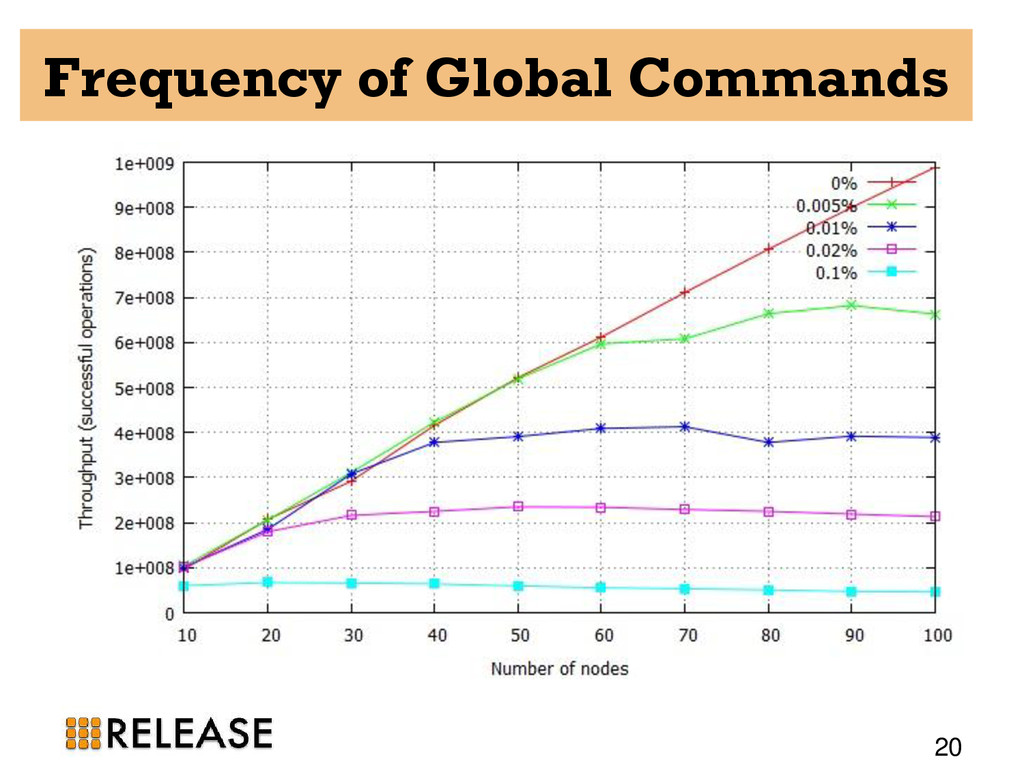
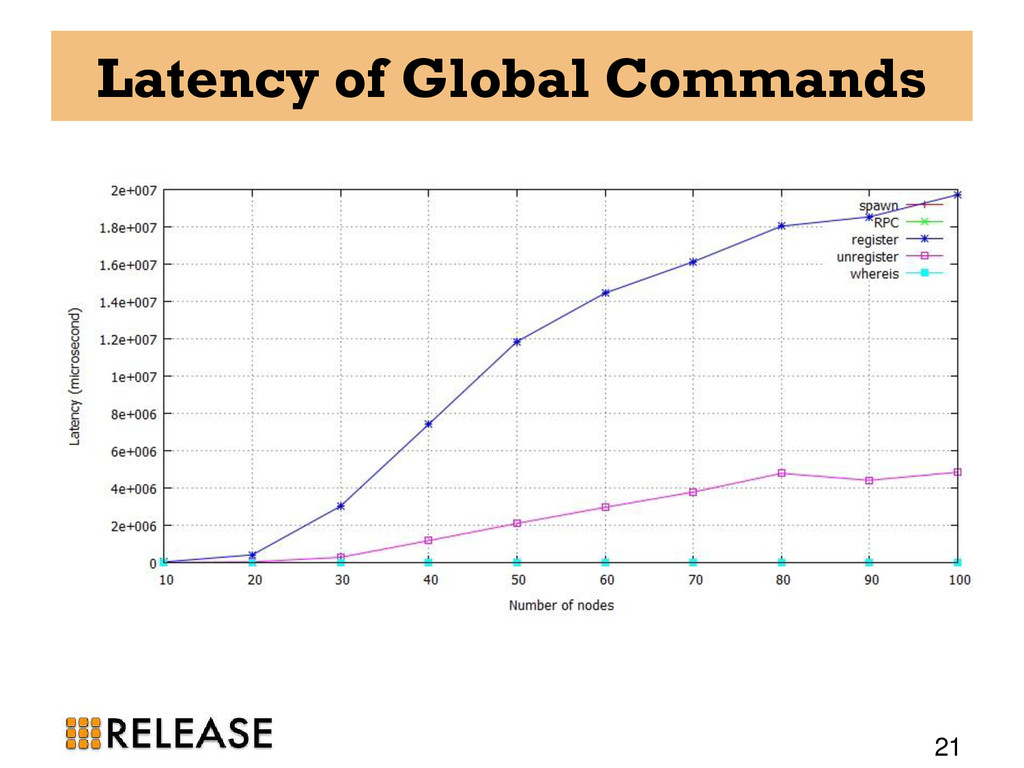
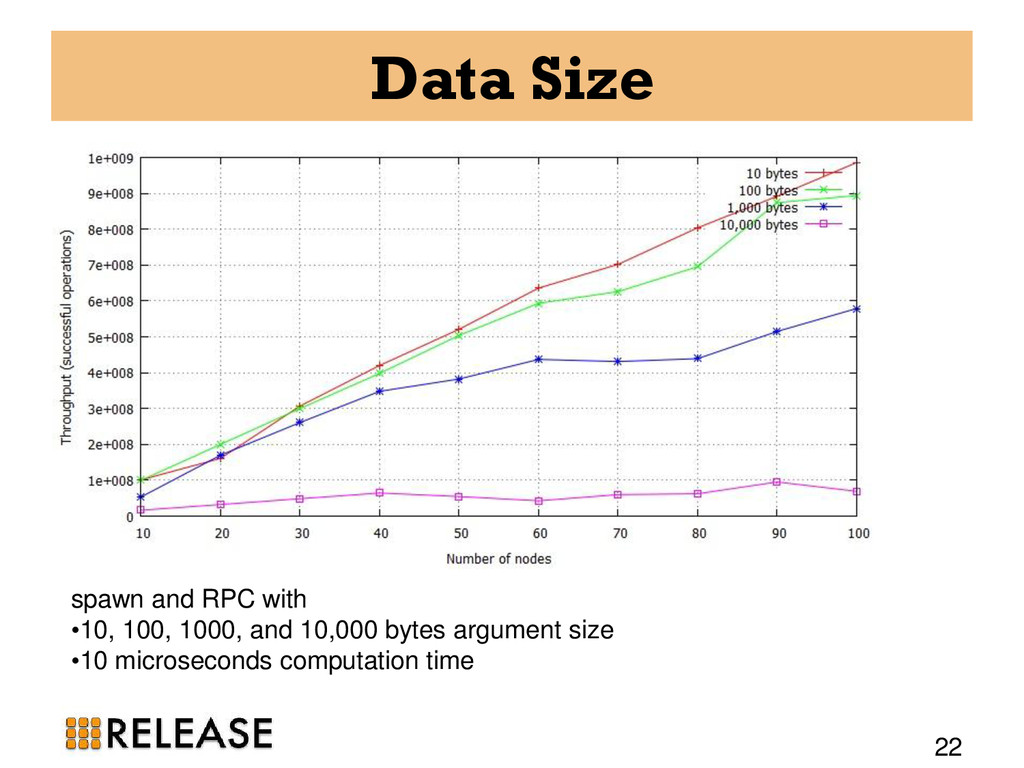
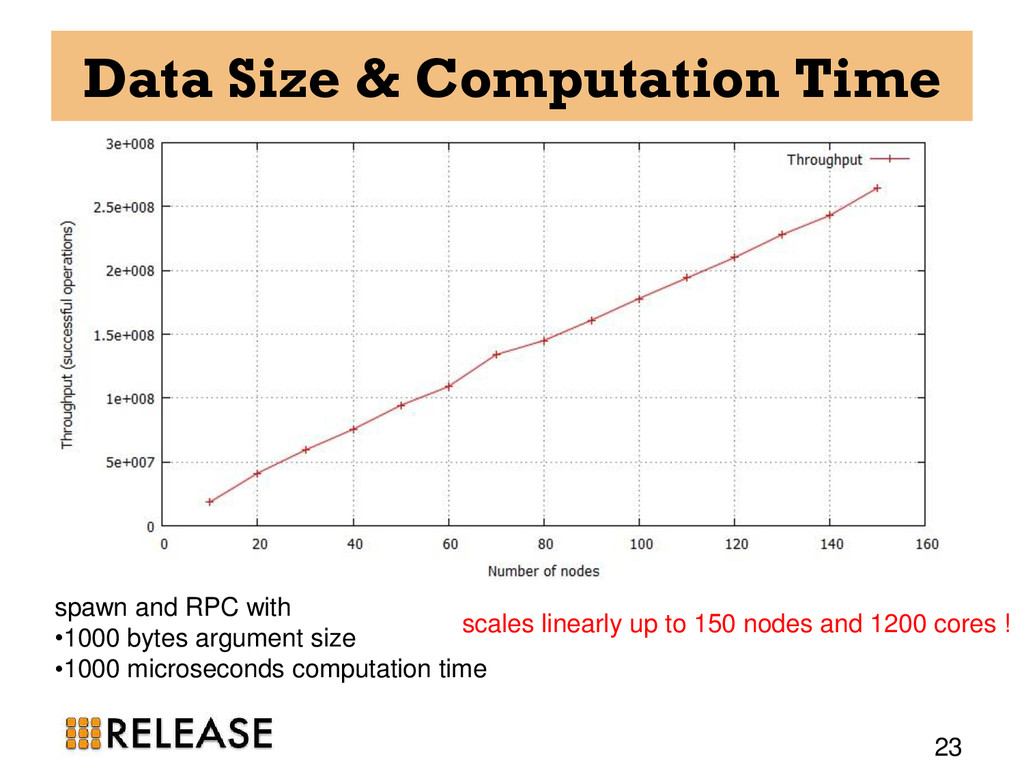
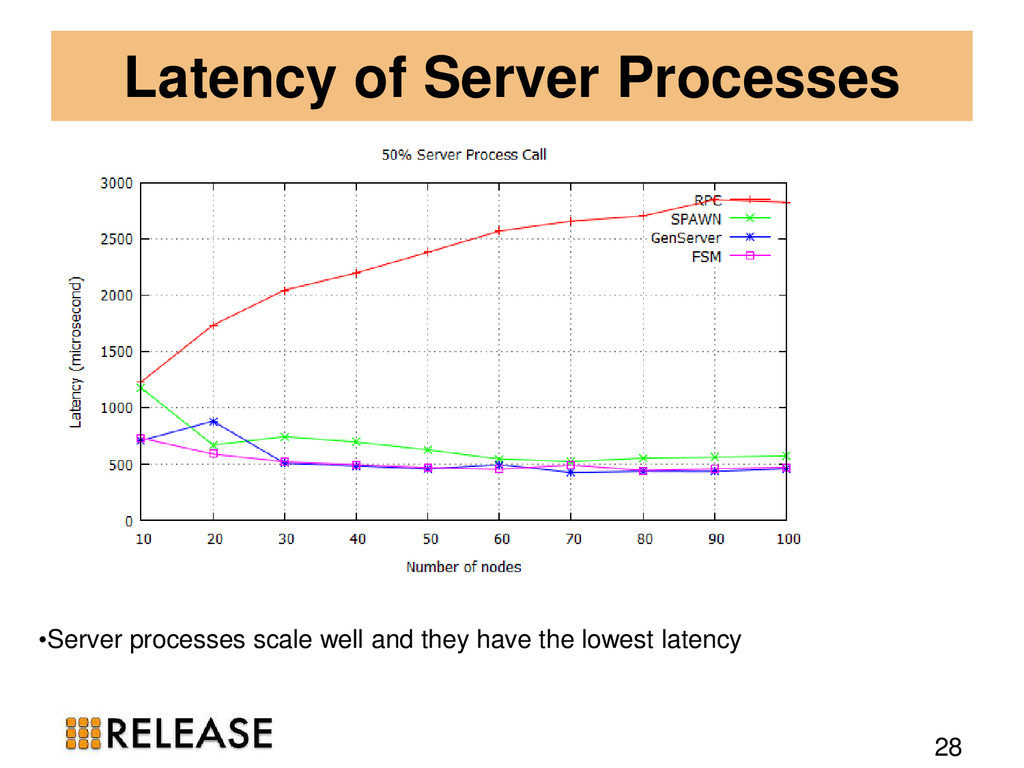
20, 30, 40, 50, 60, 70, 80, 90, and 100-node clusters • All the experiments run for 5 minutes. • one Erlang VM on each host and as always one DE-Bench instance on each VM. • CSV files from all participating nodes are aggregated to find out the total throughput and failures.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
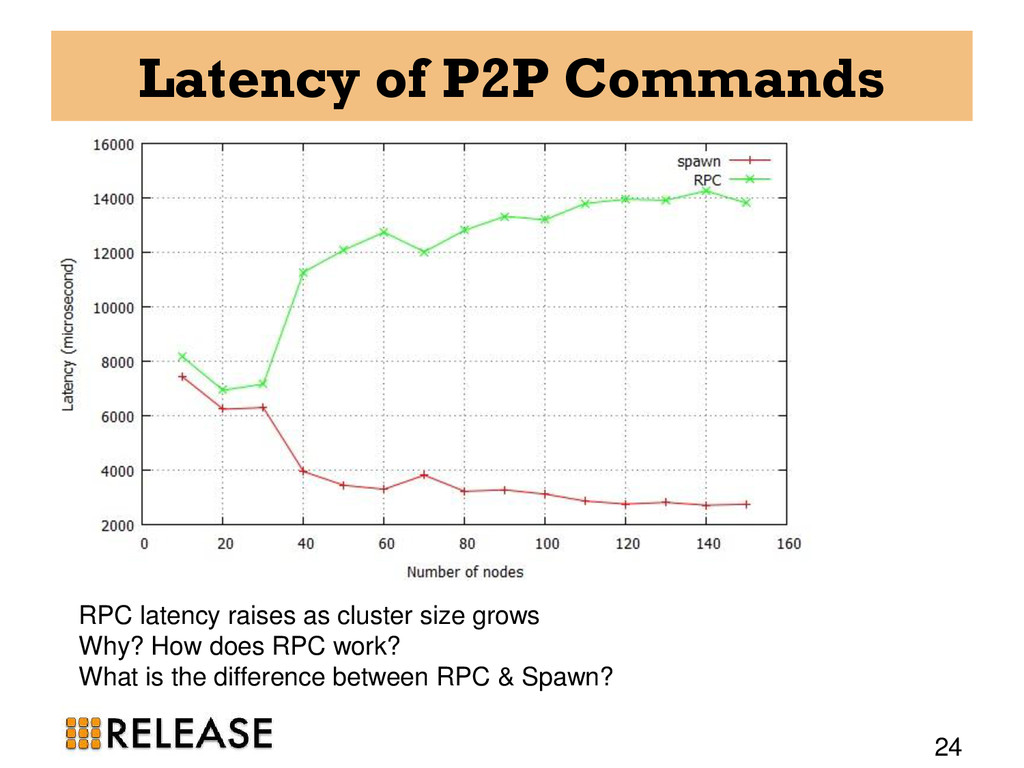{kind=link}
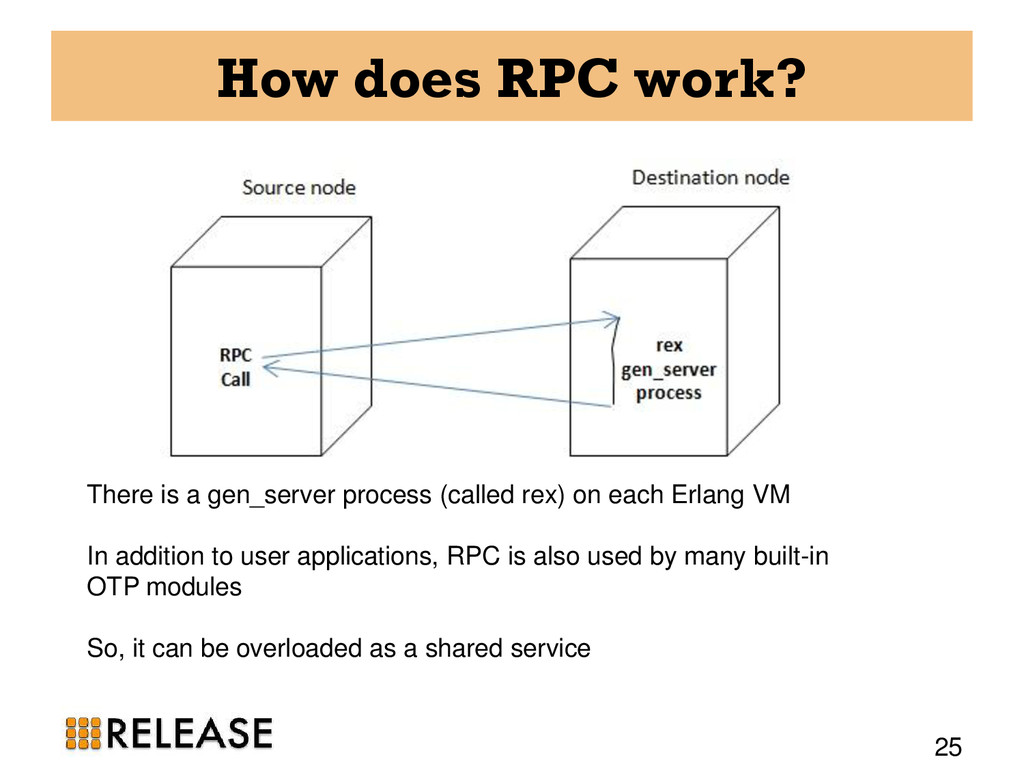{kind=link}
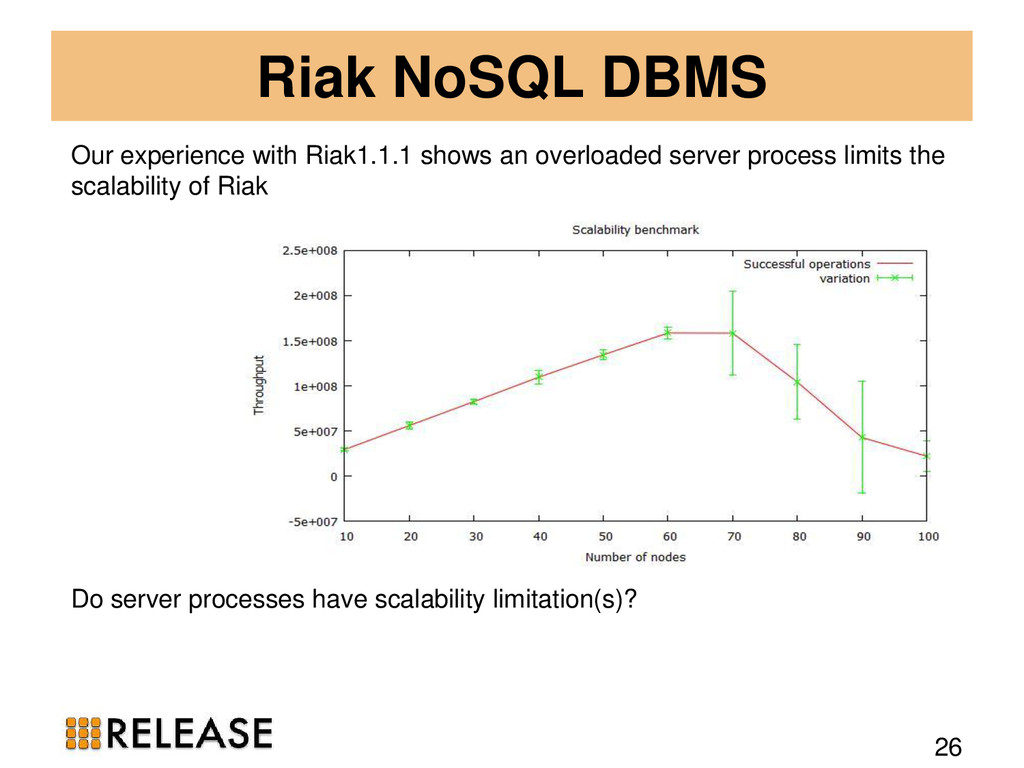{kind=link}
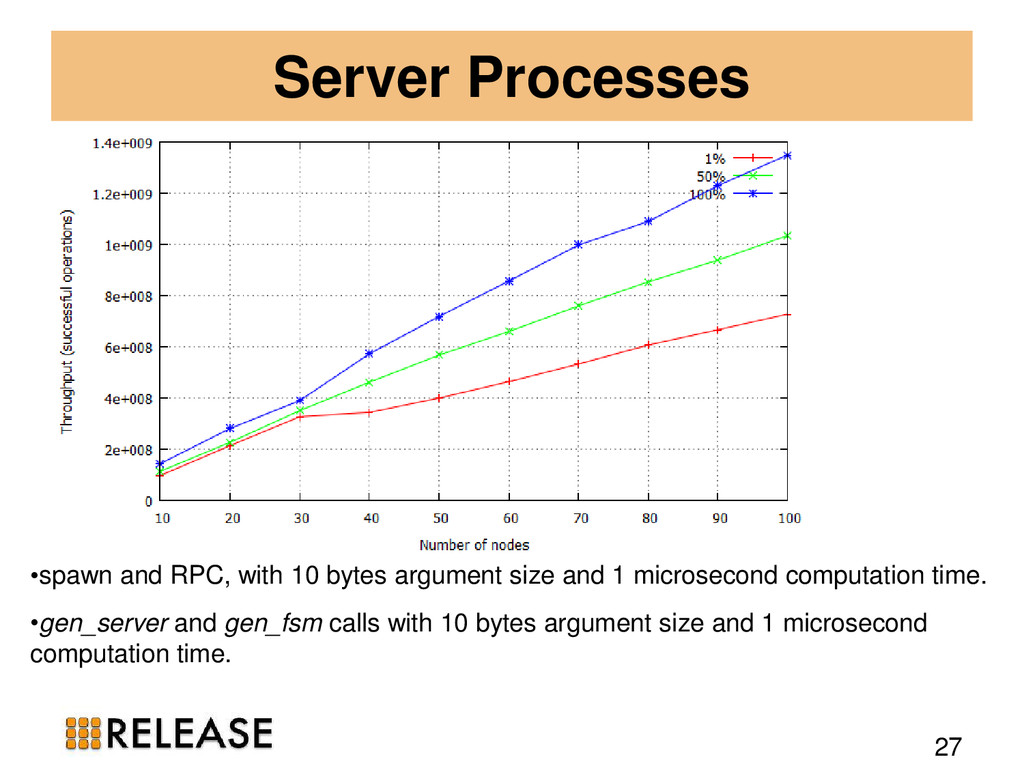{kind=link}
{kind=link}
{kind=link}
{kind=link}