The RELEASE project at Glasgow University aims to improve the scalability of Erlang onto commodity architectures with 100,000 cores.
Such architectures require scalable and available persistent storage on up to 100 hosts. The talk describes the provision of scalable persistent storage options for Erlang.
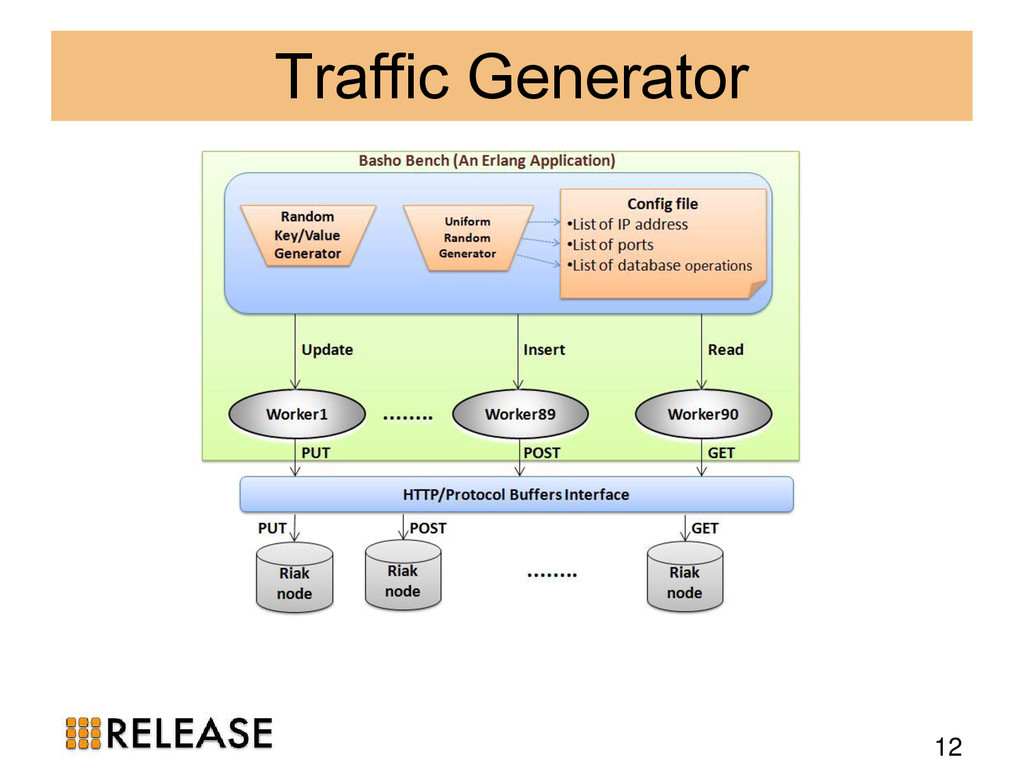
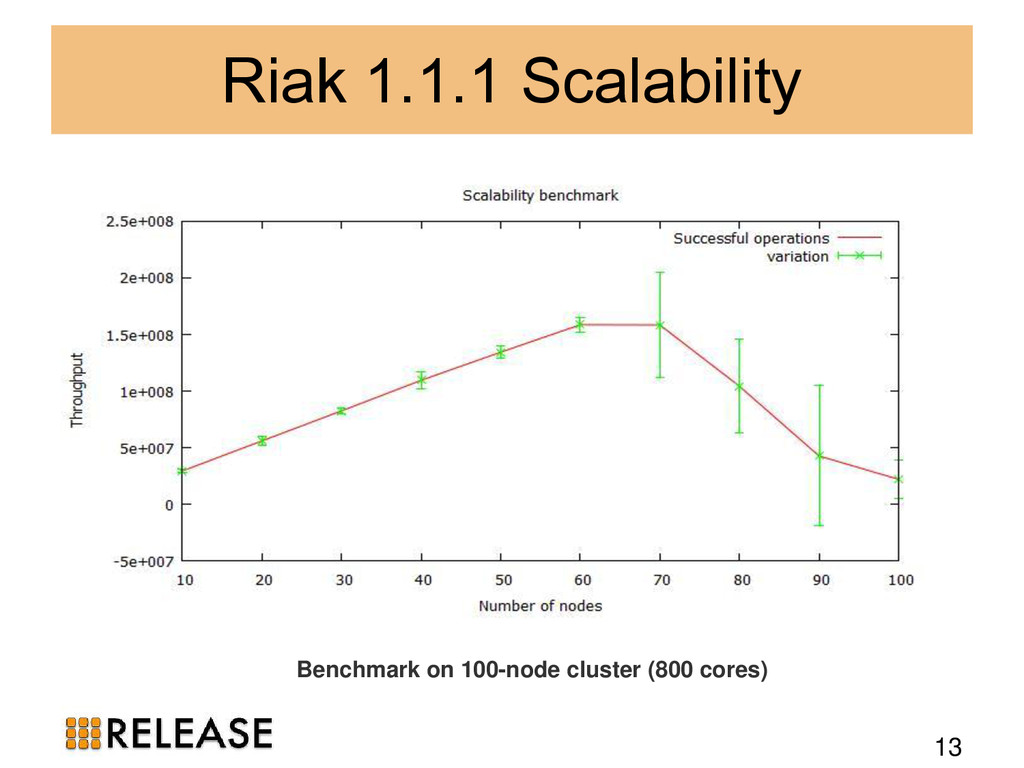
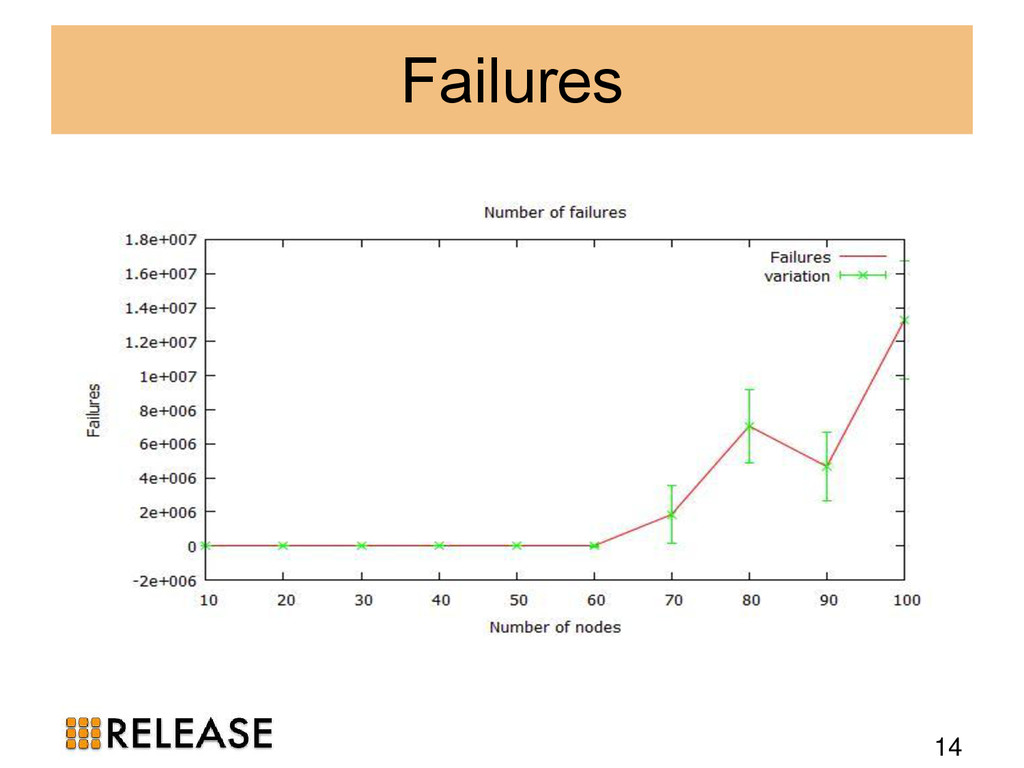
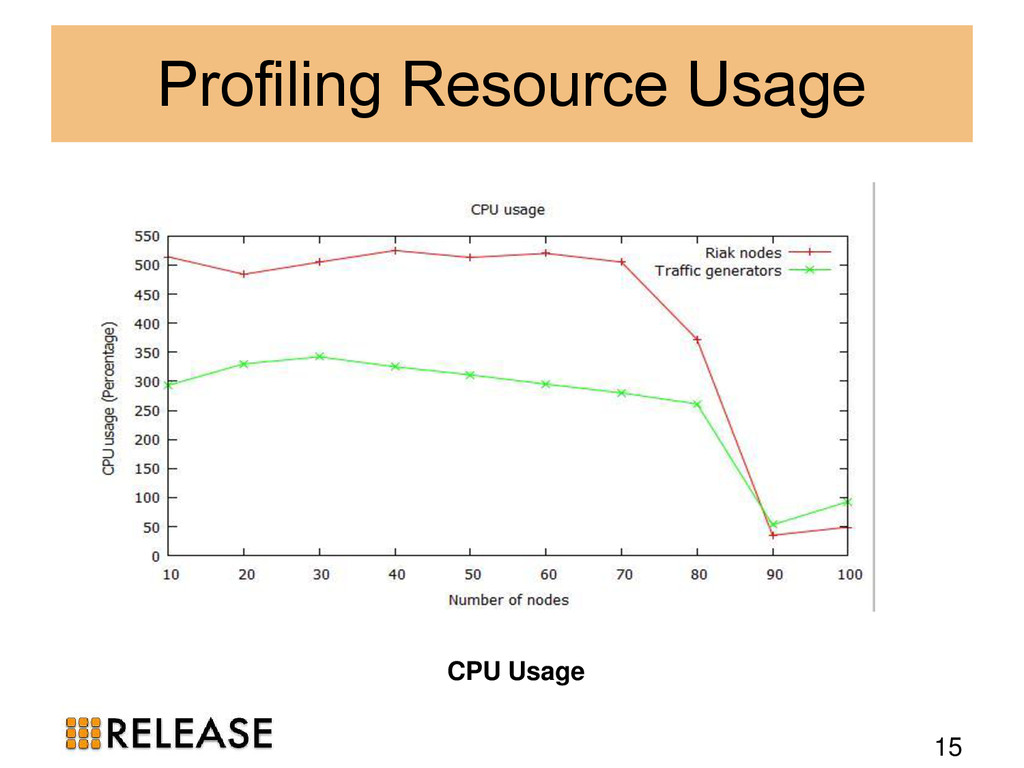
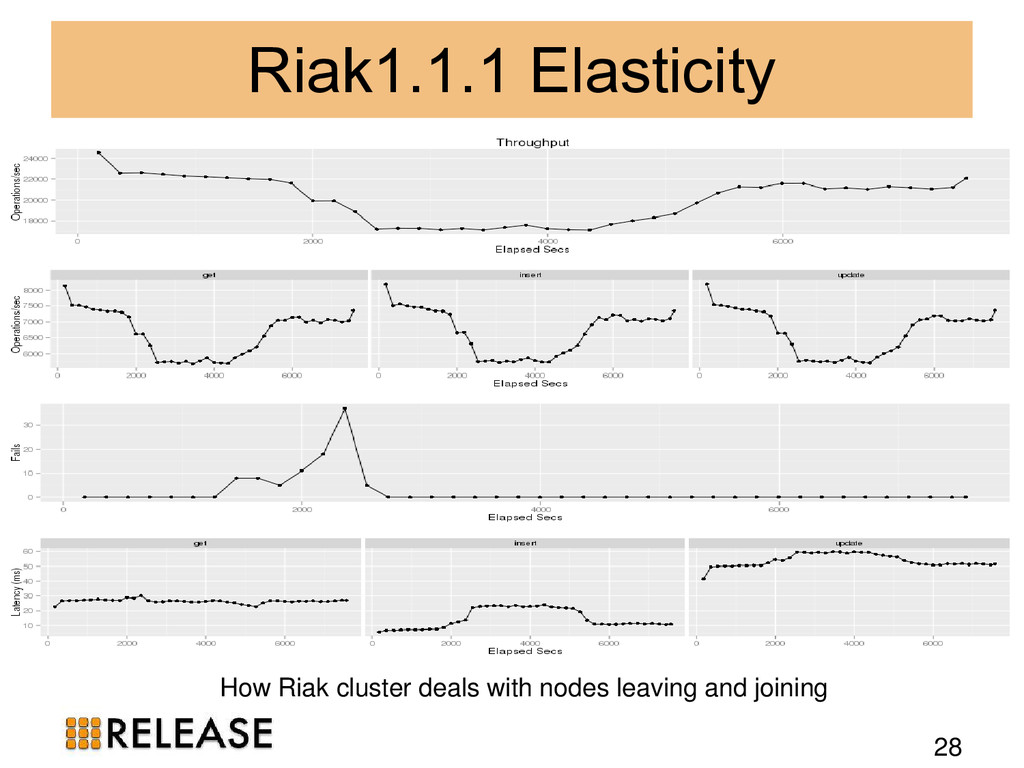
We outline the theory and apply it to popular Erlang distributed database management systems (DBMS): Mnesia, CouchDB, Riak and Cassandra. We identify Dynamo-style NoSQL DBMS as suitable scalable persistent storage technologies. To evidence the scalability we benchmark Riak in practice, measuring the scalability and elasticity of Riak on 100-node cluster with 800 cores.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
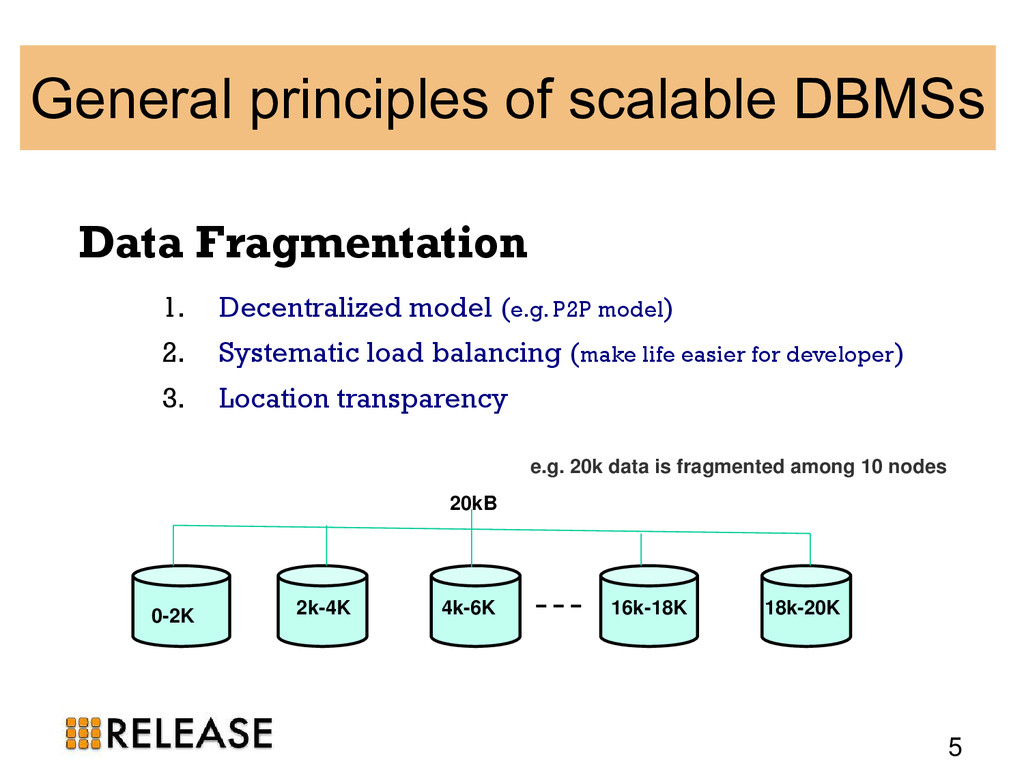{kind=link}
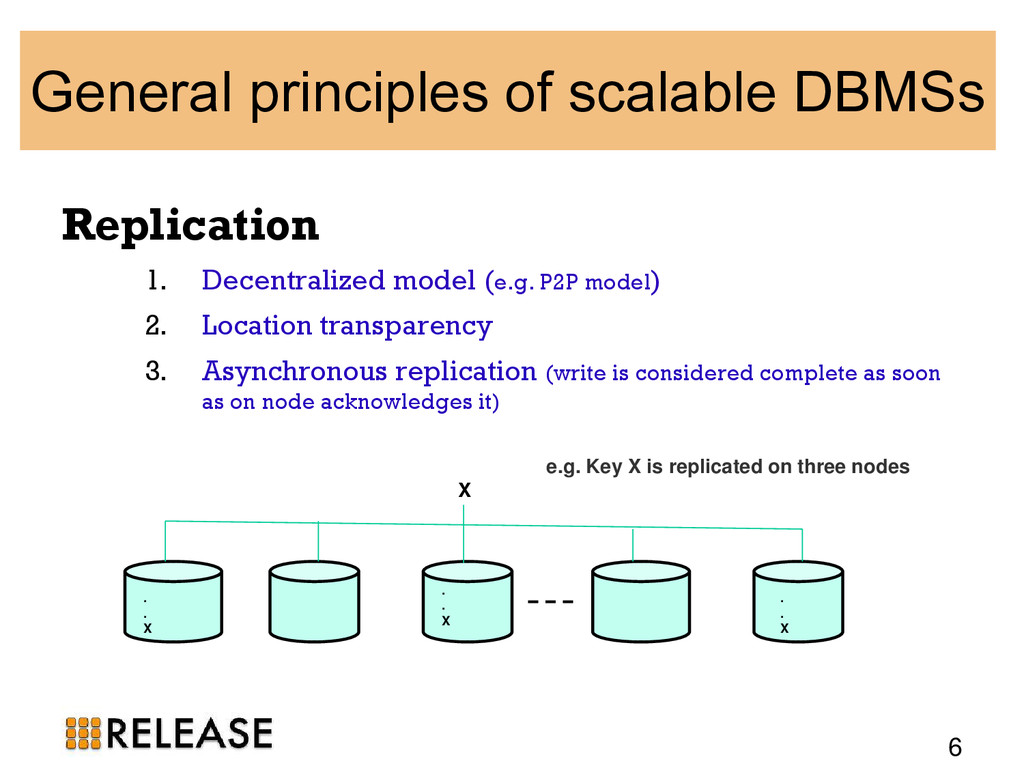{kind=link}
{kind=link}
{kind=link}
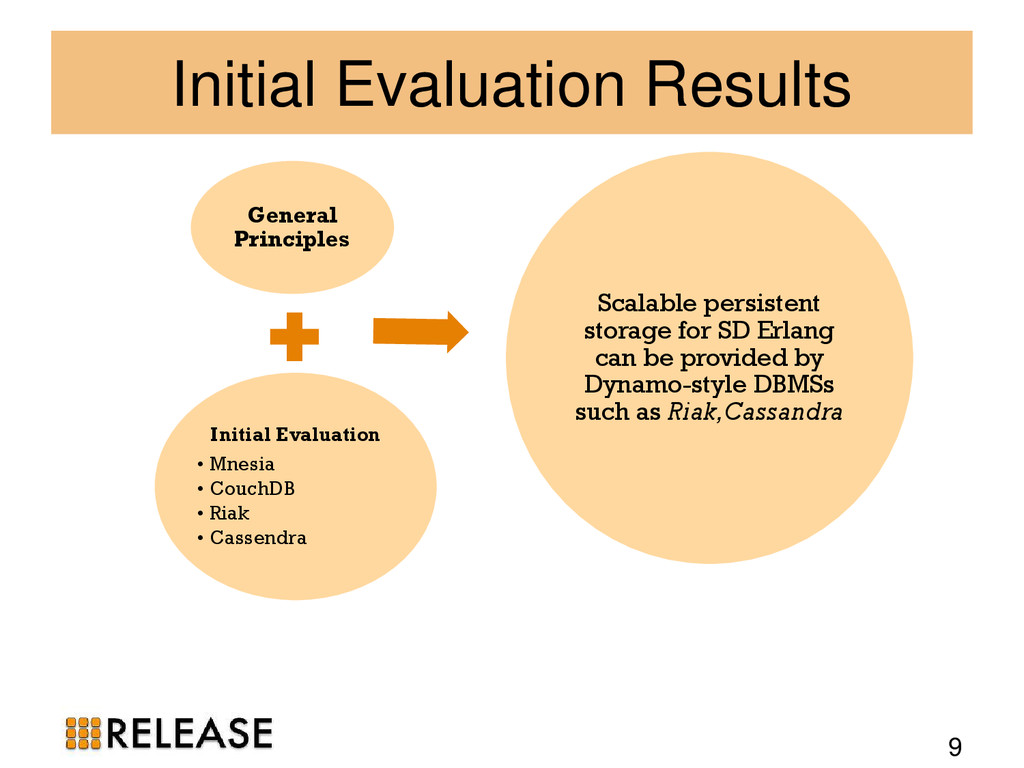{kind=link}
{kind=link}
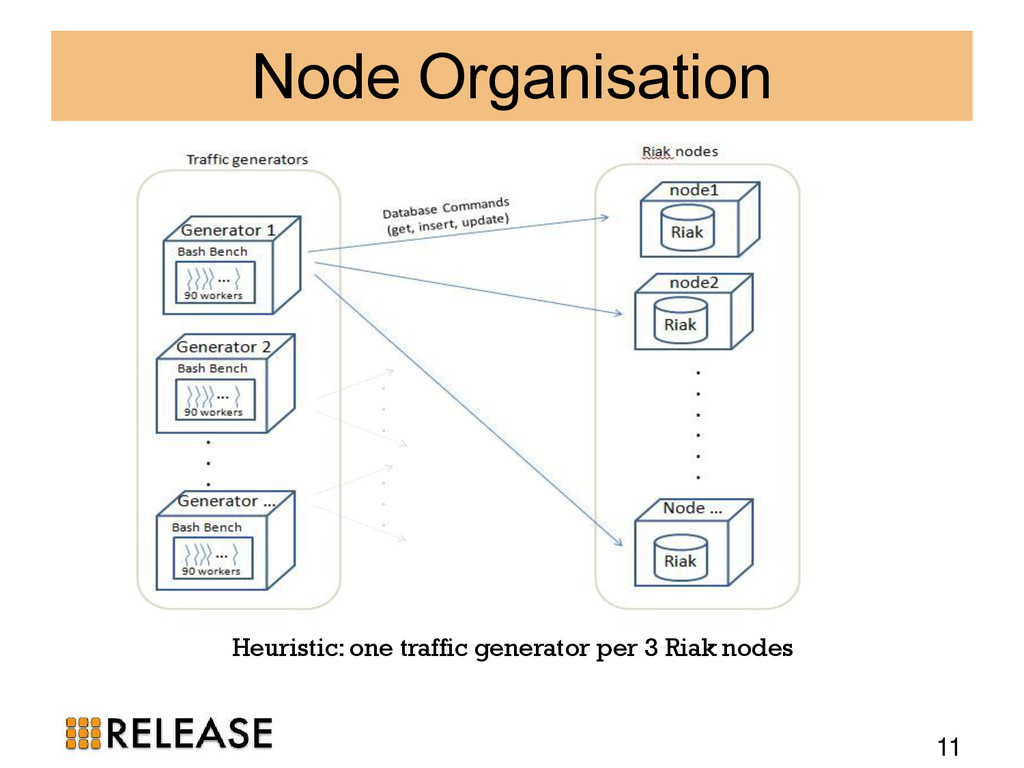{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
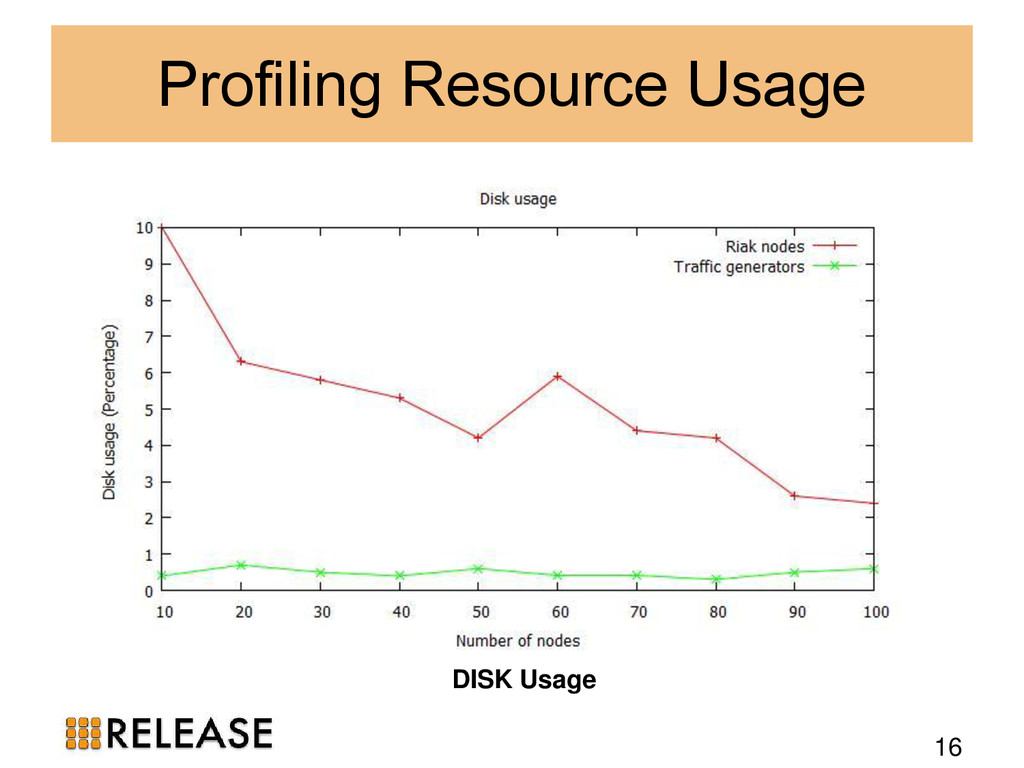{kind=link}
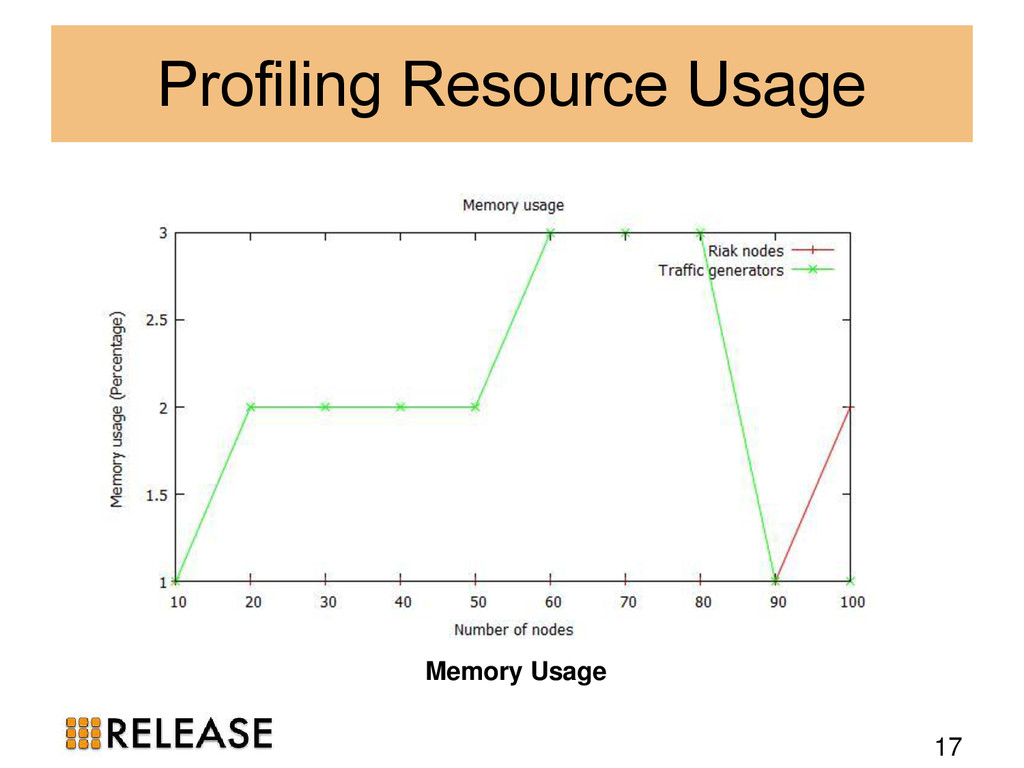{kind=link}
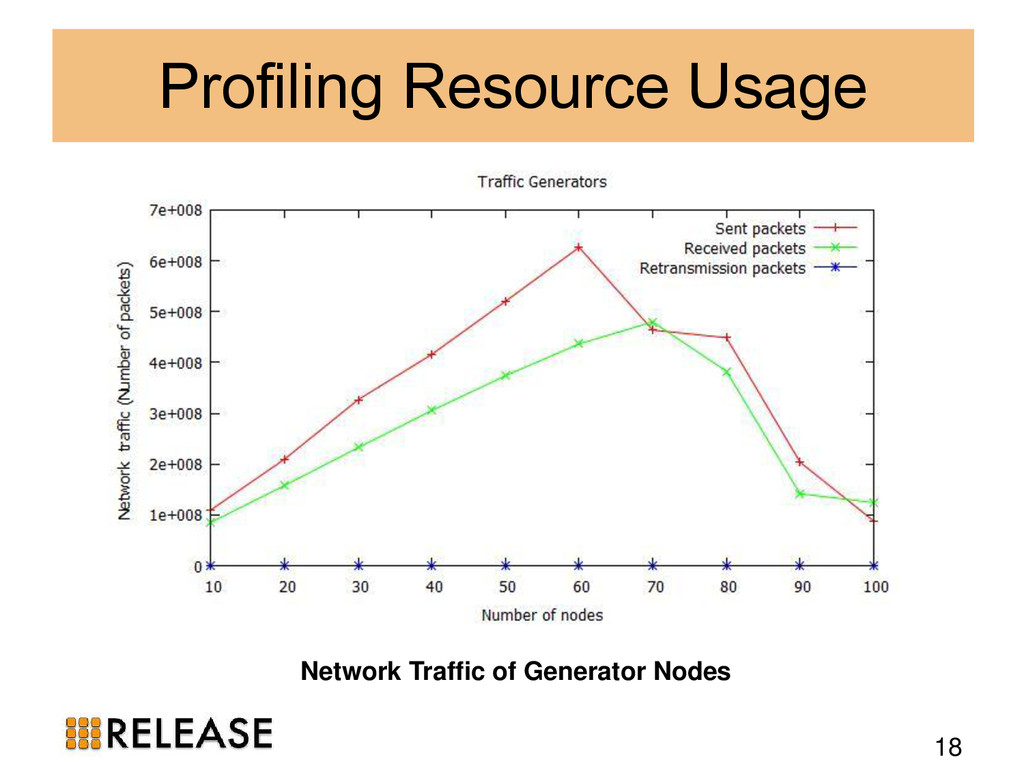{kind=link}
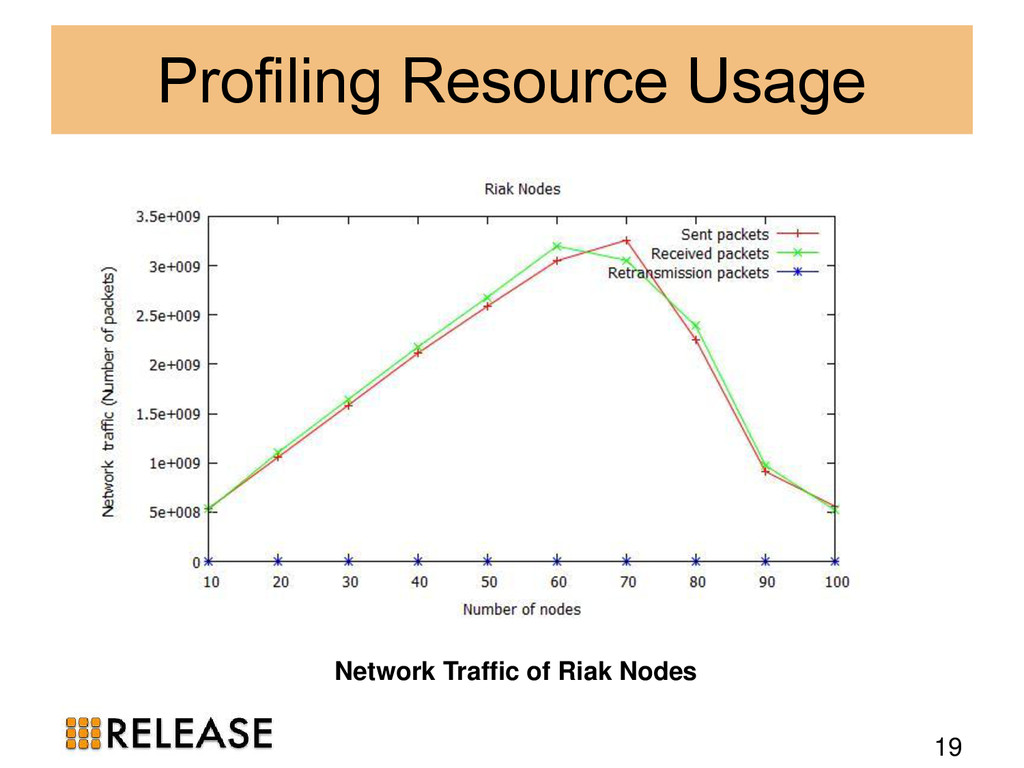{kind=link}
{kind=link}
{kind=link}
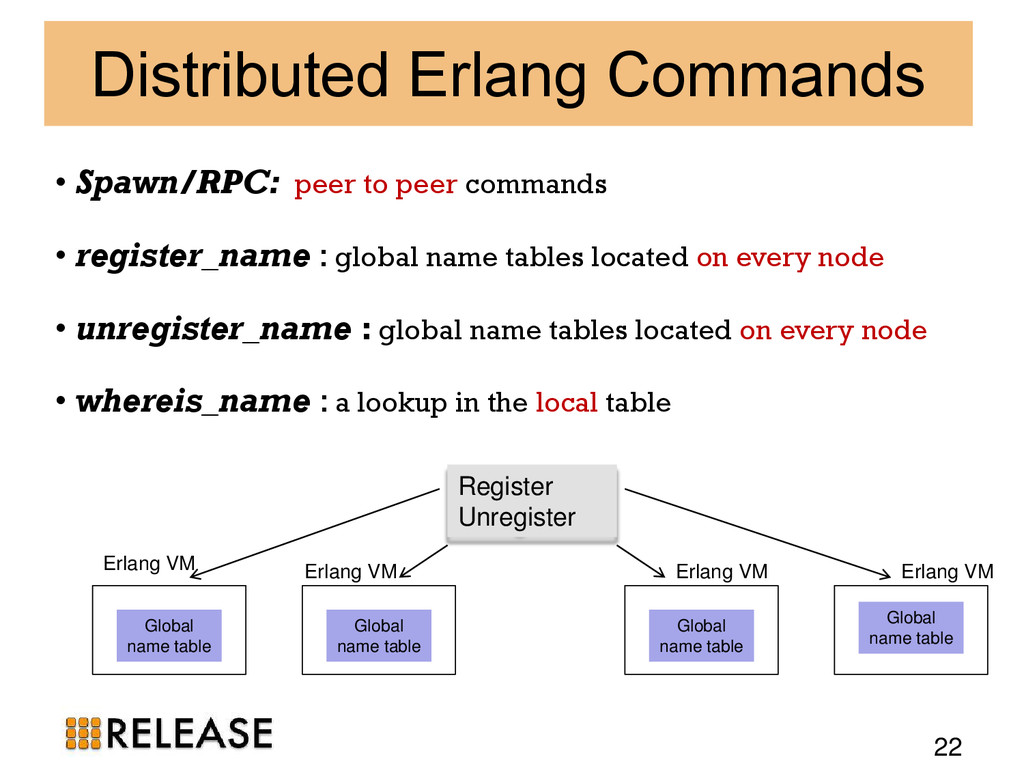{kind=link}
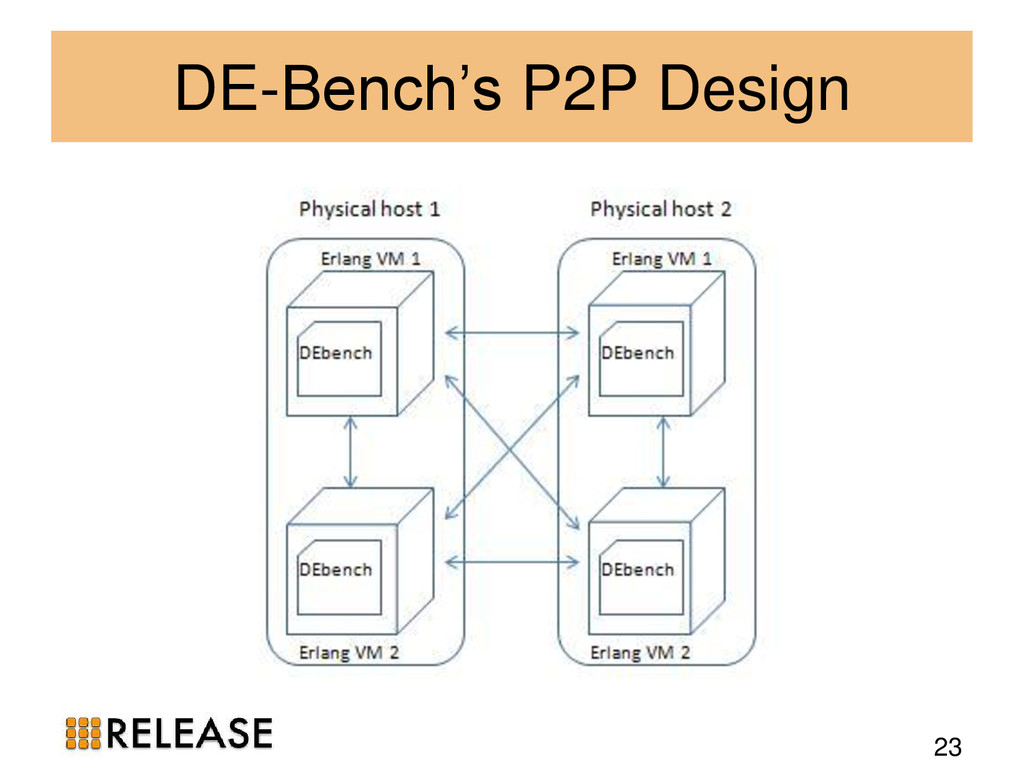{kind=link}
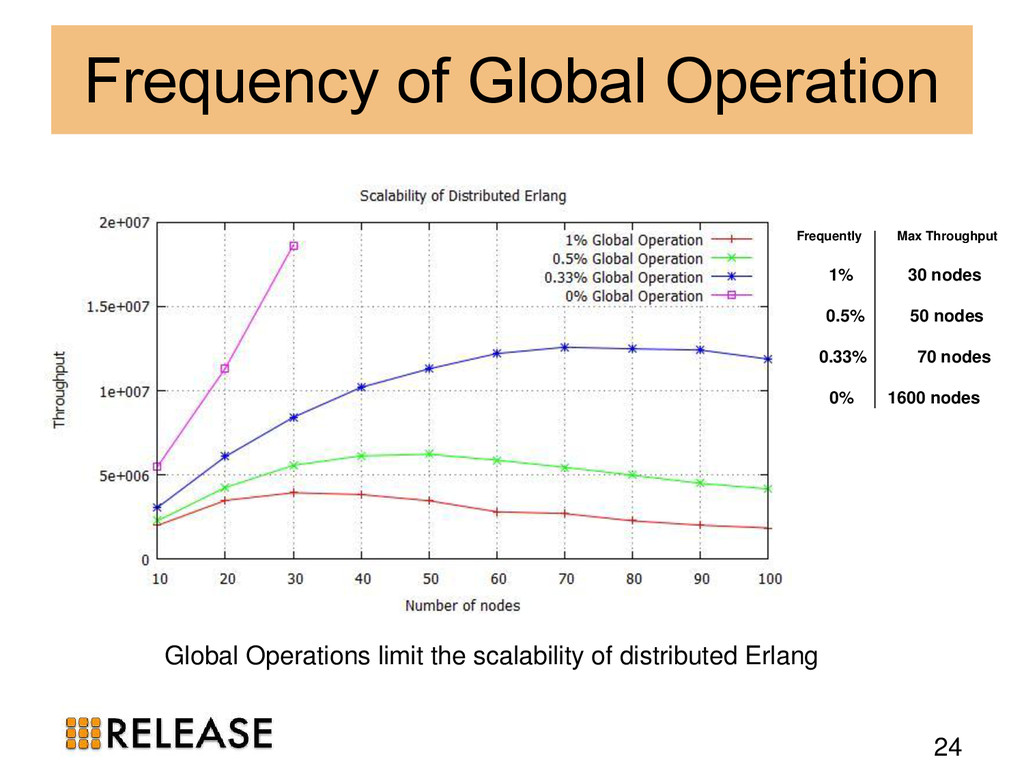{kind=link}
{kind=link}
{kind=link}
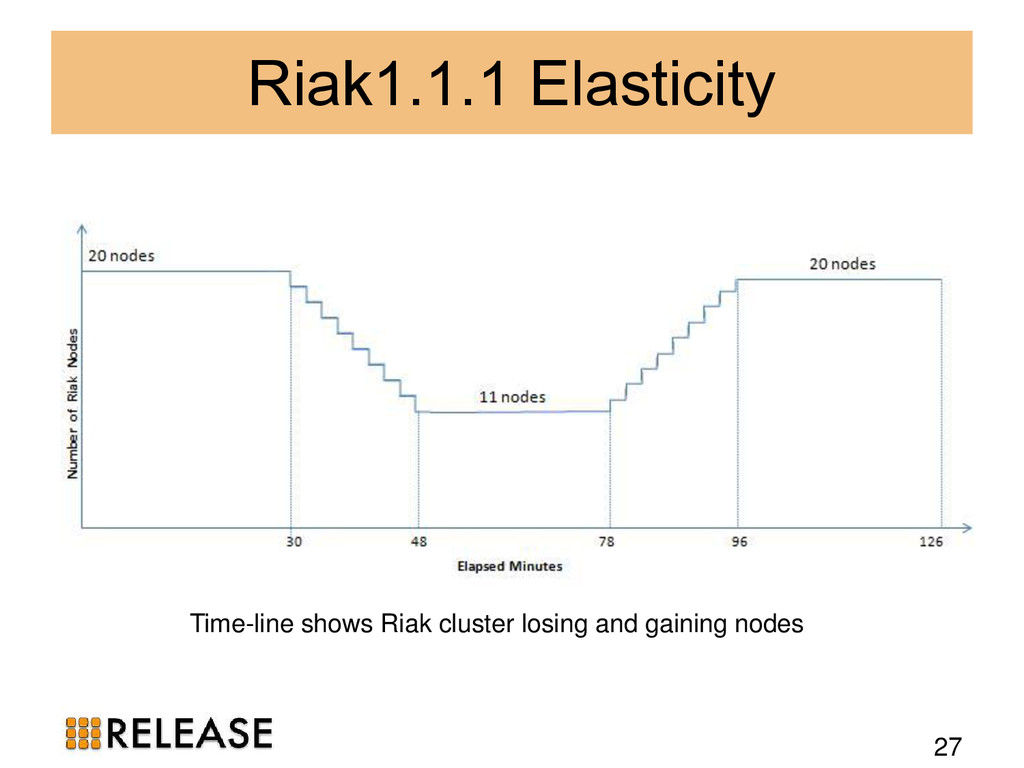{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}