instruction Can instrument any running process at any* function entry or return, and at any offset * As long as there are symbols – don't strip that binary!
lossy (DProbes) Neither is acceptable in DTrace Serialization would mean that the pid provider could “scare away” the problems you're trying to observe Lossiness would lead to inconsistent data and invalid conclusions
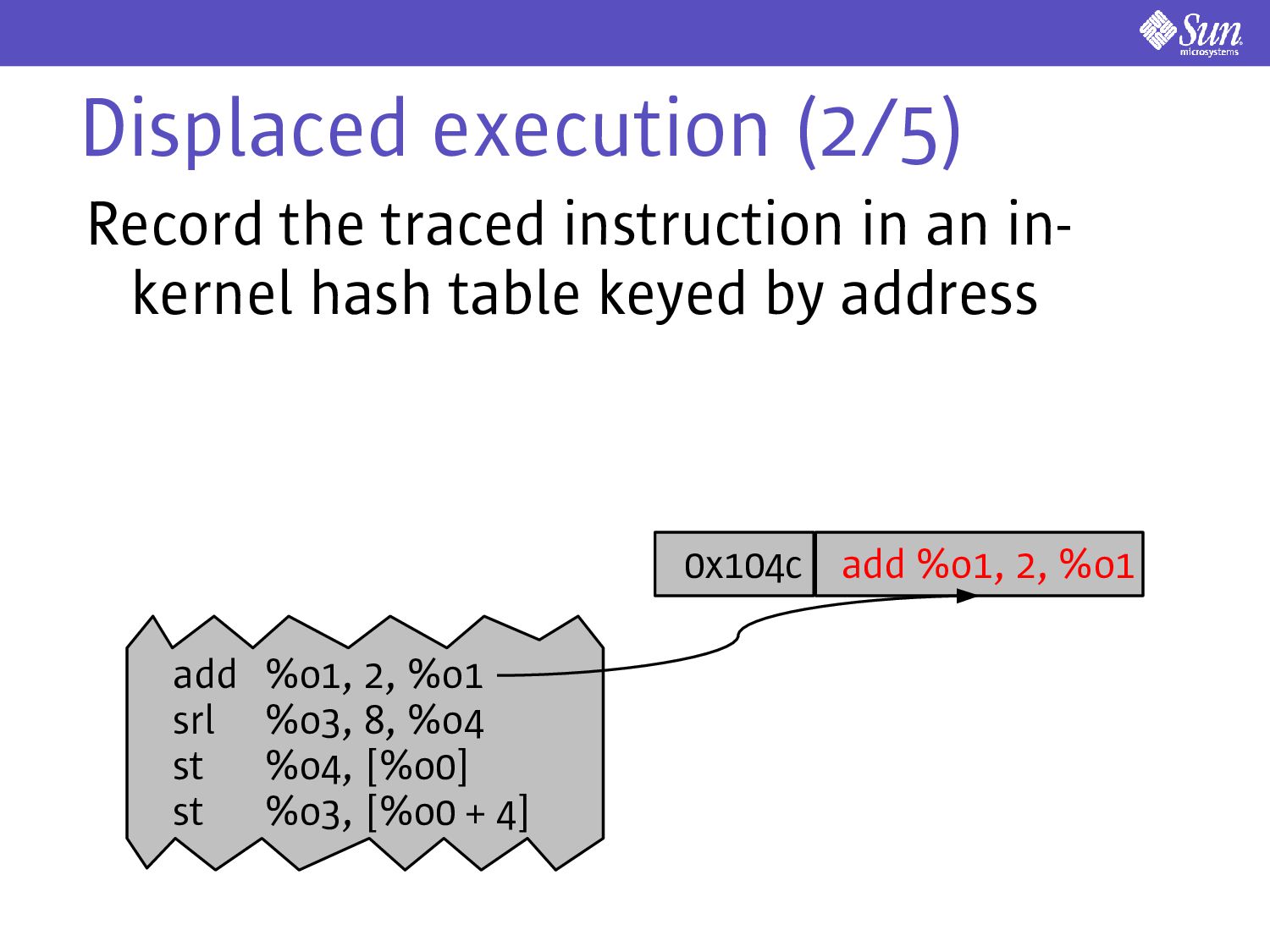
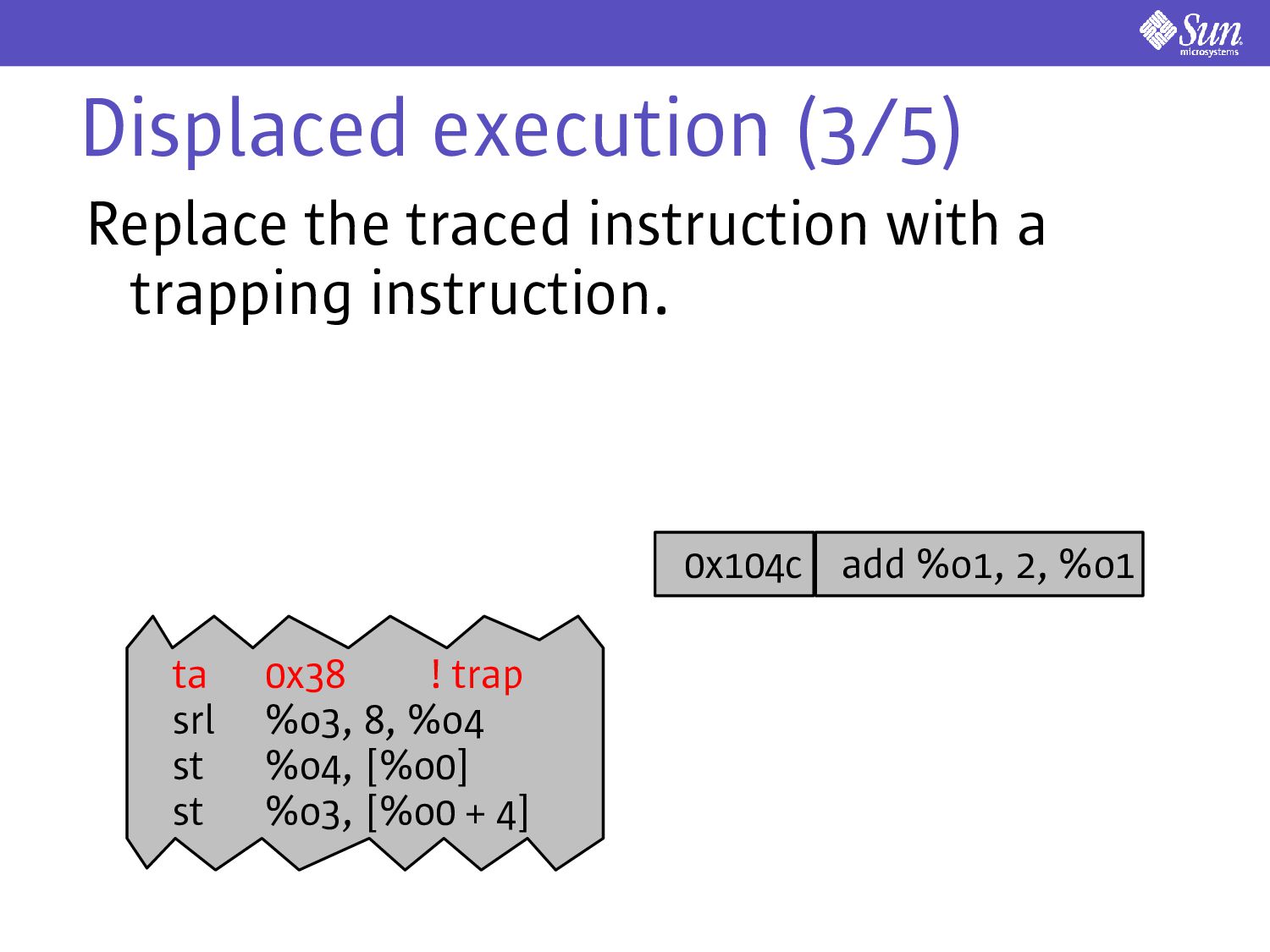
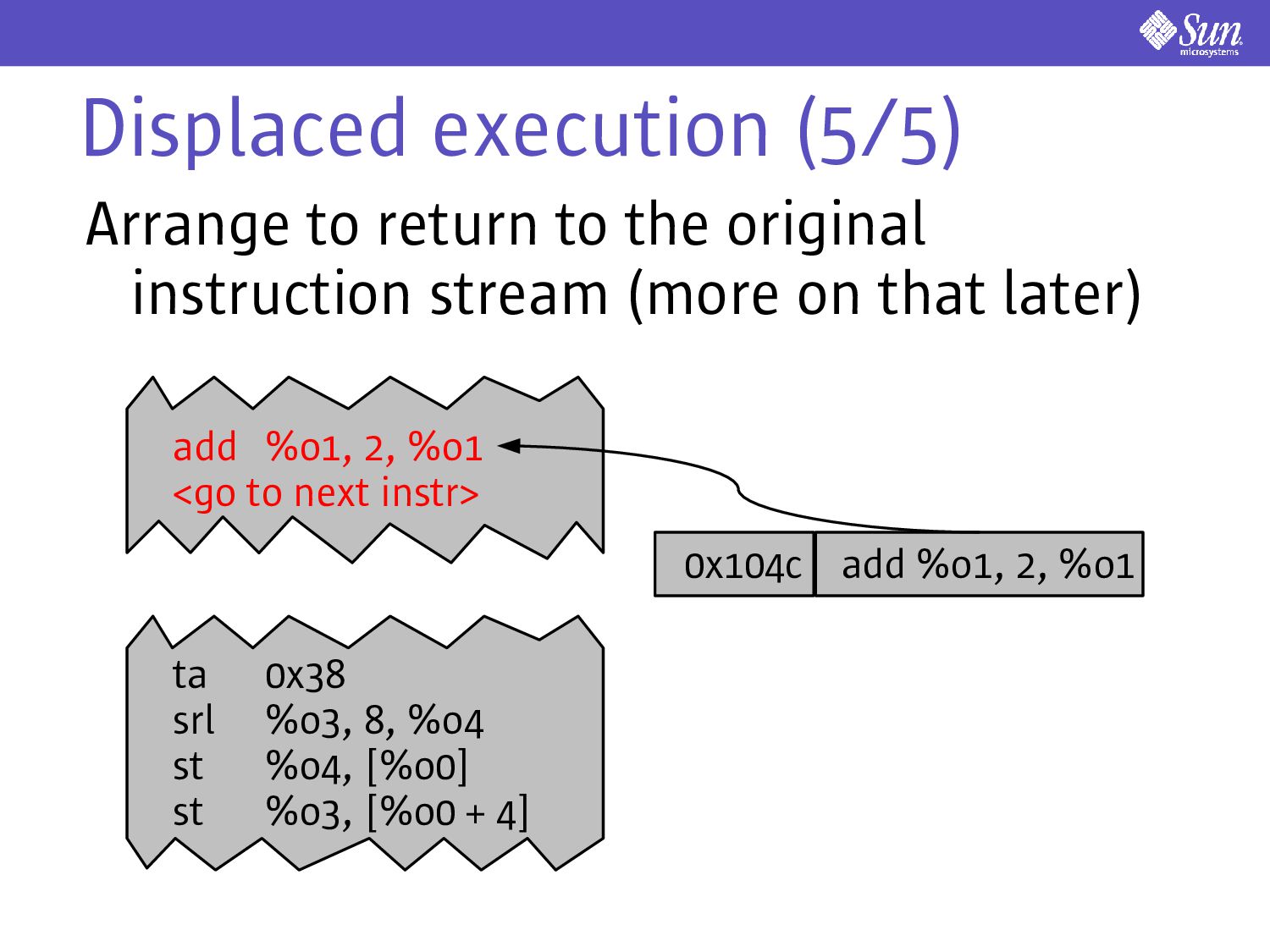
allow a window of lossiness Don't execute the traced instruction at its original address Instead, execute it at some other, thread-specific address: displaced execution
depend on their location e.g. relative branches, call and link Relatively few such instructions to emulate them in the kernel Much simpler than emulating the entire instruction set
to disassemble Delayed control transfers allow for a cool trick Only a handful of instructions to emulate Cons: Turns out the cache architecture isn't designed with the pid provider in mind
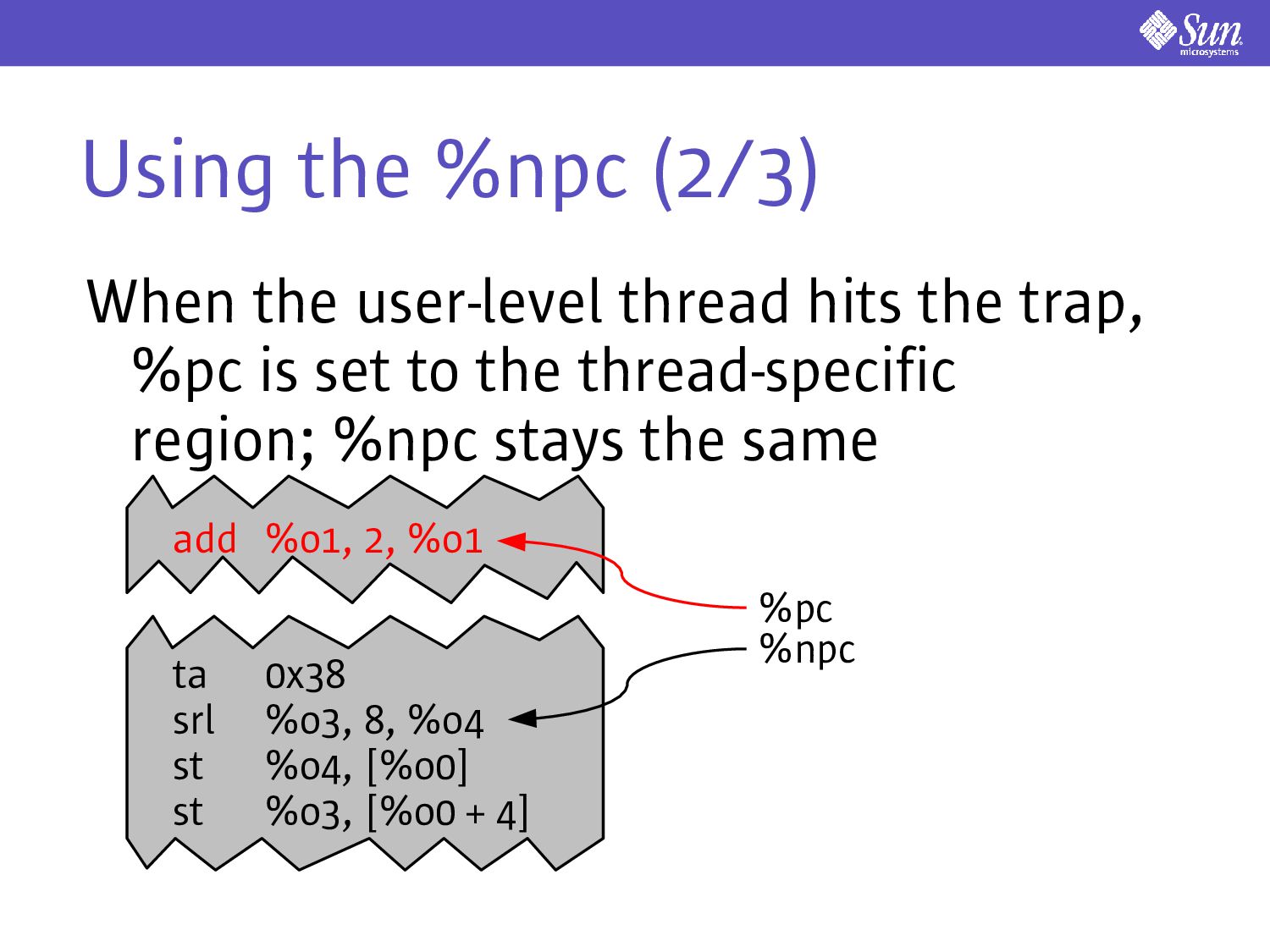
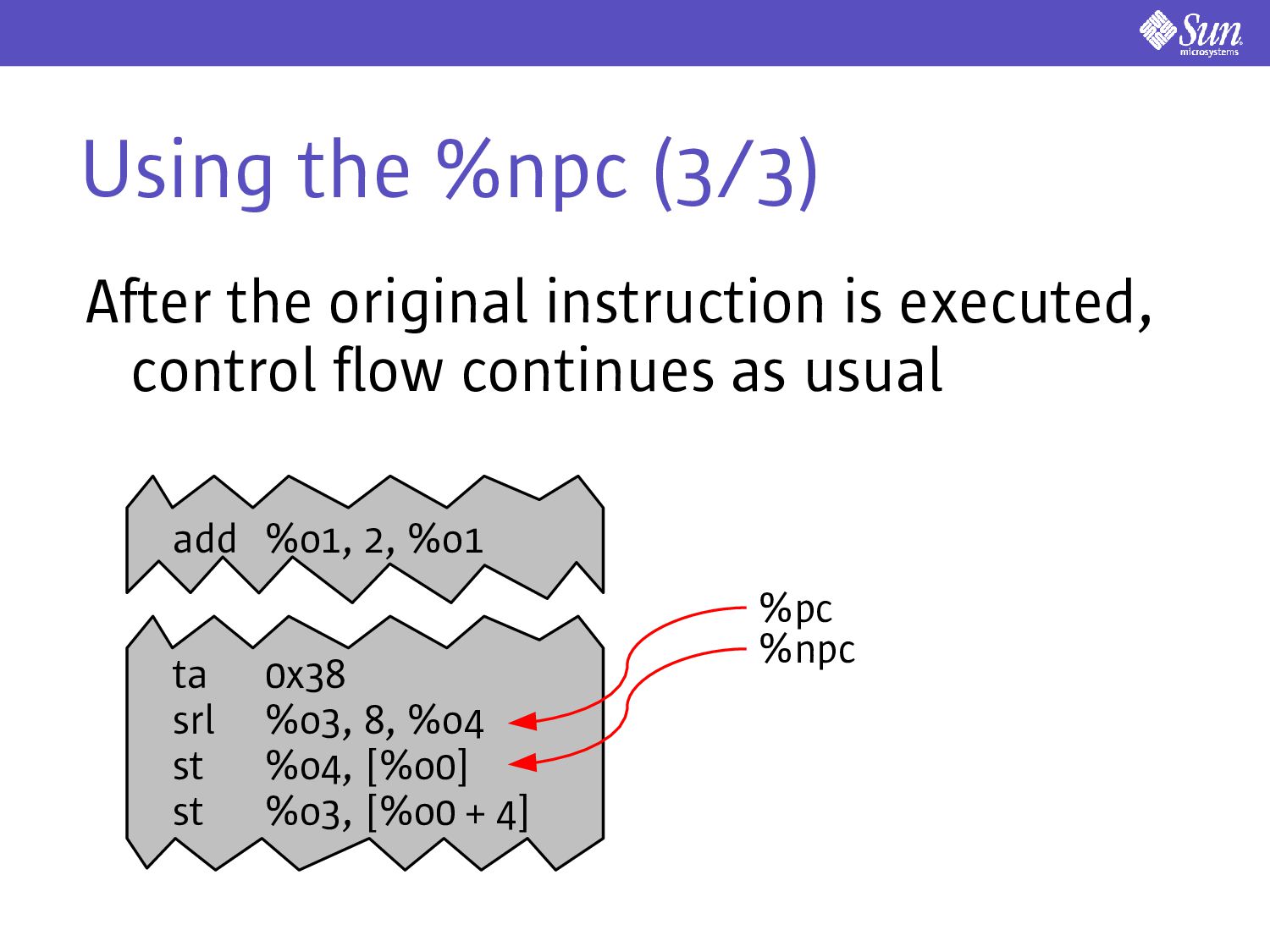
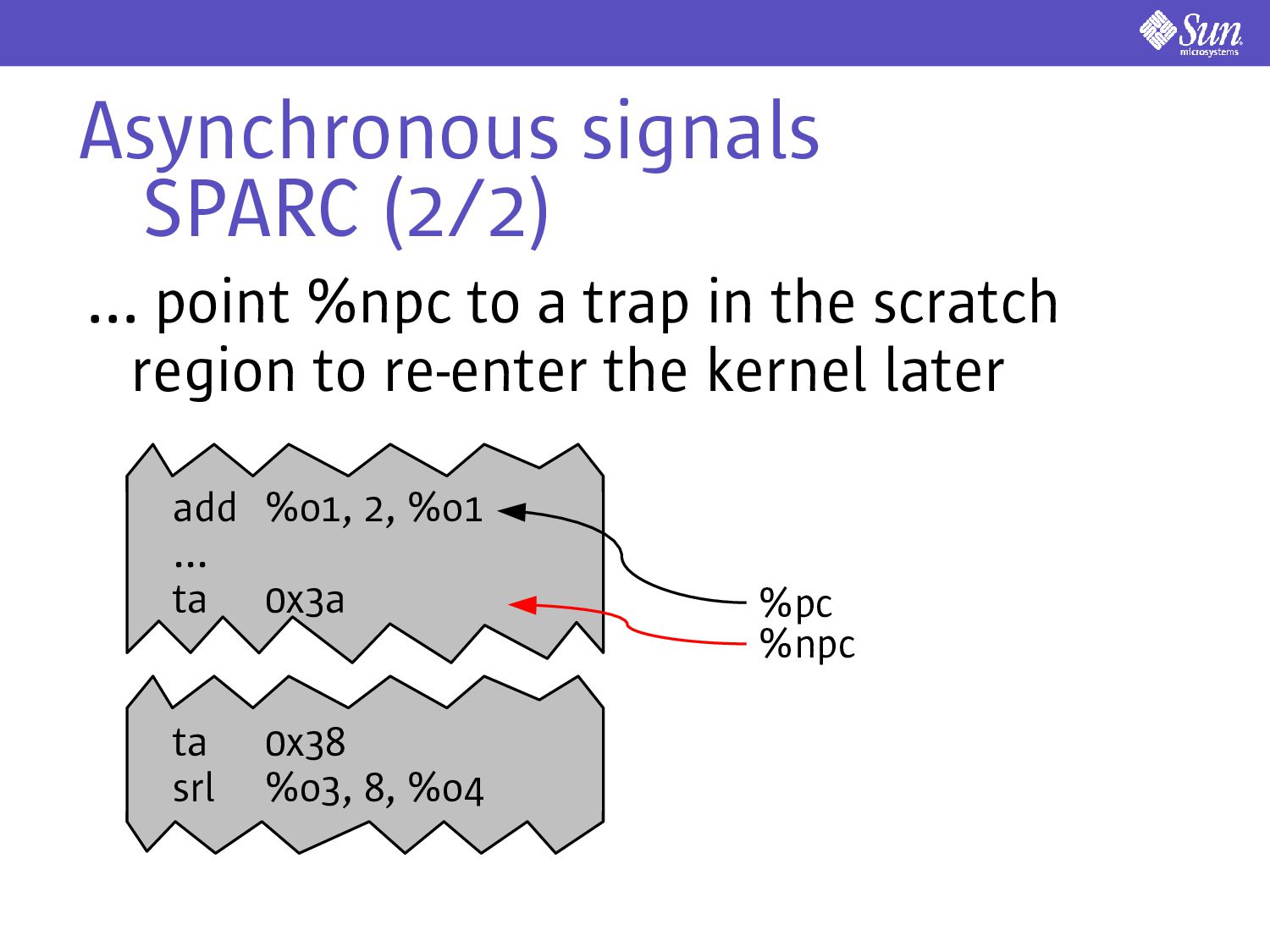
use an analogue to instruction picking to implement displaced execution Consider the following: ta 0x38 srl %o3, 8, %o4 st %o4, [%o0] st %o3, [%o0 + 4] %npc %pc
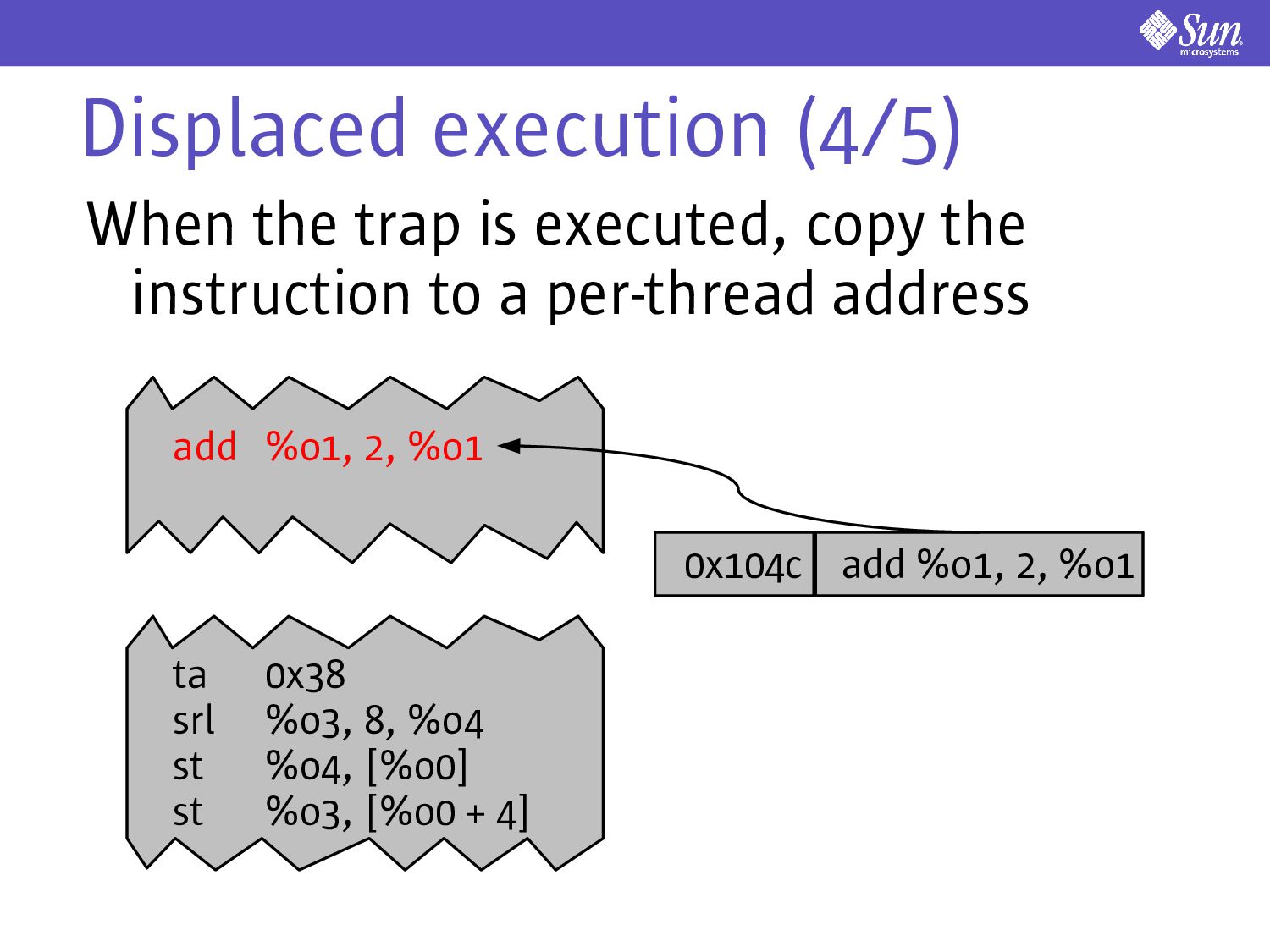
kernel copies the instruction Do this with flush normally, but there's no flusha Use a block store that ensures cache synchrony (ASI_BLK_COMMIT_S) Requires the thread-specific scratch space be 64-bytes and 64-byte aligned
addressing Recall we need to emulate position- dependent instructions With %rip-relative addressing, almost every instruction can potentially be position-dependent
Move the address of the original instruction into %rax movq 0xed8(%rax), %rcx movq $<old_rax>, %rax jmp 0(%rip) <address of next instr> Modify the instruction to be %rax-relative Copy and execute
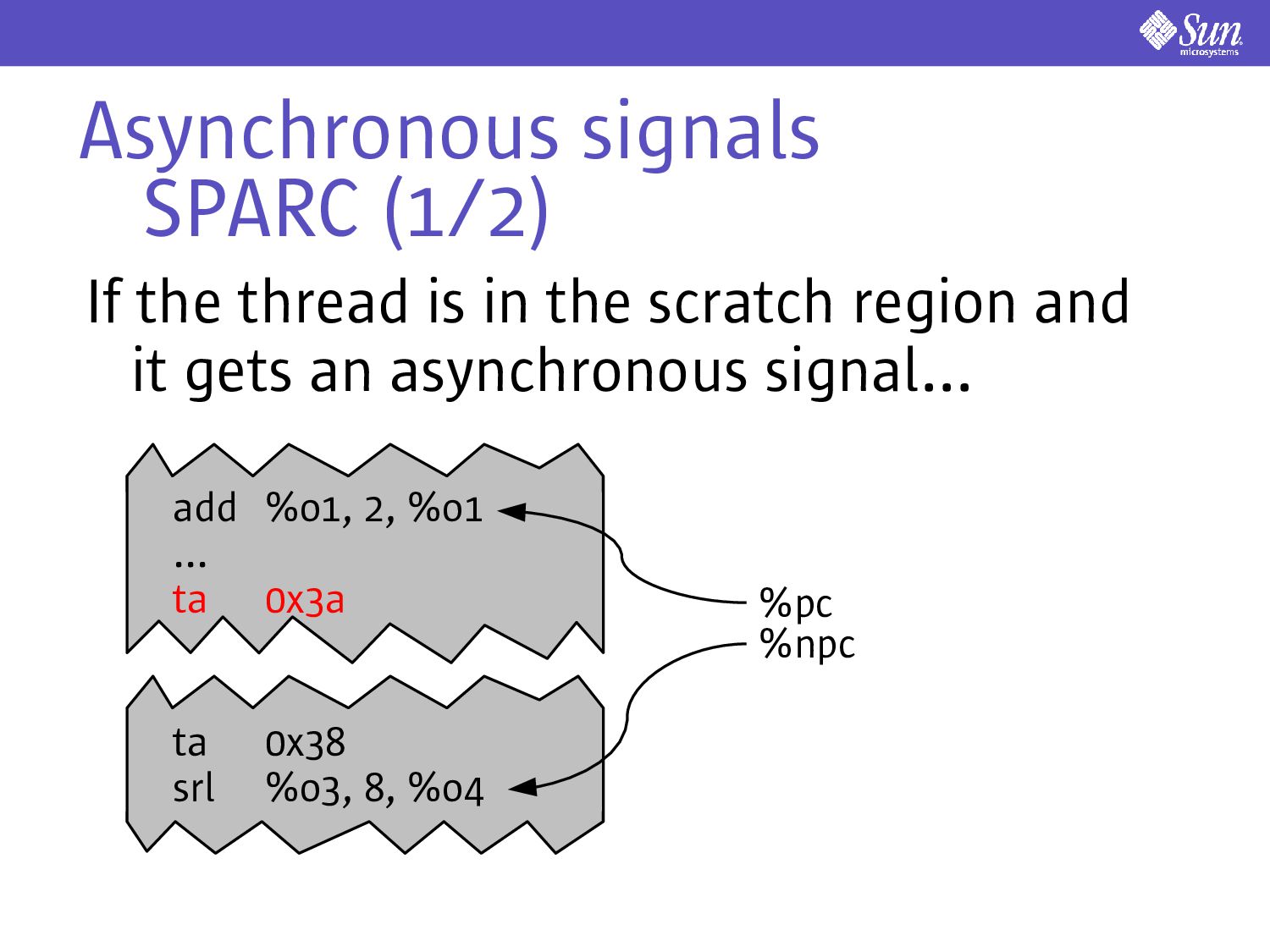
a thread can only be one place at a time However, signals can come at any time even while a thread is executing instructions out of the scratch region We need special handling for synchronous and asynchronous signals
when executing an instruction e.g. divide-by-zero, touching unmapped memory If the user-level thread is in its scratch region, reset the PC to the address of the traced instruction When the signal handler returns it will hit the tracepoint again
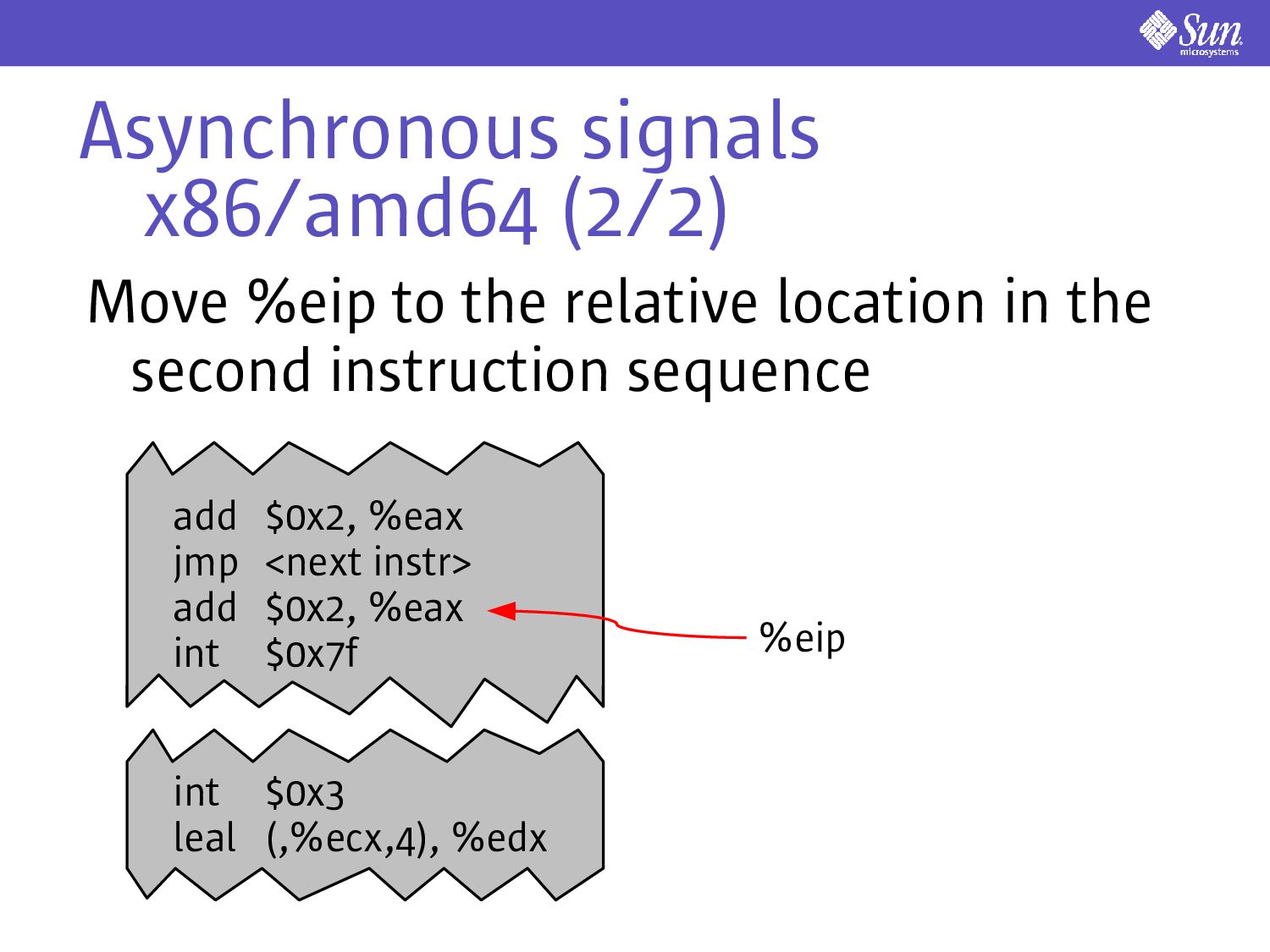
call e.g. a timer expiring, kill(2), pkill(1) If the user-level thread is in its scratch region we need to defer delivery Need to alert the kernel to delivery the signal before leaving the scratch region Implementation is ISA-specific
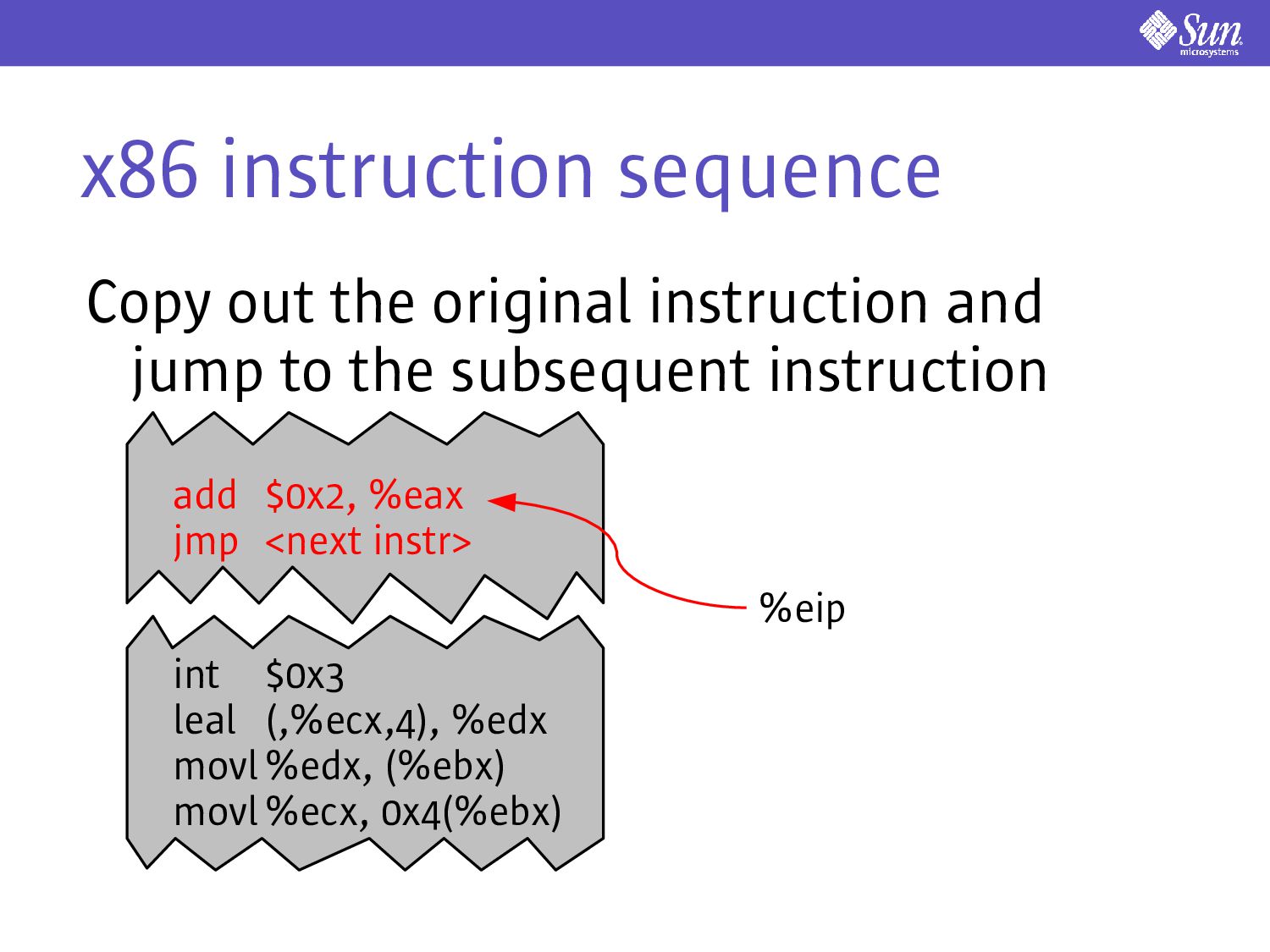
ending in a trap int $0x3 leal (,%ecx,4), %edx add $0x2, %eax jmp <next instr> add $0x2, %eax int $0x7f %eip NB: %eip can be anywhere in the first instruction sequence
creates probes at the desired places This is dicey! Overwriting data with a trap will bring the process to a grinding halt – if you're lucky Need to be very conservative about what we let users trace
are always illegal instructions [-0x8000 .. 0x3fffff] are illegal instructions On x86, interpreting one offset as an instruction invalidates all subsequent disassembly DTrace gives up at the first sign of jump tables Stay tuned for a better answer...
member of libc's per-thread ulwp_t structure Not there until libc is loaded The runtime linker has some special communication with the kernel so that the thread register set up by the time ld.so.1 executes its first instruction
mapout What was a single instruction becomes multiple context switches, hundreds of instructions, and cache misses We try to optimize the common cases entry and return probes Emulation is faster than displaced execution
sethi; end with a restore We emulate sethi in the kernel Partially emulate save and restore Stash helpful instructions in the thread structure Set %pc to one of those instructions This saves us the E$ miss
As with fbt for the kernel, it can be hard to grok all those probes For the kernel we invented statically defined tracing providers (SDT) For user-land we have the equivalent
documented probes in applications Users, sys-admins, and service engineers can plug into those probes to understand what the application is doing and how it relates to the system Instrumentation uses the same techniques as the pid provider
Put a provider description in a .d file: provider oracle { probe transaction-start(id_t id); probe transaction-finish(id_t id); }; Run dtrace -G with object files and provider description Link resulting object file into the binary
primitives Active work on a hotspot provider for the JVM Work ongoing to make USDT more robust and to add providers to more application from Sun and ISVs
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}