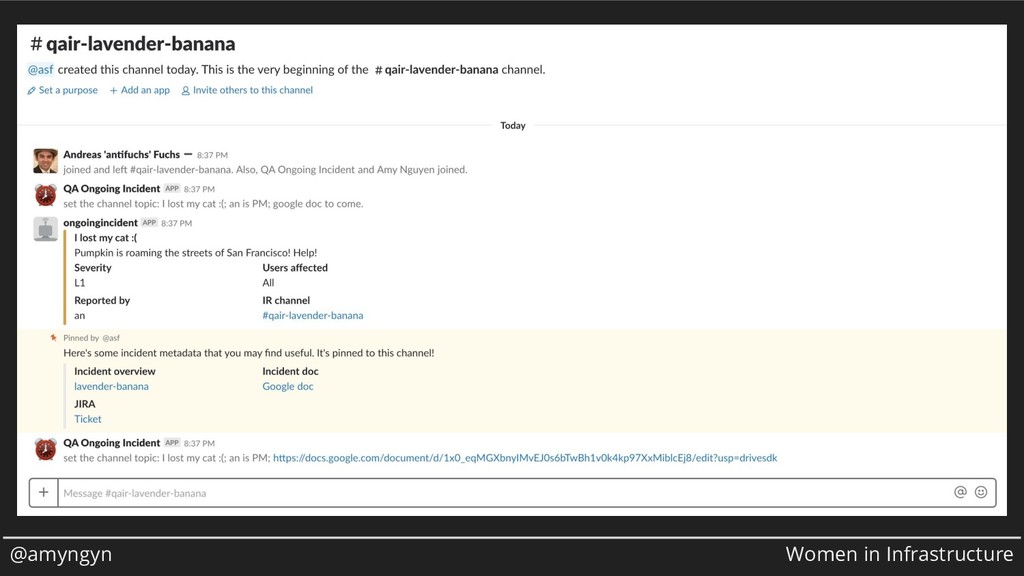
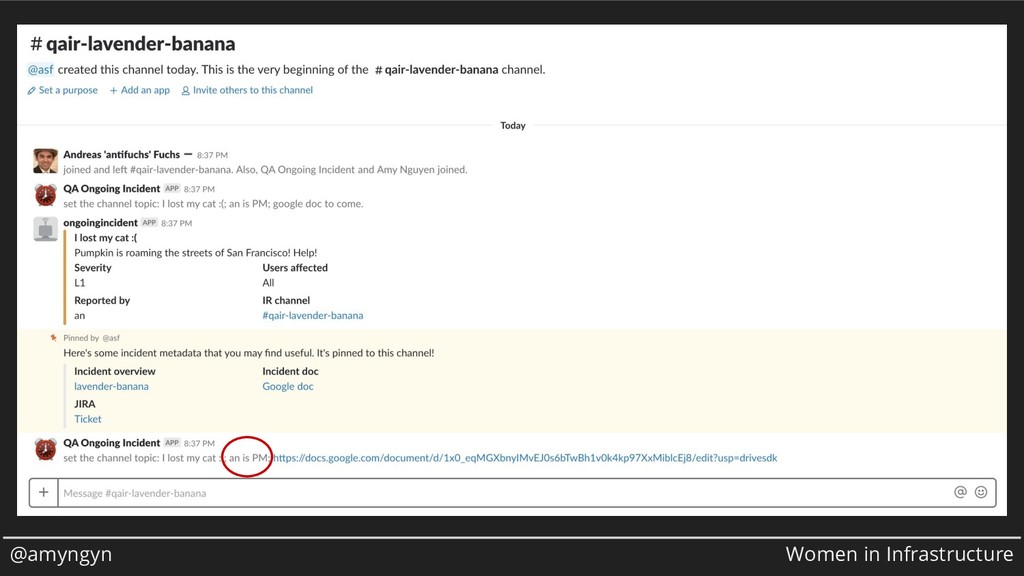
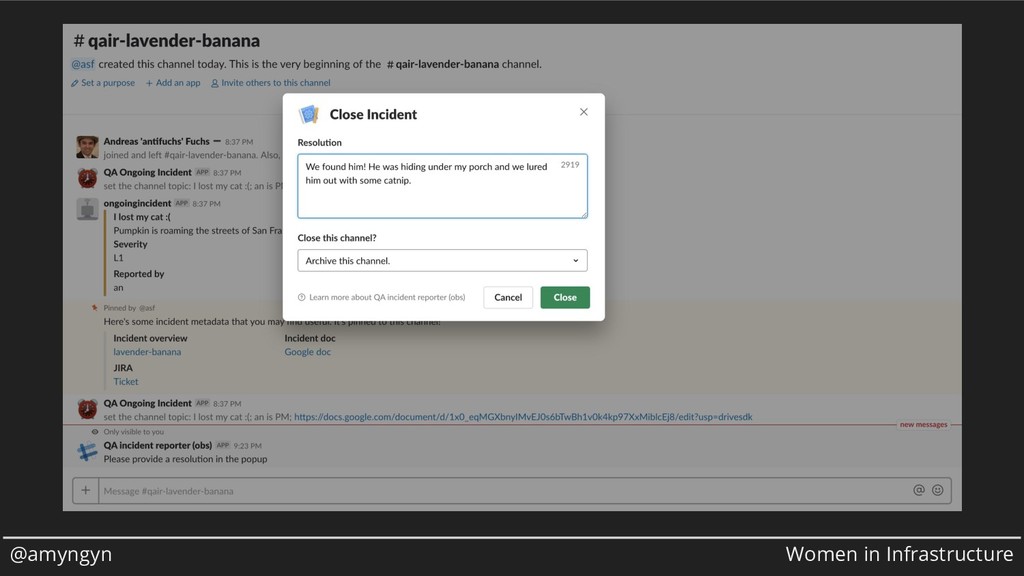
When an incident starts, ten different things need to happen at once. You need to get an incident commander, you need to get all the right people in the room, you need to mitigate the incident, and you need to stay organized. At Stripe, we've built a tool for automating as much of the routine tasks as possible so responders can focus on what humans do best. In this talk, I'll show you the Big Red Button, a web form that sends emails, creates JIRA tickets, opens Slack channels, sends pages, and more. We'll talk about the unique constraints of this tool (such as, how much incident metadata do you ask for up-front?) and how our incident management philosophy influenced our design.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}