Introductory talk on high-performance computing concepts, aimed at an actuarial audience familiar with computational challenges but not with computing at scale.
Given at the Life & Annuity 2011 Symposium of the Society of Actuaries in New Orleans, on behalf of my employer at the time, R Systems NA, Inc. http://www.r-hpc.com/
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
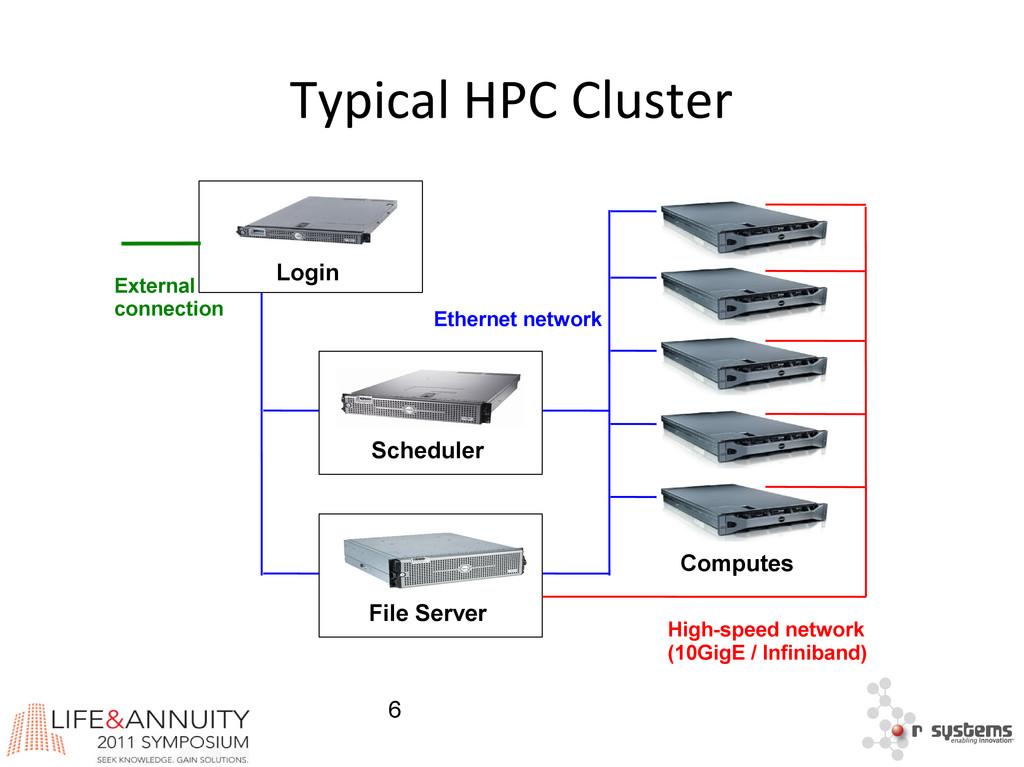{kind=link}
{kind=link}
{kind=link}
{kind=link}
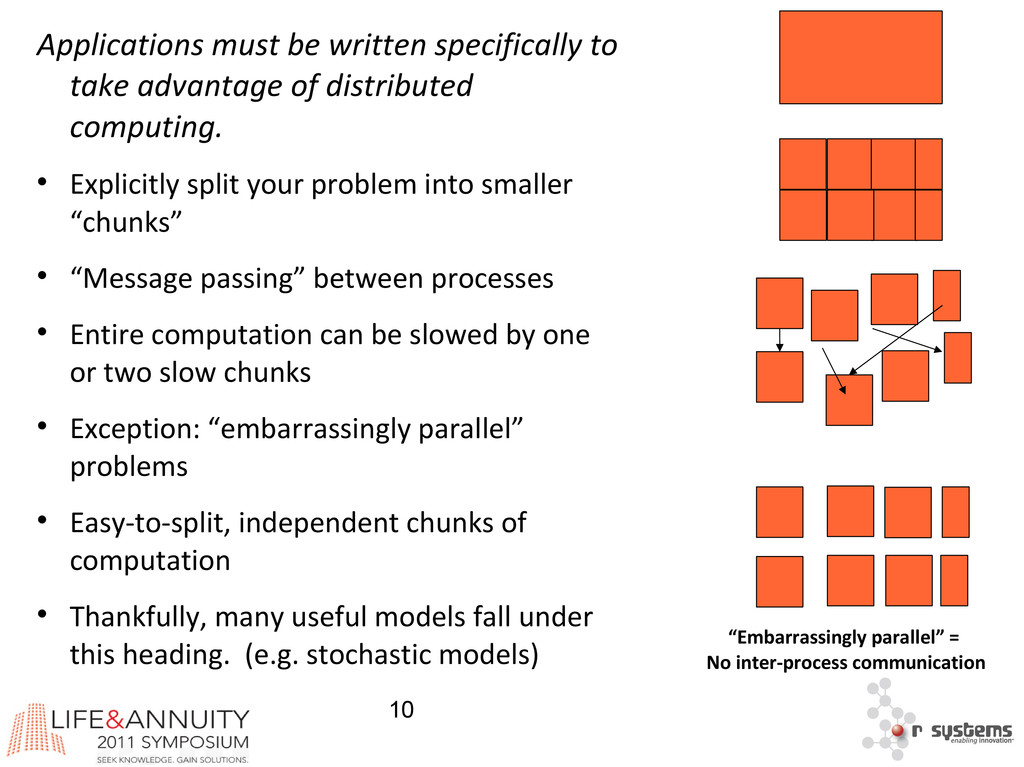{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
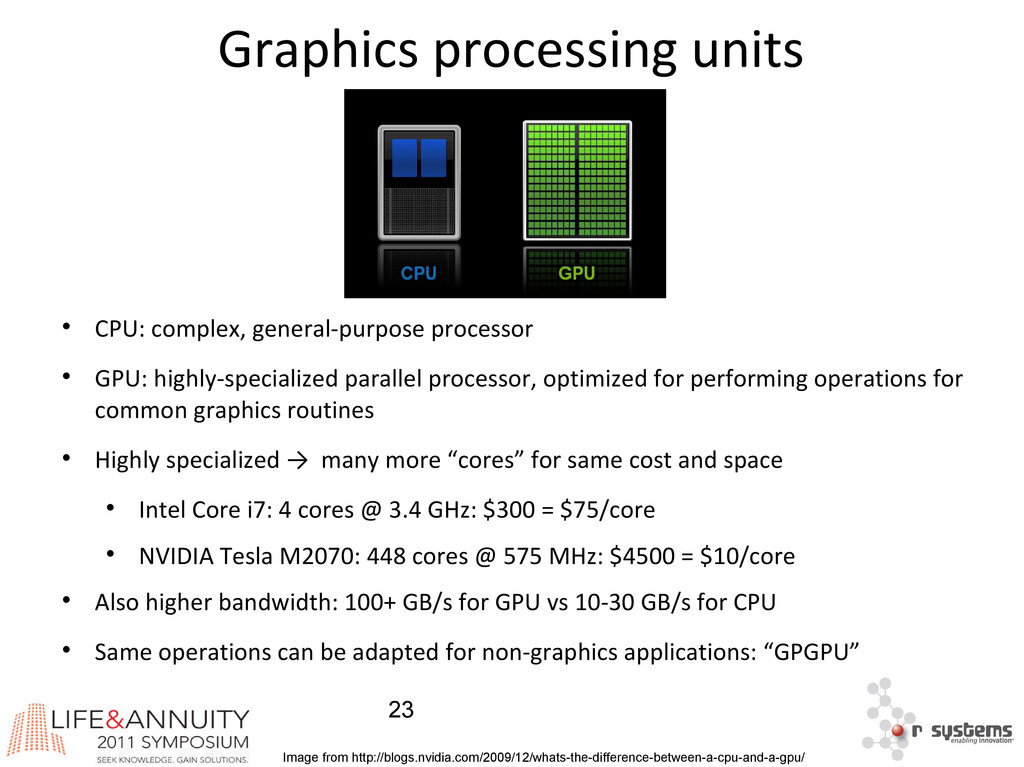{kind=link}
{kind=link}