scalability translates to the implementation as some distributed system. Low-cost is a relative term, and it’s typically in contrast to expensive specialized hardware. • Accessible to scalable compute engines
the open source stack that ushered in Big Data to the mainstream in mid-2000s. • Distributed filesystem on commodity hardware (assumes hardware failure as first-class citizen) • “Data lake 1.0”
become the storage of choice for modern data lakes. • Also stores files, but does not manage the files in a file hierarchy like filesystems. Simple PUT, GET, DELETE, and LIST.
industry-leading scalability, data availability, security, and performance • Introduced in 2006 • Over 100 trillion objects worldwide • Inexpensive: $0.023 per GB
→ Interactive experience, great for ad hoc use cases • Pluggable architecture to support multiple data sources • ANSI SQL → Lingua franca of data literate population (e.g. data analysts) • Open source and open governance → Diverse innovation, no vendor lock in
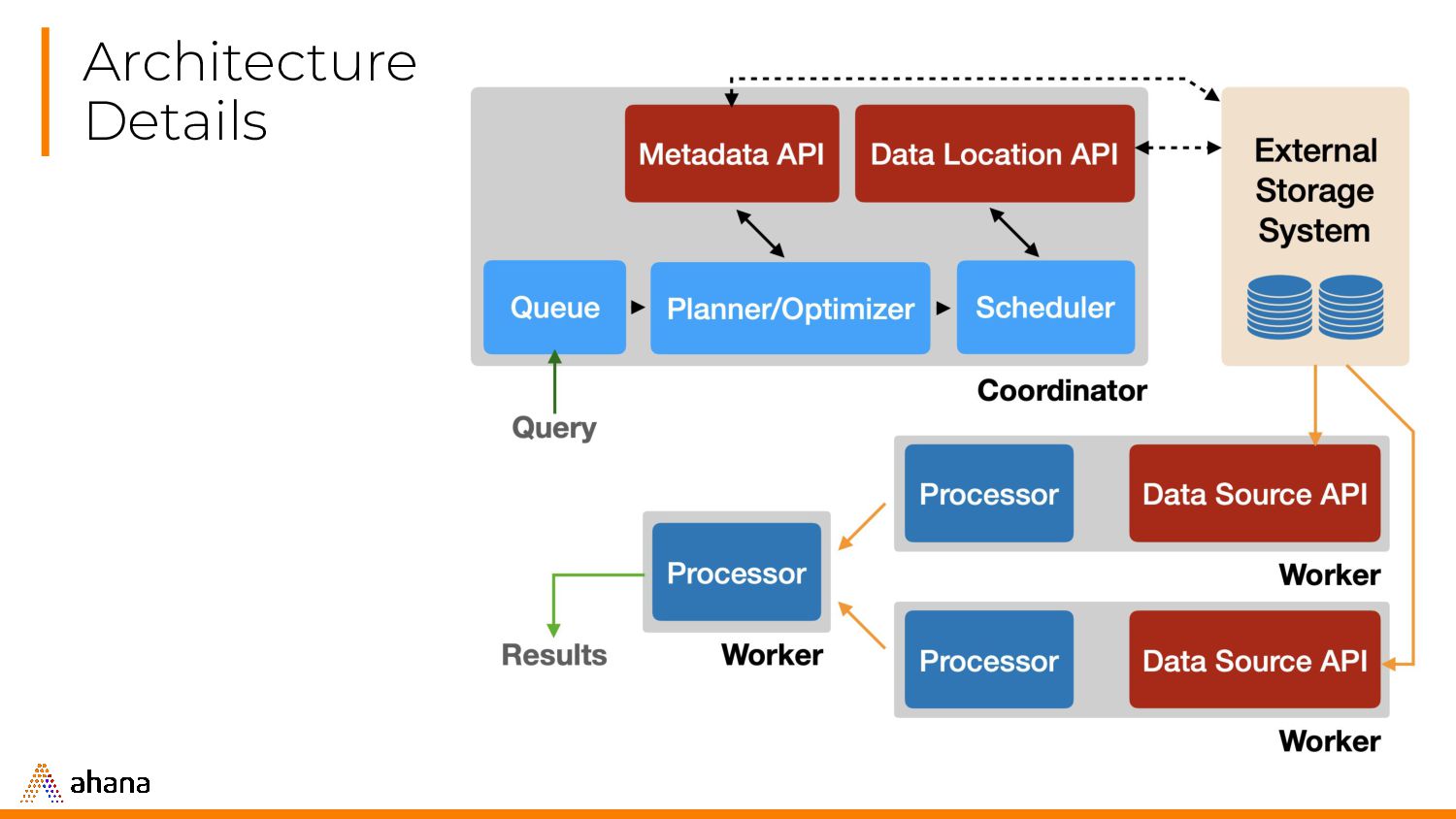
parses and plans queries, manages the Workers. • Worker. The “workhorse.” Executes tasks, fetches and processes data. Works together for distributed processing.
of catalogs, schemas, and tables. • A table is like a database table. • Remember, though, Presto can connector to data sources that are NOT databases underneath. As we know, a data lake is just a bunch of files. tpch sf1 sf100 customer orders customer Table Schema Catalog
multiple catalogs using the same connector type. For example: I can have multiple MySQL catalogs to different or the same MySQL instance. SHOW CATALOGS;
collection of tables • How it maps to the underlying data source is through the connector design. For relational sources, it’s straightforward; others, such as NoSQL, will be what makes sense for that source.
qualified name: catalog_name.schema_name.table_name Example: tpch.sf100.customer • Typing the fully qualified name can be cumbersome, especially if you primarily working in the same schema. You can tell Presto to scope assume a particular catalog-schema scope with: USE catalog_name.schema_name; Example: USE tpch.sf100;
Minutes. Managed cloud service: No installation and configuration. 2. Built for data teams of all experience level. 3. Moderate level of control of deployment without complexity. 4. Dedicated support from Presto experts.
Calendar date (year, month, day). • TIME. Time of day (hour, minute, second, millisecond) without a time zone. Values of this type are parsed and rendered in the session time zone. • TIME WITH TIME ZONE. Time of day (hour, minute, second, millisecond) with a time zone. Values of this type are rendered using the time zone from the value. • TIMESTAMP. Instant in time that includes the date and time of day without a time zone. Values of this type are parsed and rendered in the session time zone. • TIMESTAMP WITH TIME ZONE. Instant in time that includes the date and time of day with a time zone. Values of this type are rendered using the time zone from the value. • INTERVAL YEAR TO MONTH. Span of years and months. • INTERVAL DAY TO SECOND. Span of days, hours, minutes, seconds and milliseconds.
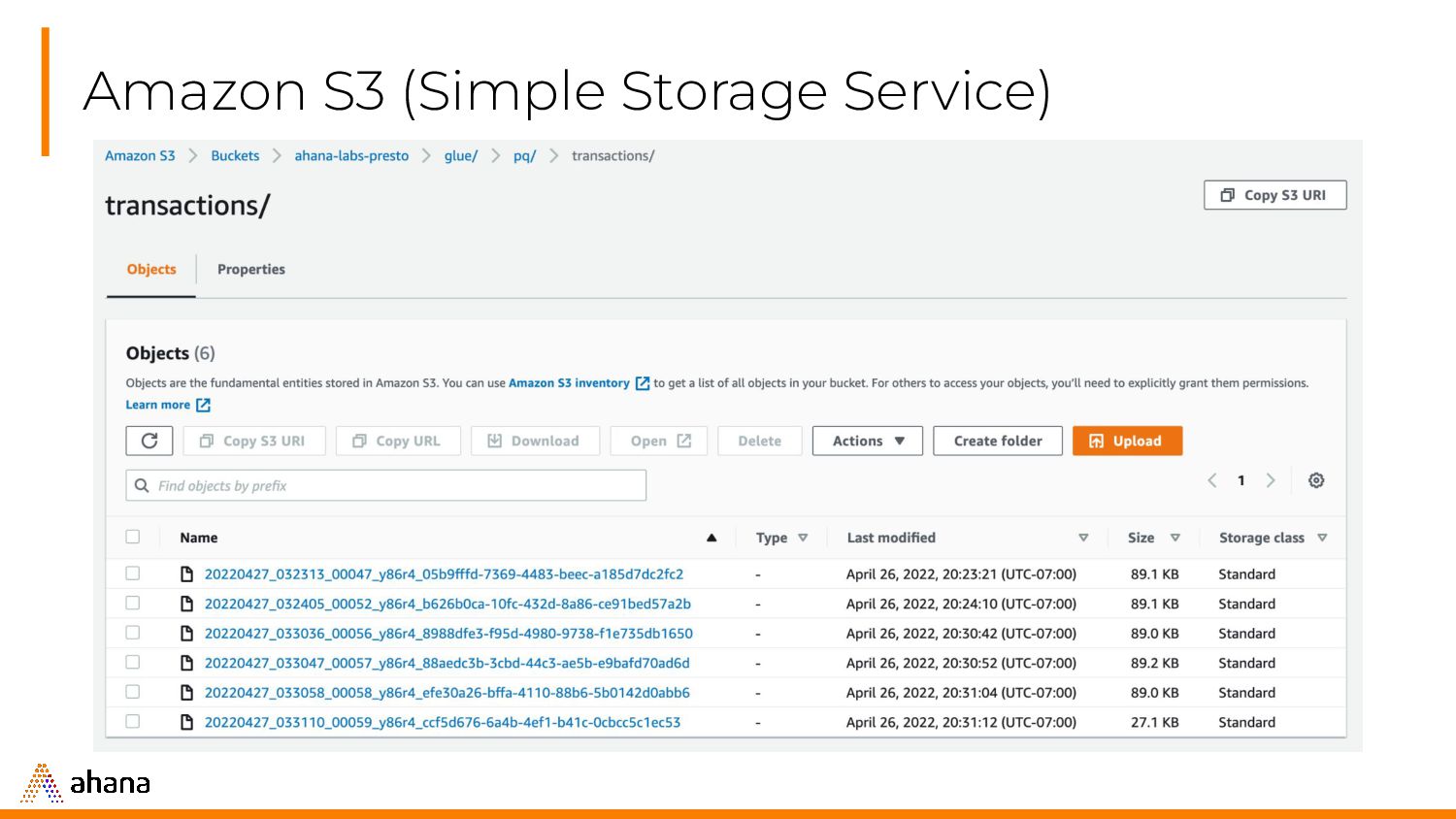
sum(amt) as total FROM glue.pq.transactions GROUP BY category; Metadata Catalog Table transactions is located at: s3://ahana-labs-presto/glue/pq/transactions s3://ahana-labs-presto/glue/pq/transactions
Lakehouse Data Science, ML, & AI Reporting and Dashboarding Data Warehouse Proprietary Storage Proprietary SQL Query Processing Governance, Discovery, Quality & Security ML and AI Frameworks SQL Query Processing Cloud Data Lake Open Formats Storage Reporting and Dashboarding
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}