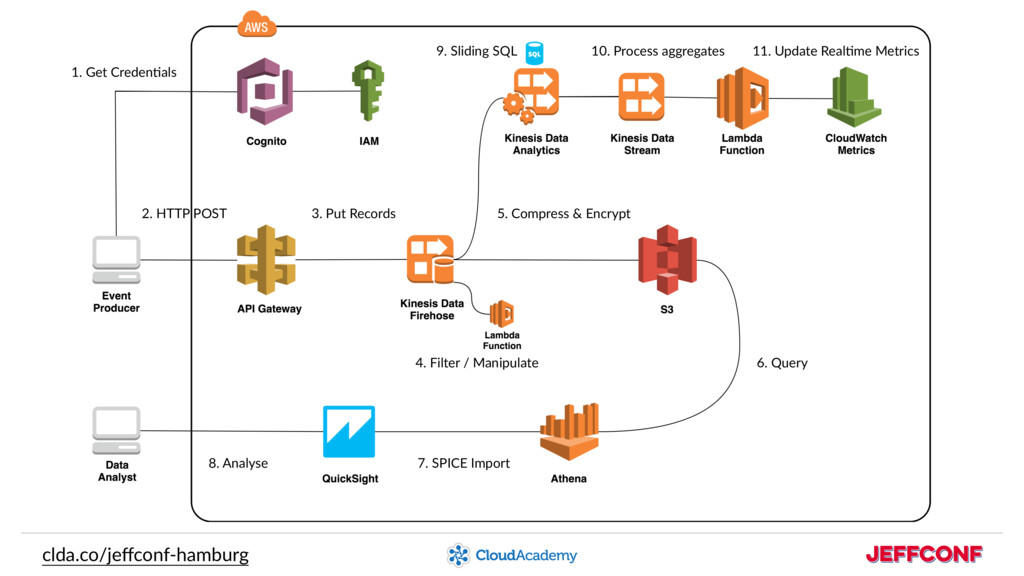
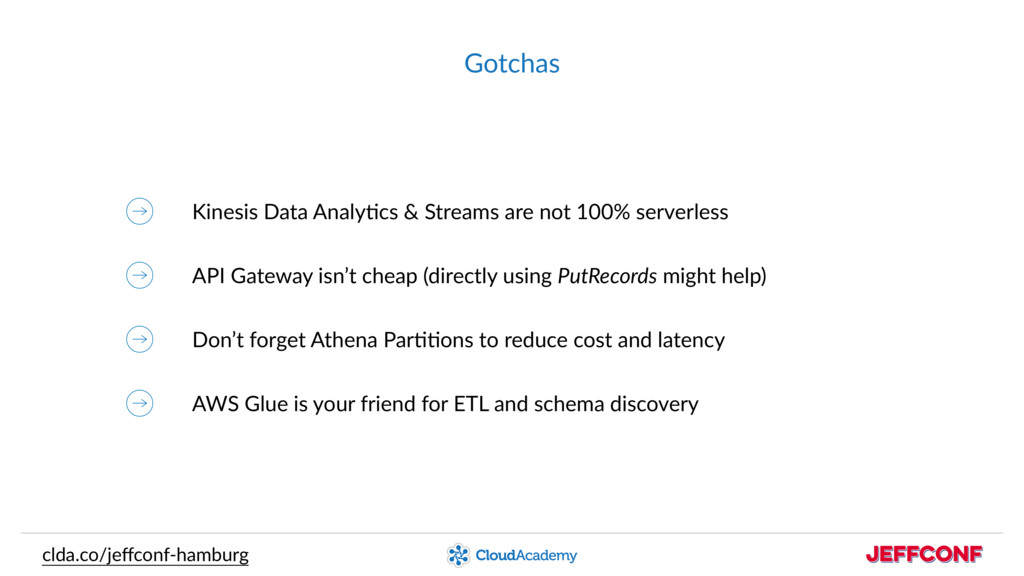
Data science teams need to reduce storage and maintenance costs, and at the same time provide analytics tools for data analysts and scientists.
How can we make data collection and data analysis exciting, performant, and cost-effective in the Cloud?
Alex will connect the dots around the data processing building blocks provided by AWS, without managing any servers!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}