Die richtige Website finden wir mit wenigen Worten in einem Suchfeld mit unserer Lieblingssuchmaschine in Sekundenbruchteilen. Wenn in Unternehmensanwendungen gesucht wird, dann gibt es komplizierte Suchmasken, die Suche dauert ewig und ist nicht fehlertolerant.
Der Vortrag zeigt, wie man mit Apache Lucene und Solr die Nadel im Heuhaufen am Beispiel von Kundendaten findet. Und das in Sekundenbruchteilen.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
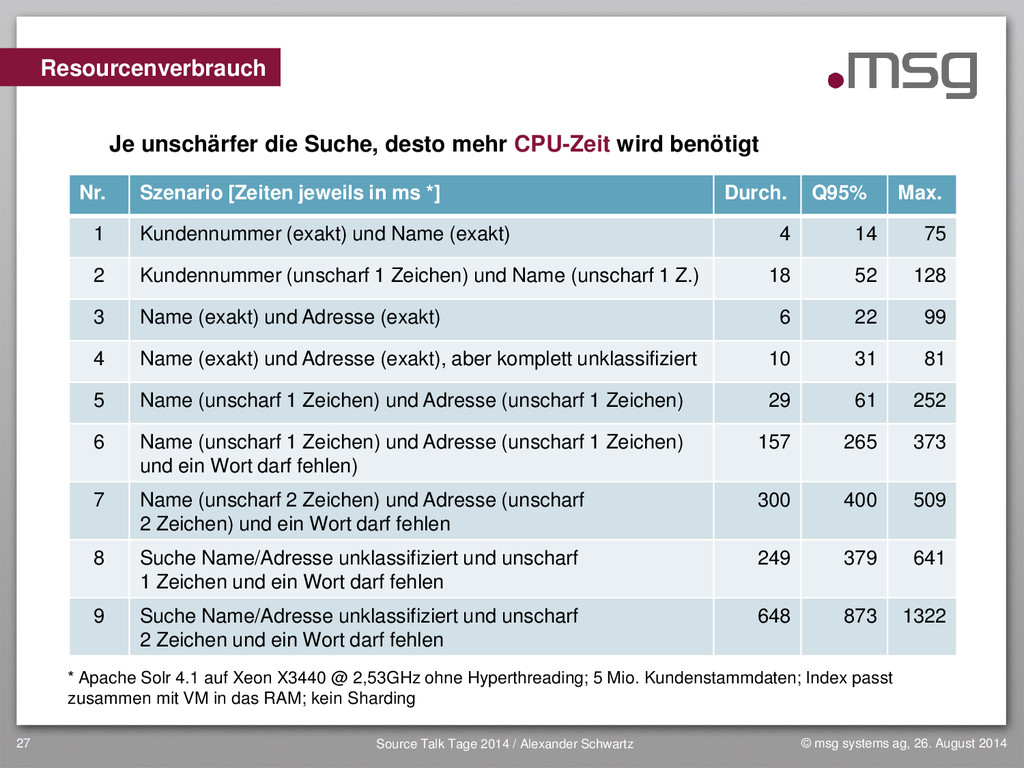{kind=link}
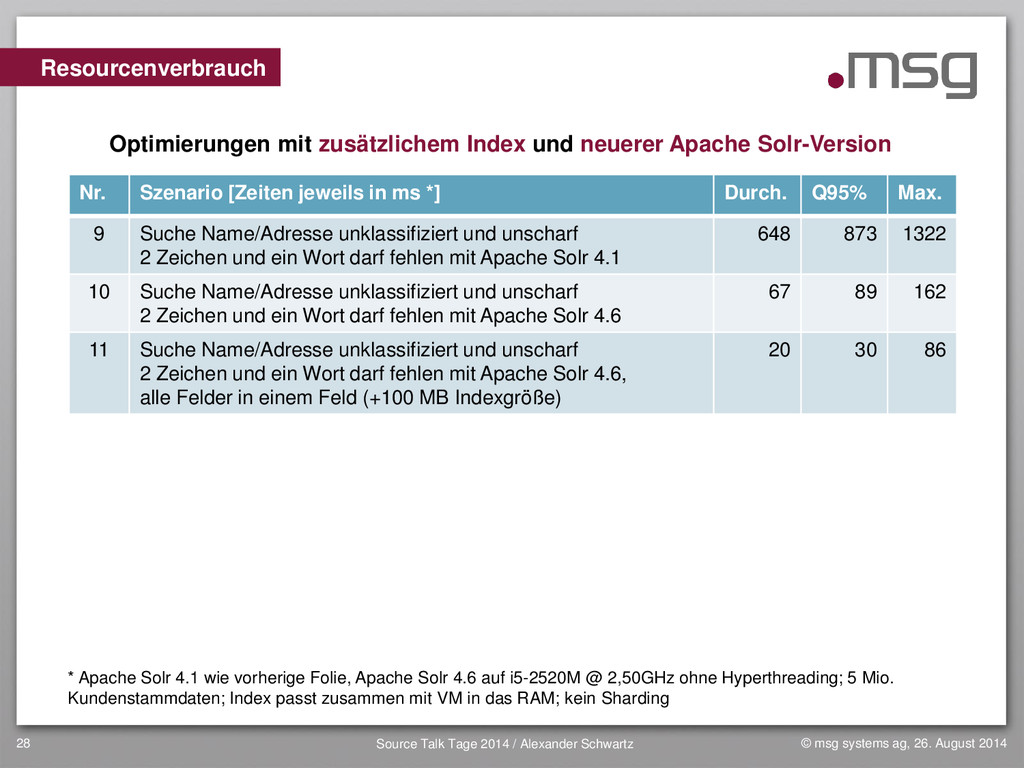{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}