send tasks to real humans, ~0.01$ per page Programming humans! Problem: not scalable! 1 million+ pages to process per week, 10 000$/week Quality not the best. (Foreshadowing: we’re going to need this anyways)
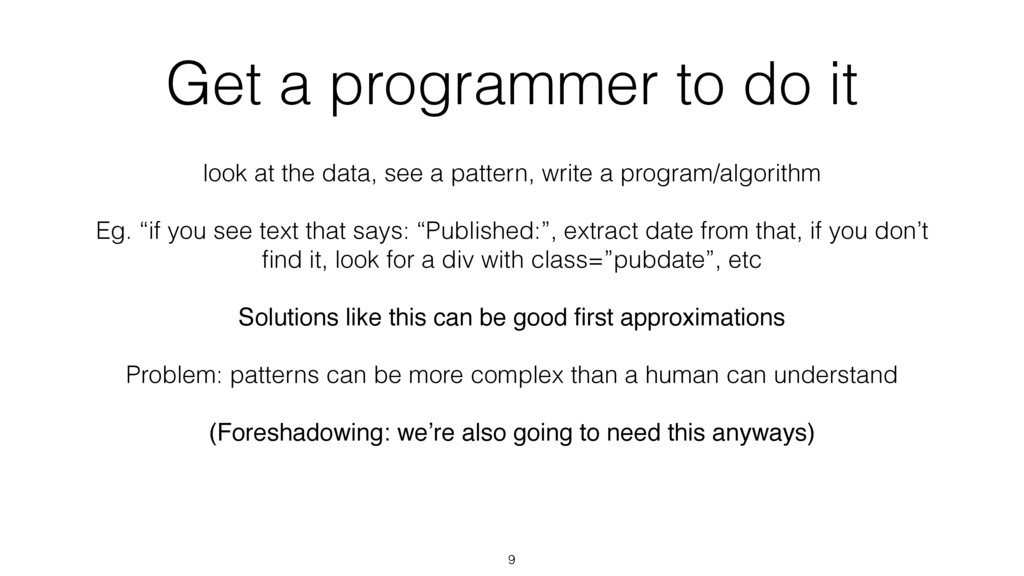
see a pattern, write a program/algorithm Eg. “if you see text that says: “Published:”, extract date from that, if you don’t find it, look for a div with class=”pubdate”, etc Solutions like this can be good first approximations Problem: patterns can be more complex than a human can understand (Foreshadowing: we’re also going to need this anyways) 9
“see” a pattern that is more complex than humans can see -note: ML includes both previous solutions: We’re going to do supervised learning: you will need humans to get examples of pages and correct dates to train the model And you will need heuristics to figure out the features to tell the model to pay attention to
Only use it if the volume of your data, or problem complexity is too much for previous solutions Eg. friend who wanted to parse dates, hiring intern vs. ML, asked her how much data she had, 2000 results -- fastest and most accurate is to actually just do it by hand at that point, even faster than signing up for mechanical turk
elements that contain a date 2) Calculate feature on each of these chunks 3) Pass each feature vector to trained classifier, get label 4) Decide which chunk to take, if more than one gets true answer 5) Extract date string from chunk 6) Fine-tuning
Babbage, if you put into the machine wrong figures, will the right answers come out?" … I am not able rightly to apprehend the kind of confusion of ideas that could provoke such a question. -Charles Babbage, 1864
look at page and enter the date in csv URL, PUBLICATION DATE Download all pages from url to use as training data People are often wrong 3 people fill out same csv, only take result if all 3 agree
entered into csv, web page goes 404 • Articles have pub dates when viewed in the browser but when you download with requests you get no data because site uses react.js • CSV AND UTF-8 ERRORS: four horsemen of the parsing apocalypse • We drop results that are “N/A”, people enter NA instead so that still gets parsed • People enter incorrect results because they make a mistake or don’t care
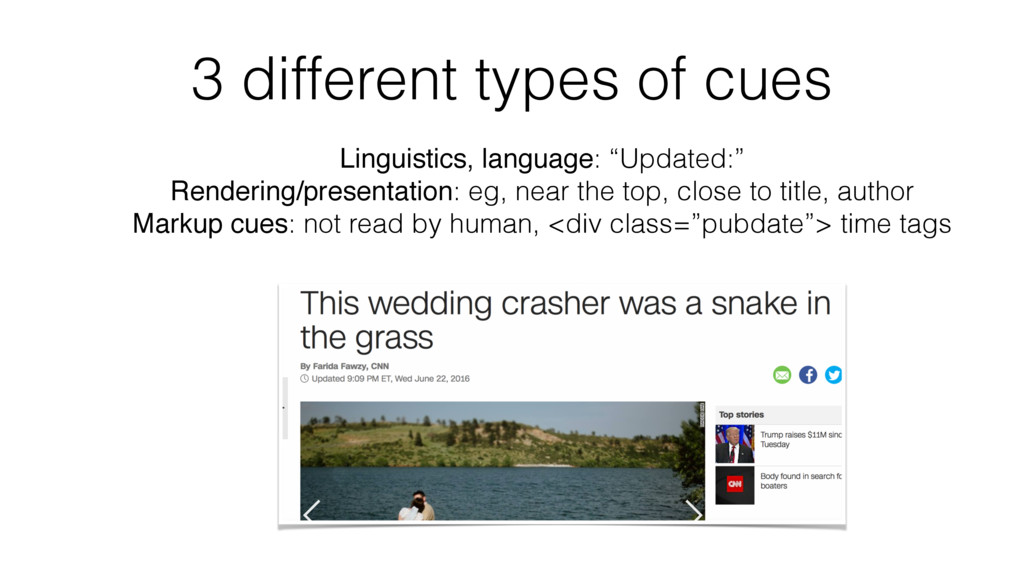
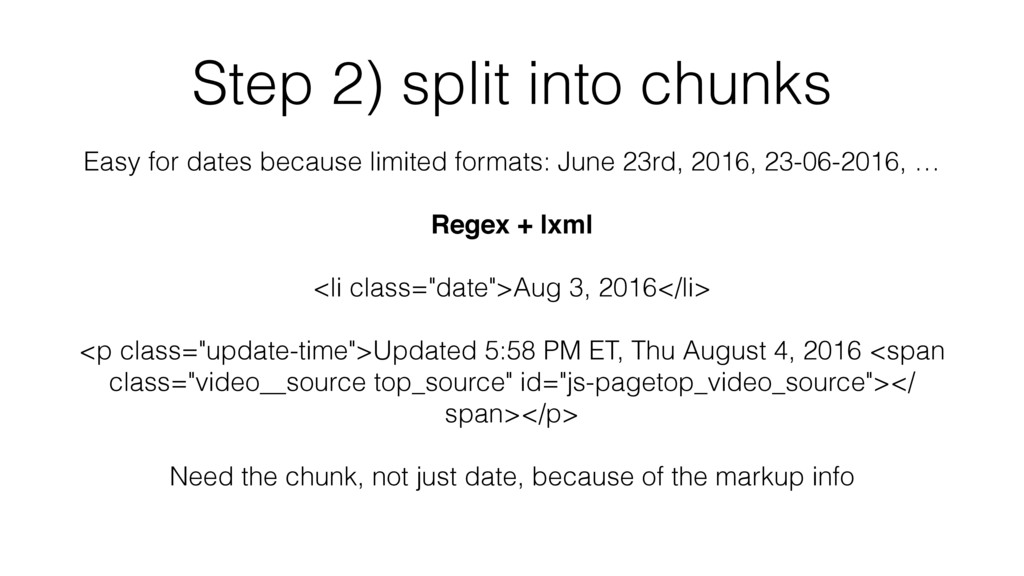
formats: June 23rd, 2016, 23-06-2016, … Regex + lxml <li class="date">Aug 3, 2016</li> <p class="update-time">Updated 5:58 PM ET, Thu August 4, 2016 <span class="video__source top_source" id="js-pagetop_video_source"></ span></p> Need the chunk, not just date, because of the markup info
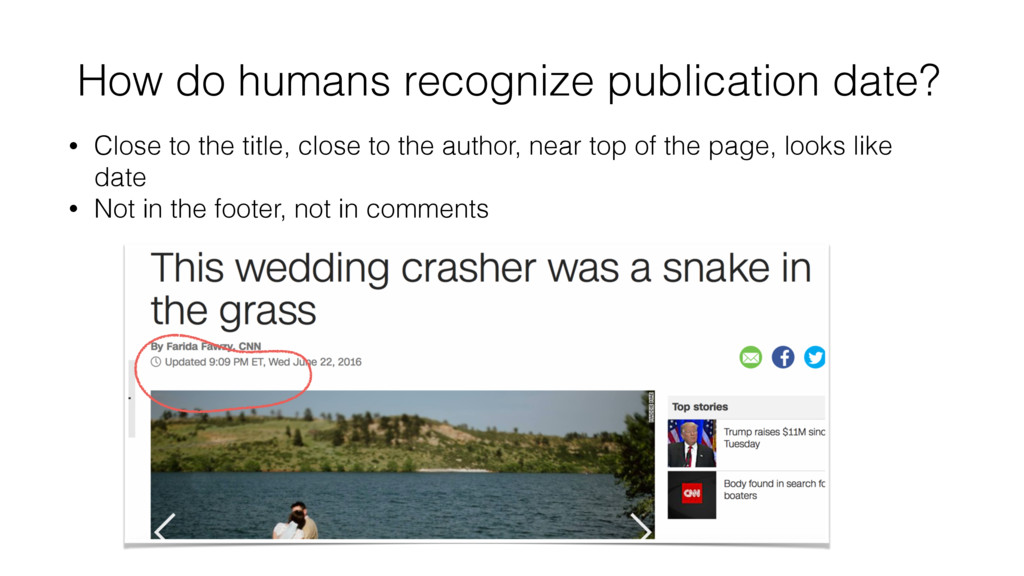
bc many features come from there Contains word “posted”, contains “modified”, contains “published” Header level Is a link Bold or not Position from top of page, position from title
does this contain publication date or not? Nltk + Naive Bayes, could use scikit-learn Probably better solutions but it was the easiest one to understand nltk tutorial understandable, scikit learn wtf
false positives: comments, footer, javascript (often library date) Post-filter: remove results that are obviously wrong: dates in the future, dates in the past but: historical articles Hacks: if there is a date in the url, almost always publication date http://www.degeneratestate.org/posts/2016/Apr/20/heavy-metal-and- natural-language-processing-part-1/
production Did not implement headless browser features, too slow for production parsing 300 000 pages per day vs. chugging along in the lab avoiding false positives > avoiding no answers
bounced ideas off CTO but also no experience with this, had problems my web dev friends didn’t have. Watched a lot of PyData talks to try to understand best practices, other people were doing, how to organize my code Wanted to list some as well
set of data to make sure data is in the correct format, if supervised learning Spreadsheet: give examples, often English not first language, clearer instructions better, don’t use slang, idioms
a page, get wrong answer, what is the problem? Do we get data at all when we download the page? Do we get chunks from that page? — chunk algo maybe wrong Does the correct chunk get classified as true? -- classifier maybe wrong Does it have multiple true chunks but picks the wrong one? -- chunk picking algo wrong Does it have chunks all the way through but empty result? post- filtering wrong
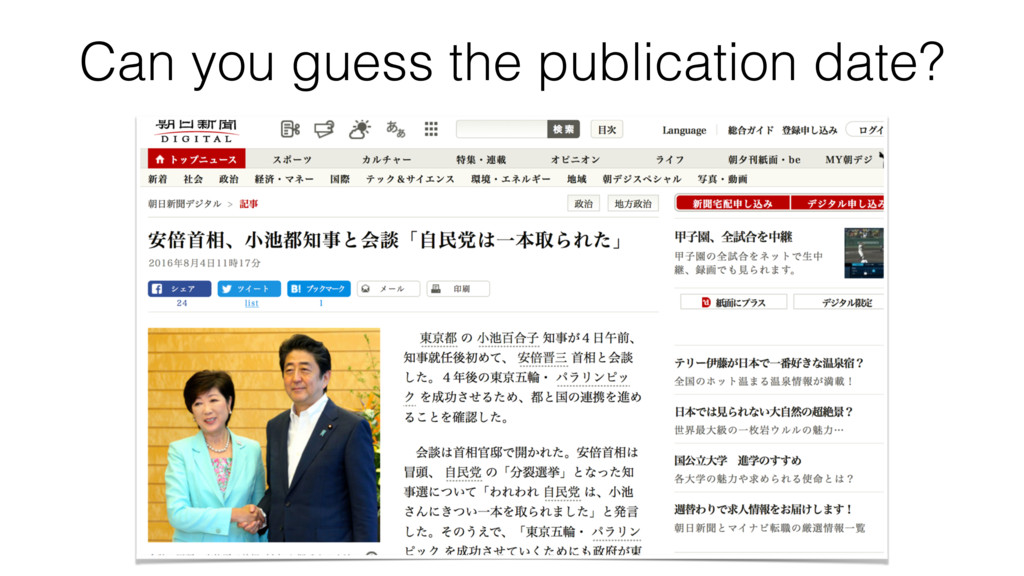
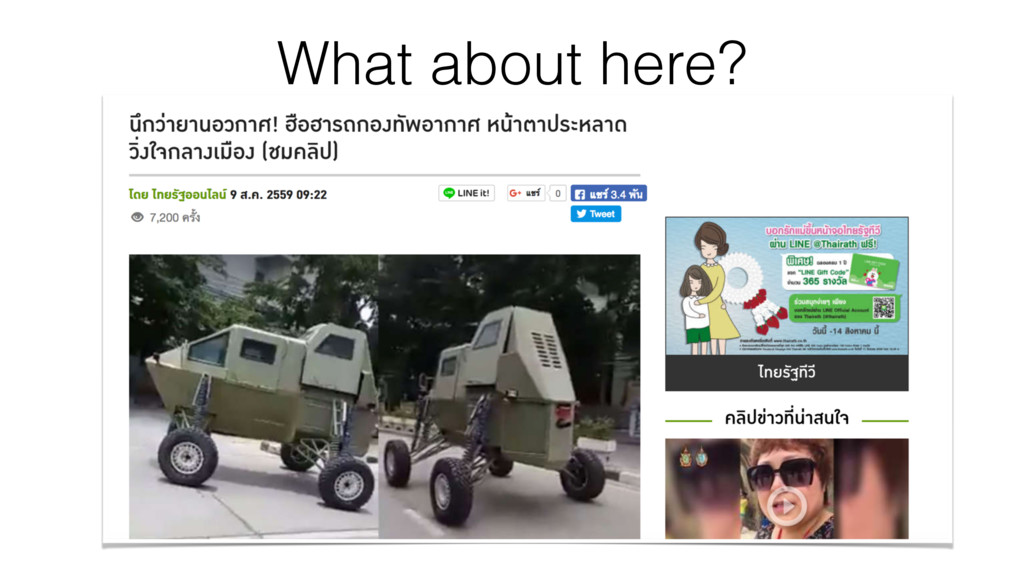
99 will have date in the top, 1 at the bottom If you write something that is correct for the 99 pages, probably get 1 page wrong But this is better than 1 correct, 99 wrong Search for what is right MOST of the time vs. algorithmically correct (1 wrong is a bug)
come talk to me in person after Talk to me later: I work on cool data problems, remotely. Julie Lavoie / [email protected] (ps. I send clients candy from Japan)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}