software developers. And unless you make space shuttles or pacemakers, you’re probably ok with that, you’ve accepted into your heart that they’re something that will happen from time to time. In my experience, customers aren’t happy about any bugs, but today we’re going to focus on a specific subset of them: operational bugs.
your website. A data breach. Something that went wrong in the production environment. A quick test is that if it’s something you’d measure in an SLA, it’s an operational failure. We’re going to focus on how you can learn from your operational failures; some of these practices are probably applicable to other situations you want to learn from (like an agile sprint retrospective), but those won’t be my focus. I’ll be using “the website went down” for my examples, because it’s a situation that’s accessible to many folks, but don’t take that to mean that it’s the only type of operational failure.
Core developer for Python Cryptographic Authority, CPython, PyPy, emeritus Django ▸ Former member of the Board of Directors for the Python Software Foundation and Django Software Foundation Before we dive too far in, you should probably know the perspective I’m bringing to this. I’m currently a security engineer protecting Firefox at Mozilla. In previous lifetimes I’ve worked for startups and for the United States Government. I’ve developed web applications and compilers, and nowadays a web browser. I’ve spent a lot of time in the Python ecosystem, from developing popular open source projects to serving on the board of the PSF.
do next? First you stop the bleeding. Resolving the immediate presentation of the breakage is outside the scope of this talk. Hopefully someone else at PyCon gave a talk on fixing bugs, if not you’re on your own. Once the situation is stabilized, what do you do next? In my experience there are two possible answers to this question: (1) is how do we make sure this doesn’t happen again, or (2) is how do we figure out who needs to be fired?
ARE PLENTY OF OTHER VENUES WHERE PEOPLE DEVOTE THEIR CREATIVE ENERGIES TO SHIFTING BLAME; WE DO NOT NEED ANOTHER ONE. WE DON'T SHOOT THE MESSENGER, ESPECIALLY WHEN THE MESSAGE IS, "I SCREWED SOMETHING UP." MIKEY DICKERSON [read quote] I think this quote from my former boss, Mikey Dickerson, captures the difference between these two perspectives. Mikey was one of the first engineers brought in to rescue healthcare.gov when it failed in 2013. If you haven’t heard that story, you should find someone to tell it to you, it’s a great one. See they had a problem, the website was down all the time, and while some folks were trying to make it work, congress was holding hearings, and whether the site was up or down at any given moment was the lead story on CNN. Nobody wanted to share anything that would point the blame at themselves, even if it would be helpful in fixing the website. If you leave here having learned absolutely nothing else, I want you to walk away believing that “holding people accountable (aka firing them)” and “making systemic improvements” are unrelated problems, and maybe even mutually exclusive. So if you want to learn how to choose who to fire when something goes wrong, you’ll need to go find a different talk, this talk is about how we learn from our mistakes.
phrase “blameless post-mortem” before. This phrase refers to exactly what I was just talking about: postmortems for finding system improvements, not for finding out who to blame. I want to take just a minute and give an example of what blamelessness looks like.
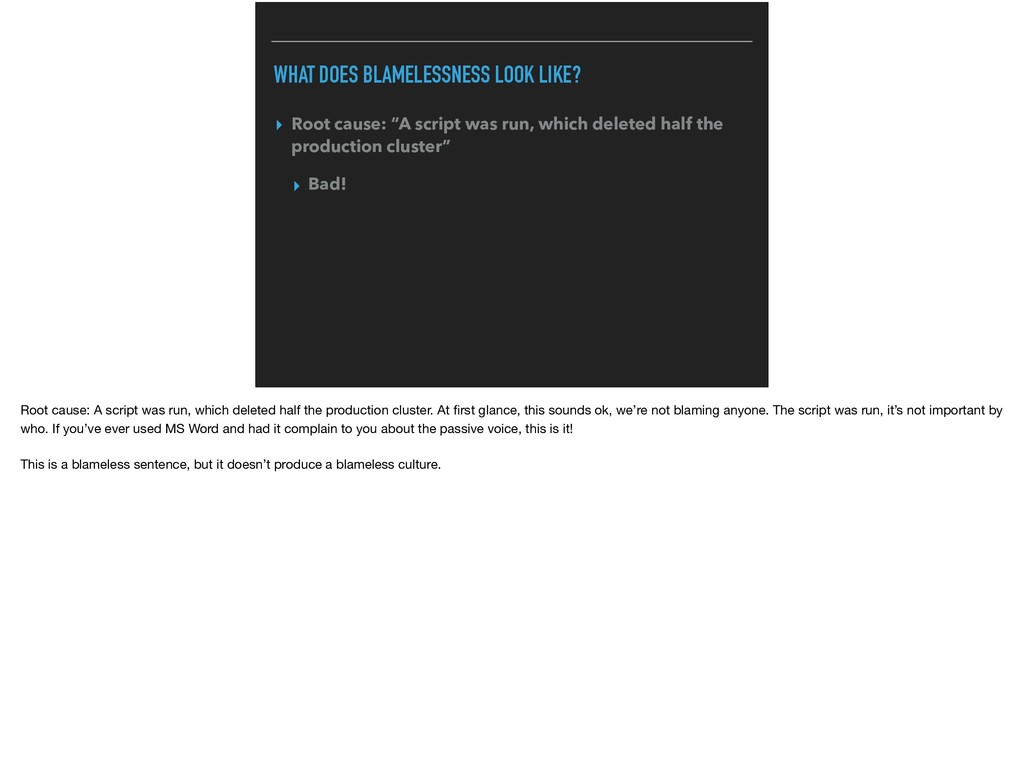
was run, which deleted half the production cluster” ▸ Bad! Root cause: A script was run, which deleted half the production cluster. At first glance, this sounds ok, we’re not blaming anyone. The script was run, it’s not important by who. If you’ve ever used MS Word and had it complain to you about the passive voice, this is it! This is a blameless sentence, but it doesn’t produce a blameless culture.
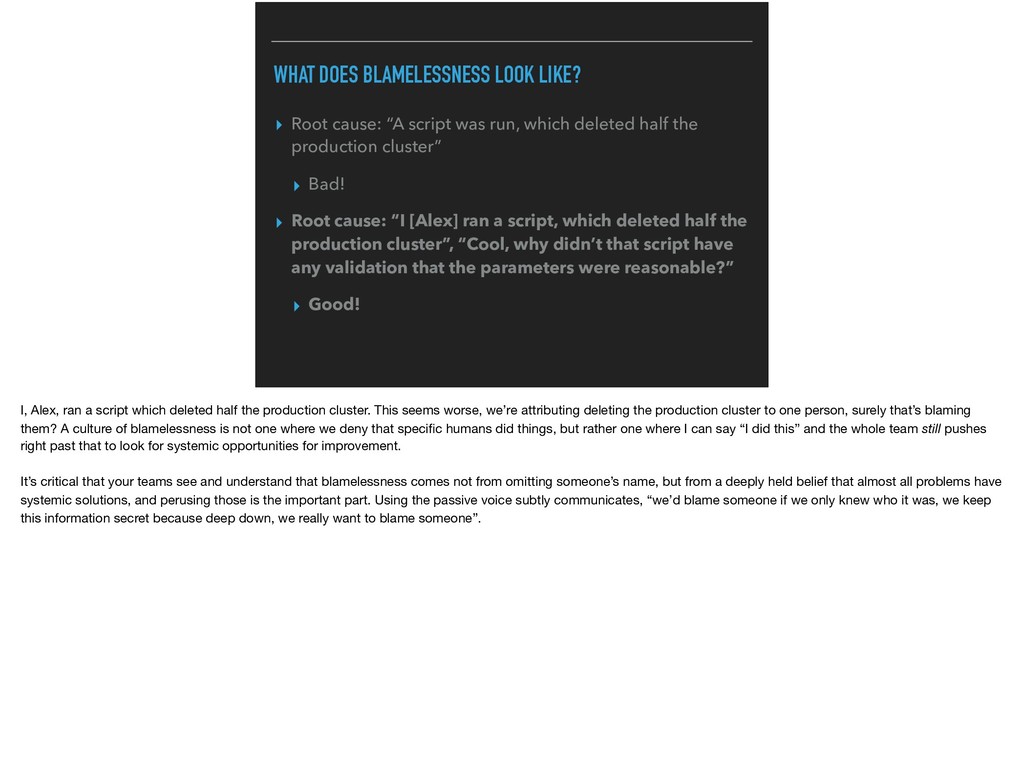
was run, which deleted half the production cluster” ▸ Bad! ▸ Root cause: “I [Alex] ran a script, which deleted half the production cluster”, “Cool, why didn’t that script have any validation that the parameters were reasonable?” ▸ Good! I, Alex, ran a script which deleted half the production cluster. This seems worse, we’re attributing deleting the production cluster to one person, surely that’s blaming them? A culture of blamelessness is not one where we deny that specific humans did things, but rather one where I can say “I did this” and the whole team still pushes right past that to look for systemic opportunities for improvement. It’s critical that your teams see and understand that blamelessness comes not from omitting someone’s name, but from a deeply held belief that almost all problems have systemic solutions, and perusing those is the important part. Using the passive voice subtly communicates, “we’d blame someone if we only knew who it was, we keep this information secret because deep down, we really want to blame someone”.
problem” or “systemic solution” several times now. If you’ll all permit a few minutes of philosophy, I want to dive into what these really mean. An operational failure happened, say the website went down. And then someone fixed the bug, re-deployed, and now the website is up. There was a failure, and now it’s resolved. What more needs doing? The iron-clad belief I bring to this process is that the operational failure that happened gave us one example presentation of an issue, but it’s one of a dozen ways some underlying failure could have presented. The job of the post-mortem process is to find the other 11, see how we can fix them all at once, and to discover what other challenges exacerbate the severity of these bugs.
ON THE NATURE OF FAILURE; HOW FAILURE IS EVALUATED; HOW FAILURE IS ATTRIBUTED TO PROXIMATE CAUSE; AND THE RESULTING NEW UNDERSTANDING OF PATIENT SAFETY I wish I had the time to fully explore this material, but I want everyone to jot down the URL how [dot] complex systems [dot] fail, or you can find it in the slides online after the talk. This page summarizes some research done by Dr. Richard Cook. He’s a medical doctor who researches failure modes of complex systems, whether they are the electrical grid, hospitals, or production distributed systems. If you’ve got a handful of webservers, a load balancer, a network filesystem, a database, and a monitoring system, you’ve got a complex system. One of the major observations of Dr. Cook’s research is that for complex systems, they already do a lot of work to handle failures, so any operational failure will have multiple contributing factors. Because of this, it’s likely that whatever changed to initiative the operational failure merely triggered a set of pre-existing, latent, bugs. It’s critical we regard the latent bugs as being as much a part of the cause of the incident as the proximate change which made them active. It’s also important that we consider things that may not be bugs, but which nonetheless are contributing factors to out incident. Now go forth and read this website, ideally after I’m done talking, but it’s pretty good stuff, I won’t blame you if you start reading it right away.
underlying philosophical rational for post-mortems, I’ve told you you have to have one. What the heck is a post-mortem? A post mortem is a process, usually in the form of a meeting and a written document, whose goal is to take our single, specific, operational failure and turn it into learning. Learning in the form of improvements to your code, improvements to your documentation, improvements to your process, improvements to the weird script on David and Sarah’s laptops that accidentally became critical production infrastructure. Learning in the form of a document that people who join the company in 6 months can read to understand what happened. And most importantly: learning in the form of turning this specific incident into observations about a more general pattern. Post-mortems are put together by the team responsible for operations and for implementing the lessons learned. If you’re SSHing into servers to fix things, you’re in the post-mortem. If you’re going to be responsible for redoing the Chef cookbooks, you’re in the post mortem. Post-mortems aren’t something someone puts together about someone else, they’re done by and for the people doing the work. The format I’ve seen work well is, a few days after the incident, everyone involved meets together, shares their notes, and produces the document together.
room, we’re sitting down to write our post-mortem for something that just happened, what do we need to make sure it contains? I’m going to run through the elements of a post mortem, with examples. This isn’t a hard-and-fast rule, but these are the elements I’ve seen as being necessary to get the important lessons, and which seem to match up with what friends at other companies use. I personally find it helpful to create a template with each of these fields, and when I say a template, I mean a markdown file with a few pre-filled headers, nothing fancy. It’s useful for your postmortems to all have the same format as each other. That said, practicality beats purity, if one of your incidents is significantly different from another, don’t shoehorn it into a template that doesn’t make sense.
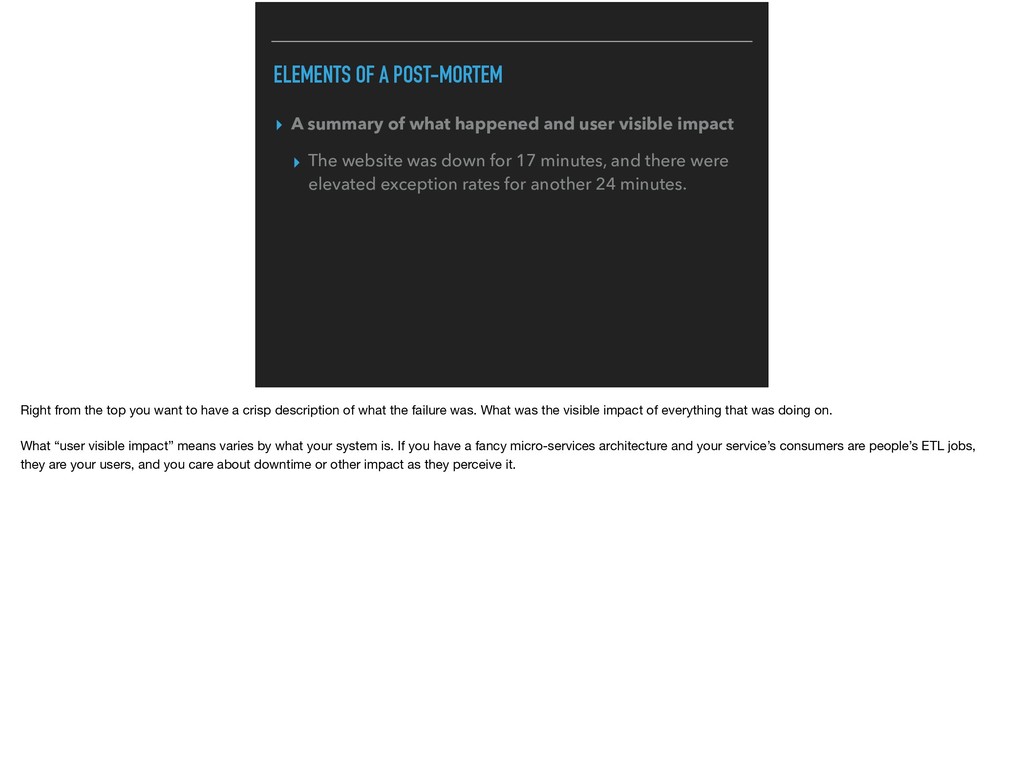
and user visible impact ▸ The website was down for 17 minutes, and there were elevated exception rates for another 24 minutes. Right from the top you want to have a crisp description of what the failure was. What was the visible impact of everything that was doing on. What “user visible impact” means varies by what your system is. If you have a fancy micro-services architecture and your service’s consumers are people’s ETL jobs, they are your users, and you care about downtime or other impact as they perceive it.
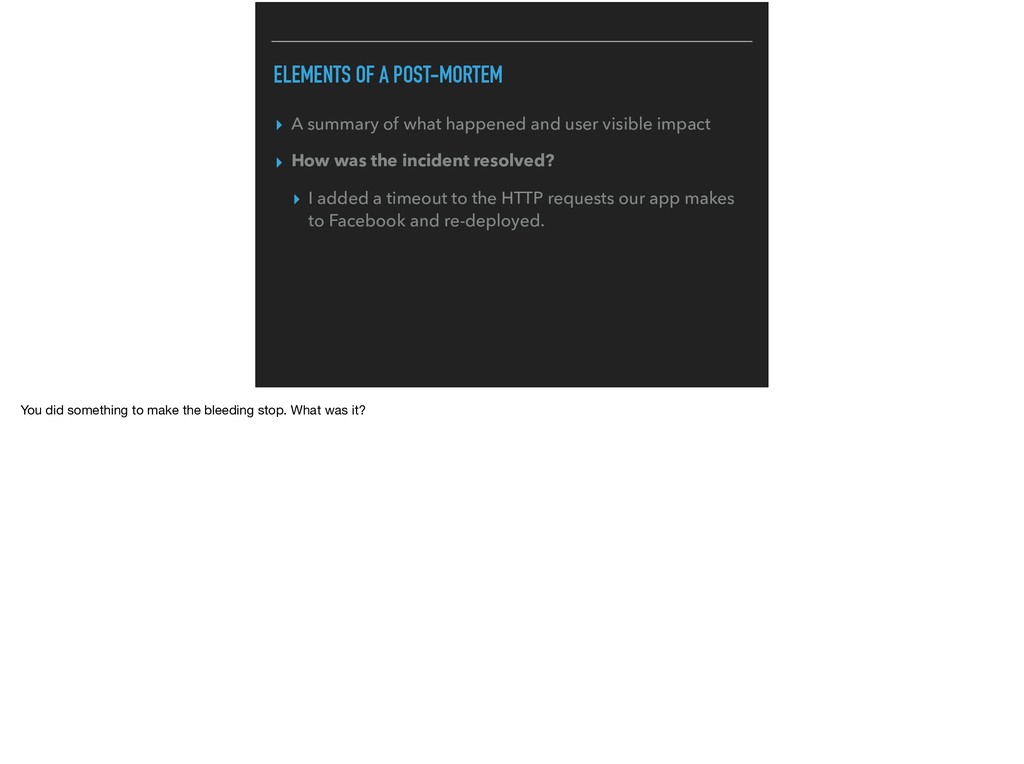
and user visible impact ▸ How was the incident resolved? ▸ I added a timeout to the HTTP requests our app makes to Facebook and re-deployed. You did something to make the bleeding stop. What was it?
and user visible impact ▸ How was the incident resolved? ▸ A complete timeline of what happened ▸ 9:09pm monitoring indicates the website is 503ing, Alex paged ▸ 9:12pm Alex acks page ▸ 9:14pm Alex restarts nginx, incident is not resolved ▸ 9:21pm Julie comments on Slack that before the incident started the API endpoints which communicate with Facebook were showing increased latency ▸ […] This is one of the most important pieces, document everything that was going and everything each person was doing. This is essential for evaluating how good your incident response process is, how well your monitoring worked, and for understanding deeply how the incident played out. Write as much as you can, there’s no such thing as too much information.
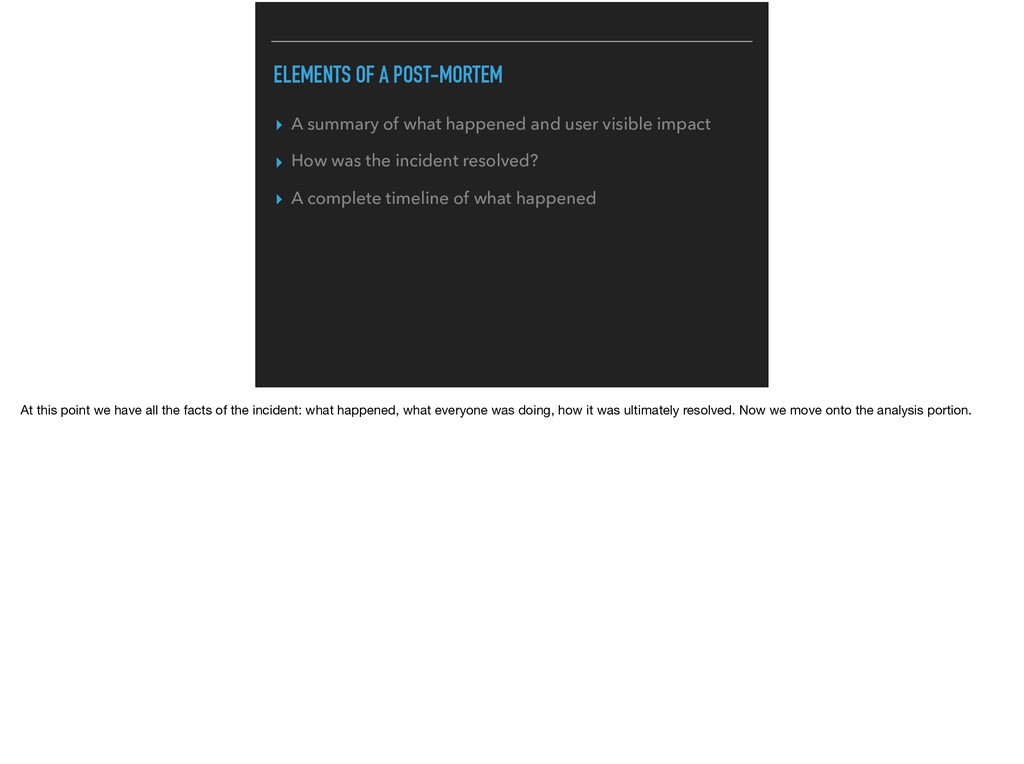
and user visible impact ▸ How was the incident resolved? ▸ A complete timeline of what happened At this point we have all the facts of the incident: what happened, what everyone was doing, how it was ultimately resolved. Now we move onto the analysis portion.
and user visible impact ▸ How was the incident resolved? ▸ A complete timeline of what happened ▸ What were the causes of this incident? ▸ Facebook started responding to requests slowly ▸ We had no timeouts on requests to Facebook & we make blocking requests to Facebook during HTTP requests to our API ▸ Our process-per-request web server made it easy for a small number of slow requests to DoS us. This we start with an analysis of the causes. This is where all the stuff I talked about at the top, about multiple-causes comes into play. In this particular incident the proximate cause was totally out of our control, but there’s still a lot of work we can do on our side to make ourselves more resilient to when facebook gets slow next time. Dig deep here, list ever possible cause, you can decide it’s not something you’re going to pursue fixing later— take a lesson from my experience though, if you dig all the way down to “computers were a mistake”, you’ve gone too far.
and user visible impact ▸ How was the incident resolved? ▸ A complete timeline of what happened ▸ What were the causes of this incident? ▸ What went well & poorly during the handling of the incident itself? ▸ Our monitoring/graphing didn’t do a good job highlighting which endpoints were slow ▸ We didn’t have any monitoring on the latency/error rates of outbound requests to Facebook, so we had to know that particular URLs on our site being slow potentially implicated Facebook ▸ Once we had a fix developed, we were able to deploy it to production very quickly and the incident was resoled Being good at responding to incidents when they do happen is a critical element of resiliency, so we need to review how things went during the incident itself. In this case there are opportunities to make improvements to our monitoring. On the good side, our deployment system worked flawlessly during the middle of this incident, so that’s good.
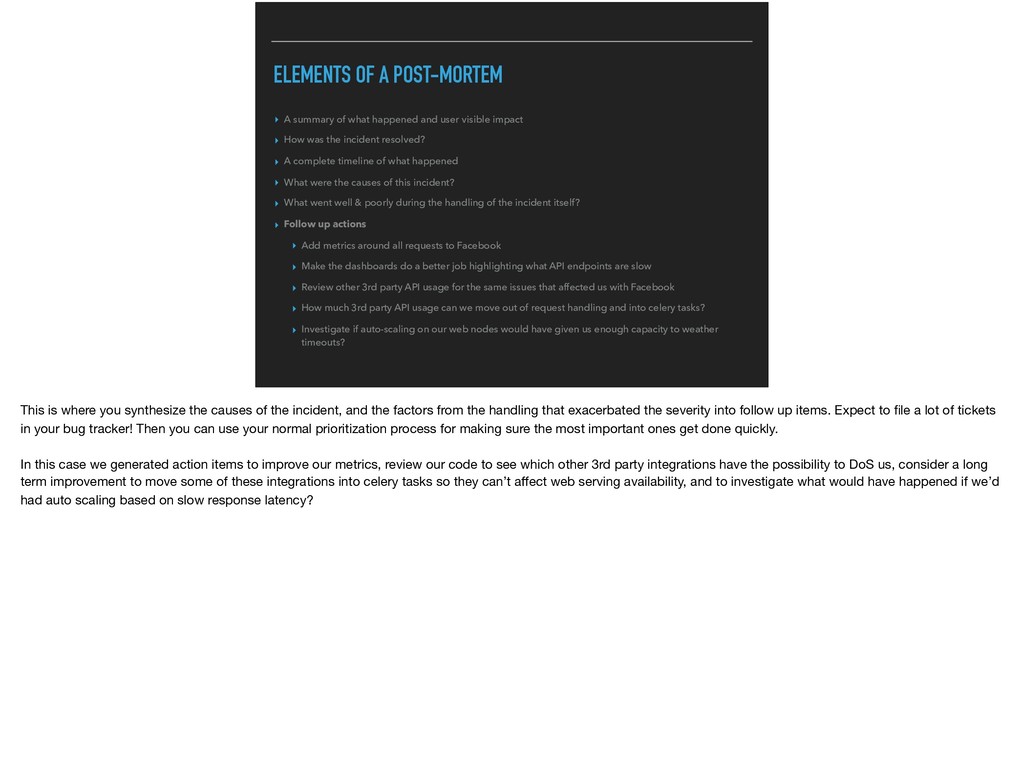
and user visible impact ▸ How was the incident resolved? ▸ A complete timeline of what happened ▸ What were the causes of this incident? ▸ What went well & poorly during the handling of the incident itself? ▸ Follow up actions ▸ Add metrics around all requests to Facebook ▸ Make the dashboards do a better job highlighting what API endpoints are slow ▸ Review other 3rd party API usage for the same issues that affected us with Facebook ▸ How much 3rd party API usage can we move out of request handling and into celery tasks? ▸ Investigate if auto-scaling on our web nodes would have given us enough capacity to weather timeouts? This is where you synthesize the causes of the incident, and the factors from the handling that exacerbated the severity into follow up items. Expect to file a lot of tickets in your bug tracker! Then you can use your normal prioritization process for making sure the most important ones get done quickly. In this case we generated action items to improve our metrics, review our code to see which other 3rd party integrations have the possibility to DoS us, consider a long term improvement to move some of these integrations into celery tasks so they can’t affect web serving availability, and to investigate what would have happened if we’d had auto scaling based on slow response latency?
of a post-mortem, I’m going to give everybody some homework. I’m going to describe an incident, and seed your thoughts with a few follow-ups I see. I want everyone here to take this home and think about what else you saw in this situation, what systematic opportunities are there for improvement.
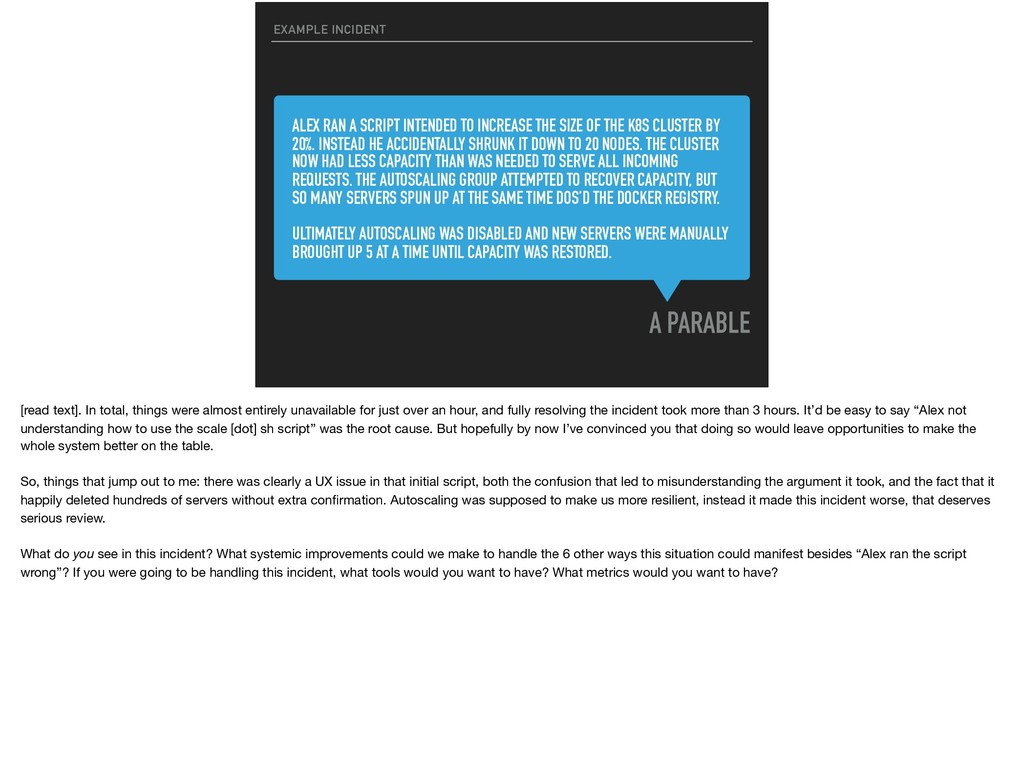
THE K8S CLUSTER BY 20%. INSTEAD HE ACCIDENTALLY SHRUNK IT DOWN TO 20 NODES. THE CLUSTER NOW HAD LESS CAPACITY THAN WAS NEEDED TO SERVE ALL INCOMING REQUESTS. THE AUTOSCALING GROUP ATTEMPTED TO RECOVER CAPACITY, BUT SO MANY SERVERS SPUN UP AT THE SAME TIME DOS’D THE DOCKER REGISTRY. ULTIMATELY AUTOSCALING WAS DISABLED AND NEW SERVERS WERE MANUALLY BROUGHT UP 5 AT A TIME UNTIL CAPACITY WAS RESTORED. A PARABLE EXAMPLE INCIDENT [read text]. In total, things were almost entirely unavailable for just over an hour, and fully resolving the incident took more than 3 hours. It’d be easy to say “Alex not understanding how to use the scale [dot] sh script” was the root cause. But hopefully by now I’ve convinced you that doing so would leave opportunities to make the whole system better on the table. So, things that jump out to me: there was clearly a UX issue in that initial script, both the confusion that led to misunderstanding the argument it took, and the fact that it happily deleted hundreds of servers without extra confirmation. Autoscaling was supposed to make us more resilient, instead it made this incident worse, that deserves serious review. What do you see in this incident? What systemic improvements could we make to handle the 6 other ways this situation could manifest besides “Alex ran the script wrong”? If you were going to be handling this incident, what tools would you want to have? What metrics would you want to have?
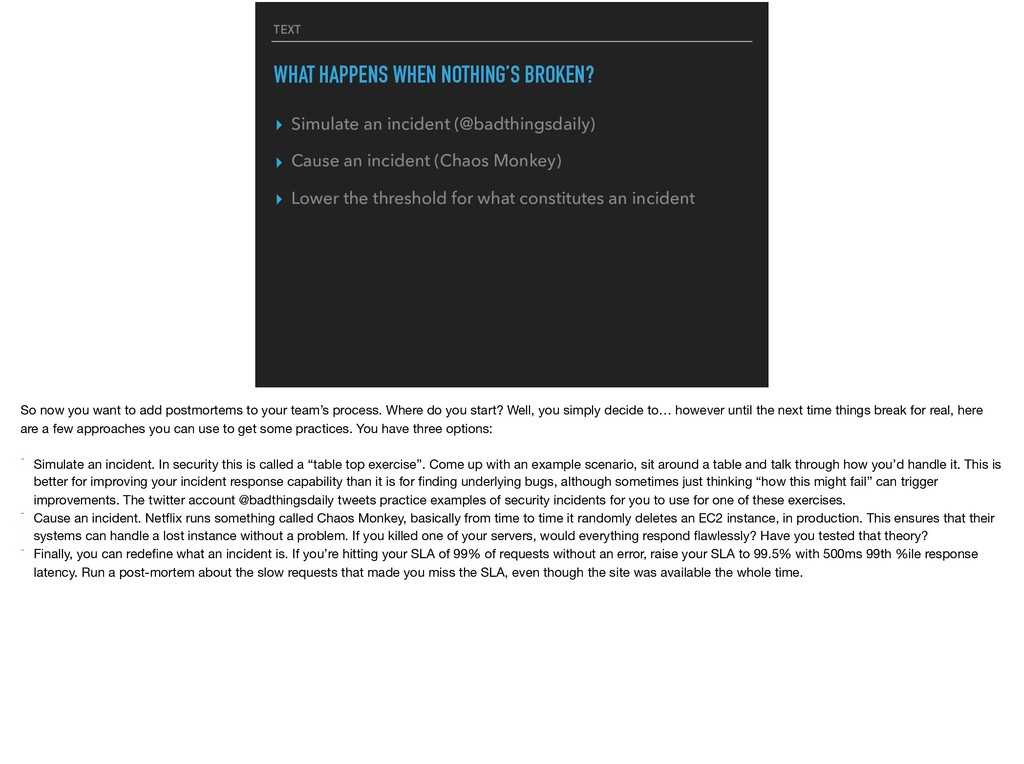
(@badthingsdaily) ▸ Cause an incident (Chaos Monkey) ▸ Lower the threshold for what constitutes an incident So now you want to add postmortems to your team’s process. Where do you start? Well, you simply decide to… however until the next time things break for real, here are a few approaches you can use to get some practices. You have three options: - Simulate an incident. In security this is called a “table top exercise”. Come up with an example scenario, sit around a table and talk through how you’d handle it. This is better for improving your incident response capability than it is for finding underlying bugs, although sometimes just thinking “how this might fail” can trigger improvements. The twitter account @badthingsdaily tweets practice examples of security incidents for you to use for one of these exercises. - Cause an incident. Netflix runs something called Chaos Monkey, basically from time to time it randomly deletes an EC2 instance, in production. This ensures that their systems can handle a lost instance without a problem. If you killed one of your servers, would everything respond flawlessly? Have you tested that theory? - Finally, you can redefine what an incident is. If you’re hitting your SLA of 99% of requests without an error, raise your SLA to 99.5% with 500ms 99th %ile response latency. Run a post-mortem about the slow requests that made you miss the SLA, even though the site was available the whole time.
of post-mortems to computer problems, but software engineers didn’t invest this idea. Post-mortems have a long history in other industries. In the military they call them hot washes or after action reviews. Doctors call them Morbidity and Mortality conferences. And they are a core part of what the NTSB does. The NTSB is an independent federal agency with a few hundred employees. They’re responsible for investigating transportation accidents, be they planes, trains, or automobiles. The mission of the NTSB is, “to determine the probable cause of transportation accidents and incidents and to formulate safety recommendations to improve transportation safety”. Tell me that doesn’t sound familiar. The NTSB performs investigations by what they call the party system. Basically, in addition to their own team members, the party will also include people from industry, including people directly from the organizations involved in the accident. If the accident was an engine malfunction as an airplane was on final descent, there’ll probably be someone from the engine manufacturer, air traffic control, and the airline who are a part of the party. You cannot investigate the causes of an accident without having experts from all those perspectives in the room. However, you can’t be a member of an insurance company and be a member of a party; insurance companies are all about allocating blame. Probably the most important thing to know about the NTSB is that they are not a law enforcement agency. They conduct accident investigations, not criminal investigations. This extends beyond merely words. The results of an NTSB investigation and the testimony they receive cannot be used as evidence in a court of law. Their public safety mission requires this. The NTSB will turn over the objective technical and scientific data, and support law enforcement with analysis of data, but the reports on underlying causes are all privileged from use in court. This is an extraordinary status, akin to attorney-client privilege or spousal privilege, and I don’t think there can be any more clear evidence that making safety recommendations is a different line of work from finding out who or what is to blame.
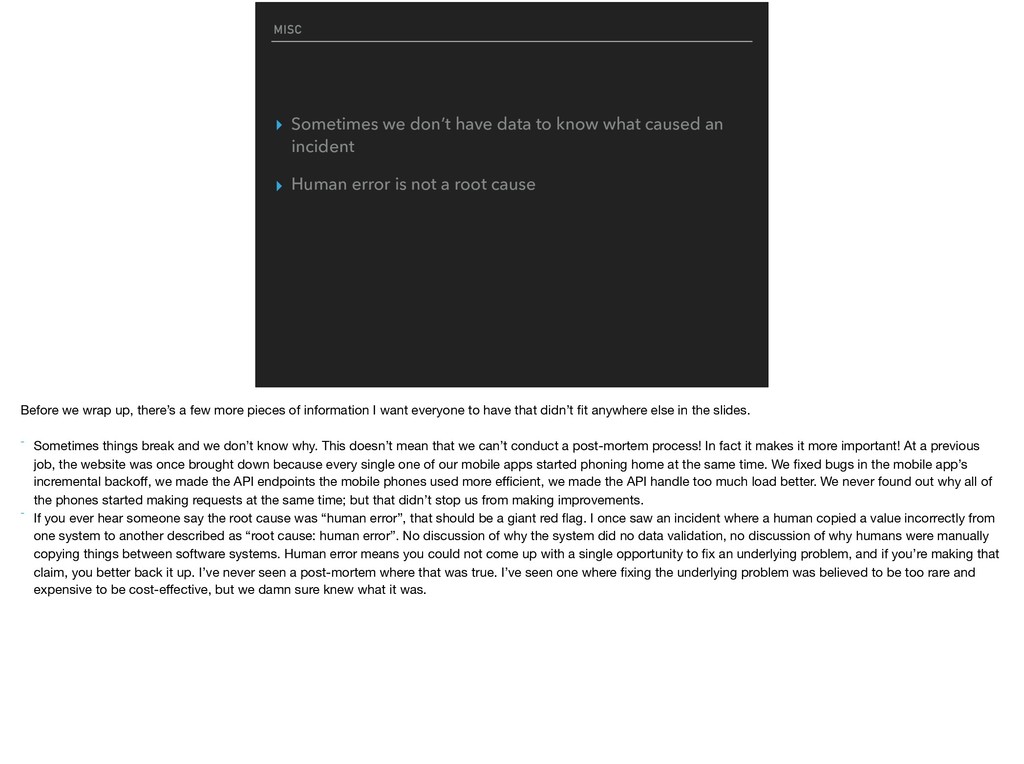
caused an incident ▸ Human error is not a root cause Before we wrap up, there’s a few more pieces of information I want everyone to have that didn’t fit anywhere else in the slides. - Sometimes things break and we don’t know why. This doesn’t mean that we can’t conduct a post-mortem process! In fact it makes it more important! At a previous job, the website was once brought down because every single one of our mobile apps started phoning home at the same time. We fixed bugs in the mobile app’s incremental backoff, we made the API endpoints the mobile phones used more efficient, we made the API handle too much load better. We never found out why all of the phones started making requests at the same time; but that didn’t stop us from making improvements. - If you ever hear someone say the root cause was “human error”, that should be a giant red flag. I once saw an incident where a human copied a value incorrectly from one system to another described as “root cause: human error”. No discussion of why the system did no data validation, no discussion of why humans were manually copying things between software systems. Human error means you could not come up with a single opportunity to fix an underlying problem, and if you’re making that claim, you better back it up. I’ve never seen a post-mortem where that was true. I’ve seen one where fixing the underlying problem was believed to be too rare and expensive to be cost-effective, but we damn sure knew what it was.
errors will show up faster than you can fix one off bugs If you don’t fix classes of bugs at the root, you’ll end up generating more classes of bugs faster than you can fix individual bugs. As time advances you’re product will get less and less reliable as more systemic errors are added.
errors will show up faster than you can fix one off bugs ▸ Hone your craft Software engineering is a discipline that requires practice to improve at. If you don’t take the opportunity to learn from your mistakes, you are missing out an awful lot of learning opportunities. Particularly, once you learn to recognize certain classes of errors, you can avoid making them right from the start on your next project. There are an awful lot of types of bugs that are very cheap to avoid if you know about them at the start, and very expensive to fix after the fact, once your project is large. An ounce of prevention is worth a pound of cure.
errors will show up faster than you can fix one off bugs ▸ Hone your craft ▸ Fixing bugs systemically is cheaper than fixing them one at a time Finally, and perhaps most importantly, in the long term, it’s almost always way cheaper to fix a bug at the root, once, than it is to fix each of the individual ways the bug manifests itself.
for blaming people ▸ Blamelessness is about psychological safety, not using the passive voice ▸ Analyzing specific failures in your system is an opportunity to extract more general observations about how it responds to failure ▸ Both your system and your post-mortem process will improve with practice ▸ The operations of complex systems has many characteristics that defy our expectations: https://how.complexsystems.fail/ ▸ The incident already happened, don’t waste the opportunity to learn something from it ▸ Human error is not a root cause. Human error is not a root cause. Human error i
for spending your Sunday afternoon with me! That’s my website and the URL the slide will be up on. We have a few minutes for questions if anyone wants to ask anything. Hopefully everybody knows this by now, but a question is something you don’t already know the answer to!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}