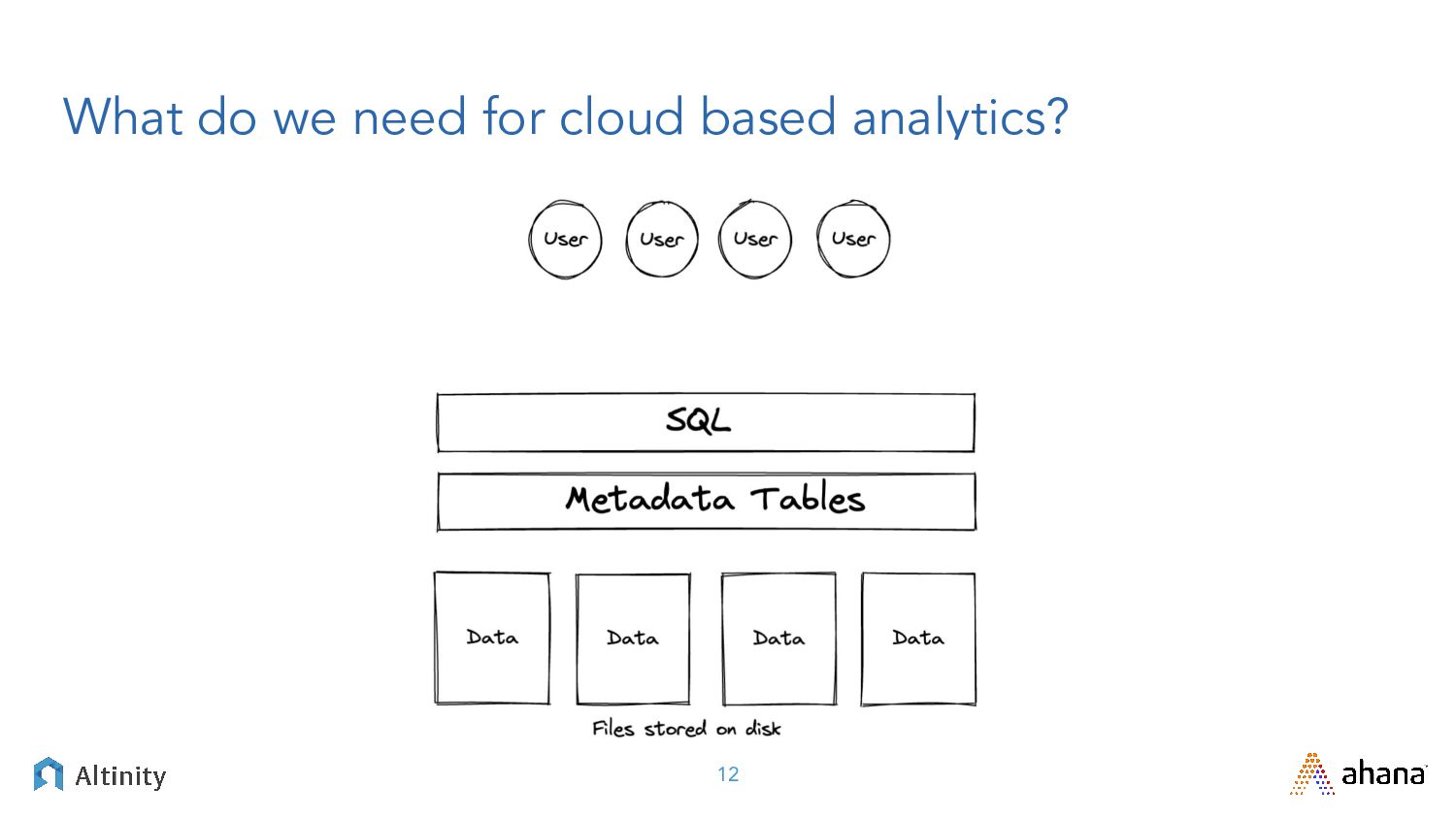
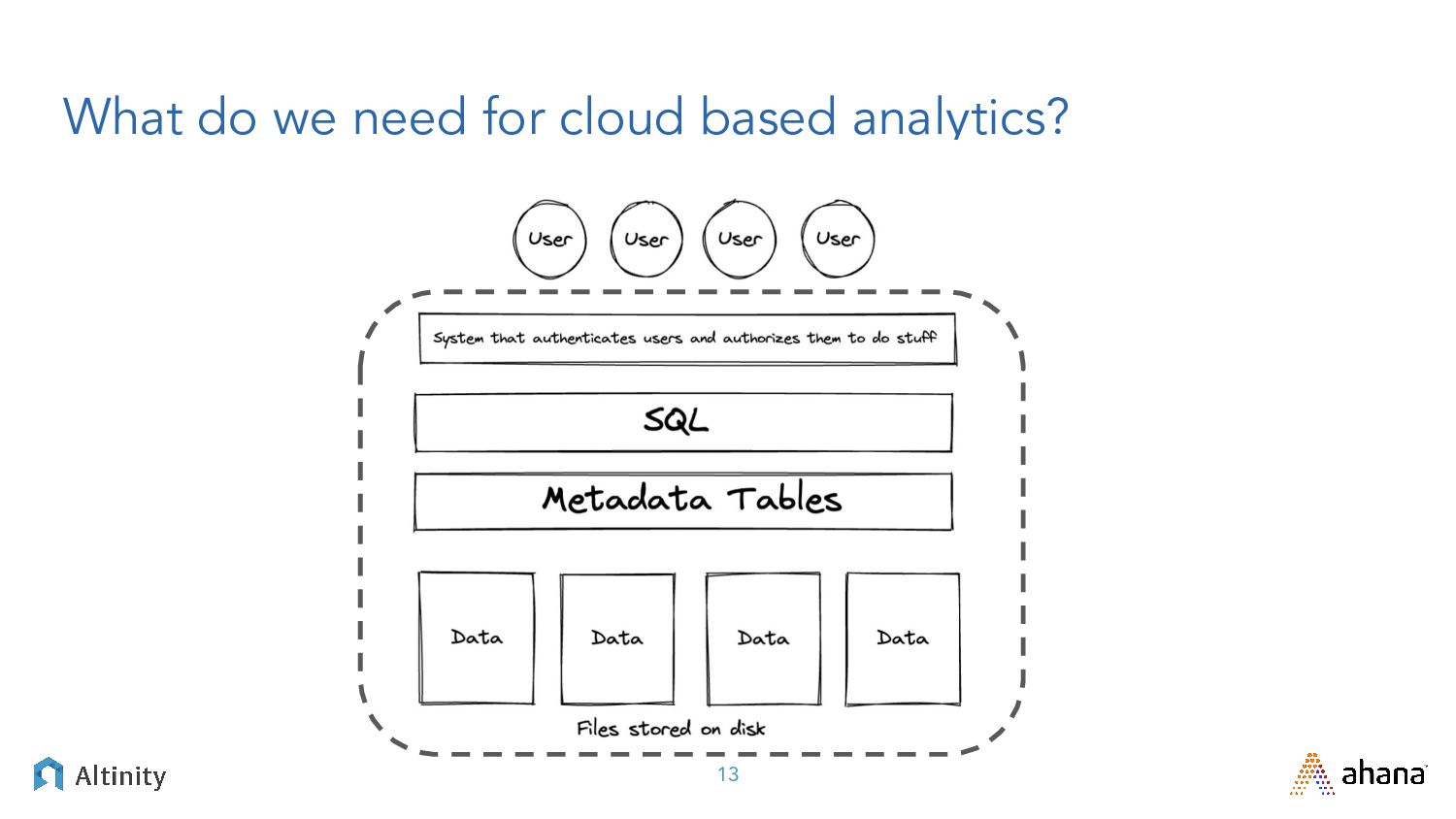
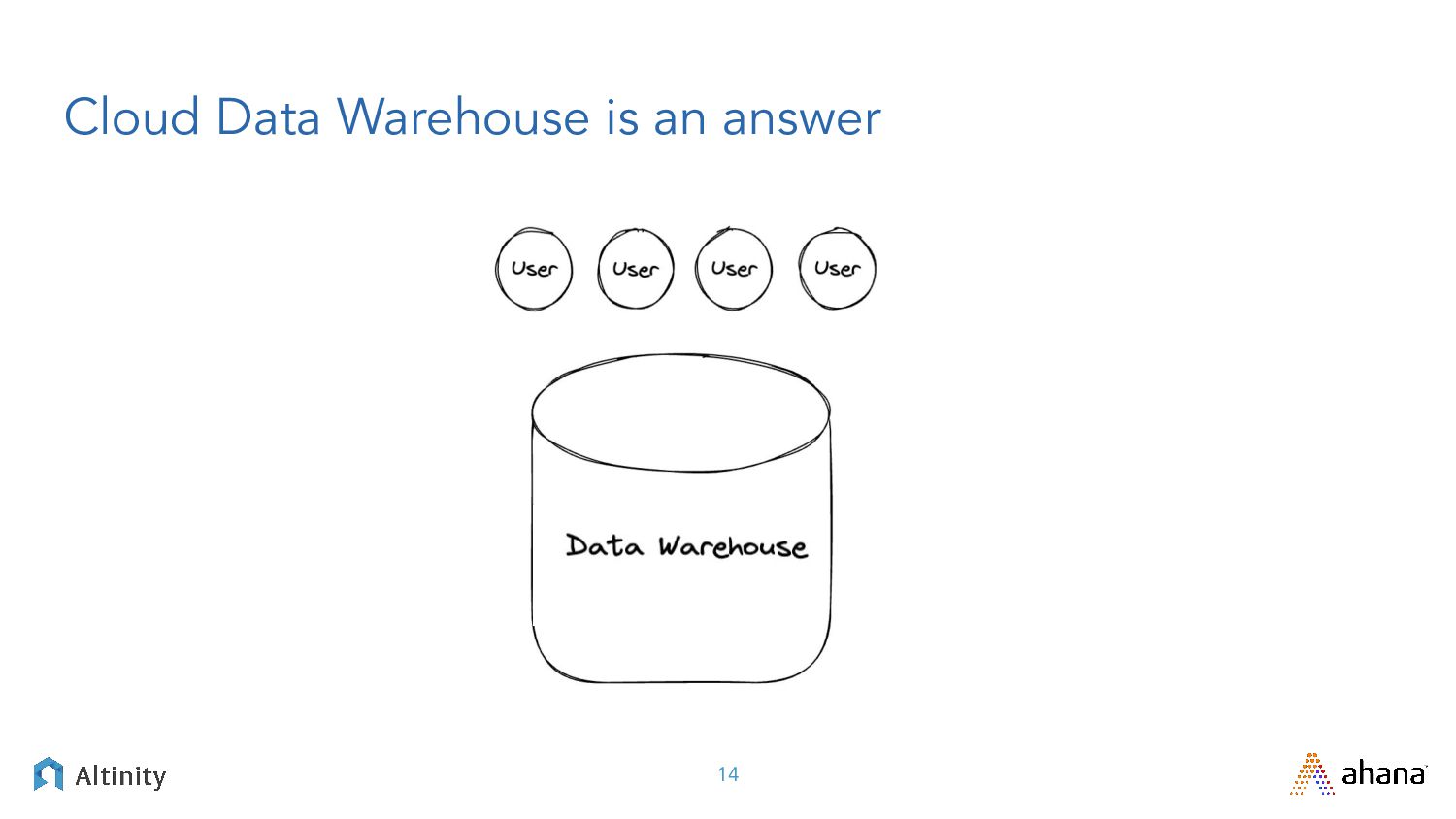
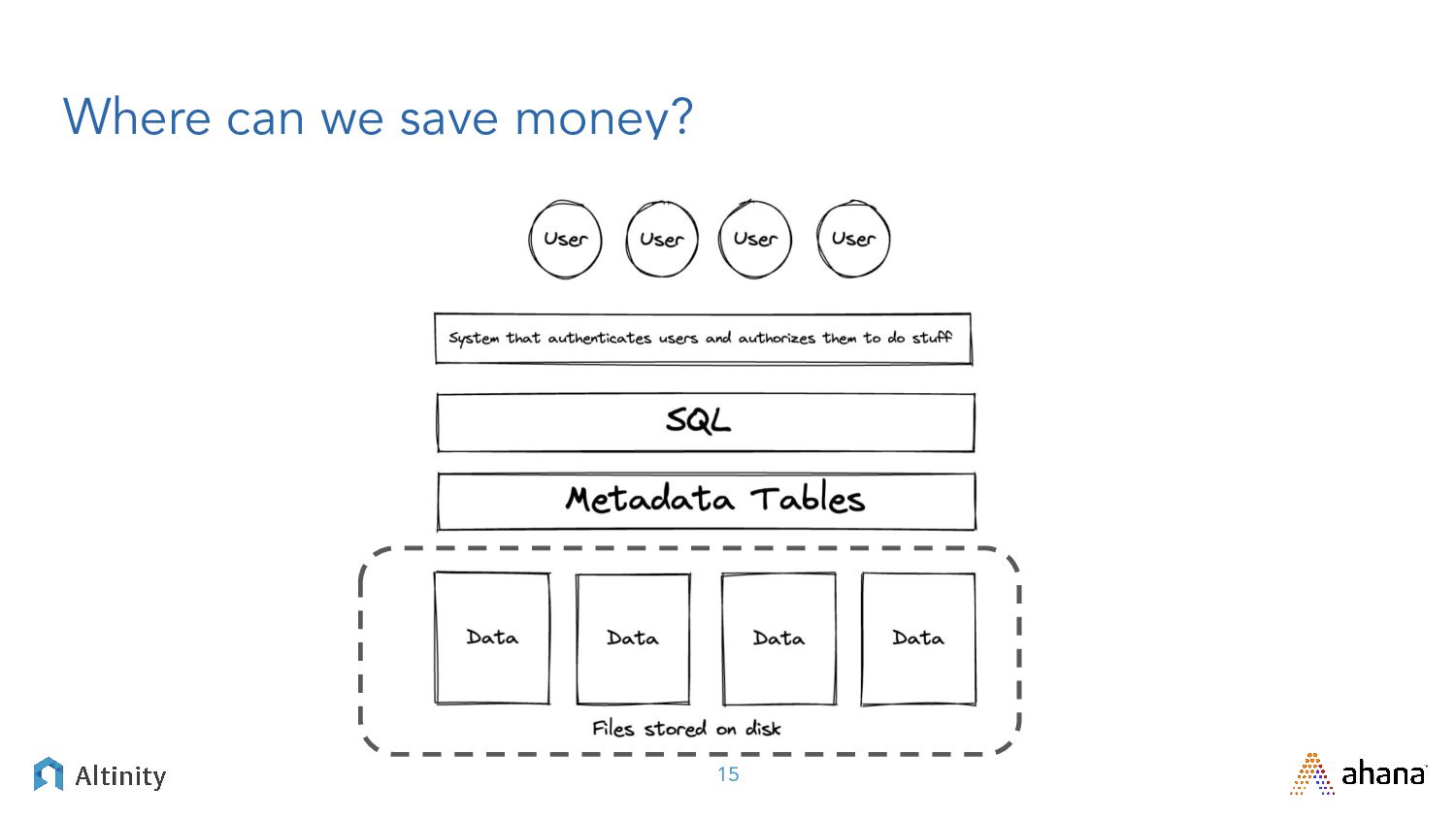
Big data these days means big, fast, or both, and there’s a lot of technologies that promise to fulfill various pieces of that big data architecture.
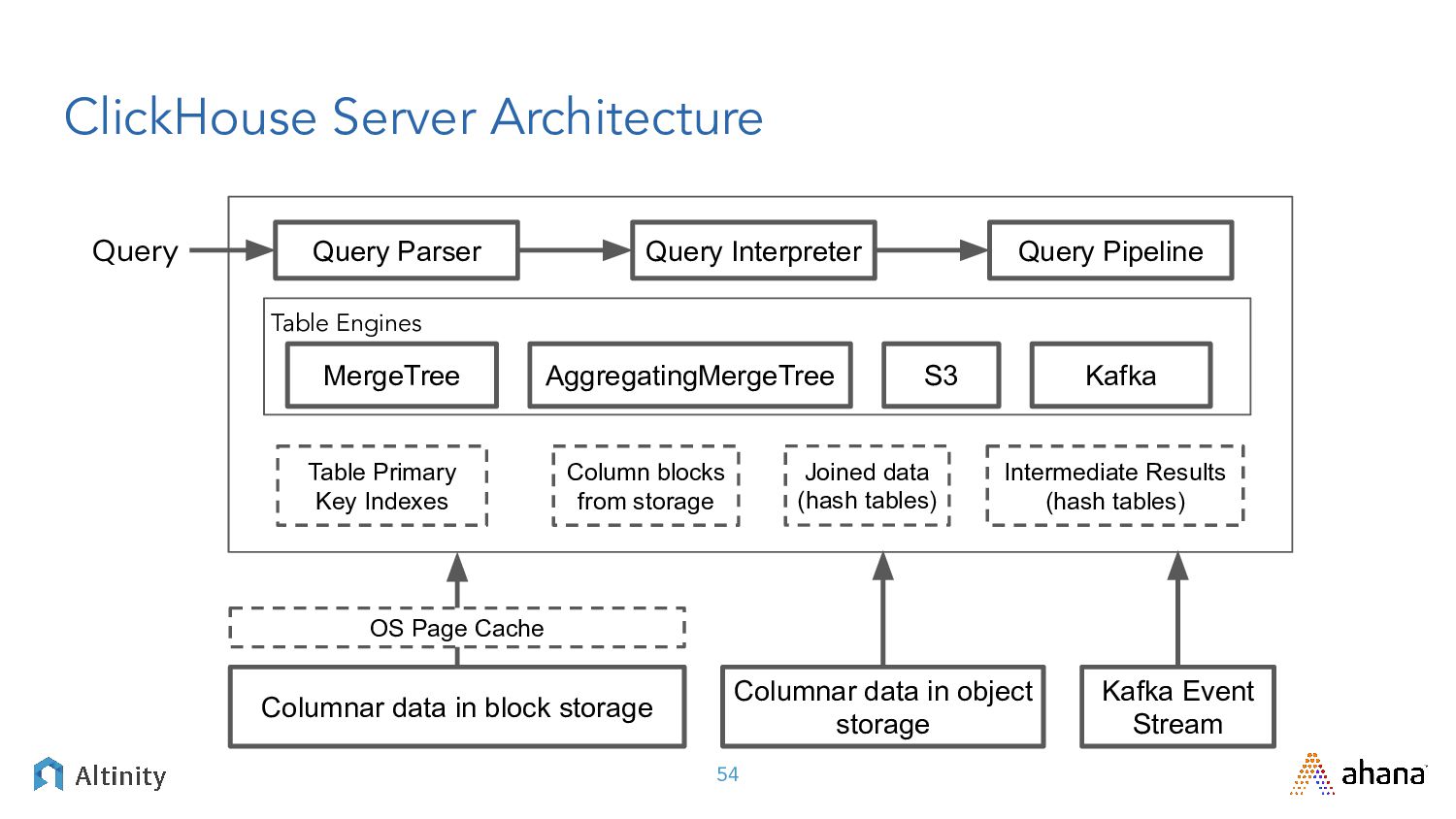
Join us for this webinar we’re delivering in partnership with Altinity where we’ll explore open source big data solutions. We’ll contrast Presto, the leading SQL Query engine for data lakes, with ClickHouse, the DBMS champ for real-time analytics. After framing the problem with relevant use cases we’ll dig into solutions using Presto and ClickHouse.
You can expect a deep dive into the plumbing that exposes key trade-offs between approaches. Join us for an enlightening discussion filled with practical advice for your next big data project!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
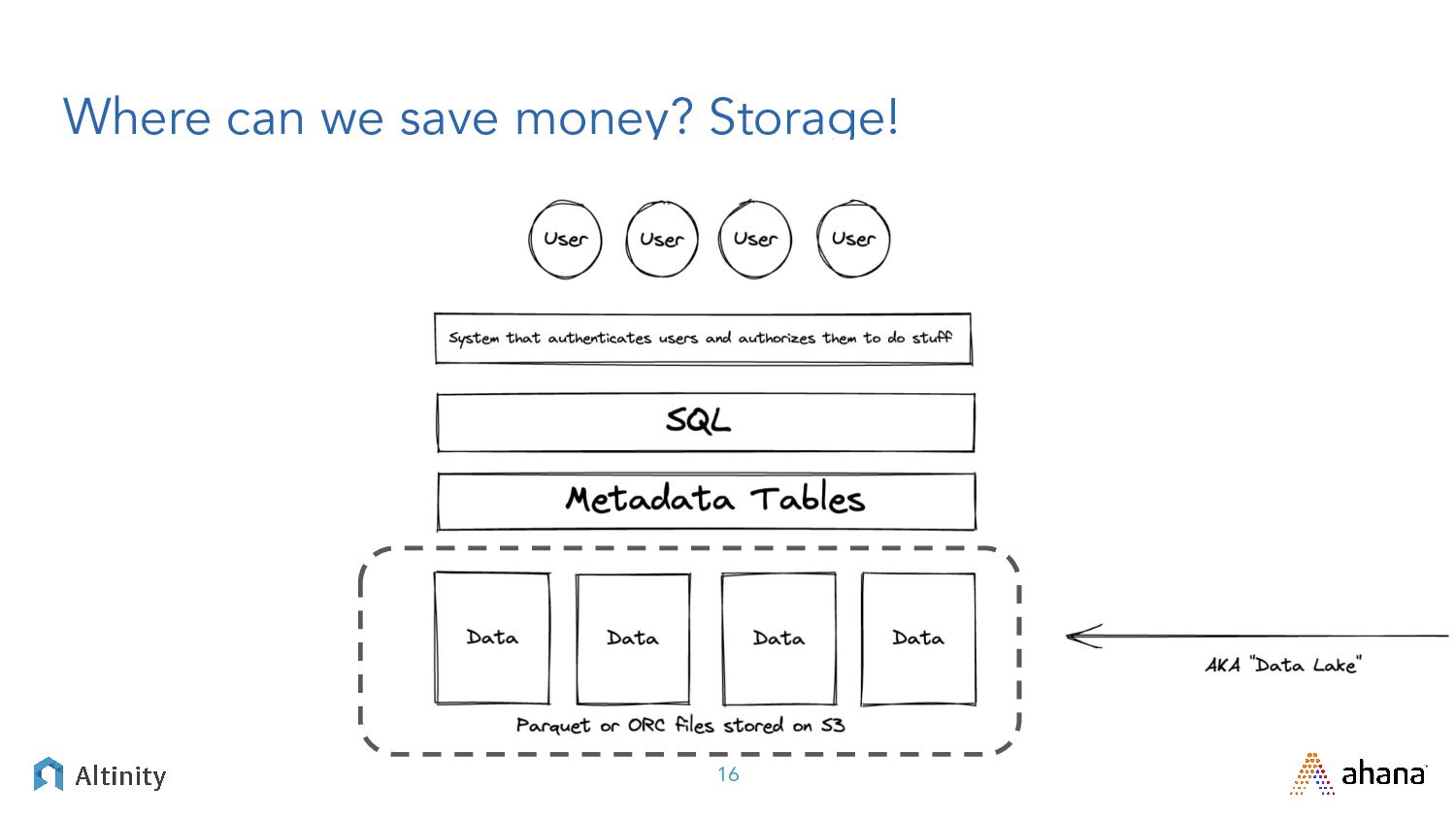{kind=link}
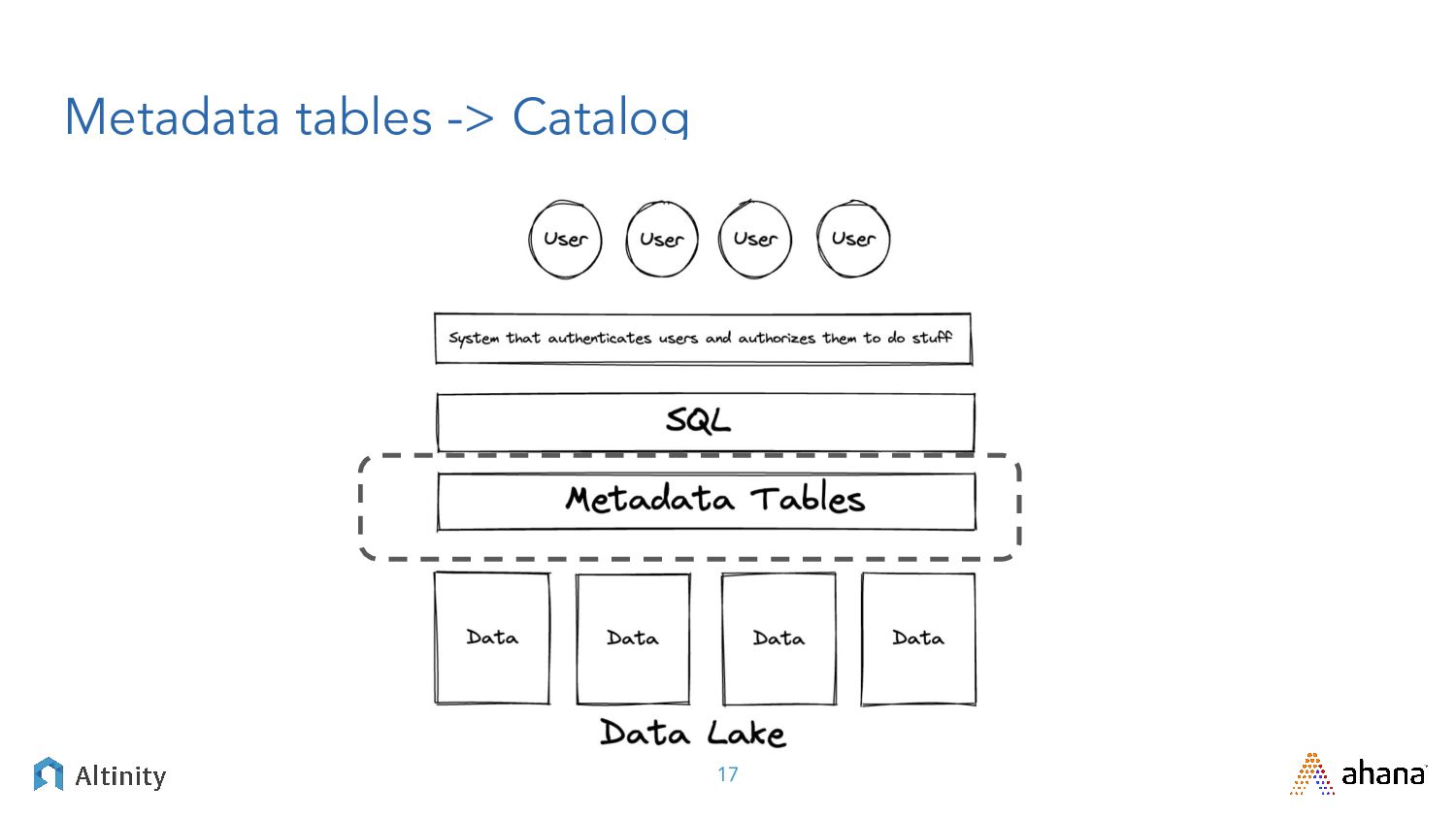{kind=link}
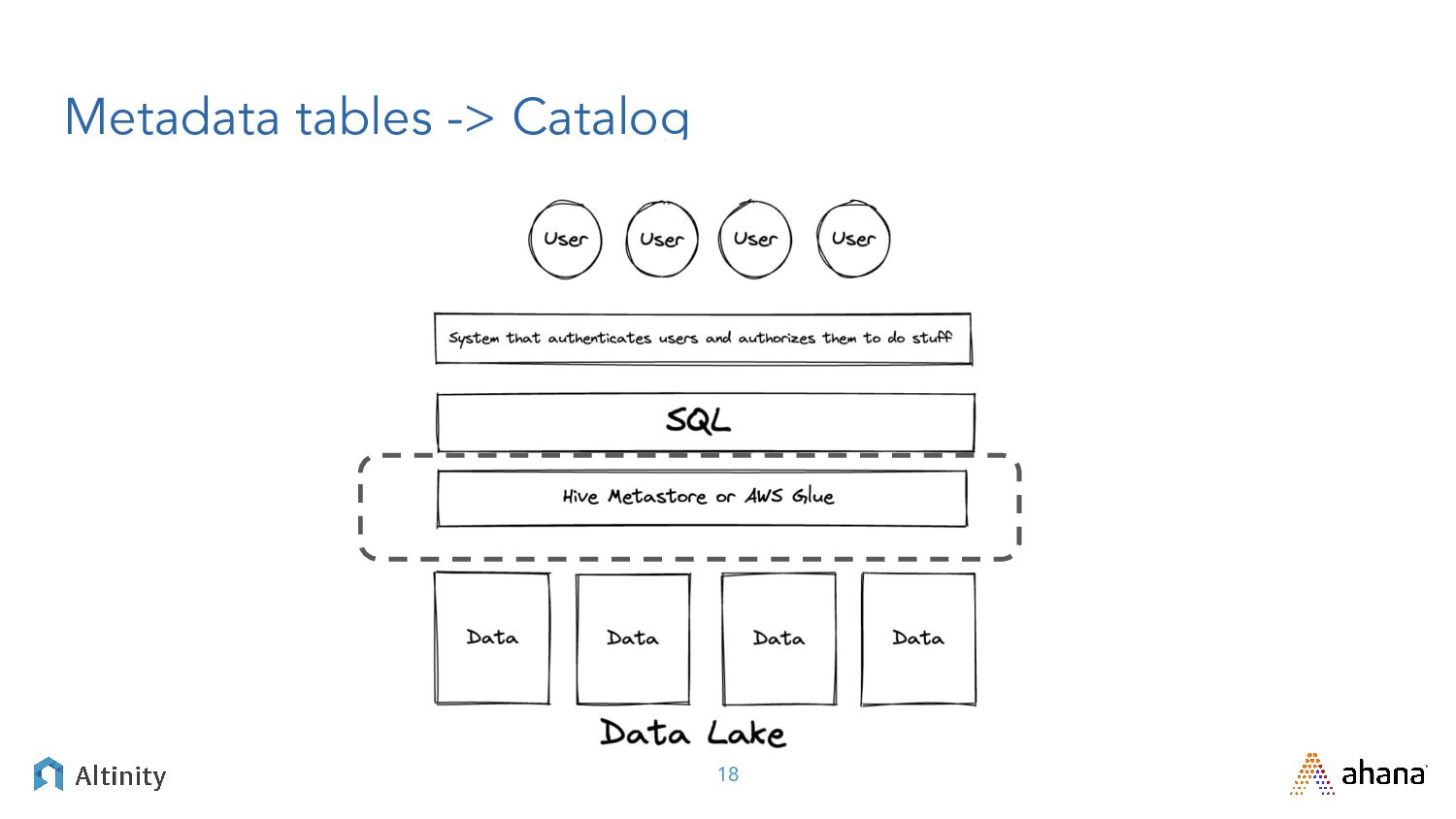{kind=link}
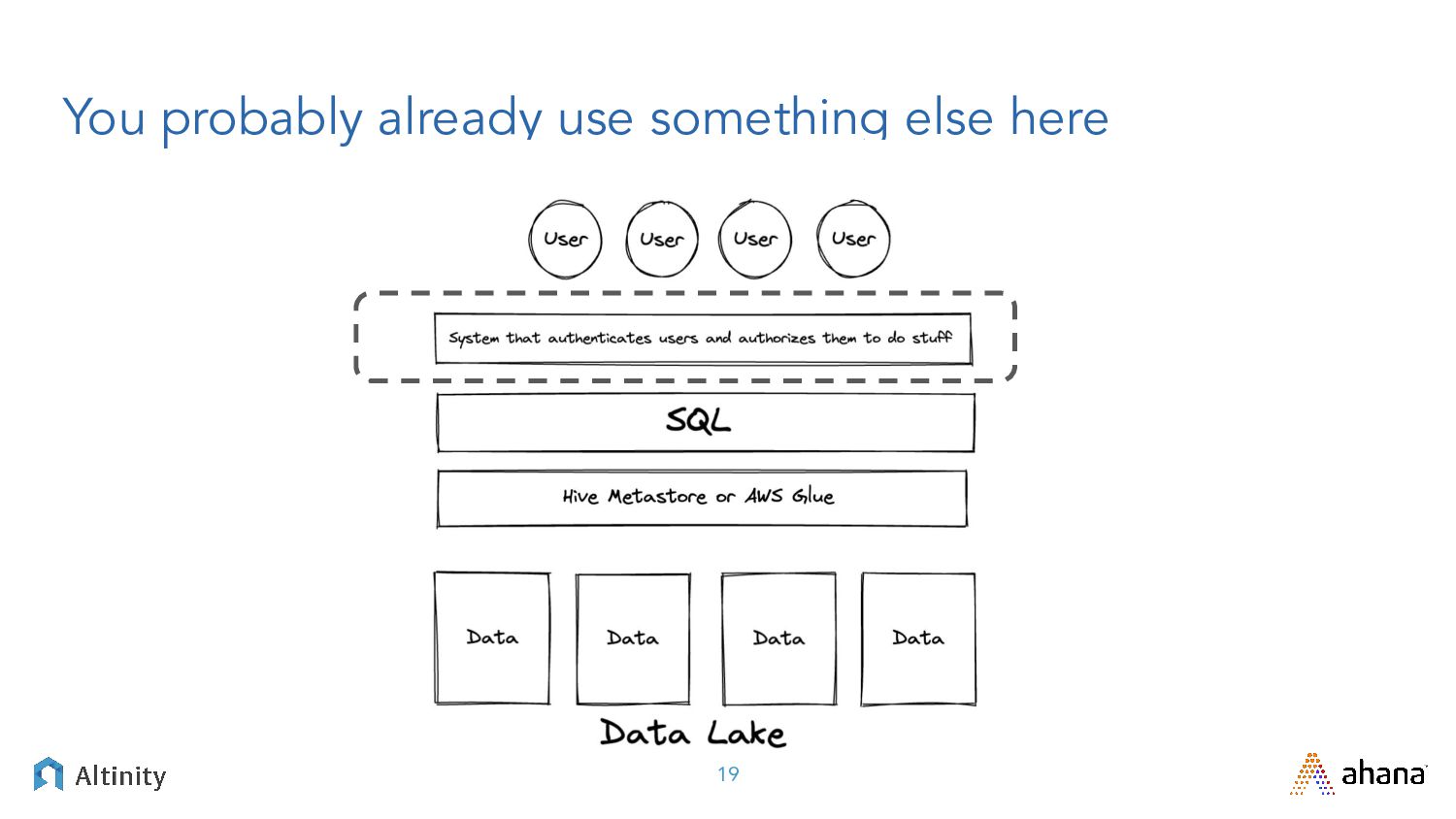{kind=link}
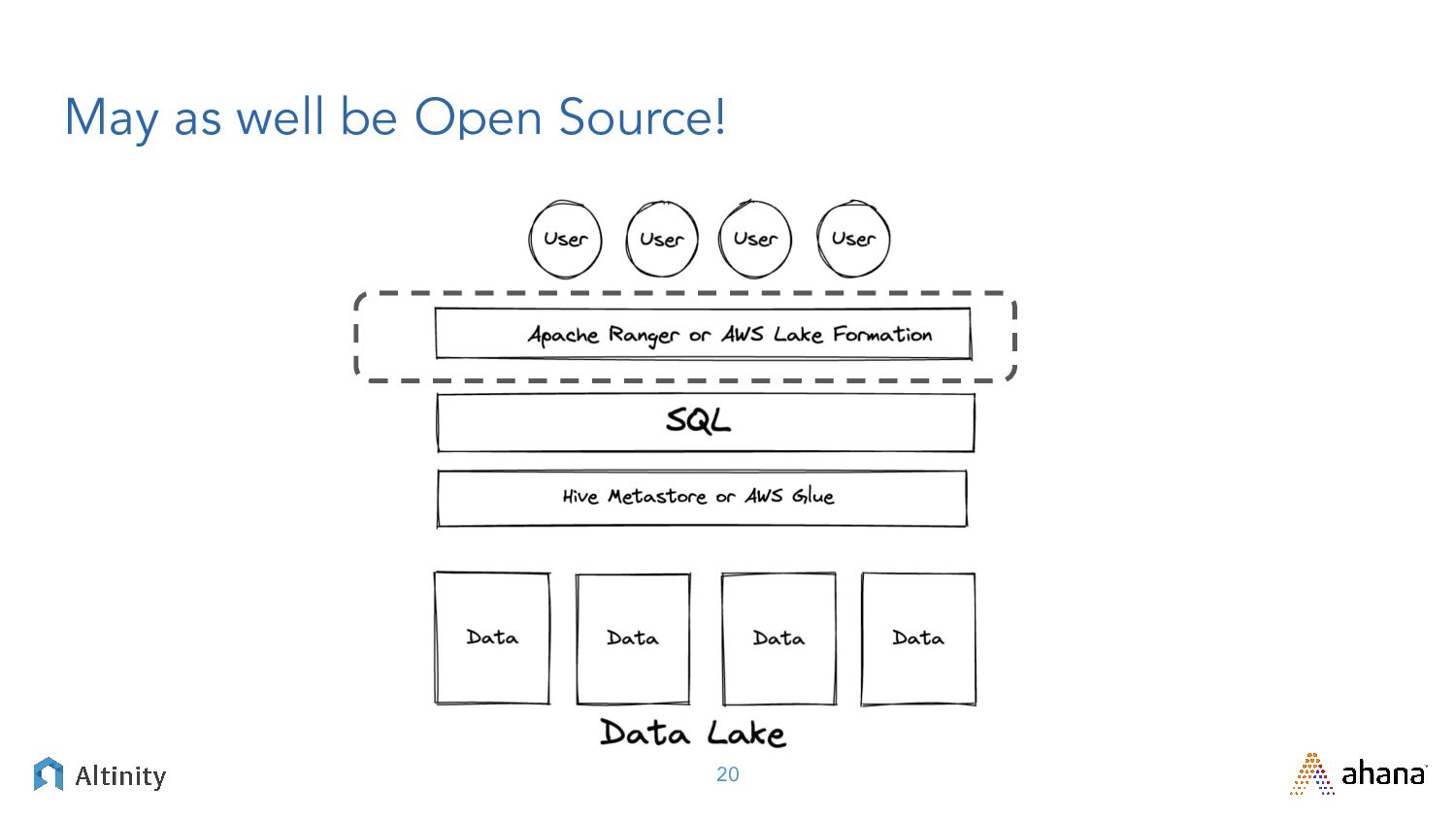{kind=link}
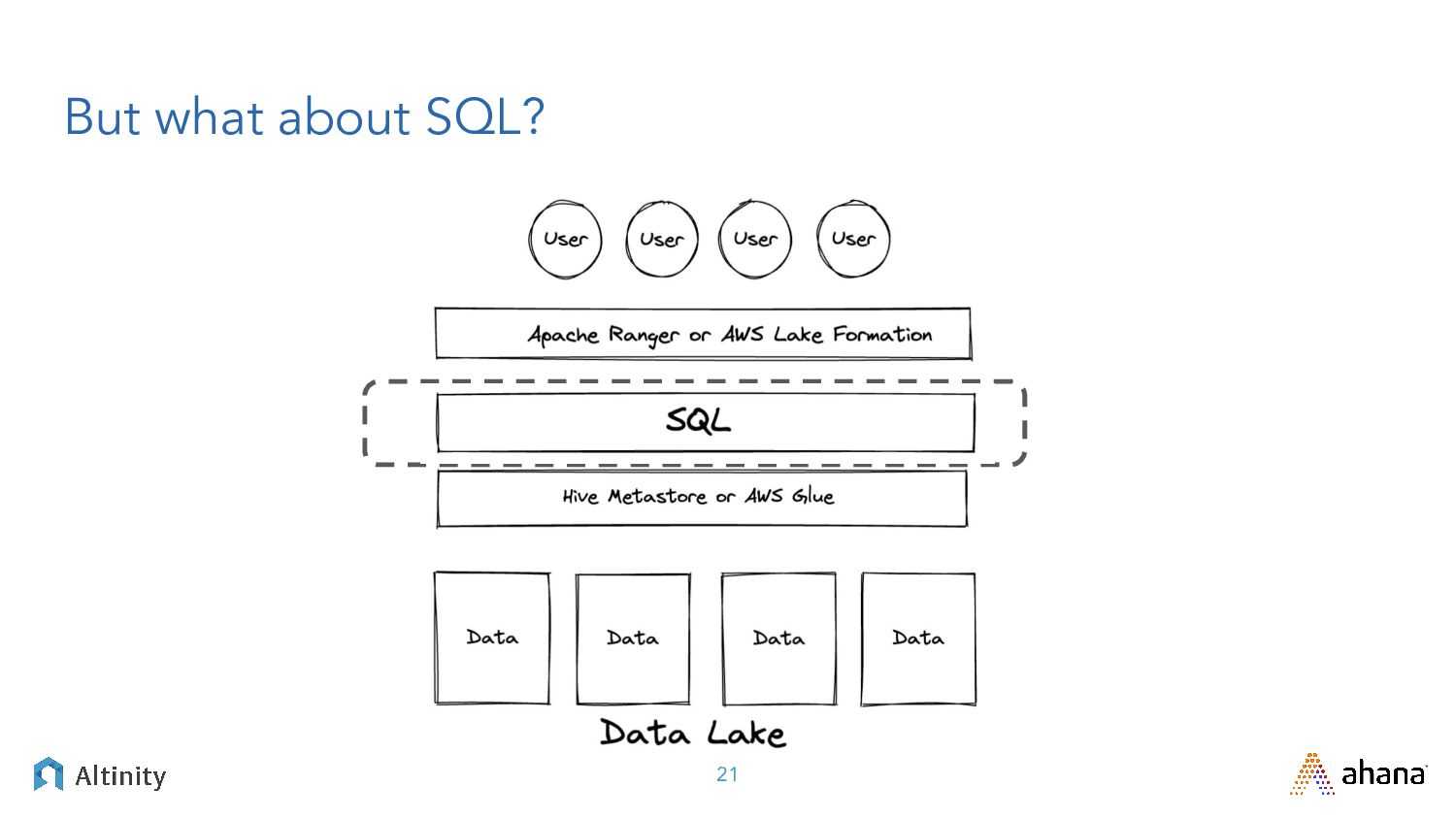{kind=link}
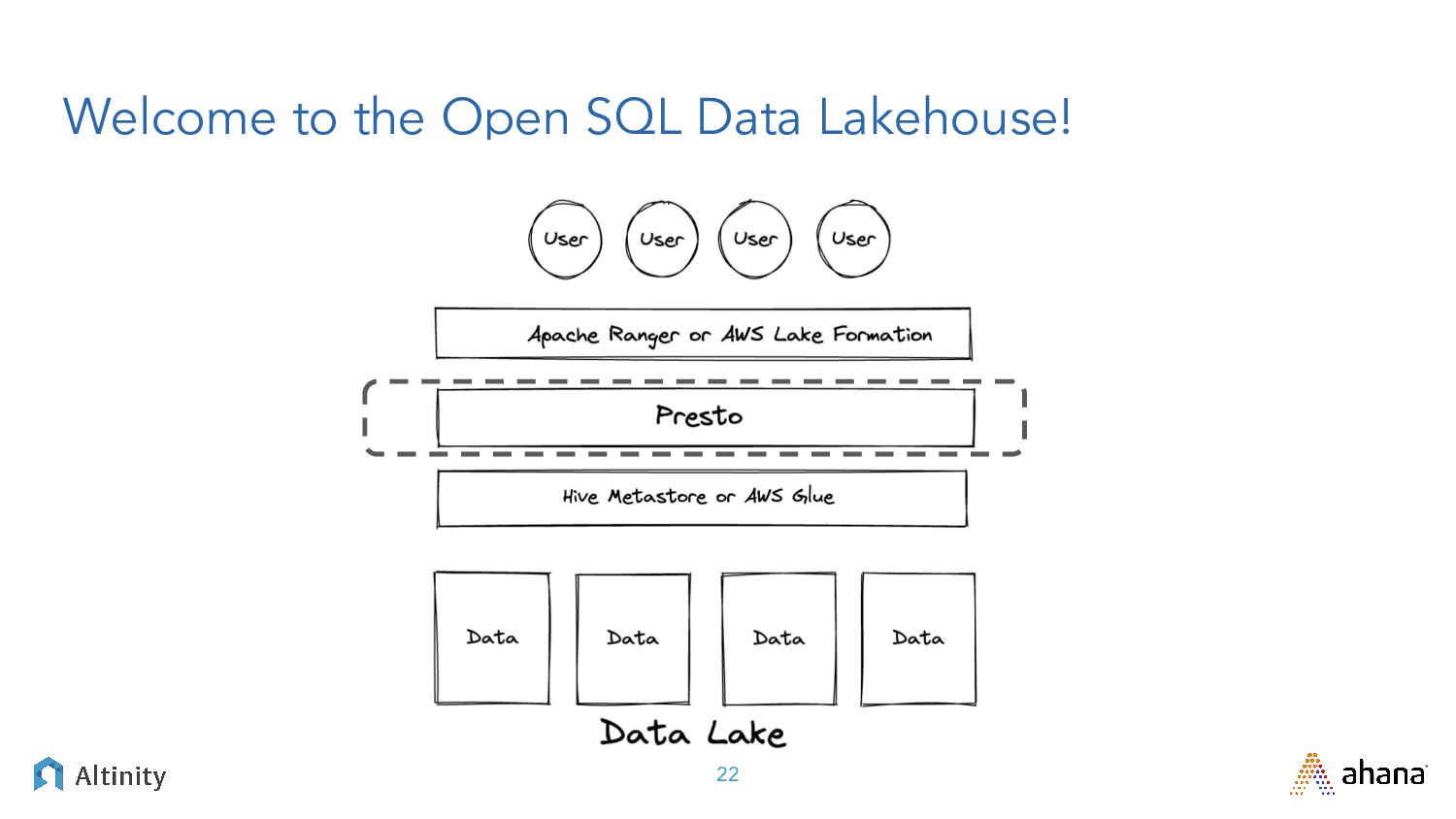{kind=link}
{kind=link}
{kind=link}
{kind=link}
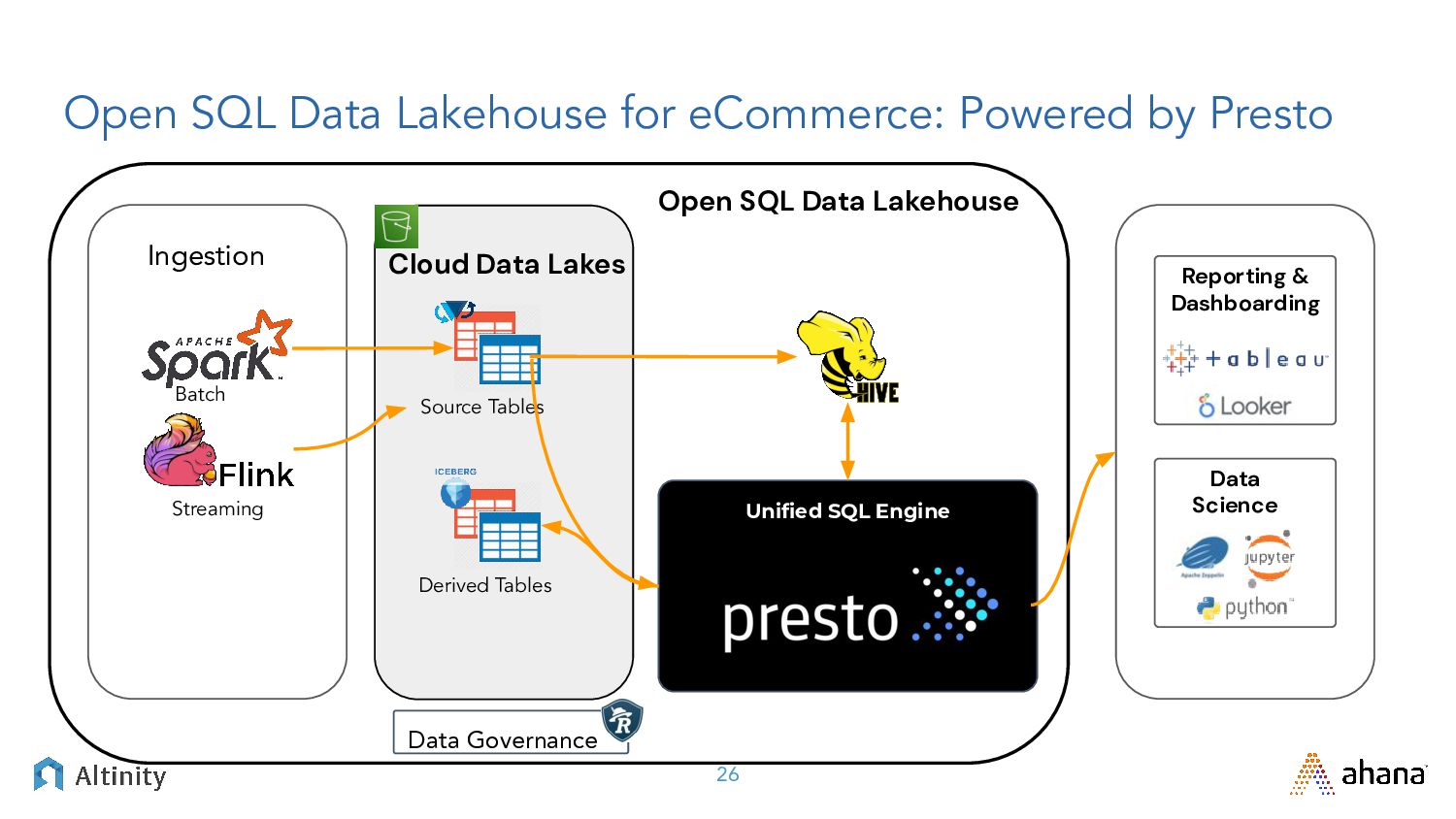{kind=link}
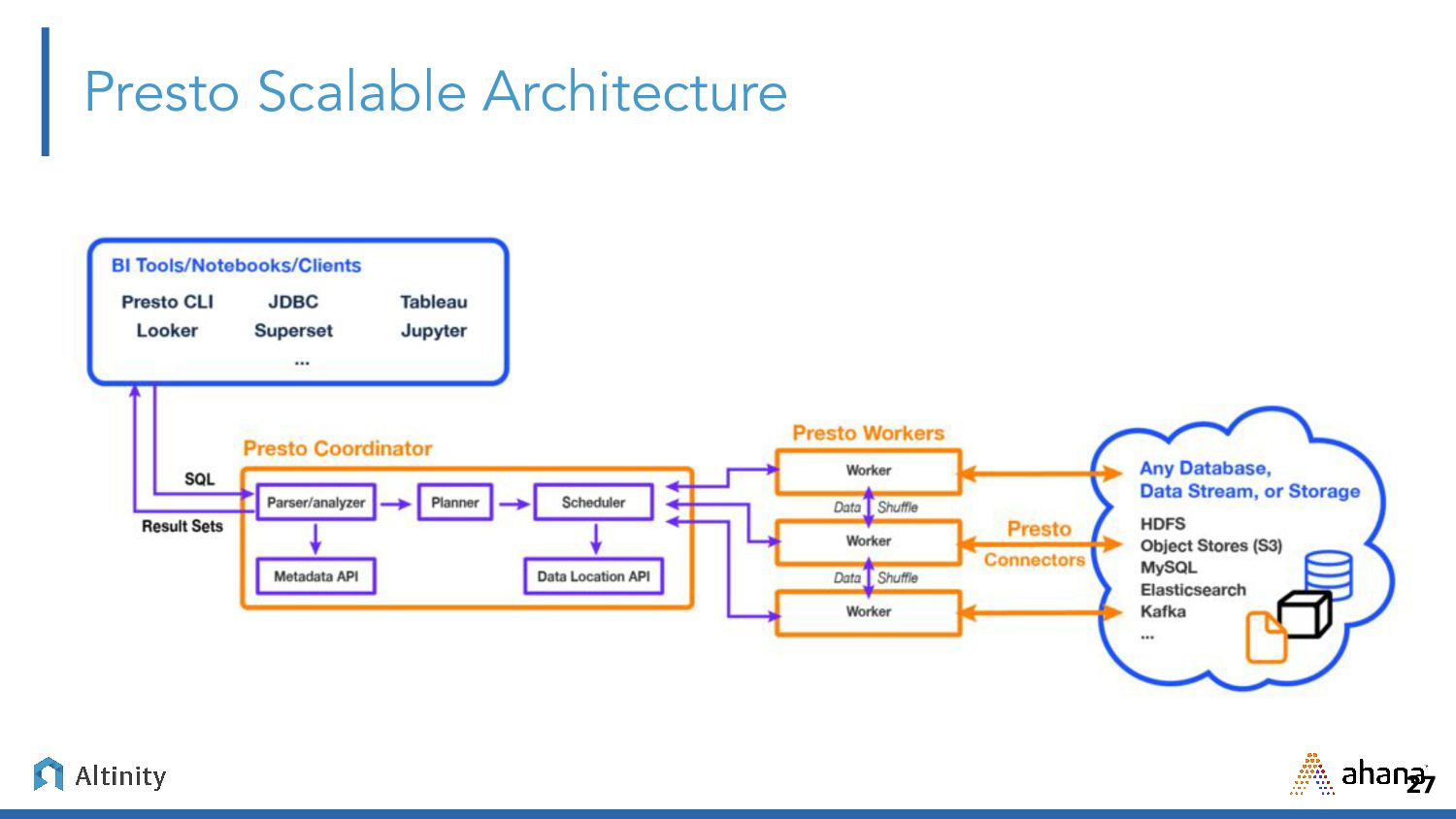{kind=link}
{kind=link}
{kind=link}
{kind=link}
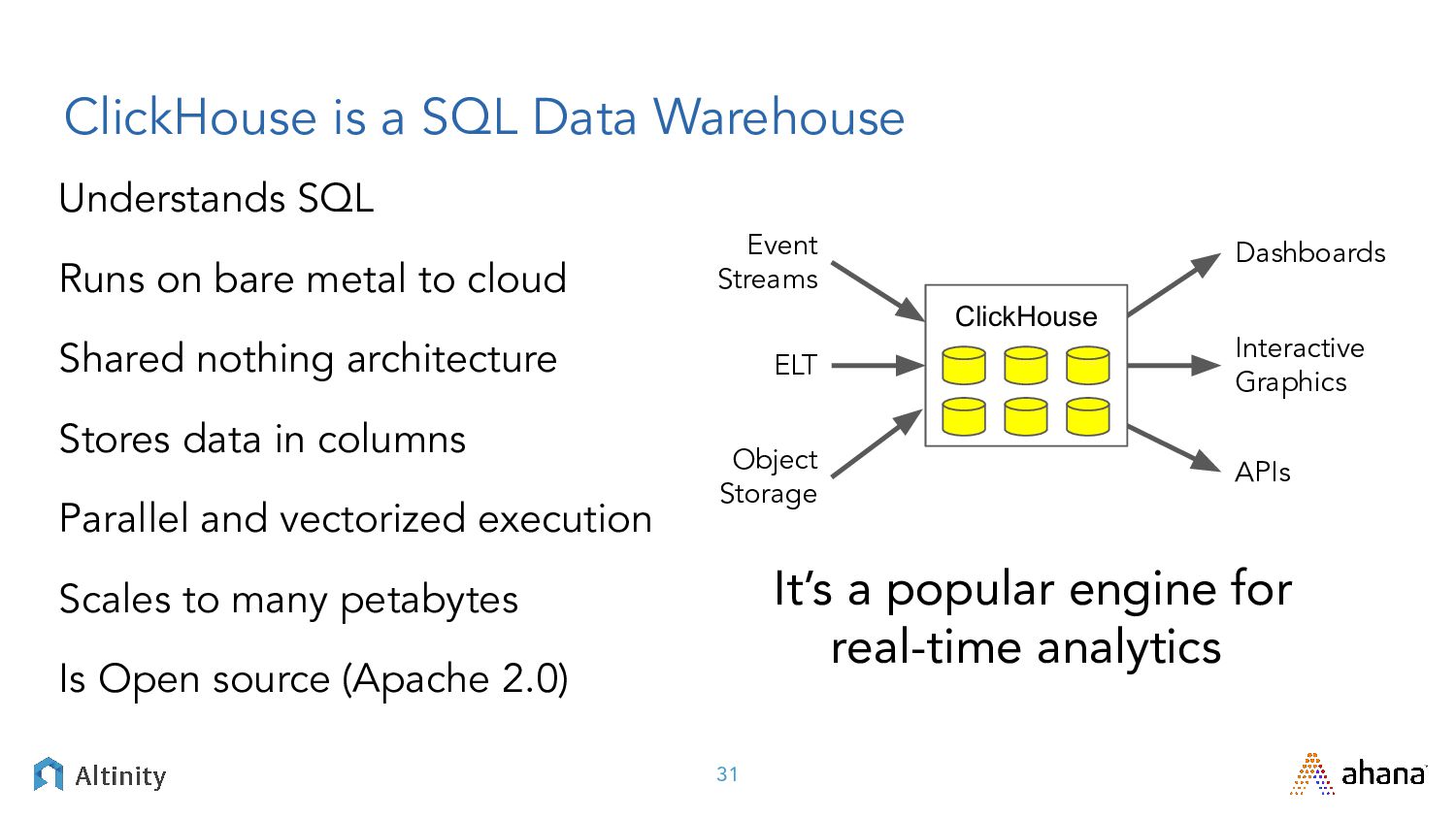{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
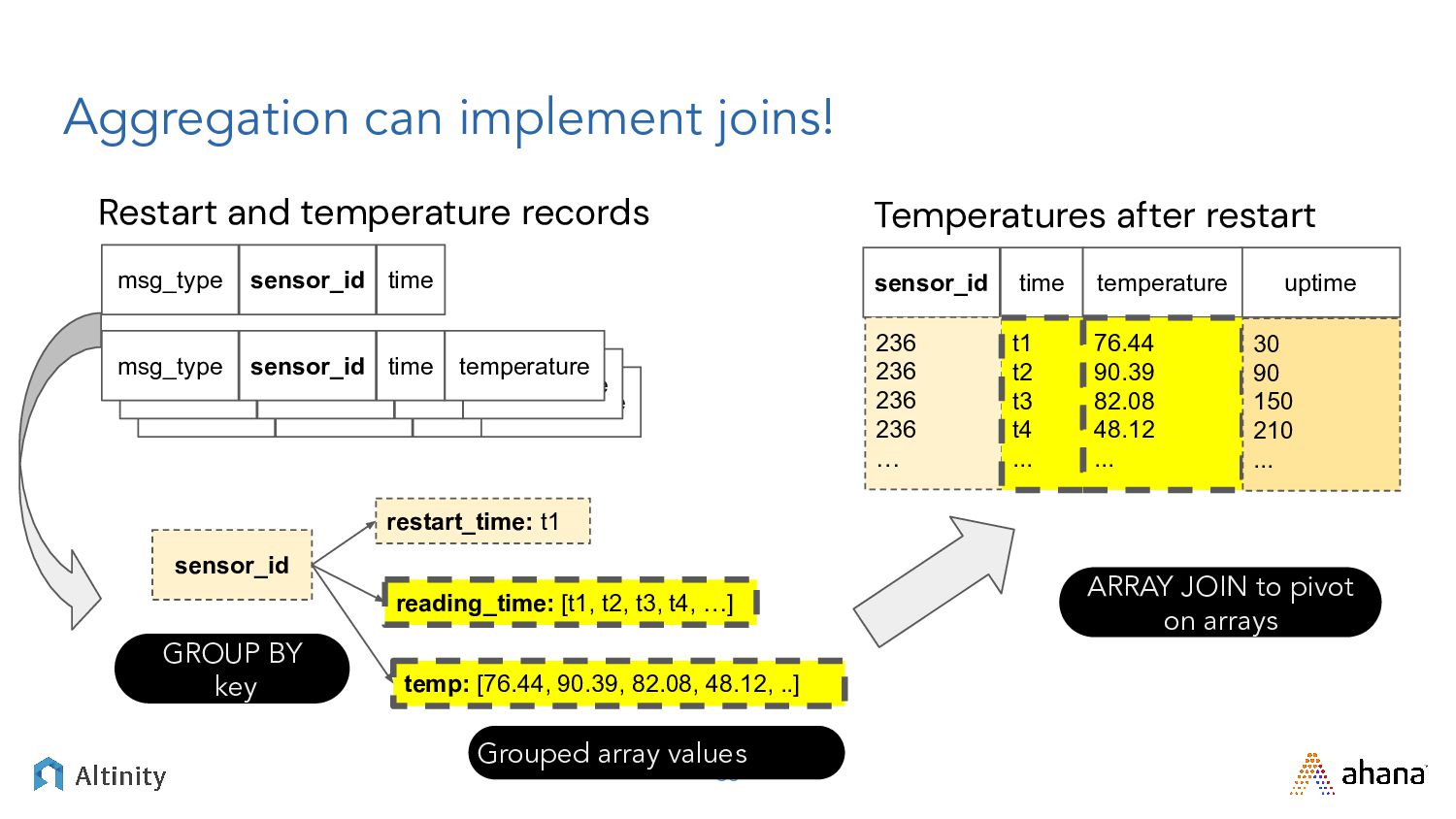{kind=link}
{kind=link}
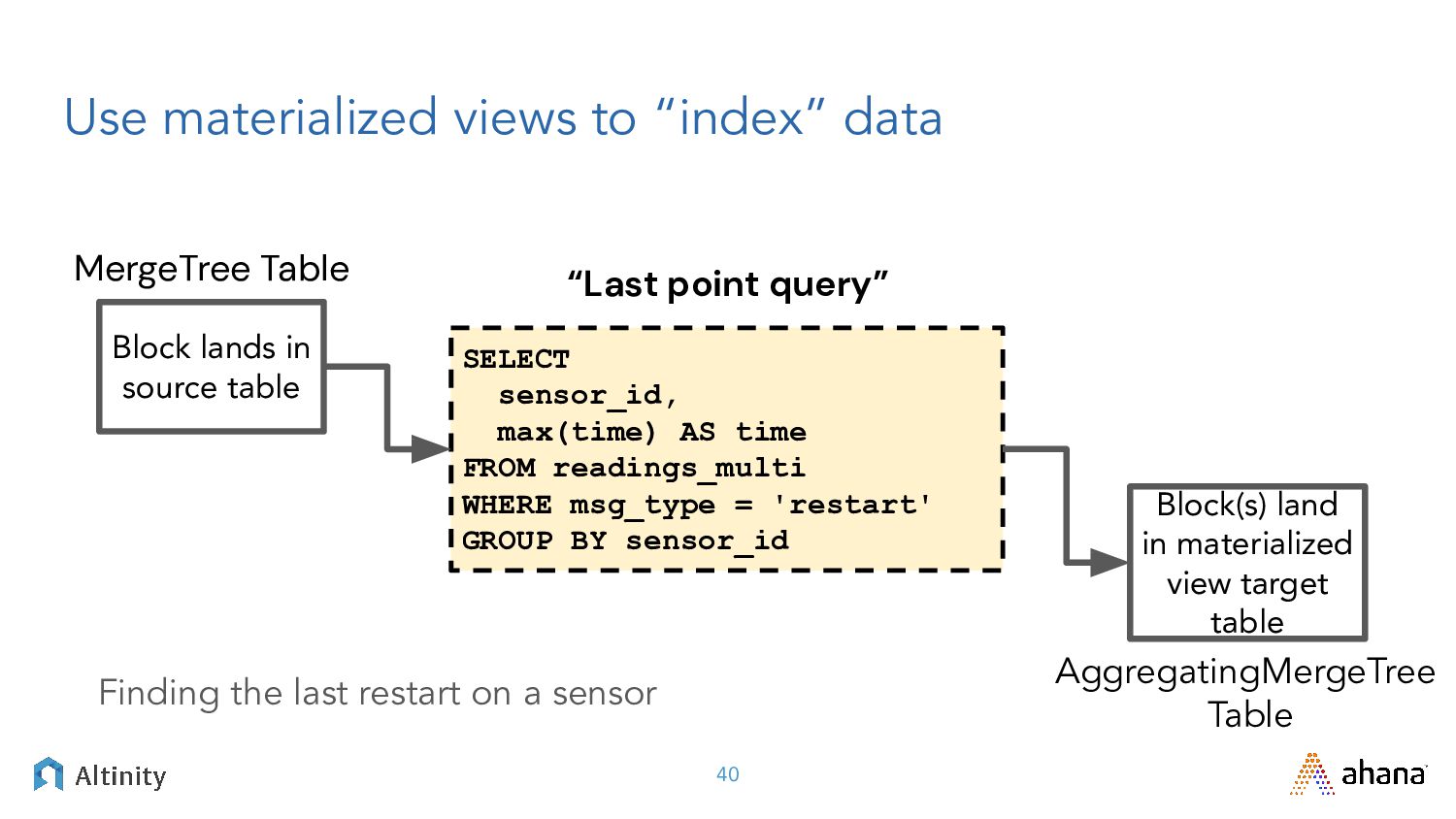{kind=link}
{kind=link}
{kind=link}
{kind=link}
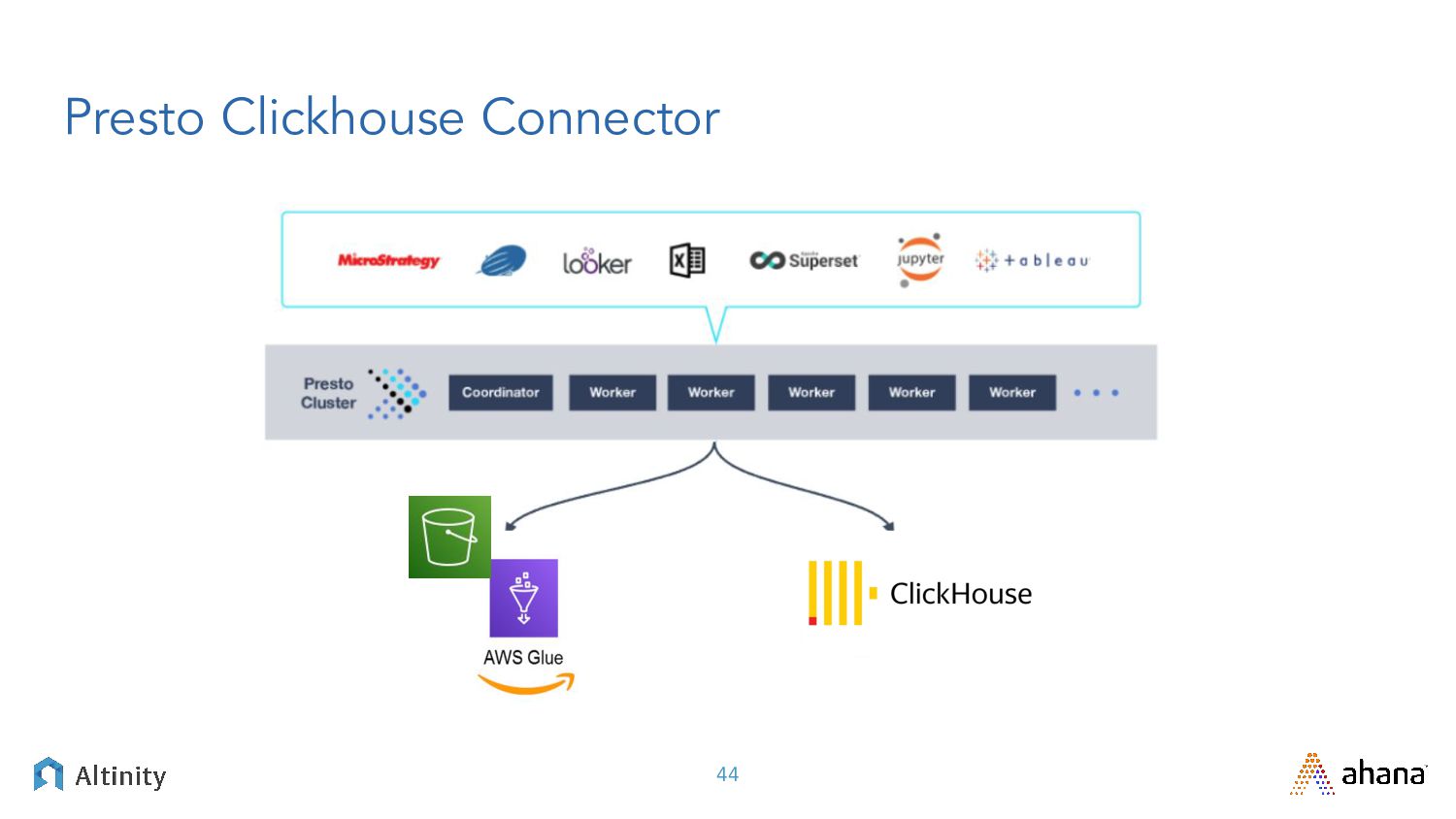{kind=link}
{kind=link}
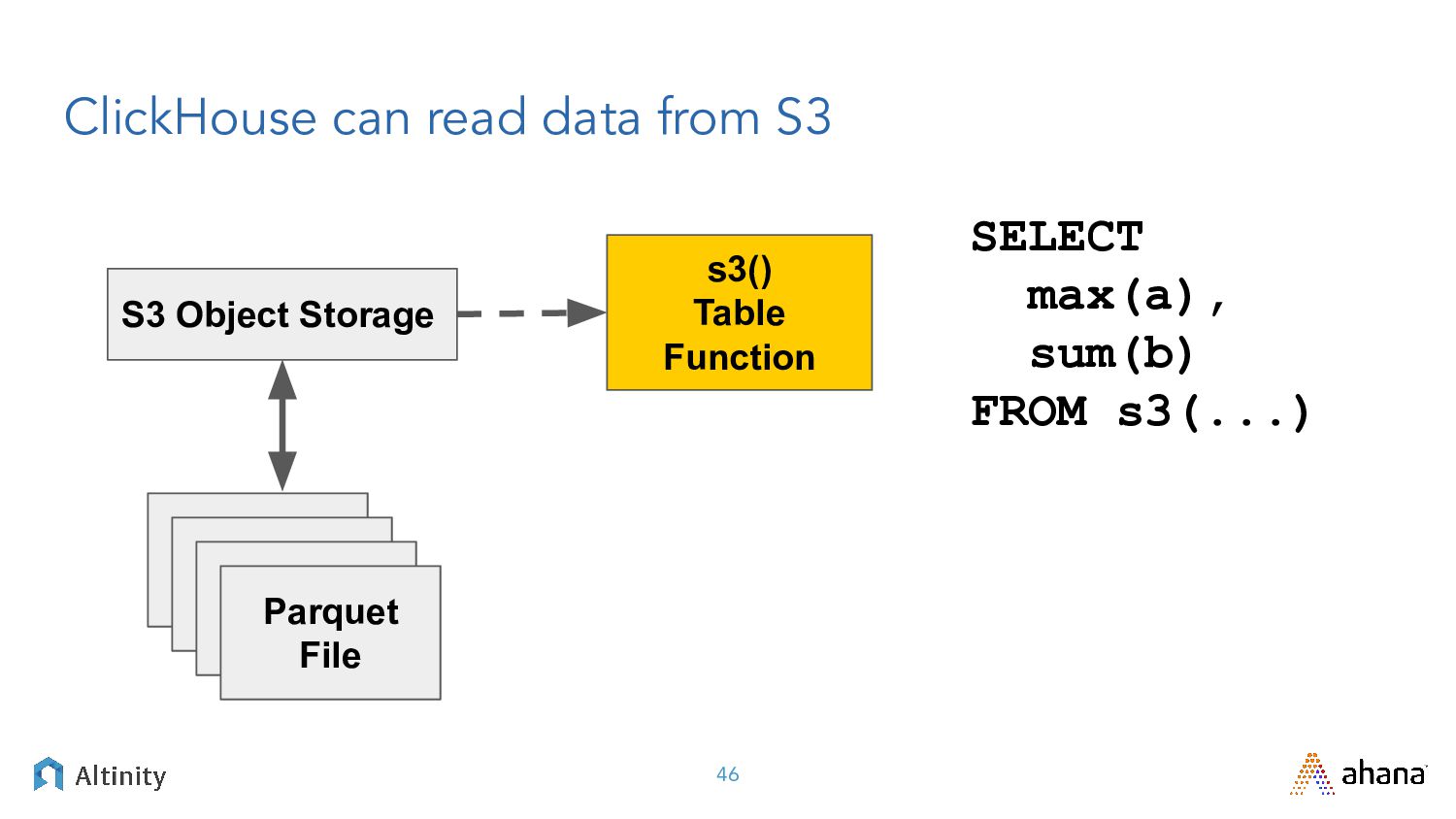{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
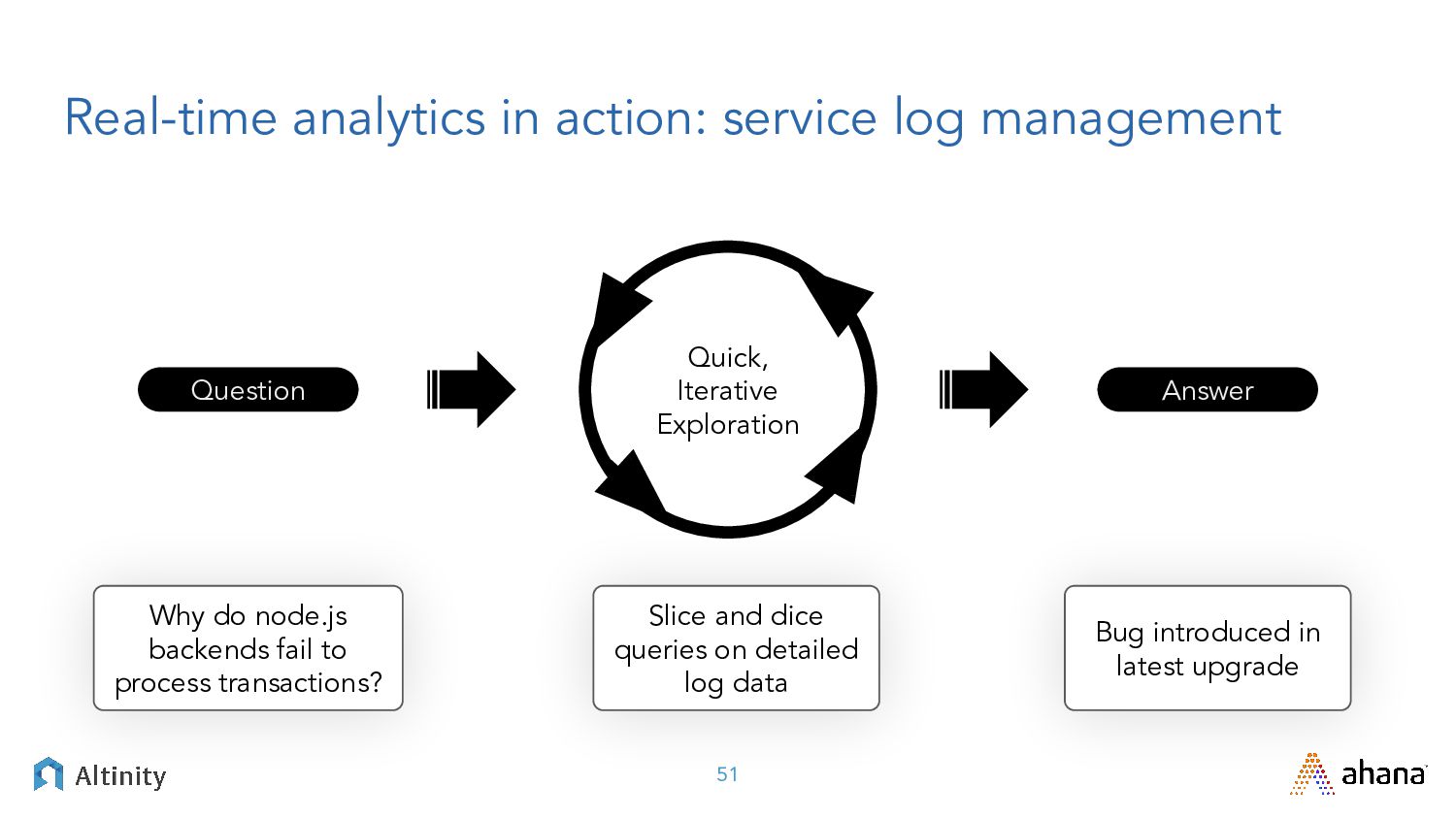{kind=link}
{kind=link}
{kind=link}
{kind=link}