http://code.google.com/p /pyodbc MIT 2.4 - 3.2 Windows, Linux, MacOS X, FreeBSD, Solaris, Any adodbapi http://adodbapi.sourcefor ge.net/ LGPL 2.5 이상 WINDOWS ONLY pymssql http://pymssql.org LGPL 2.6 이상 3.3 이상 Windows and Unix mssql http://www.object- craft.com.au/projects/mss ql/ BSD Windows mxODBC http://www.egenix.com/ eGenix.com Commercial License 2.4 - 2.7 Windows, Unix, Mac OS X, FreeBSD, Solaris, AIX, other platforms on request pypyodbc http://code.google.com/p /pypyodbc MIT 2.4 - 3.3 Windows, Linux
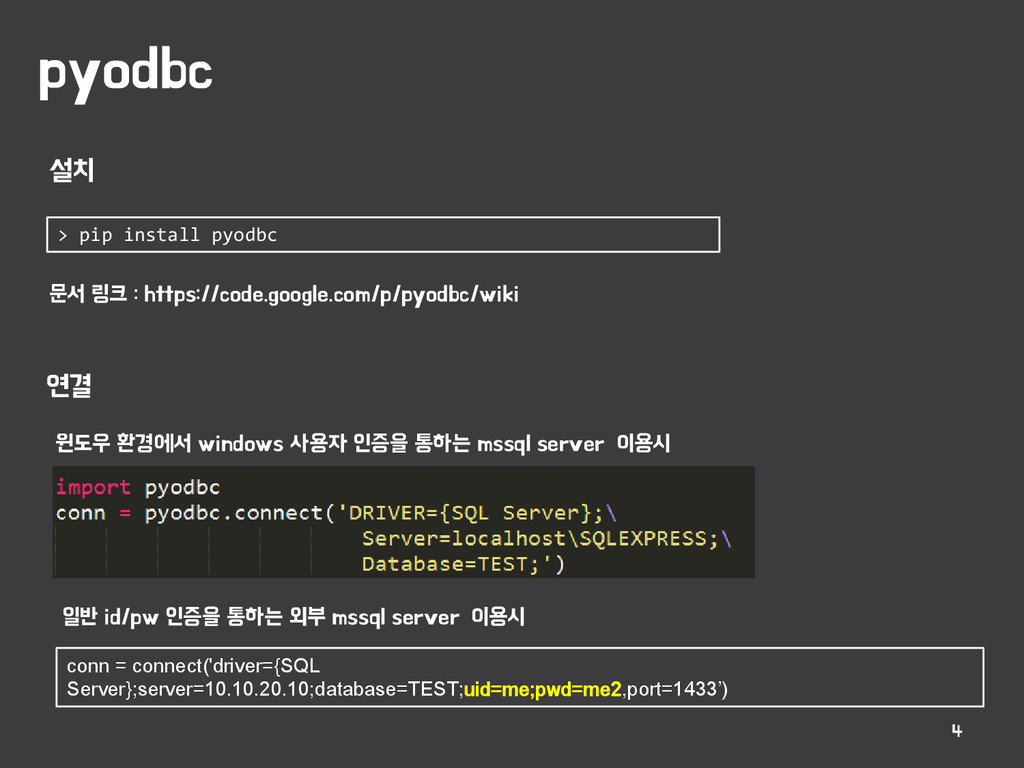
server 이용시 conn = connect('driver={SQL Server};server=10.10.20.10;database=TEST;uid=me;pwd=me2,port=1433’) 일반 id/pw 인증을 통하는 외부 mssql server 이용시 > pip install pyodbc 문서 링크 : https://code.google.com/p/pyodbc/wiki 설치
DRIVER={SQL Server Native Client 10.0}; 세가지 타입의 Driver SQL Server - 모든 버전 사용가능 - SQL2000에서만 지원하는 기능/타입을 지원 SQL Native Client - SQL 2005에서만 지원하는 기능/타입을 지원 - SQL 2008은 지원 X SQL Server Native Client - SQL2008에서만 지원하는 기능/타입 지원
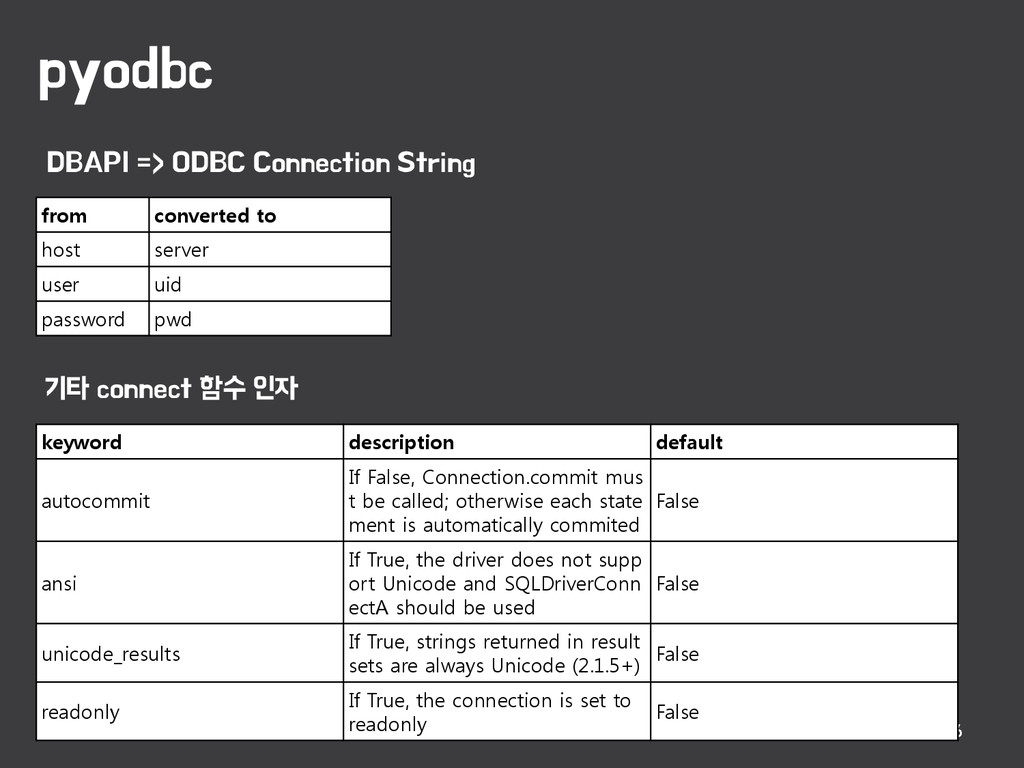
pwd keyword description default autocommit If False, Connection.commit mus t be called; otherwise each state ment is automatically commited False ansi If True, the driver does not supp ort Unicode and SQLDriverConn ectA should be used False unicode_results If True, strings returned in result sets are always Unicode (2.1.5+) False readonly If True, the connection is set to readonly False DBAPI => ODBC Connection String 기타 connect 함수 인자
= cursor.execute("delete from products where id <> 'pyodbc'").rowcount SQL내에서 ‘’ 를 사용, python 에서는 쌍따옴표를 사용 row = cursor.execute("select count(*) as user_count from users").fetchone() print '%s users' % row.user_count SQL Server는 결과에 컬럼명 반환 x, 기본 index로 접근, 그게 싫으면 as를 쓰면 컬럼명으로 가져올수 있다. count = cursor.execute("select count(*) from users").fetchone()[0] print '%s users' % count 결과내에서 하나의 값만 사용할것이면, index 로 바로 접근해서 그것만 가져와서 사용할것.
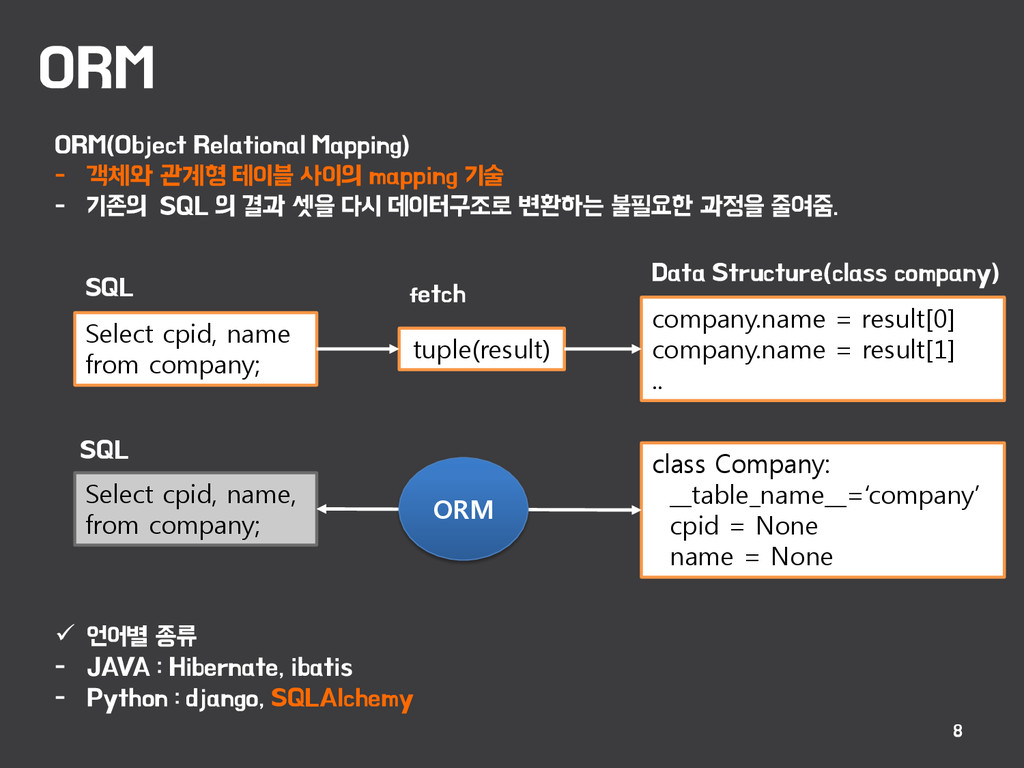
mapping 기술 - 기존의 SQL 의 결과 셋을 다시 데이터구조로 변환하는 불필요한 과정을 줄여줌. 언어별 종류 - JAVA : Hibernate, ibatis - Python : django, SQLAlchemy Select cpid, name from company; tuple(result) company.name = result[0] company.name = result[1] .. SQL fetch Data Structure(class company) Select cpid, name, from company; SQL class Company: __table_name__=‘company’ cpid = None name = None ORM
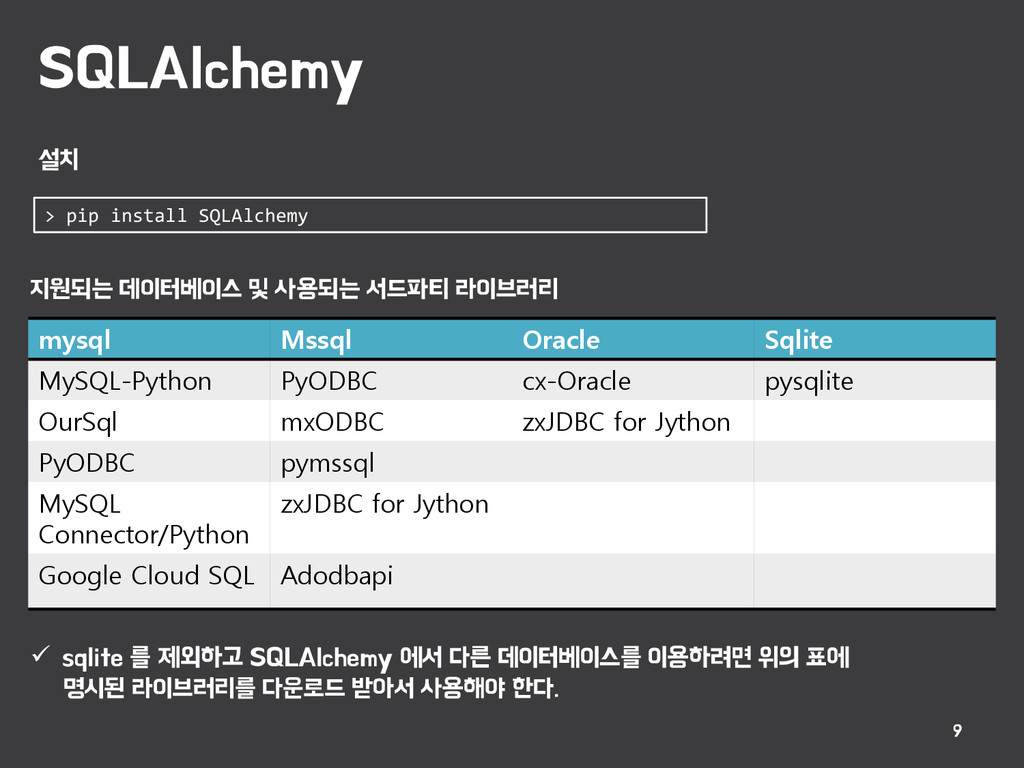
를 제외하고 SQLAlchemy 에서 다른 데이터베이스를 이용하려면 위의 표에 명시된 라이브러리를 다운로드 받아서 사용해야 한다. mysql Mssql Oracle Sqlite MySQL-Python PyODBC cx-Oracle pysqlite OurSql mxODBC zxJDBC for Jython PyODBC pymssql MySQL Connector/Python zxJDBC for Jython Google Cloud SQL Adodbapi 설치 > pip install SQLAlchemy
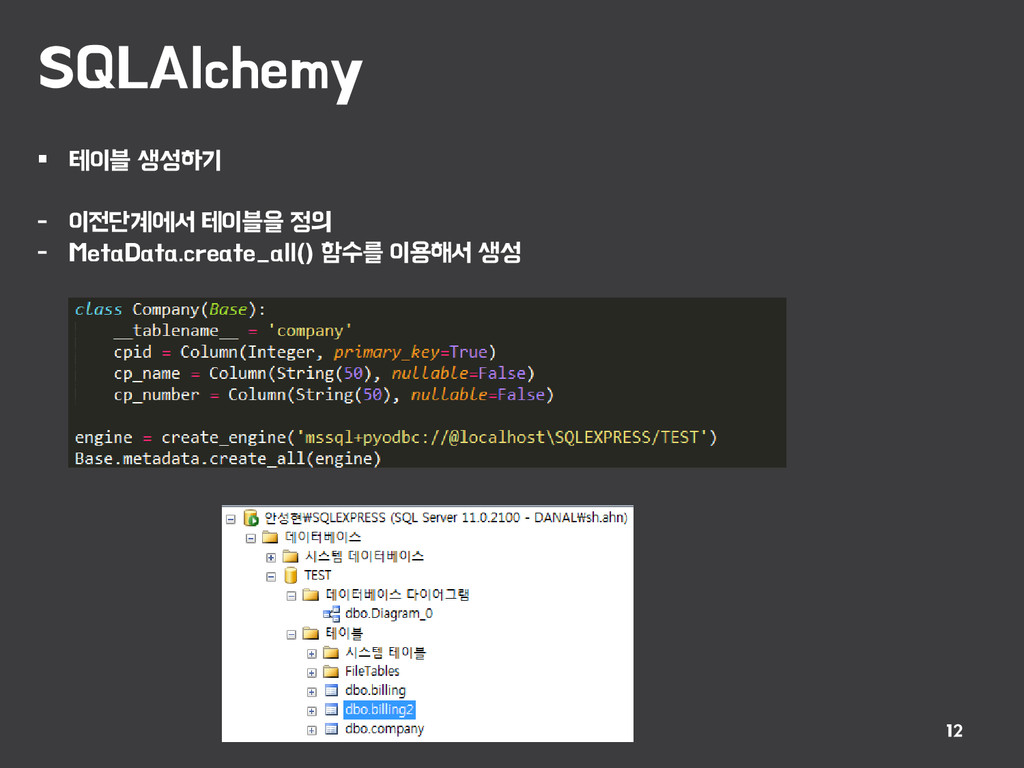
생성 - Base : 맵핑클래스에서 상속해서 사용 - 맵핑클래스에서 DB 컬럼을 나타내는 Column, 각각의 형을 나타내는 것을 import - __tablename__ : 해당 테이블 명을 명시, 그 테이블과 맵핑 - 각각의 컬럼을 정의, 멤버변수, 데이터형, primary_key, nullable 지정 from sqlalchemy.ext.declarative import declarative_base Base = declarative_base()
연산을 책임지는 단위 , sessionmaker 를 이용해서 생성 - Session 클래스의 객체를 만들어서 사용한다. - commit() 호출 전까지는 결과가 db 에 반영되지 않은 상태, 호출후 실제 반영됨. SQLAlchemy 13 ② 맵핑클래스의 인스턴스 만들기 ①세션만들기 ③ 세션에 맵핑인스턴스 추가
'ed') query.filter(User.name.like('%ed%')) query.filter(User.name.in_(['ed', 'wendy', 'jack'])) equal not equal like in not in query.filter(~User.name.in_(['ed', 'wendy', 'jack']))
None) from sqlalchemy import and_ filter(and_(User.name == 'ed', User.fillname == 'Edward Kim')) filter(User.name == 'ed').filter(User.fullname == 'Edward Kim') from sqlalchemy import or_ filter(or_(User.name == 'ed', User.name == 'wendy')) is null is not null and or query.filter(User.name.match('wendy')) match
삭제 => DB 에서도 삭제 delete from company where cp_name = ‘LIG’ update company SET cp_name = ‘LIG’ where cp_name=‘GS’ update - session 이 close() 되기 전에 select 를 통해 가져온 mapping instance 에 변경을 가하면 해당 데이터가 업데이트 됨.
all() : 결과의 전체를 리스트를 반환 first() : 결과내에서 첫번째 열을 반환 one() : 하나의 결과를 반환, 여러 개의 결과이거나 혹은 매칭되는게 없으면 예외 발생 sqlalchemy.orm.exc.MultipleResultsFound: Multiple rows were found for one() sqlalchemy.orm.exc.NoResultFound: No row was found for one()
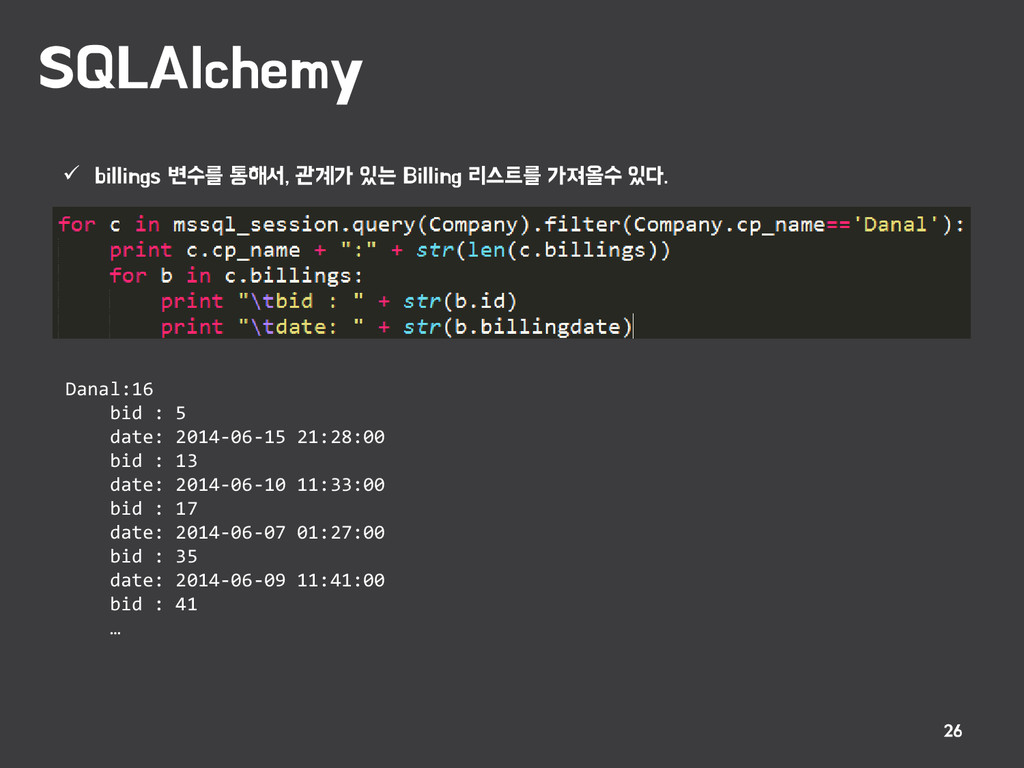
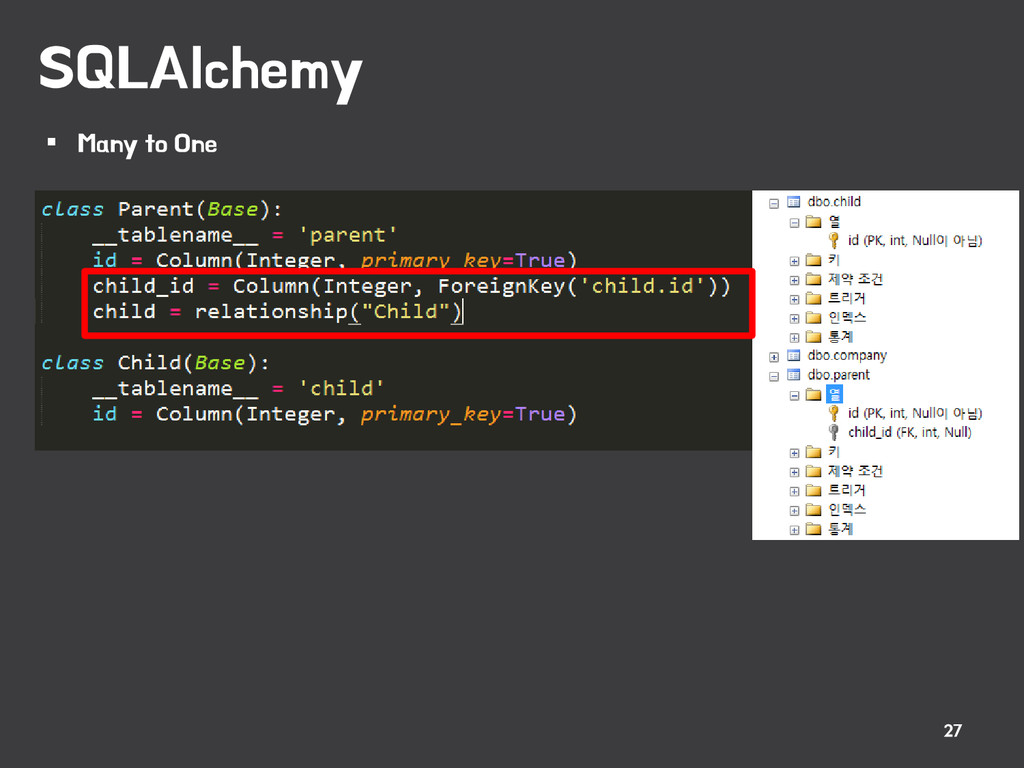
관계 맵퍼 클래스(Billing)이 관계가 있다는 지정 - 반드시 써야하는것은 아님. - billings 은 컬럼이 아니기 때문에 DB에 생성되지 않음. - billings 변수를 통해서 관계가 있는 Billing 객체에 접근할수가 있다. - 관계가 있는 데이터에 접근할 수 있는 DB에는 없는 변수를 하나 만든다고 생각. One to Many
찾는 방식 join() 함수를 이용하는 방식, 키의 기준은 지정하지 않으면 하나의 지정된 외래키를 기준으로 함. query.join(Address, User.id==Address.user_id) # 정확한 상태를 적어줌 query.join(User.addresses) # 명확한 관계 표기 (좌에서 우로) query.join(Address, User.addresses) # 동일, 명확하게 목표를 정해줌 query.join('addresses') # 동일, 문자열 이용
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}