT-oss 20B • 4Bまでは、特定用途単機能で考えるのがいい
• GPT-oss 20B • OpenAI、mxfp4で量子化 • Qwen3 30B-A3B, 32B, 14B, 8B, 4B, 1.7B, 0.6B • Alibaba、小さいモデルでも性能が高い • Gemma 3 27B, 12B, 4B, 1B, 270m • Google、大きいモデル含め、オープンウェイトで最も日本語が流暢。
大きめモデル • MacやEVO X2、DGX Sparkで動かす • 普通にChatGPTなどの代替になりだす • MoEが基本(アクティブパラメータをAnBと表記) •
GPT-oss 120B (A5.5B) • 賢いけど日本語力はちょっと弱い • GLM 4.5 Air(106B-A12B) • Z.ai、賢いし日本語もGemma 3並にうまい。おすすめ • Qwen3 Next 80B-A3B • 単発では賢いけどマルチターンは弱そう
大きい • Mac Studioで動かせるけどコンテキストが長くなると重い • GLM 4.6(355B-A32B) • かなりいい。コードも結構書ける •
Qwen3 235B-A22B • 単発でかなり賢いけどマルチターンでは弱い感じがある。 • MiniMax M2(230B-A10B) • 日本語が全くだめ。Roo Codeが使えないなど、少し残念。 • Roo Codeの問題は報告したら対策中とのこと。
巨大モデル • MacStudioで一応1bit量子化で動かせるけど重くて使い物にはな らない。 • DeepSeek V3.1(685B-A37B) • 大きさの割にはそんなに賢くない気がする •
Kimi K2(1T-A32B) • オープンウェイトでは最大 • 性能にも大きさが反映されて、商用モデルの無償版となら張り合えそう • 日本語もかなり書ける • 手元のパソコンで動かないのだけが残念
マルチモーダル • 画像言語モデル • Qwen3-VL, GLM-4.5V, Llama 4, Gemma 3
LLMを動かすフレームワーク • PyTorch • 機械学習定番フレームワーク • Hugging Face Transformers(Python) •
LLM作成フレームワーク • Llama.cpp(GGUF) • C++で実装したエンジン。モデル形式はGGUF。量子化がある • MLX • Apple Sililcon用行列計算フレームワーク • Unsloth • 動的量子化、ファインチューンフレームワーク
ローカルLLMの実行環境 • LM Studio • llama.cpp • Ollama • vLLM
• Docker • Open WebUI
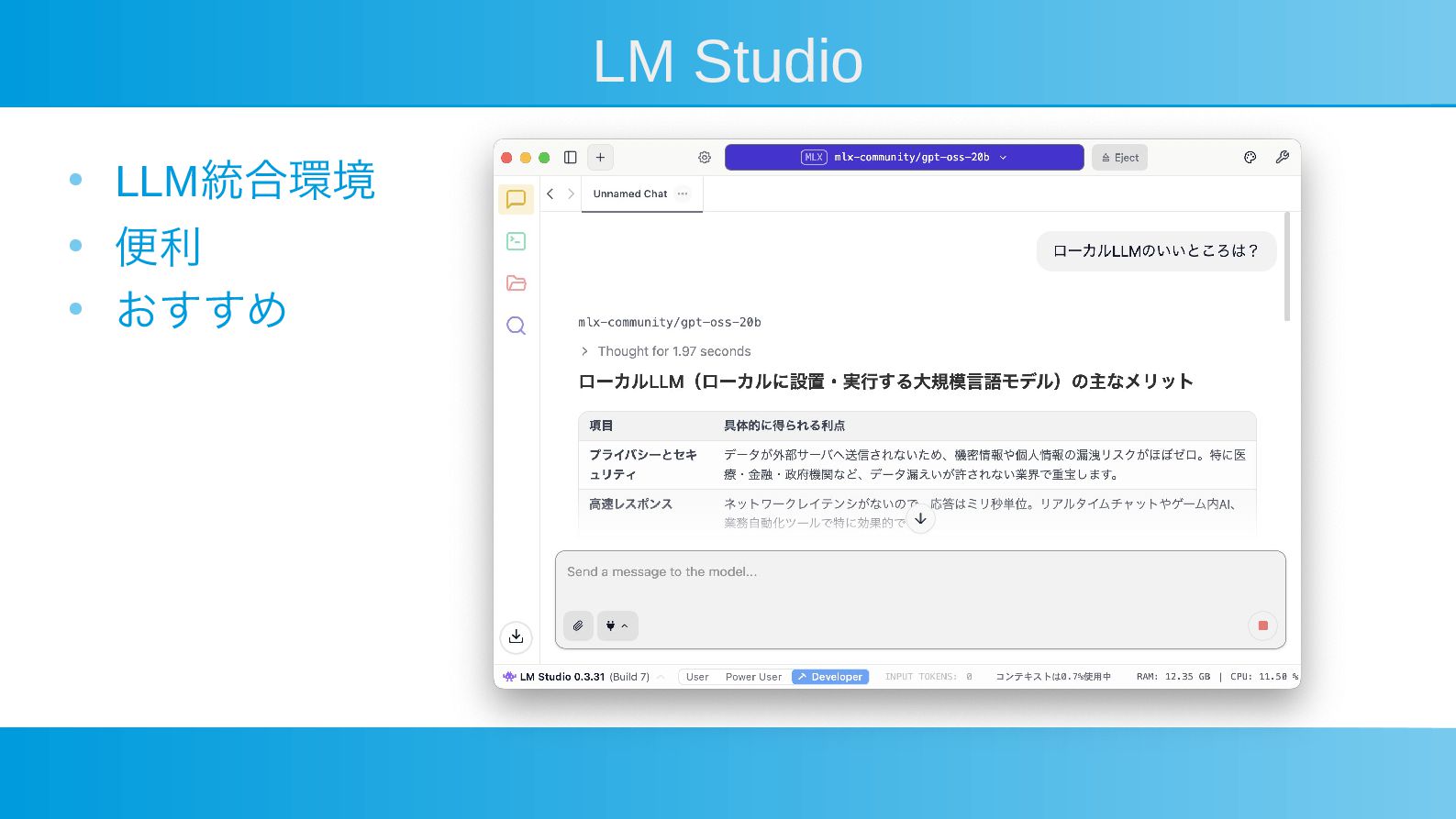
LM Studio • LLM統合環境 • 便利 • おすすめ
llama.cpp • LLM実行エンジン • LM StudioもOllamaも内部で使う • サーバー機能を持っている • 軽量でプログラムから使いやすい
• 30MBくらい(+モデルが3GBくらい)
Ollama • 個人用LLM実行サーバー • あまり便利ではない • モデルを独自形式で保持 • ファイル操作できない •
モデルの選択肢が不自由 • 量子化などを選べない
vLLM • サービス向け実行サーバー • ちょっとおおげさ
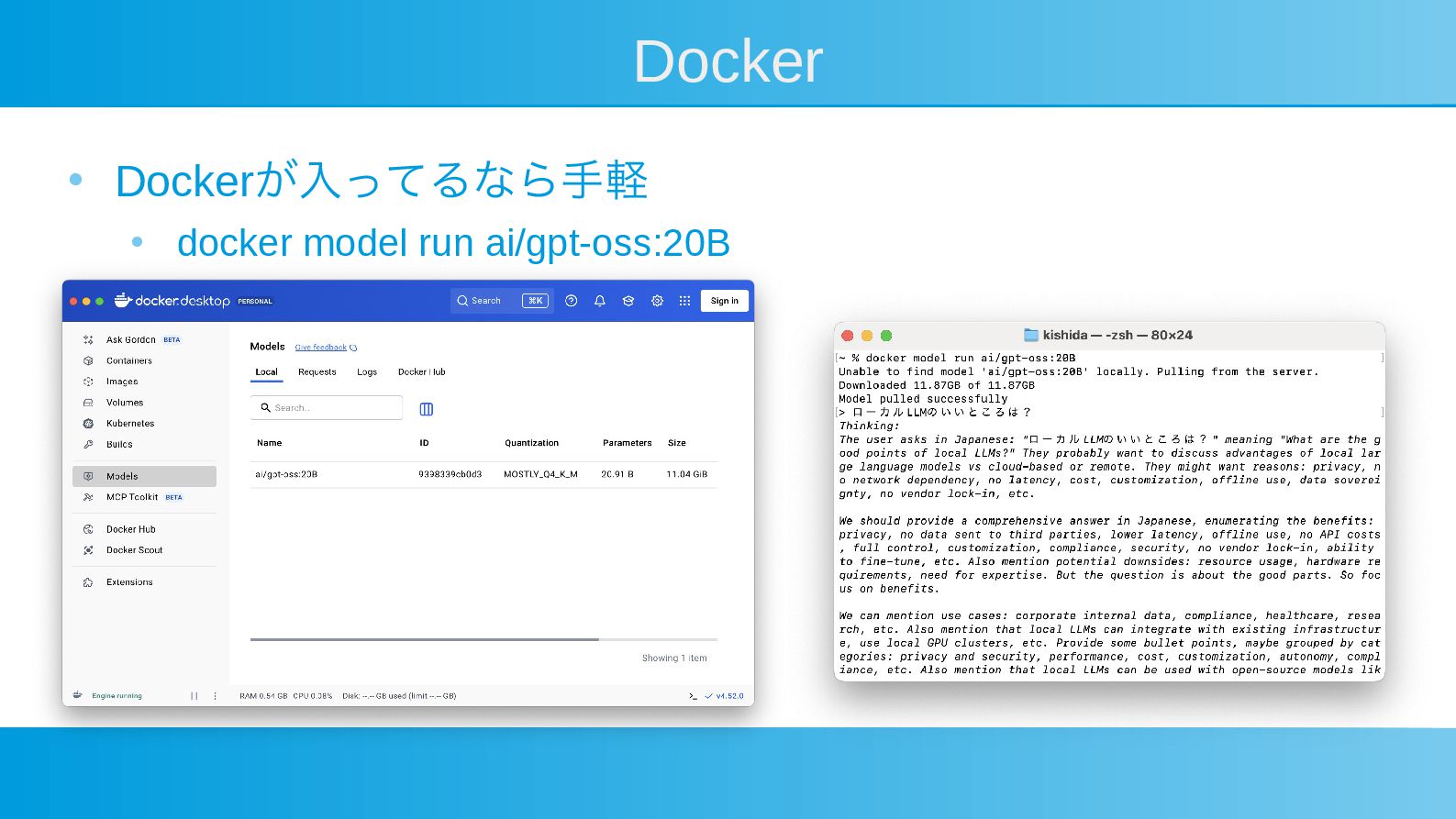
Docker • Dockerが入ってるなら手軽 • docker model run ai/gpt-oss:20B
Open WebUI • Web用UI • LLMを動かす機能は持たない • LM Studioなどに接続
ファインチューニング • LLMのカスタマイズ • ファインチューニングの分類 • CPT(継続事前学習) • 知識を教える •
SFT(教師ありファインチューニング) • よいやりとりを教える • RLHF(人間の評価による強化学習) • 出力結果に点をつける • DPO(直接的な選考最適化) • 質問に対してよい応答とよくない応答を教える
ファインチューニングで考えること • データセットは? • どこで実行する? • NVIDIA GPUが必要 • モデルは?
• どう実行する? • どう試す?
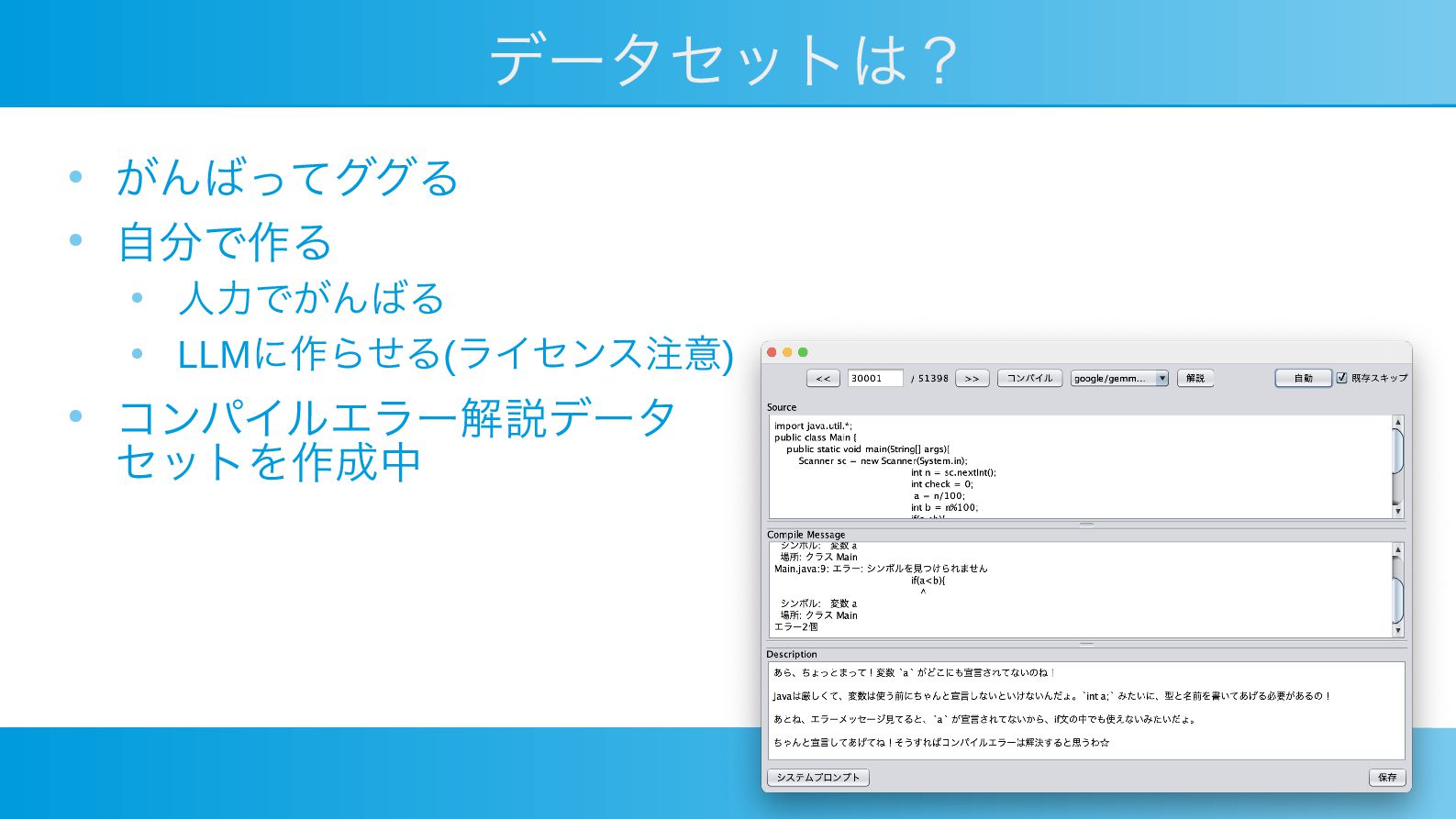
データセットは? • がんばってググる • 自分で作る • 人力でがんばる • LLMに作らせる(ライセンス注意) •
コンパイルエラー解説データ セットを作成中
どこで実行する? • ファインチューンのフレームワーク(Unsloth)がCUDA前提なので NVIDIA GPUが必要 • 軽く試すならGoogle Colabがおすすめ • https://colab.research.google.com/
モデルは? • 確保できたハードウェアでトレーニングできるサイズ • 8Bや14Bくらい。 • Gemma 3やQwen 3、Llama 3
どう実行する? • Unslothフレームワーク • unsloth + finetuneで検索 • Colab Notebookが用意されている
• 学習パラメータなど試行錯誤
できたモデルどう試す? • 趣味なら雰囲気で!
実際のところは? • おそらくローカルLLMは小さい単機能な用途が多いはず • 大きいモデルでデータセットを作って、より小さいモデルをファ インチューンして動かせればコストも安くレスポンスもよい • 同じことを小さいモデルで動かせるようになれば勝ち
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}