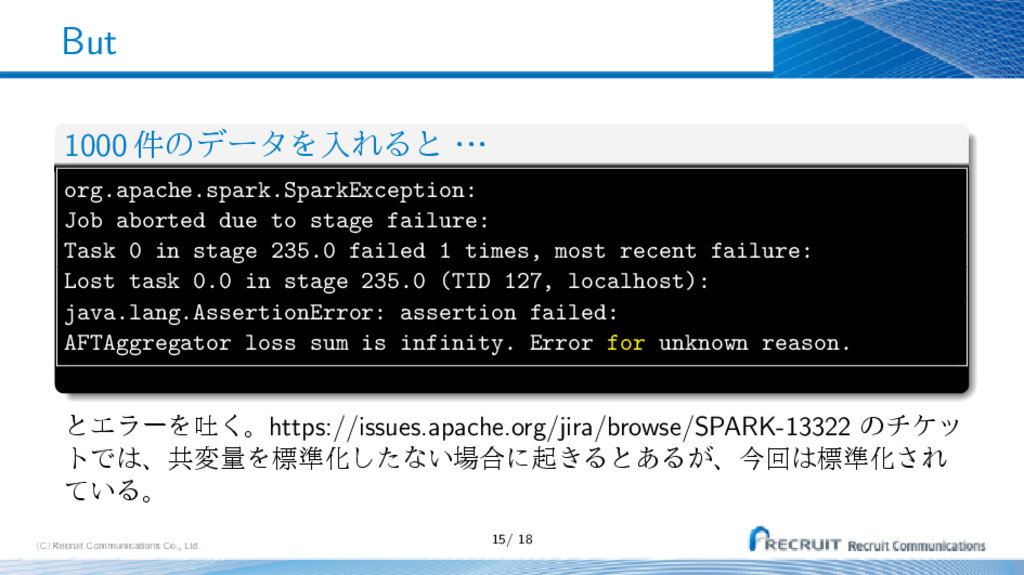
stage failure: Task 0 in stage 235.0 failed 1 times, most recent failure: Lost task 0.0 in stage 235.0 (TID 127, localhost): java.lang.AssertionError: assertion failed: AFTAggregator loss sum is infinity. Error for unknown reason. ͱΤϥʔΛు͘ɻhttps://issues.apache.org/jira/browse/SPARK-13322 ͷνέο τͰɺڞมྔΛඪ४Խͨ͠ͳ͍߹ʹى͖Δͱ͋Δ͕ɺࠓճඪ४Խ͞Ε ͍ͯΔɻ 15/ 18
{kind=link}
{kind=link}
{kind=link}
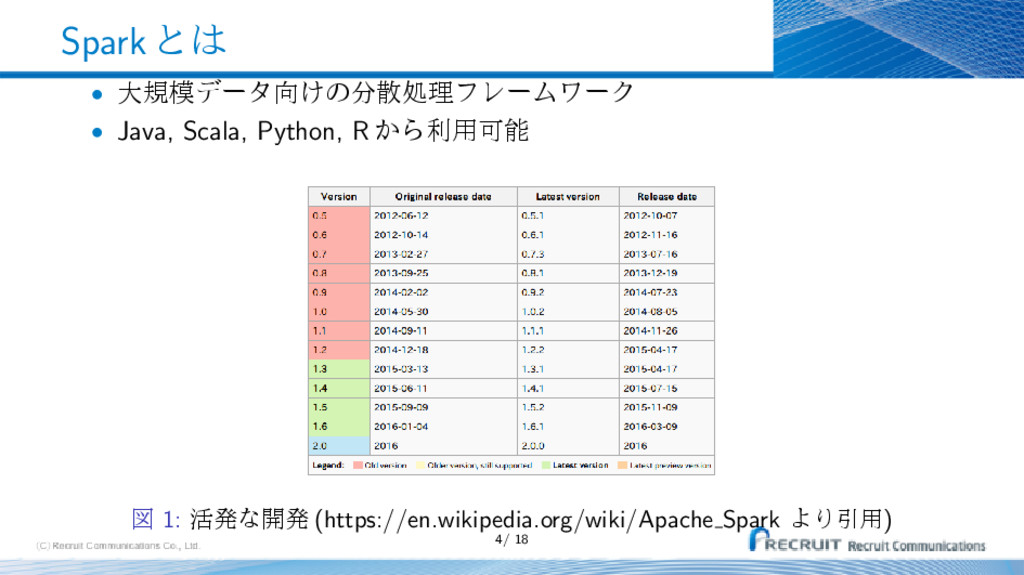{kind=link}
{kind=link}
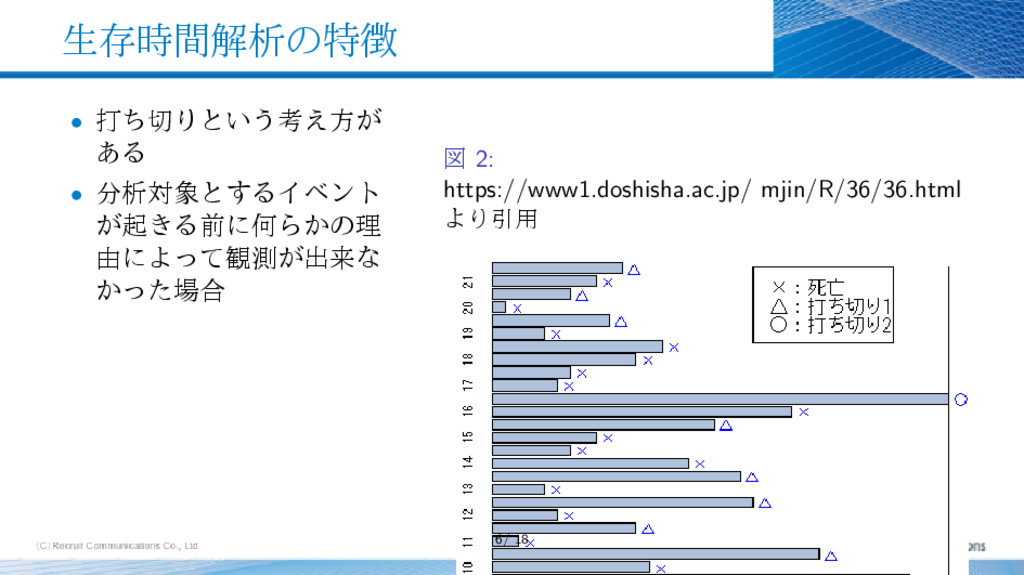{kind=link}
{kind=link}
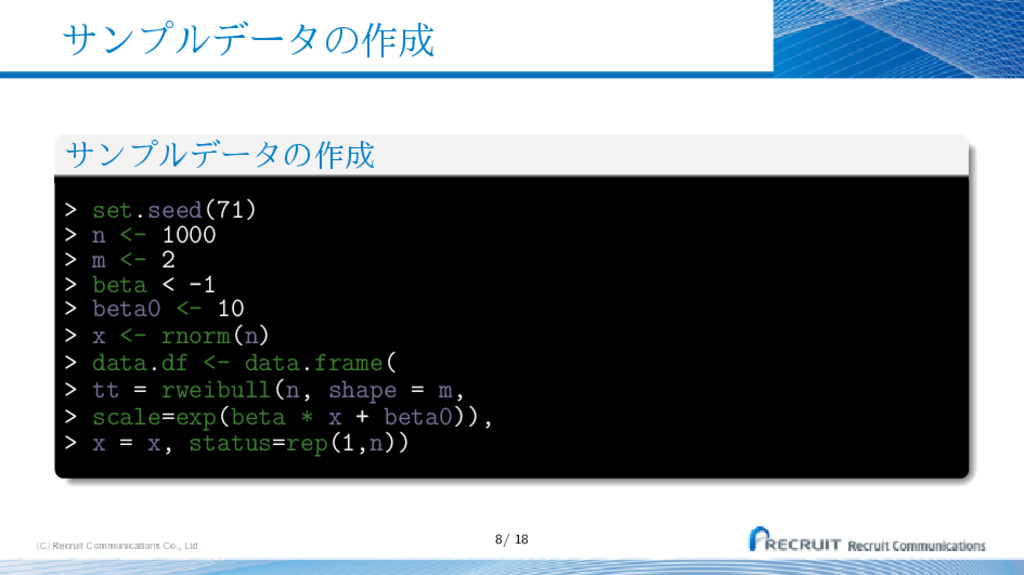{kind=link}
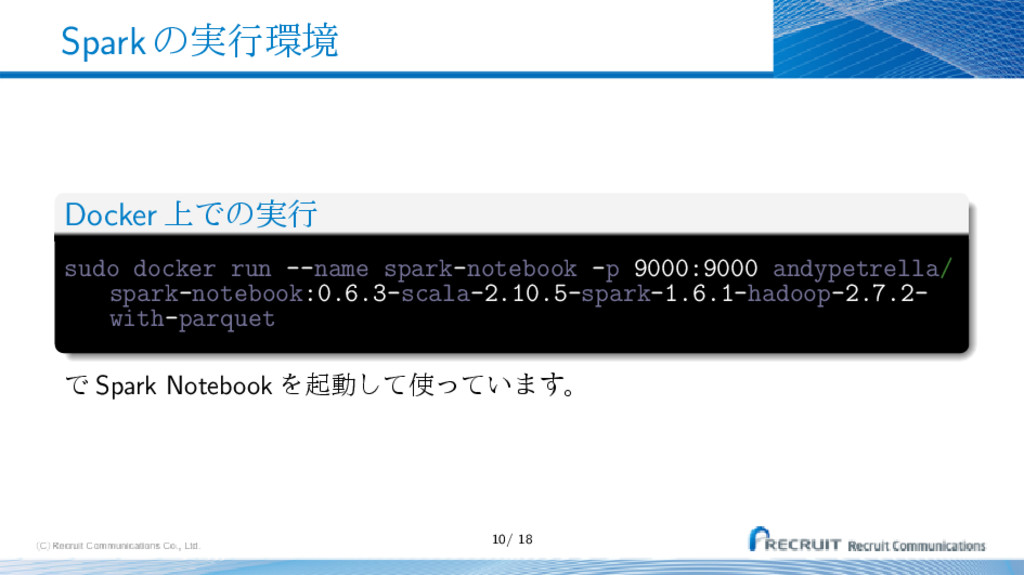
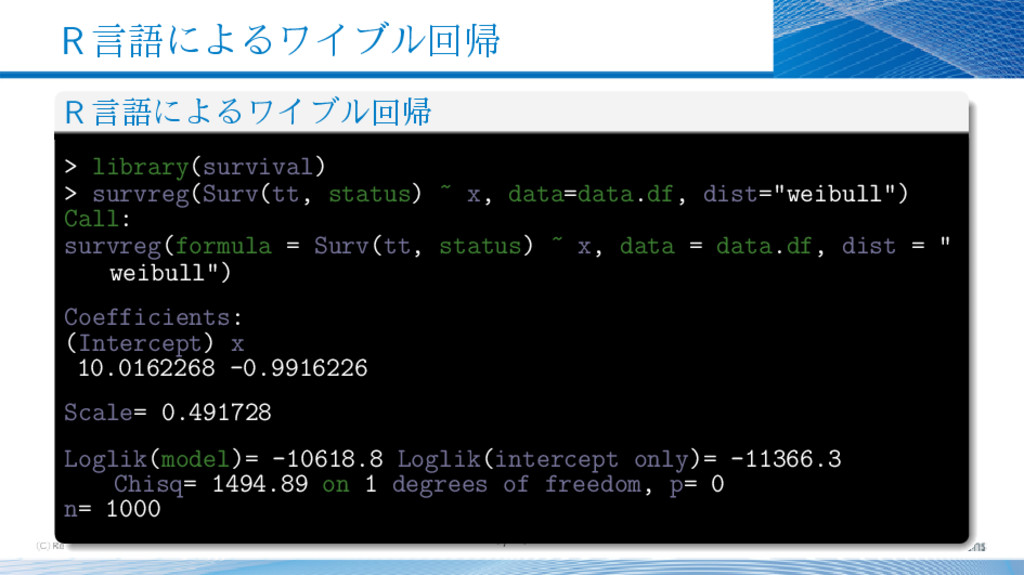{kind=link}
{kind=link}
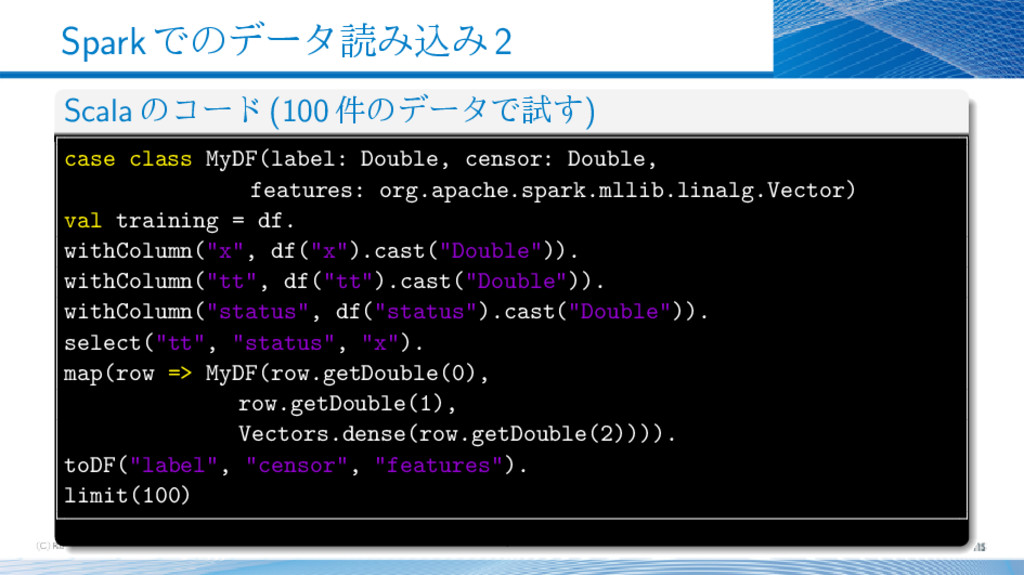
{kind=link}
{kind=link}
{kind=link}
![݁Ռ ύϥϝʔλਪఆΛͯ͠ɺΠϕϯτͷൃੜΛ༧ଌ͍ͯ͠Δ Coefficients: [-0.94] Intercept: 9.94 Scale: 0.49 +---------+------+--------+-----------+--------------------+ |label](https://files.speakerdeck.com/presentations/5d7541fdf99c495eb9252d70d1f8847d/slide_13.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}