Evangelist of Ahana with over 15 years experience in distributed data and database technology including relational, NoSQL and federated systems. She is also the Presto Foundation Outreach Chairperson. Prior to Ahana, Dipti held executive roles at Alluxio, Kinetica and Couchbase. At Alluxio, she was Vice President of Products and at Couchbase she held several leadership positions there including VP, Product Marketing, Head of Global Technical Sales and Head of Product Management. Earlier in her career Dipti managed development teams at IBM DB2 Distributed where she started her career as a database software engineer. Dipti holds a M.S. in Computer Science from UC San Diego, and an MBA from the Haas School of Business at UC Berkeley. Dipti Borkar Cofounder, Chief Product Officer and Chief Evangelist Ahana
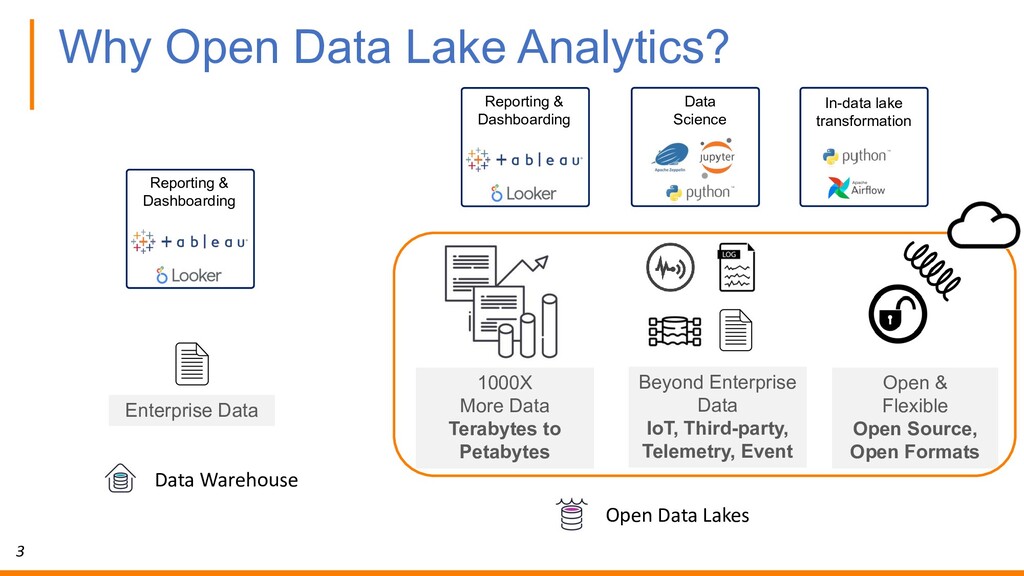
Data IoT, Third-party, Telemetry, Event 1000X More Data Terabytes to Petabytes Open & Flexible Open Source, Open Formats Reporting & Dashboarding Data Science In-data lake transformation Reporting & Dashboarding Data Warehouse Open Data Lakes
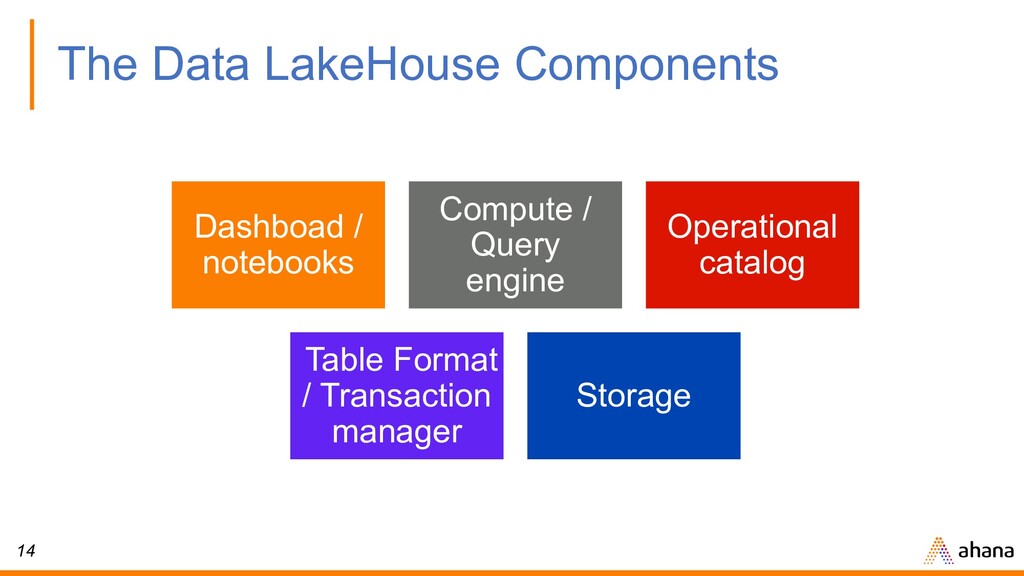
/ Object Store • Structured / Semi-Structured Data • Ingestion • Discovery • Data Science • Notebook and Python Access • Less expensive, but… • Good enough performance • Supports ~70% of DW workloads • Different approach to governance 7
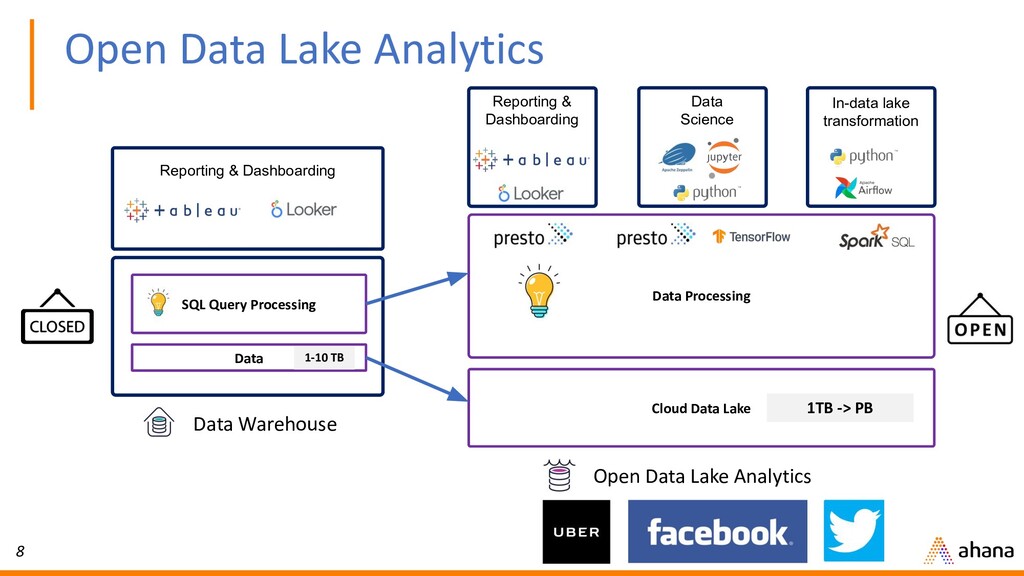
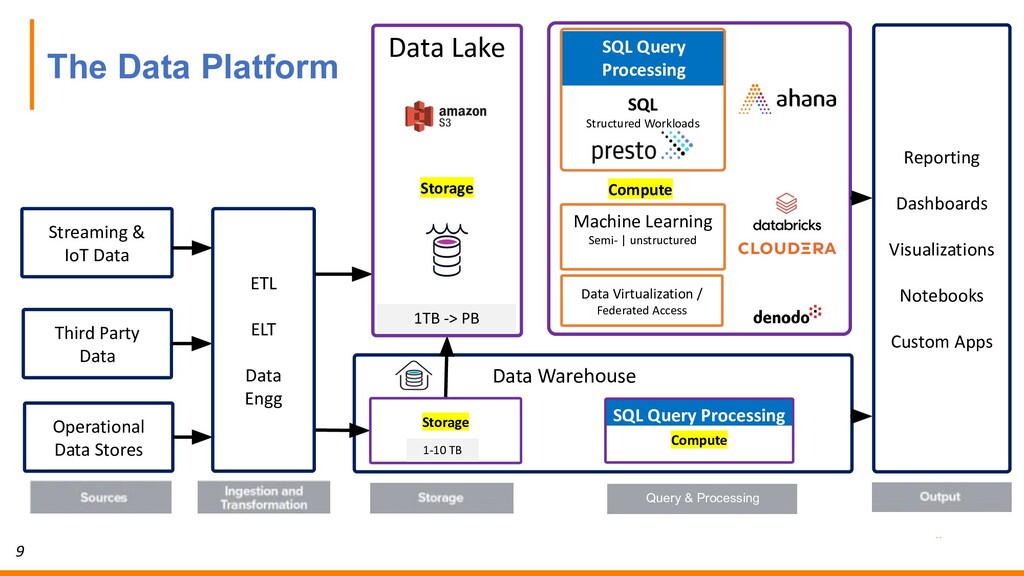
Data Processing 1-10 TB 1TB -> PB Open Data Lake Analytics Reporting & Dashboarding Data Science In-data lake transformation Open Data Lake Analytics Reporting & Dashboarding
& dashboarding Interactive querying use cases Transformation using SQL (ETL) Federated access across data sources SQL Data Science Customer-facing app analytics
/ AWS Serverless options get very expensive for growing data volumes ▪ Cloud data warehouse costs grow much faster than compute engine costs ▪ Serverless options like AWS Athena charge /query and get expensive “Do it yourself” approach is complicated ▪ Big data skills in platform teams are limited ▪ Presto is complicated and operationally very time consuming Presto on AWS like AWS Athena has limited capabilities and doesn’t scale ▪ Limited concurrency of 20 per account ▪ No visibility into cluster logs, query logs, no flexibility / control on scale
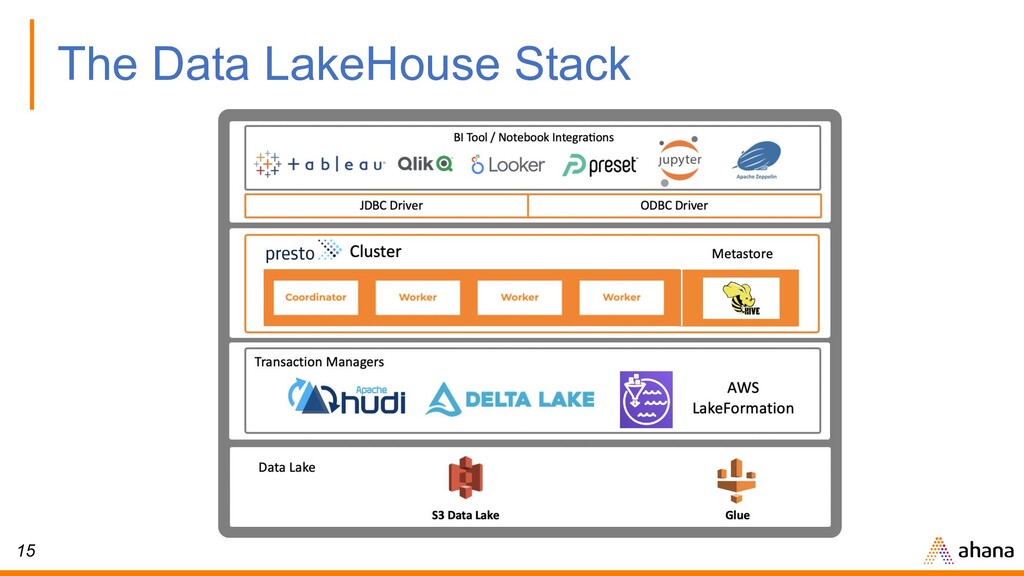
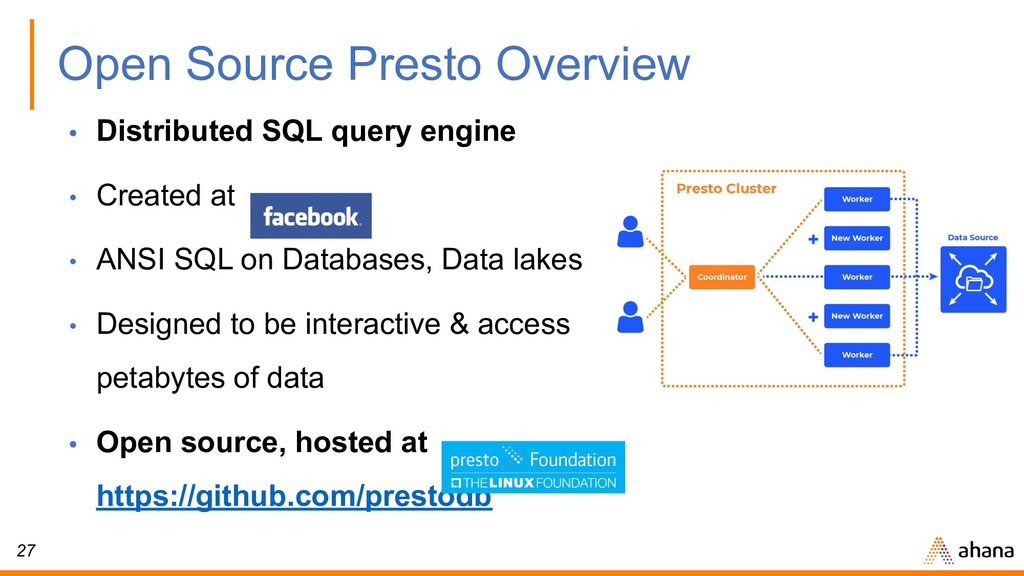
• Created at • ANSI SQL on Databases, Data lakes • Designed to be interactive & access petabytes of data • Open source, hosted at https://github.com/prestodb
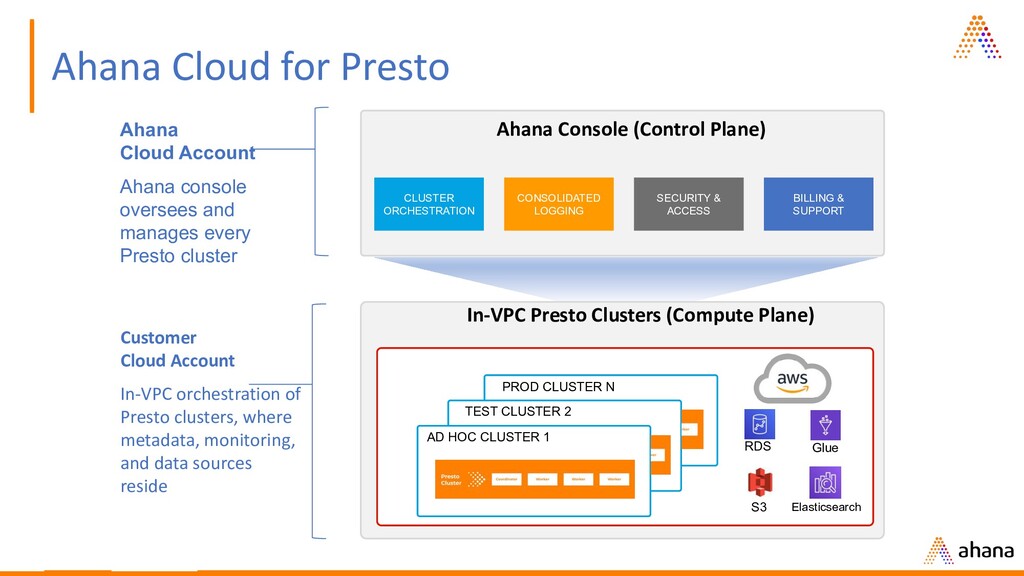
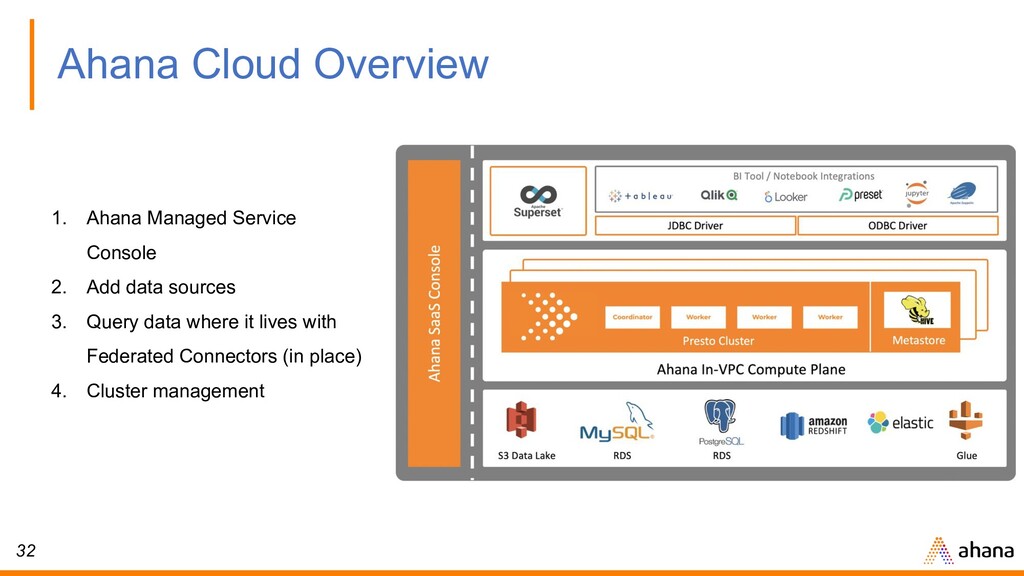
ORCHESTRATION CONSOLIDATED LOGGING SECURITY & ACCESS BILLING & SUPPORT In-VPC Presto Clusters (Compute Plane) AD HOC CLUSTER 1 TEST CLUSTER 2 PROD CLUSTER N Glue S3 RDS Elasticsearch Ahana Cloud Account Ahana console oversees and manages every Presto cluster Customer Cloud Account In-VPC orchestration of Presto clusters, where metadata, monitoring, and data sources reside
Lake Glue Metastore ▪ Securonix is a Security information and event management software ▪ They use Ahana for in-app SQL analytics on data from AWS S3 for threat hunting ▪ They pull in billions of events per day that get stored in S3 ▪ With Ahana Cloud, they saw 3x better price performance compared with Presto on AWS
on AWS S3 with an open data lake + USER ▪ Presto compute brought to your data in your VPC in your account ▪ Fully managed Presto cluster life cycle including idle-time management ▪ Query AWS DBs - RDS/MySQL , RDS/Postgres, Elasticsearch, Redshift, Elasticsearch ▪ Cloud-native and highly available running on Kubernetes ▪ Bring your own ▪ BI tool / Data Science Notebook ▪ Metadata Catalog ▪ Transaction Manager Easy to use 3 x Price Performance Open & Flexible
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}