The Bayesian information sharing module for the "Adaptive and Bayesian Methods for Clinical Trial Design Short Course" by Dr. Alex Kaizer. We review motivation and highlight some statistical methods to facilitate incorporating historic, external, or supplemental data sources into a clinical trial.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
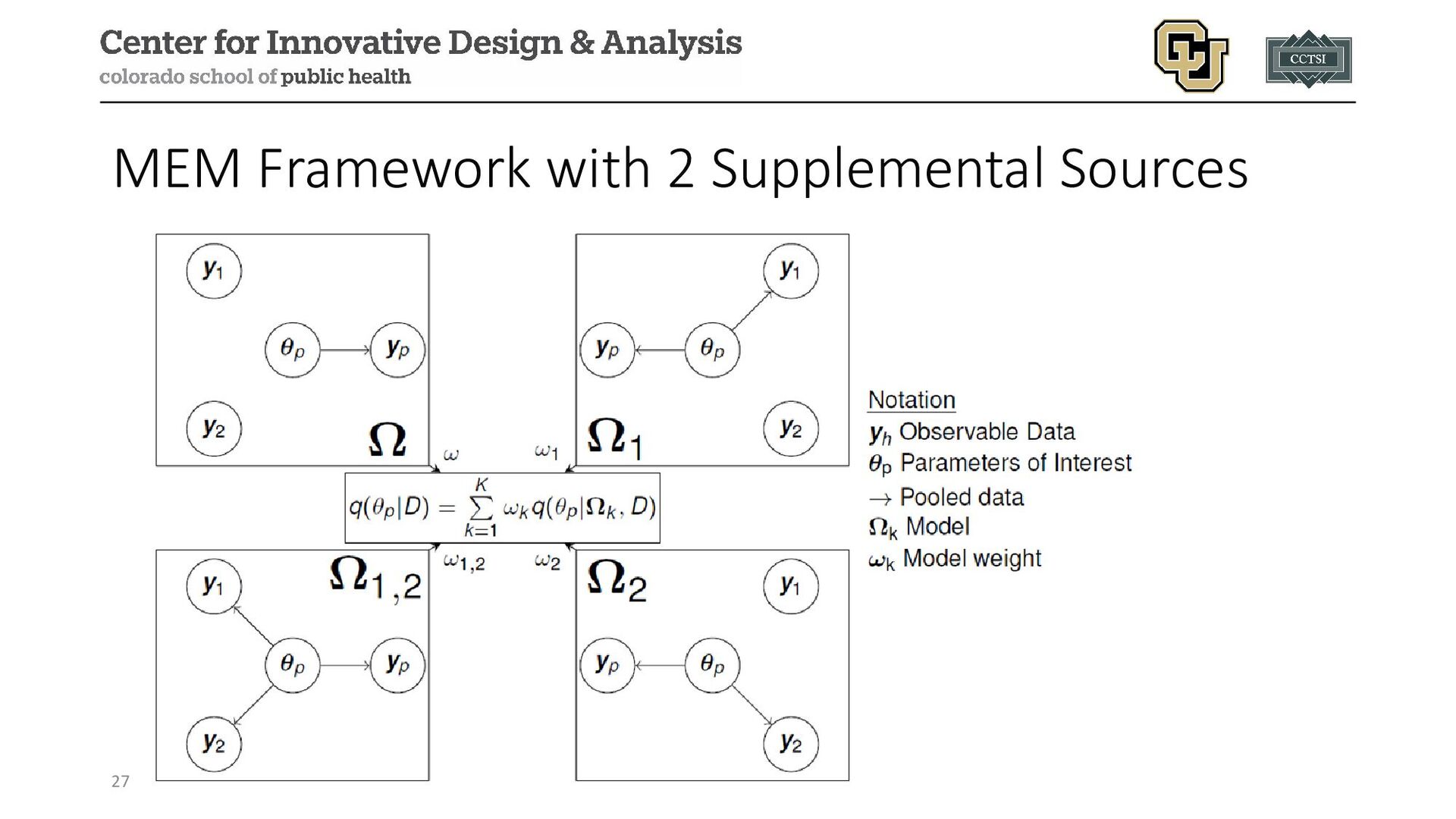{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
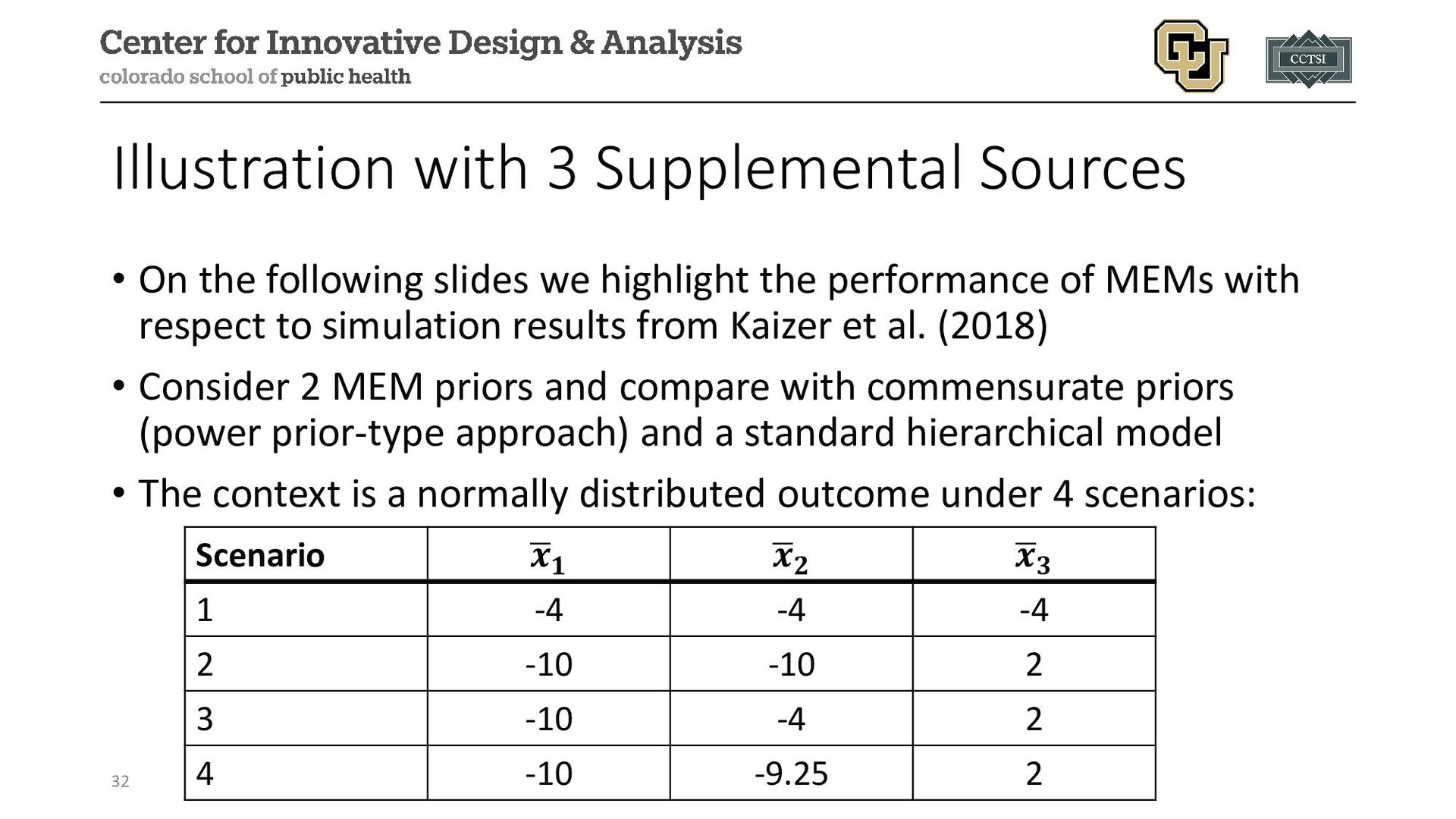{kind=link}
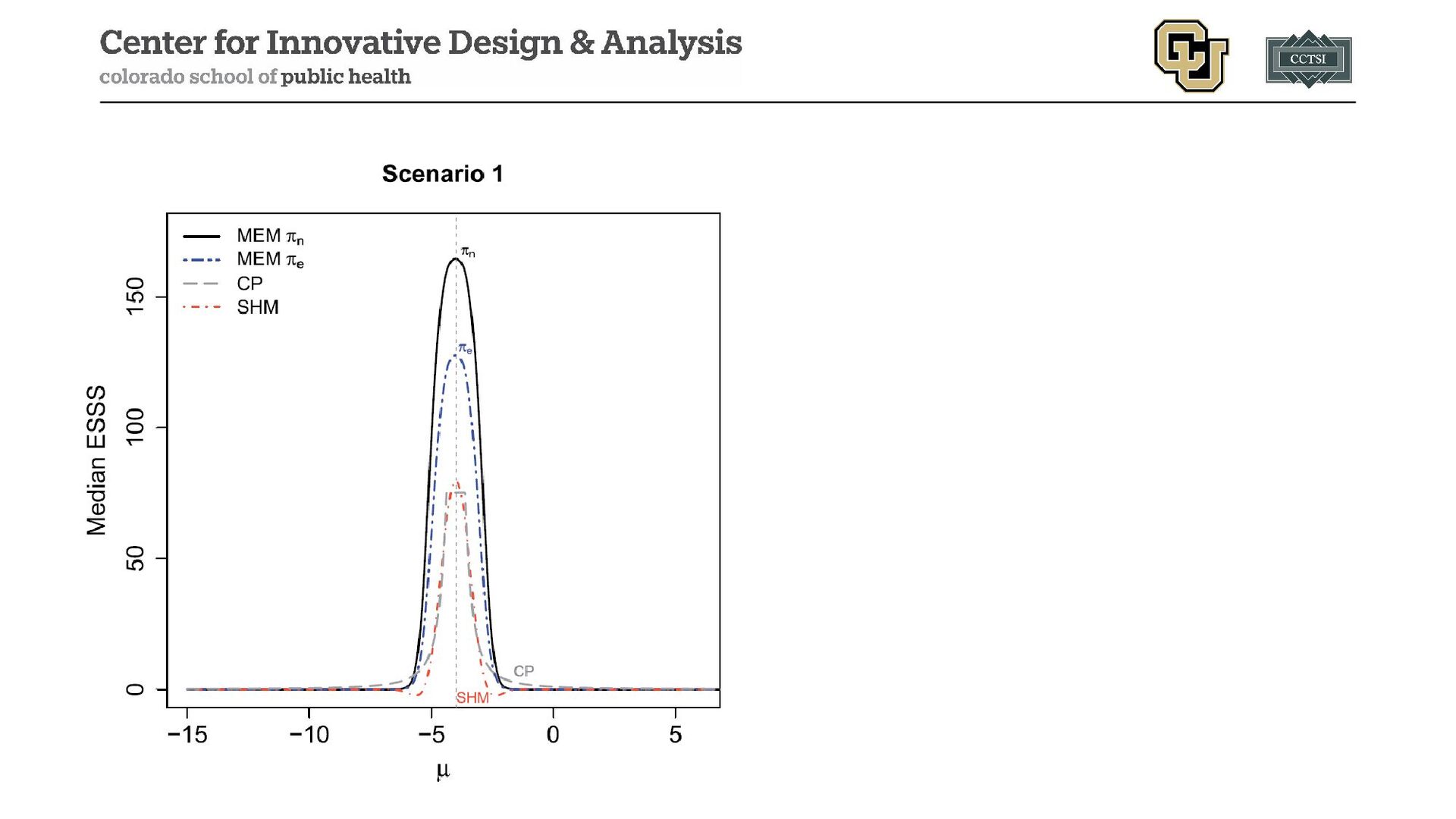{kind=link}
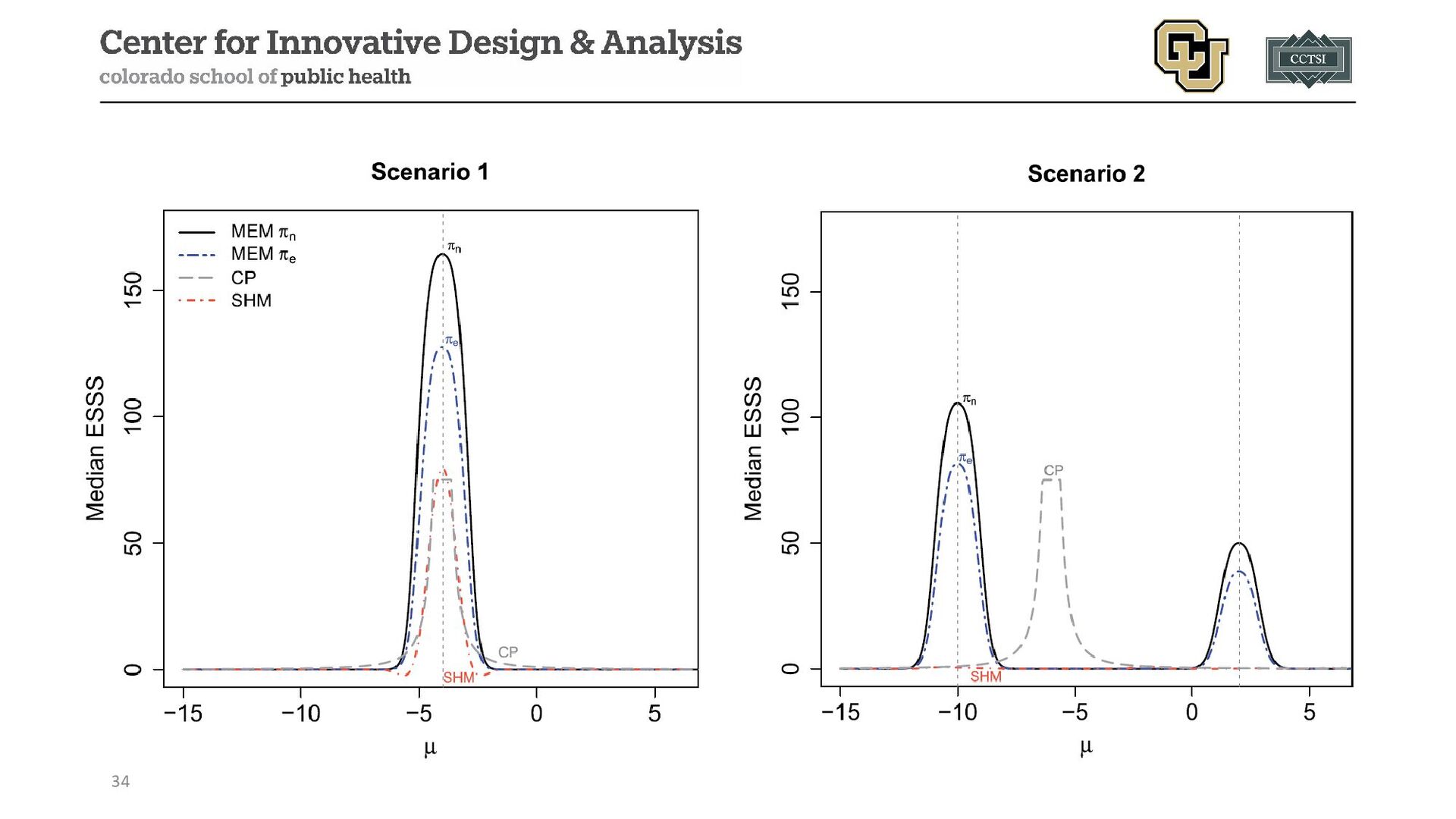{kind=link}
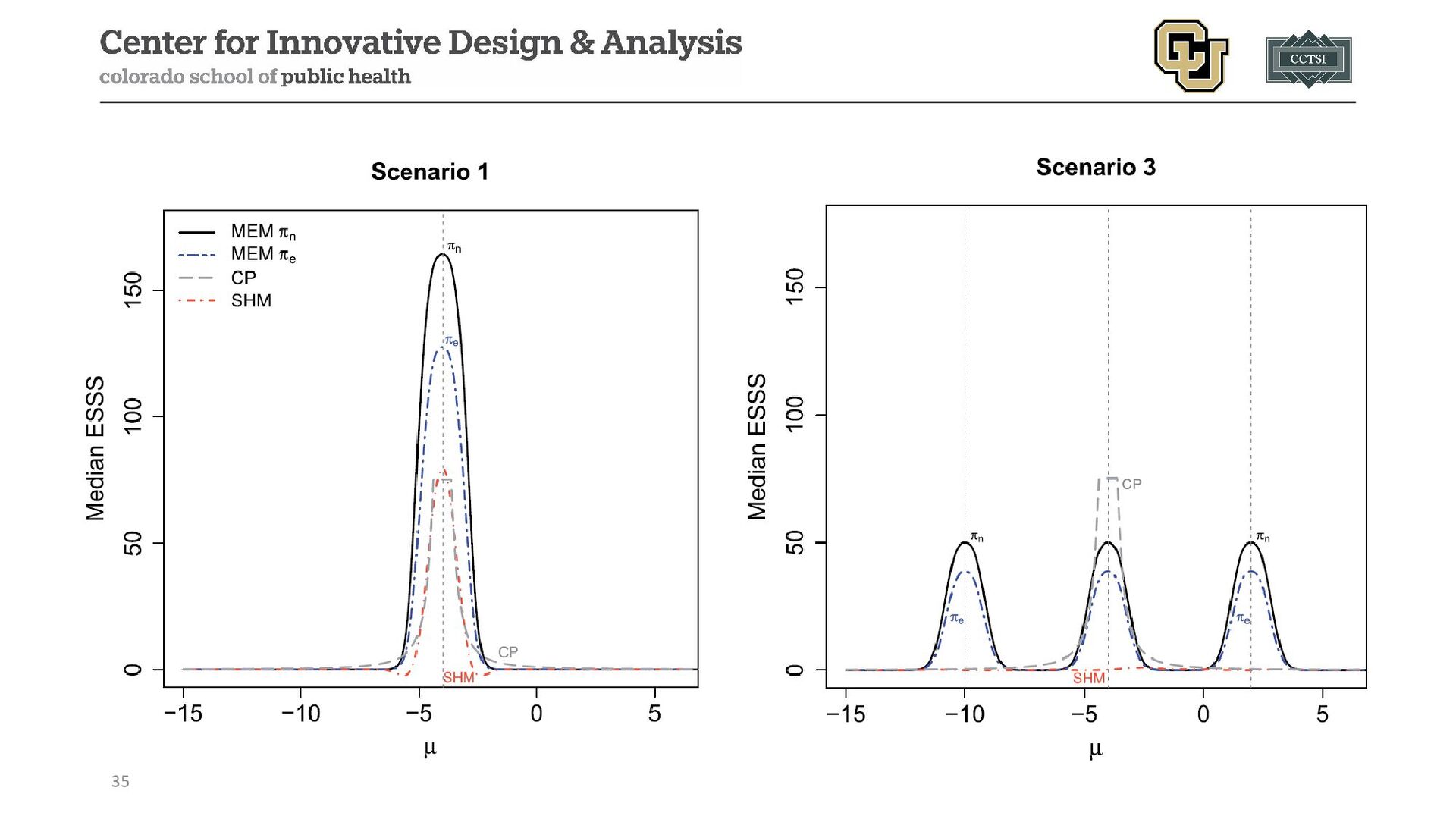{kind=link}
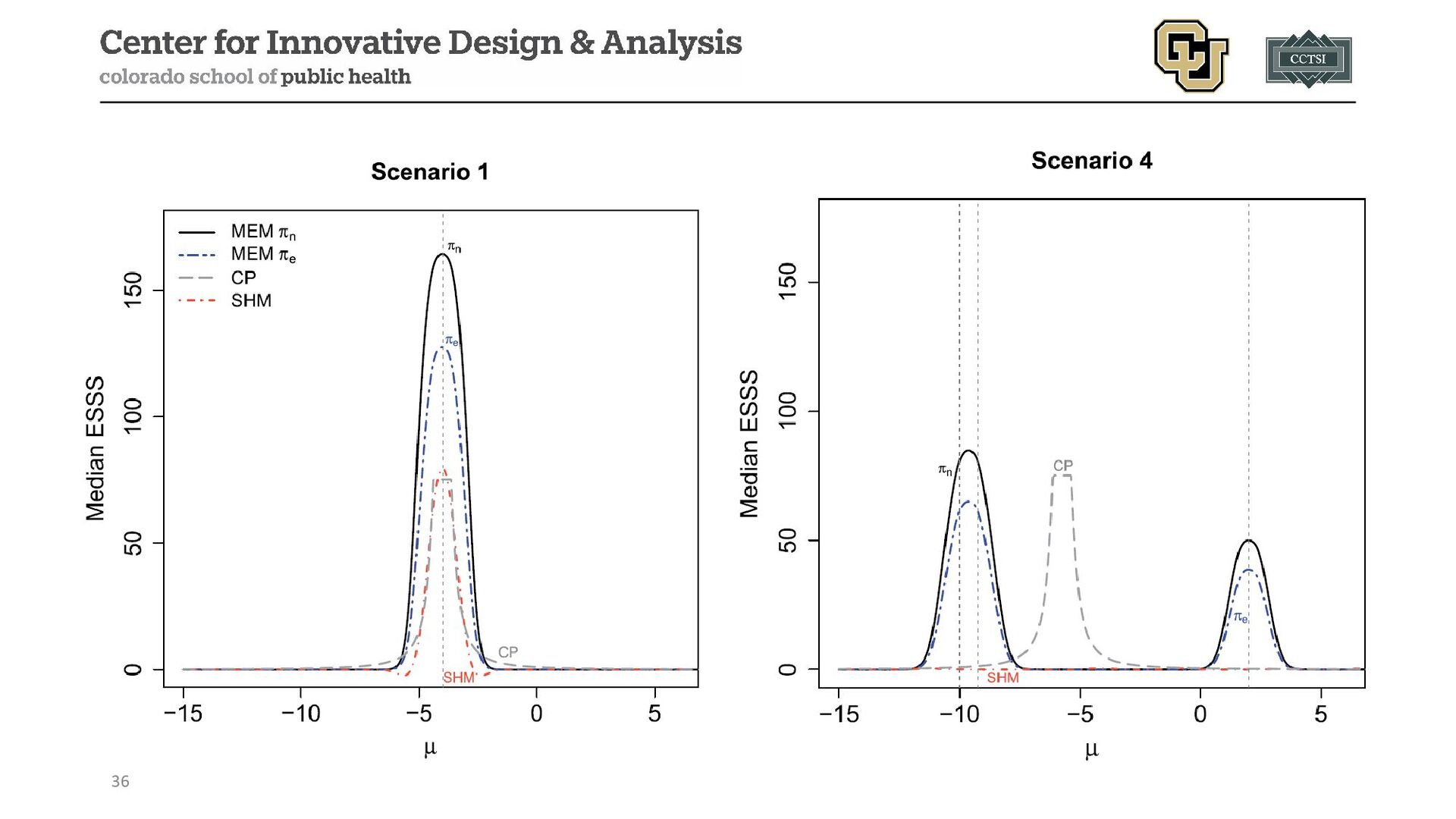{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
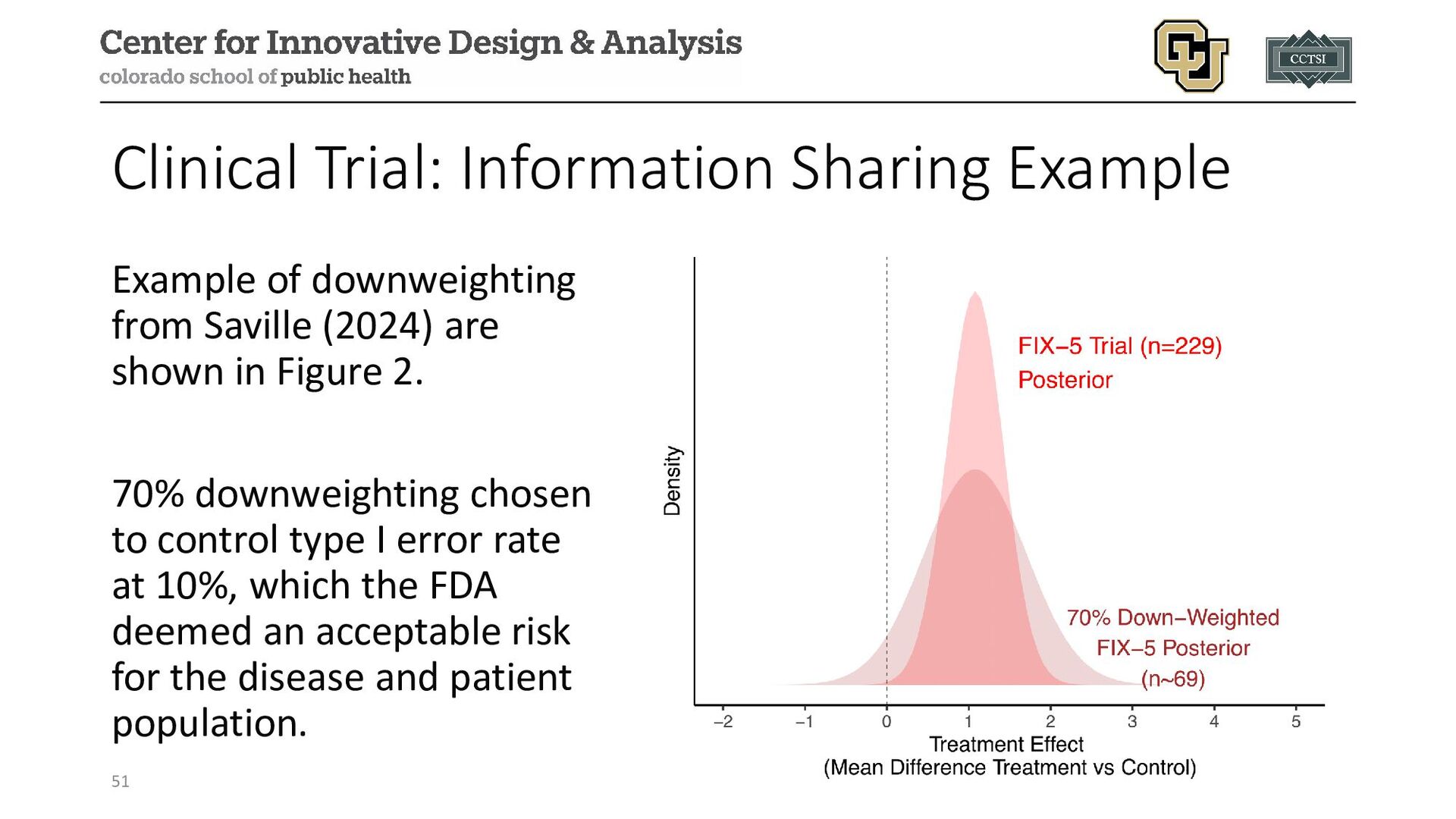{kind=link}
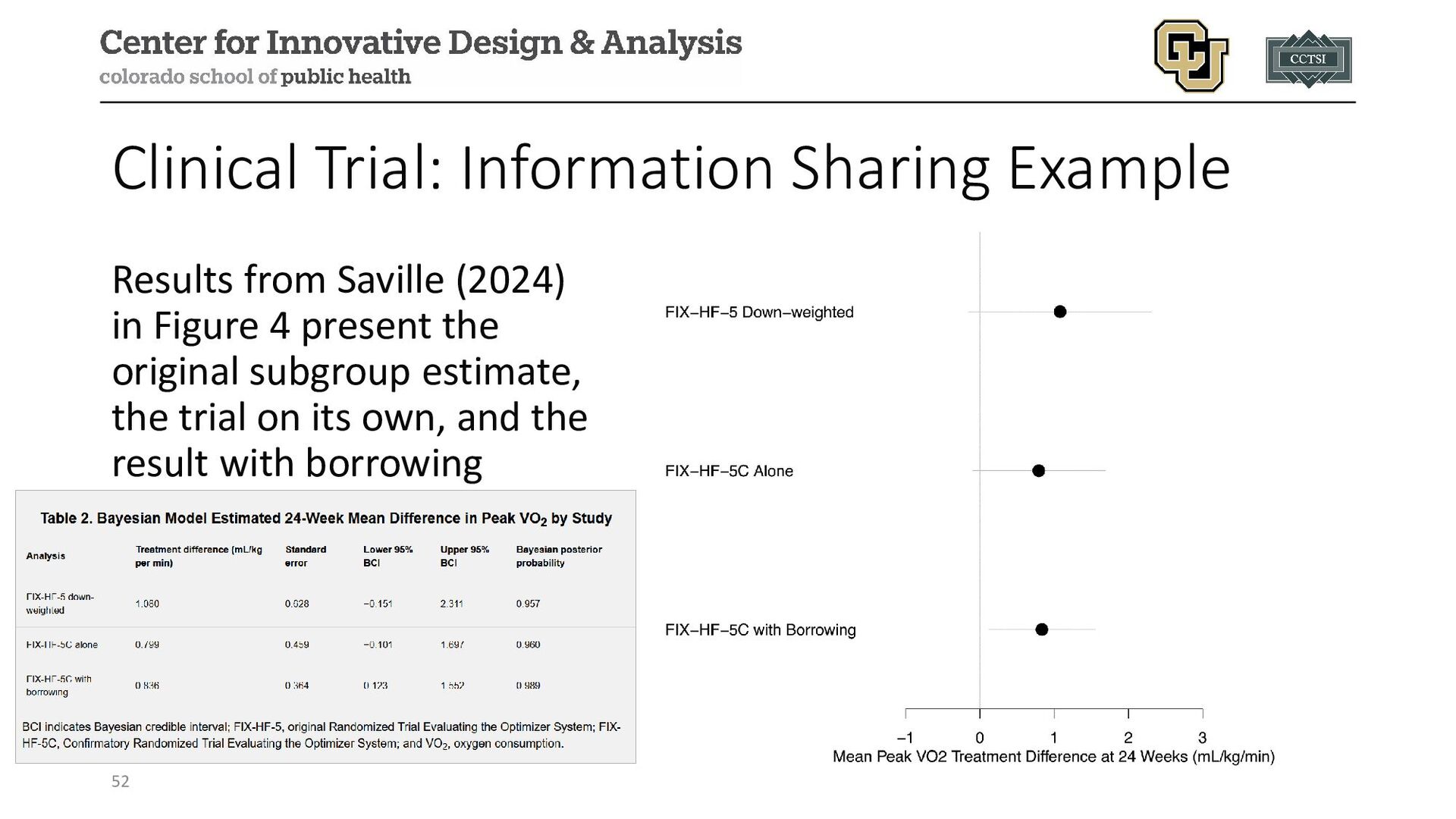{kind=link}
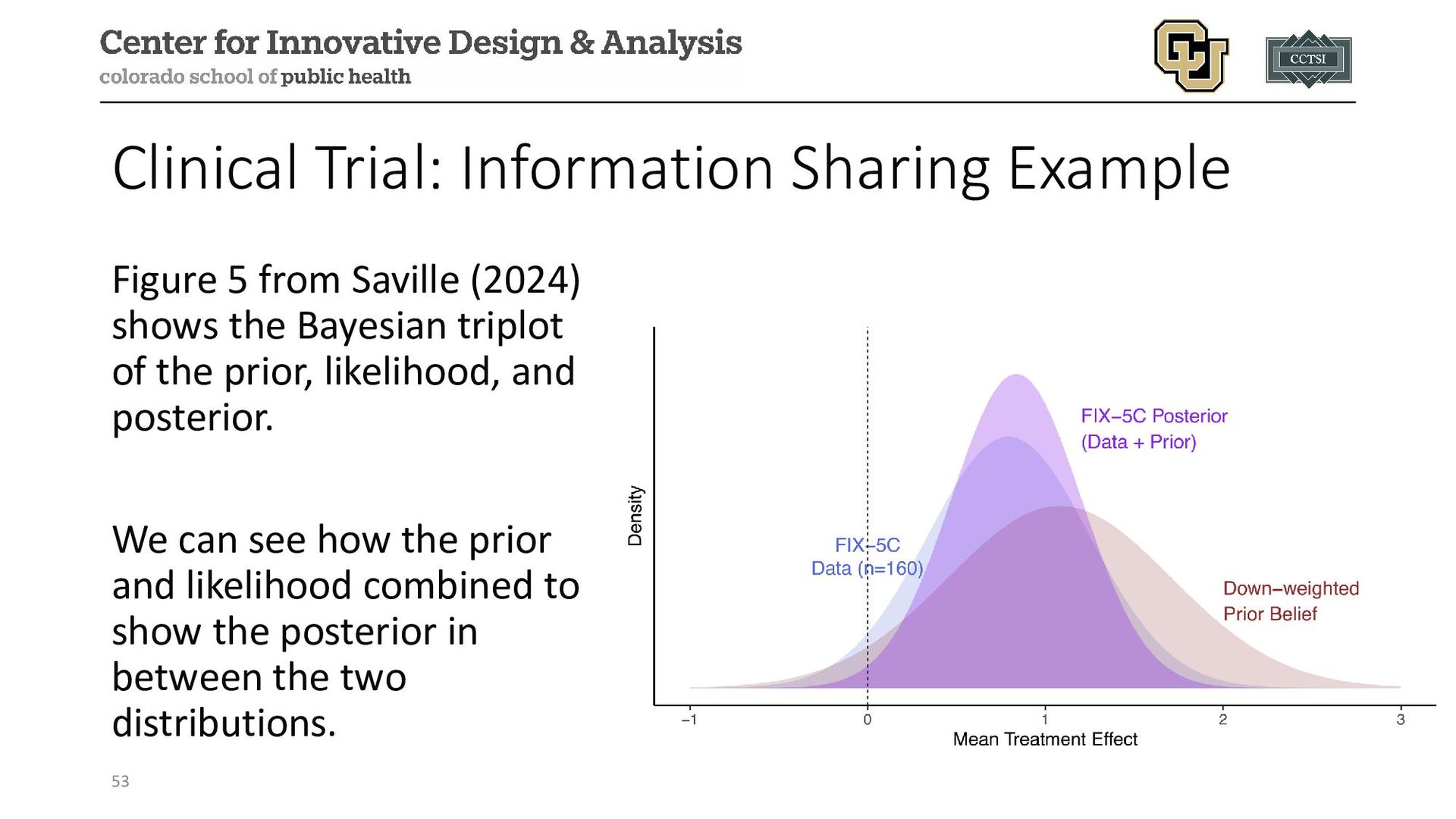{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Contact Info: • Email: • [email protected] • Website: www.alexkaizer.com •](https://files.speakerdeck.com/presentations/5a2ffc83655b4dafaae254de01753cd3/slide_57.jpg){kind=link}