Conquering Massive Traffic Spikes in Ruby Applications with Pitchfork
Discover how we tackled extreme traffic spikes on our Rails platform using Pitchfork. Learn to efficiently warm up Rails applications and significantly improve latency during massive sales events.
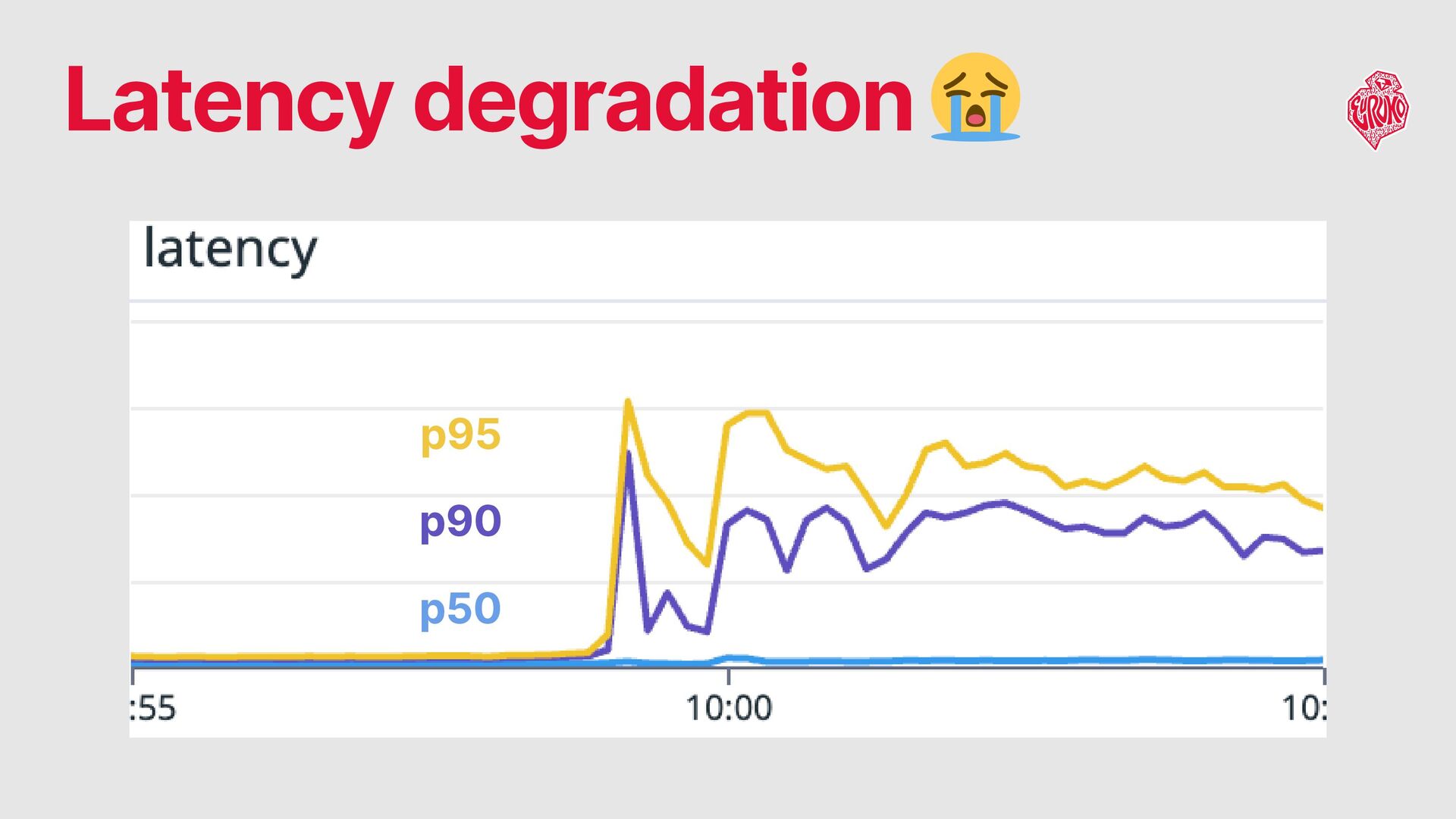
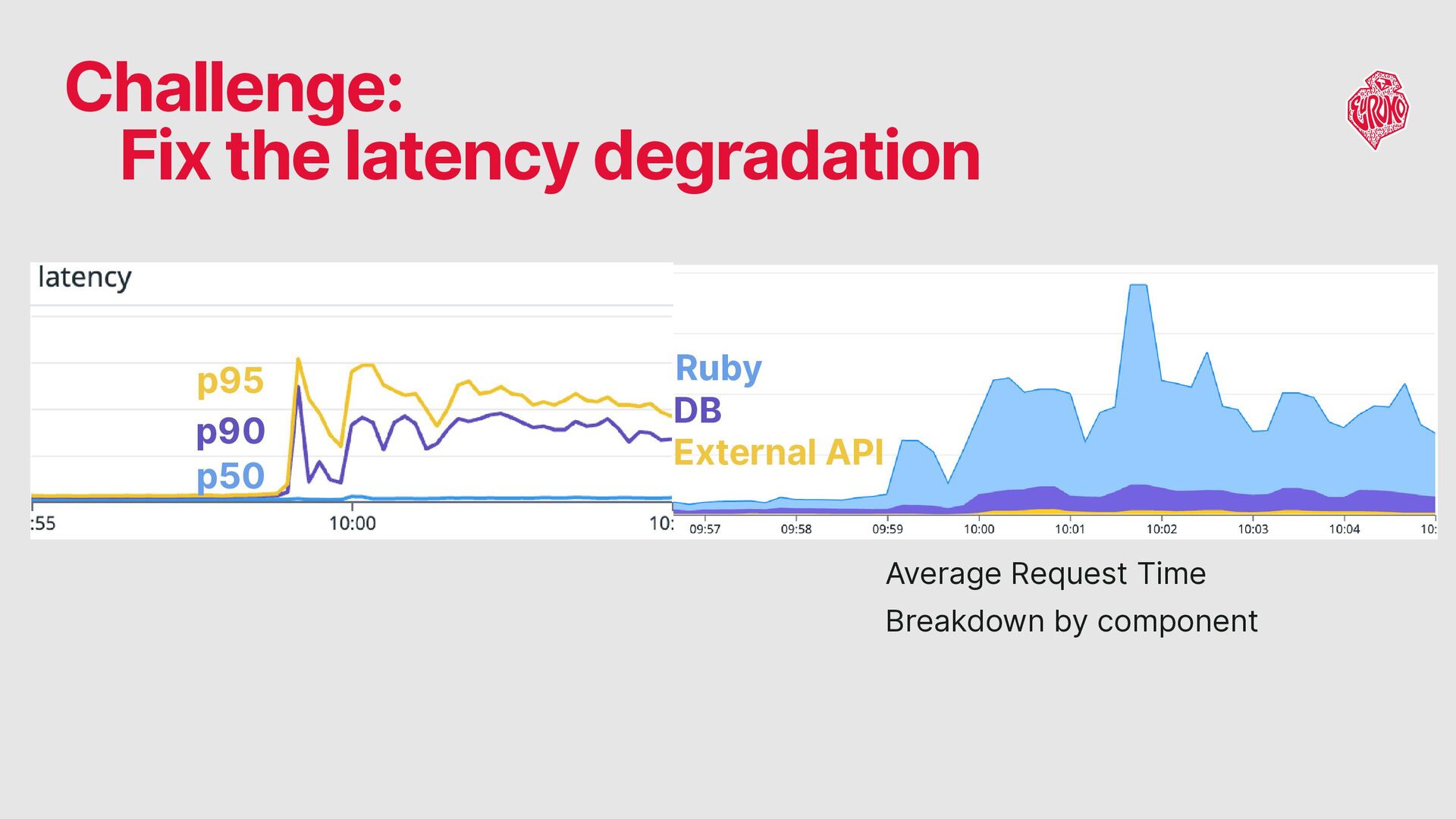
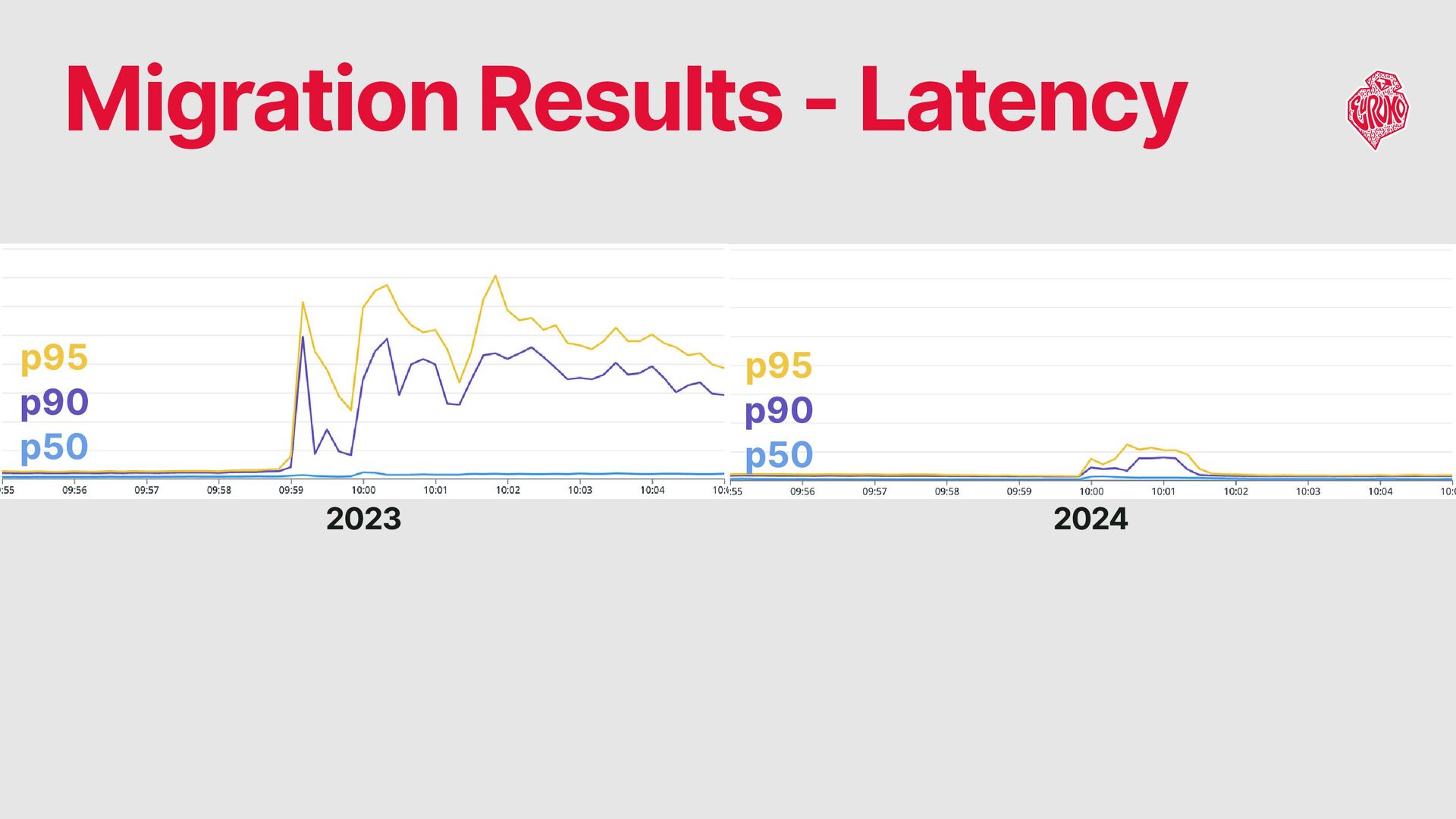
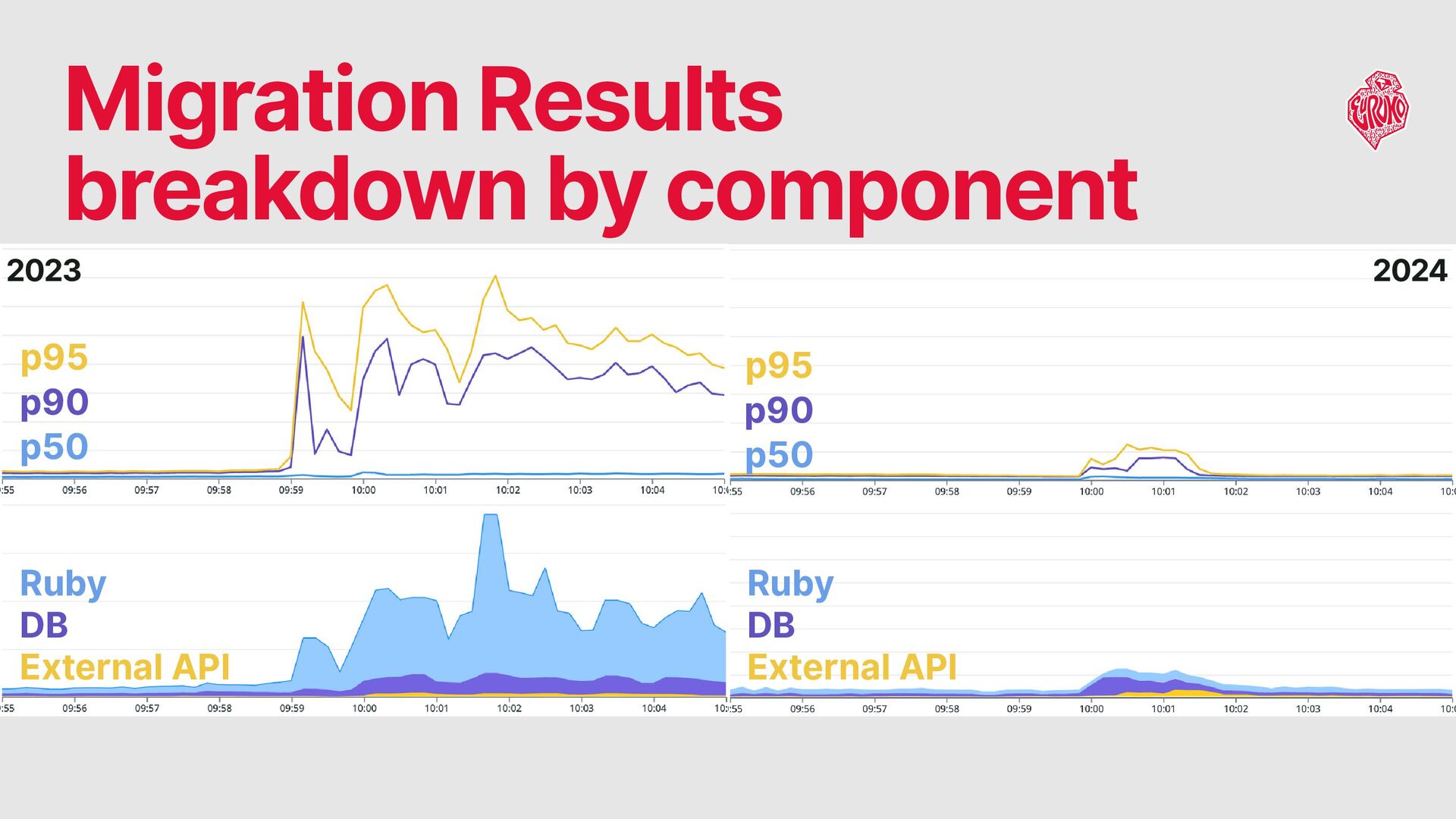
the latency degradation observed at p90 and above Problems Note: Application optimization and cache-based load reduction are out of scope for this talk.
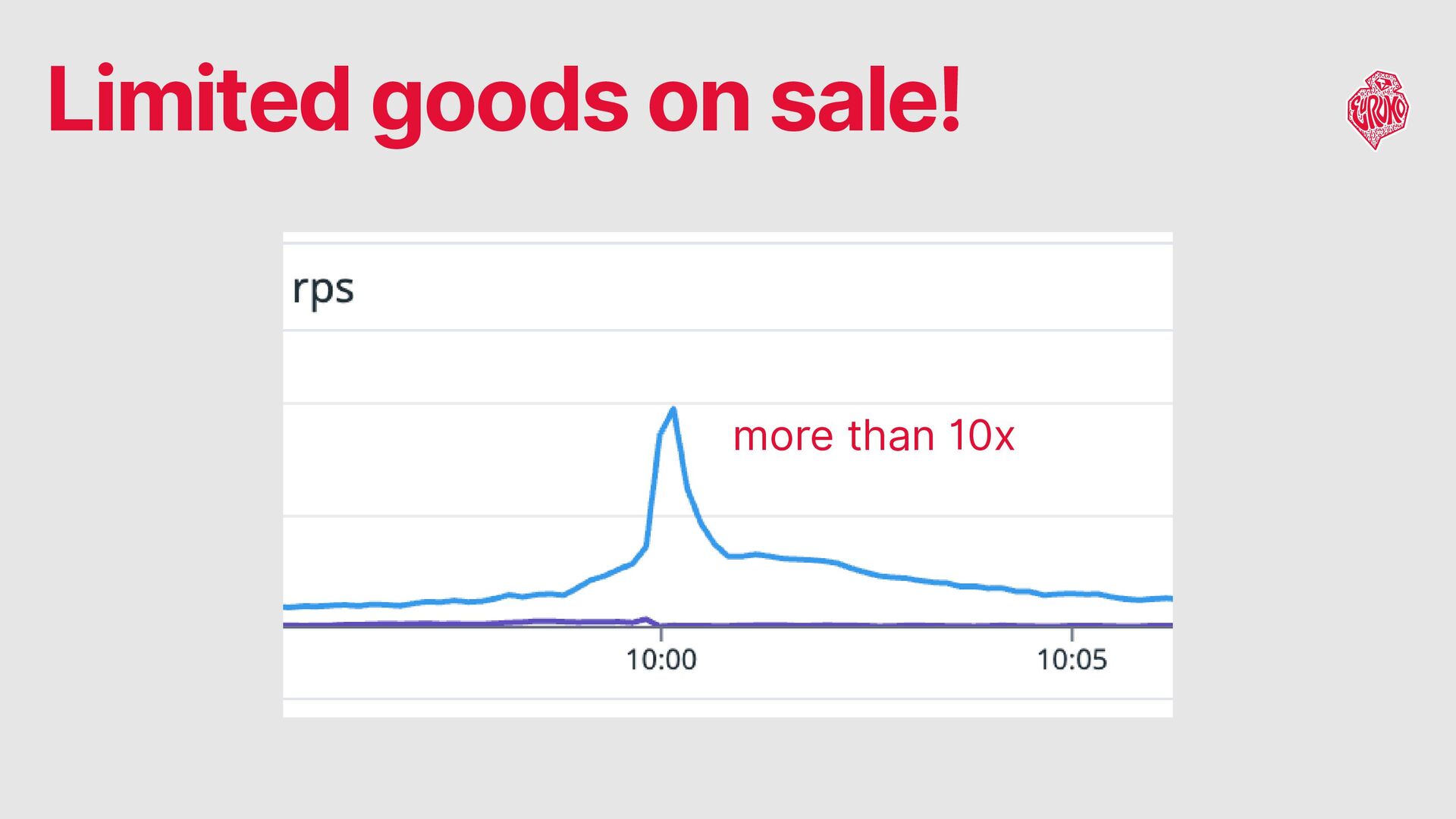
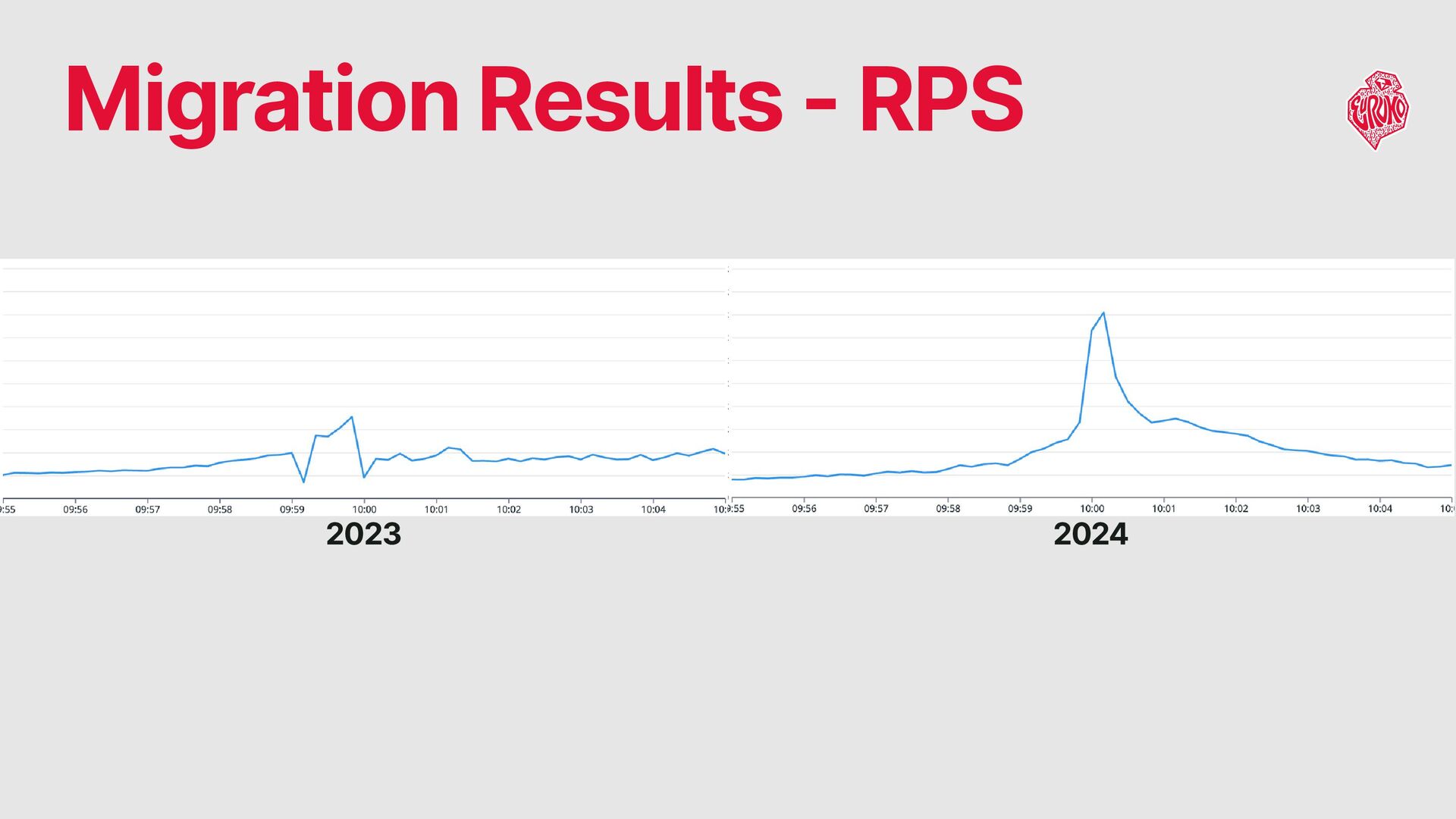
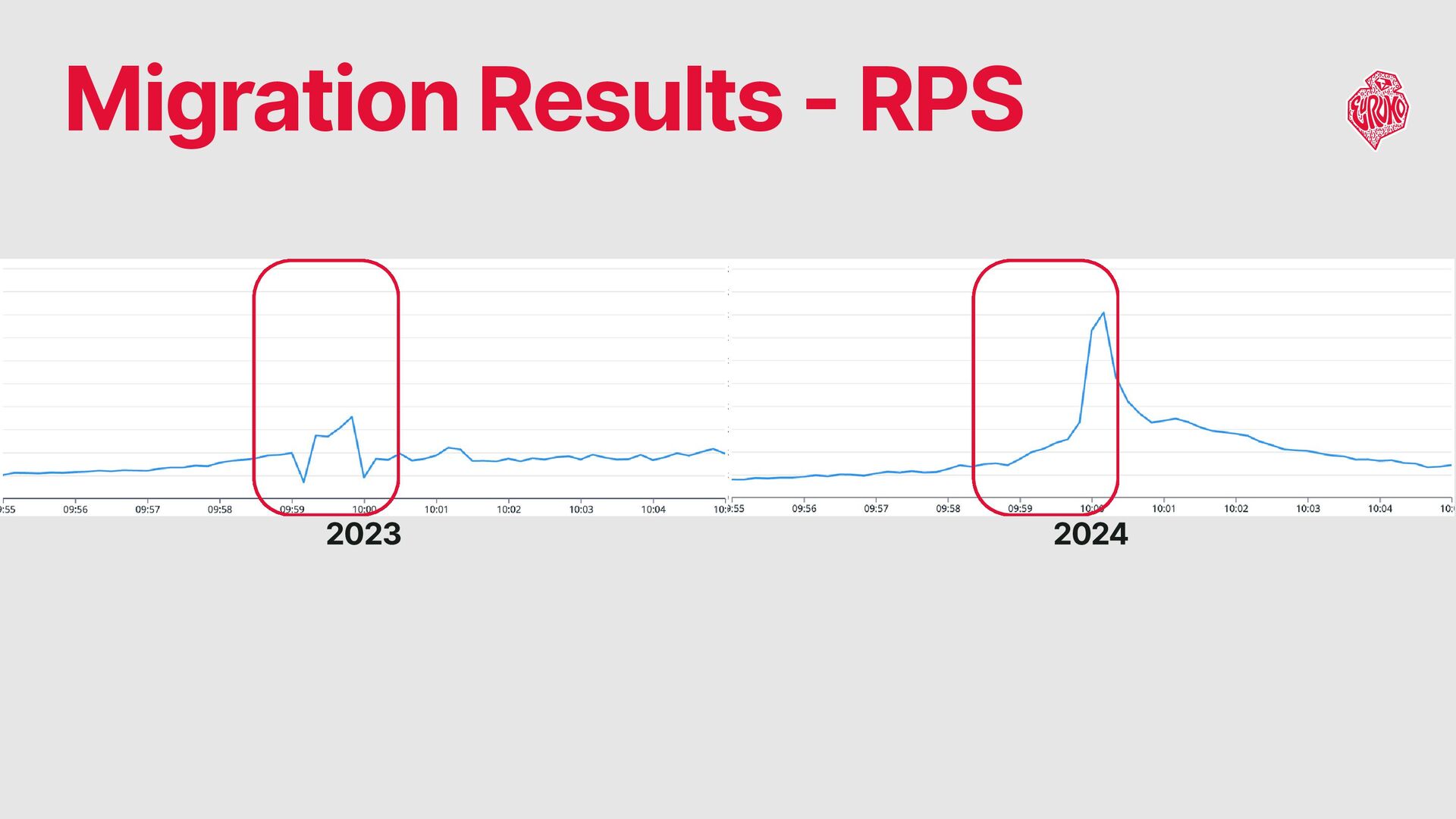
When traffic exceeds estimates → Some queuing is inevitable Peak duration: typically under 1 minute, full resolution: within 5 minutes workers requested by ASG 2-5 min later, so it won’t help. Challenge: Provisioning Sufficient Web Server Workers
as buffer Use Fargate Spot for cost optimization Large-scale spikes The rare extreme spikes are usually predictable from their scale, so we manually scale out right before launch Challenge: Provisioning Sufficient Web Server Workers
times after boot up, making first requests be slow: TCP connection establishment In-memory cache JIT compilation (if YJIT is enabled) Define methods by method_missing Action View template compilation … The Cold Worker Problem
100ms response time 8 workers 2 concurrent connections (simulating low load) 10 second test run Compare the number of processed requests per worker Why Only Some Requests?
n ... Notify Watch Unicorn is a prefork web server At startup, forks configured number of worker processes All workers share a single TCP socket Unicorn uses epoll (or kqueue) What's the notification order?
like LIFO (Last in First out) -> with just 2 concurrent requests, workers 0 and 1 keep jumping to the front Ref: https://blog.cloudflare.com/the-sad-state-of-linux-socket-balancing/ Why the Imbalance? epoll Notify Worker 2 Worker 0 ... Goes back to the front of the queue
request? If you’re using unicorn already, then might be ok except some gems: grpc, ruby-vips ... See more: https://github.com/Shopify/pitchfork/blob/master/docs/FORK_SAFETY.md Caveat 1: Fork safety
refork. The limit is per-worker, for instance with refork_after “[50]” a refork is triggered once at least one worker processed 50 requests. Each element is a limit for the next generation. “[50, 100, 1000]” a new generation is triggered when a worker has processed 50 requests, then the second generation when a worker from the new generation processed an additional 100 requests and finally after every 1000 requests. Ref: https://github.com/Shopify/pitchfork/blob/master/docs/CONFIGURATION.md#refork_after Caveat 2: refork_after
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![COMMAND \_ pitchfork master \_ (gen:0) mold \_ (gen:0) worker[0]](https://files.speakerdeck.com/presentations/7f05116b06b942998fc644b1b6239d63/slide_25.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}