Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Good Schema Design and Why It Matters
Search
Andrew Godwin
May 15, 2014
Programming
1.3k
12
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Good Schema Design and Why It Matters
A talk I gave at DjangoCon Europe 2014.
Andrew Godwin
May 15, 2014
More Decks by Andrew Godwin
See All by Andrew Godwin
Reconciling Everything
andrewgodwin
1
400
Django Through The Years
andrewgodwin
0
330
Writing Maintainable Software At Scale
andrewgodwin
0
530
A Newcomer's Guide To Airflow's Architecture
andrewgodwin
0
420
Async, Python, and the Future
andrewgodwin
2
740
How To Break Django: With Async
andrewgodwin
1
830
Taking Django's ORM Async
andrewgodwin
0
850
The Long Road To Asynchrony
andrewgodwin
0
770
The Scientist & The Engineer
andrewgodwin
1
860
Other Decks in Programming
See All in Programming
言語を使う側から、作る側へ。 自作 Lisp で得た新たな気づき。
andpad
0
130
Apache Hive: そしてCloud Native Lakehouseへ
okumin
1
150
音楽のための関数型プログラミング言語mimiumにおける多段階計算の活用
tomoyanonymous
1
350
AI時代の仕事技芸論〜ソフトウェア開発で「遊ぶように働く」職人的熟達のすすめ(スクフェス仙台 2026バージョン)
kuranuki
0
680
Claude Opus 4.6以後の受託開発エンジニアの変化(Claude Code開発ノウハウ大公開スペシャルbyクラスメソッド)
iidatakuma
1
820
ビデオ通話が繋がる0.2秒で何が起きているのか
supurazako
2
150
トークンをケチるな、設計しろ:GitHub Copilotを賢く使うコンテキスト戦略
ochtum
0
330
yield再入門 #phpcon
o0h
PRO
0
690
任せる範囲はこう広がった / How the Scope of AI Delegation Has Expanded
nrslib
1
270
SREの積み重ねがAI駆動開発のガードレールになった ― 7つの実践/SRE Guardrails The 7
tomoyakitaura
8
4.9k
信頼性について考えてみる(SRE NEXT 2026 miniLT)
hayama17
0
200
鹿野さんに聞く!『TypeScriptコードレシピ集』で磨く実践力
tonkotsuboy_com
4
1.1k
Featured
See All Featured
WCS-LA-2024
lcolladotor
0
730
Building the Perfect Custom Keyboard
takai
2
820
Digital Ethics as a Driver of Design Innovation
axbom
PRO
1
350
Jess Joyce - The Pitfalls of Following Frameworks
techseoconnect
PRO
1
310
Balancing Empowerment & Direction
lara
6
1.2k
The Language of Interfaces
destraynor
162
27k
New Earth Scene 8
popppiees
3
2.4k
Abbi's Birthday
coloredviolet
3
8.7k
世界の人気アプリ100個を分析して見えたペイウォール設計の心得
akihiro_kokubo
PRO
72
40k
First, design no harm
axbom
PRO
2
1.2k
Primal Persuasion: How to Engage the Brain for Learning That Lasts
tmiket
0
390
The AI Search Optimization Roadmap by Aleyda Solis
aleyda
1
6k
Transcript
Andrew Godwin @andrewgodwin GOOD SCHEMA DESIGN WHY IT MATTERS and
Andrew Godwin Core Developer Senior Engineer Author & Maintainer
Schemas Explicit & Implicit
Explicit PostgreSQL MySQL Oracle SQLite CouchDB MongoDB Redis ZODB Implicit
Explicit Schema ID int Name text Weight uint 1 2
3 Alice Bob Charles 76 84 65 Implicit Schema { "id": 342, "name": "David", "weight": 44, }
Explicit Schema Normalised or semi normalised structure JOINs to retrieve
related data Implicit Schema Embedded structure Related data retrieved naturally with object
Silent Failure { "id": 342, "name": "David", "weight": 74, }
{ "id": 342, "name": "Ellie", "weight": "85kg", } { "id": 342, "nom": "Frankie", "weight": 77, } { "id": 342, "name": "Frankie", "weight": -67, }
Schemas inform Storage
PostgreSQL
Adding NULLable columns: instant But must be at end of
table
CREATE INDEX CONCURRENTLY Slower, and only one at a time
Constraints after column addition This is more general advice
MySQL Locks whole table Rewrites entire storage No DDL transactions
Oracle / MSSQL / etc. Look into their strengths
Changing the Schema Databases aren't code...
You can't put your database in a VCS You can
put your schema in a VCS But your data won't always survive.
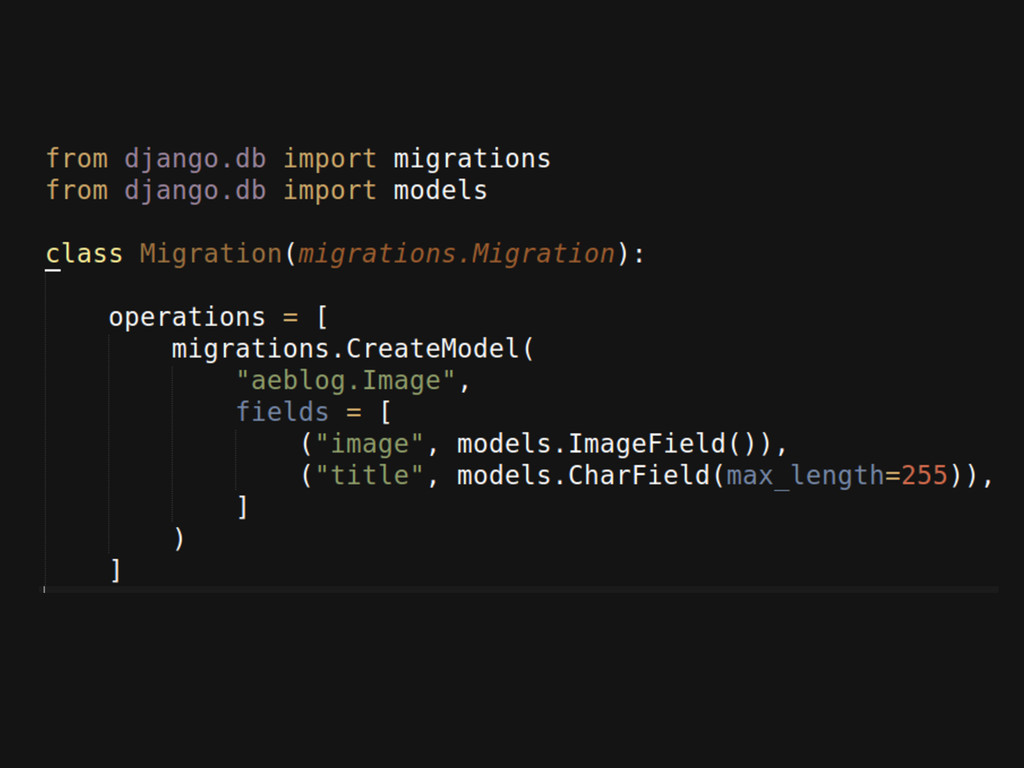
Django Migrations Codified schema change format
None
Migrations aren't enough You can't automate away a social problem!
What if we got rid of the schema? That pesky,
pesky schema.
The Nesting Problem { "id": 123, "name": "Andrew", "friends": [
{"id": 456, "name": "David"}, {"id": 789, "name": "Mazz"}, ], "likes": [ {"id": 22, "liker": {"id": 789, "name", "Mazz"}}, ], }
You don't have to use a document DB (like CouchDB,
MongoDB, etc.)
Schemaless Columns ID int Name text Weight uint Data json
1 Alice 76 { "nickname": "Al", "bgcolor": "#ff0033" }
But that must be slower... Right?
Comparison (never trust benchmarks) Loading 1.2 million records PostgreSQL MongoDB
76 sec 8 min Sequential scan PostgreSQL MongoDB 980 ms 980 ms Index scan (Postgres GINhash) PostgreSQL MongoDB 0.7 ms 1 ms
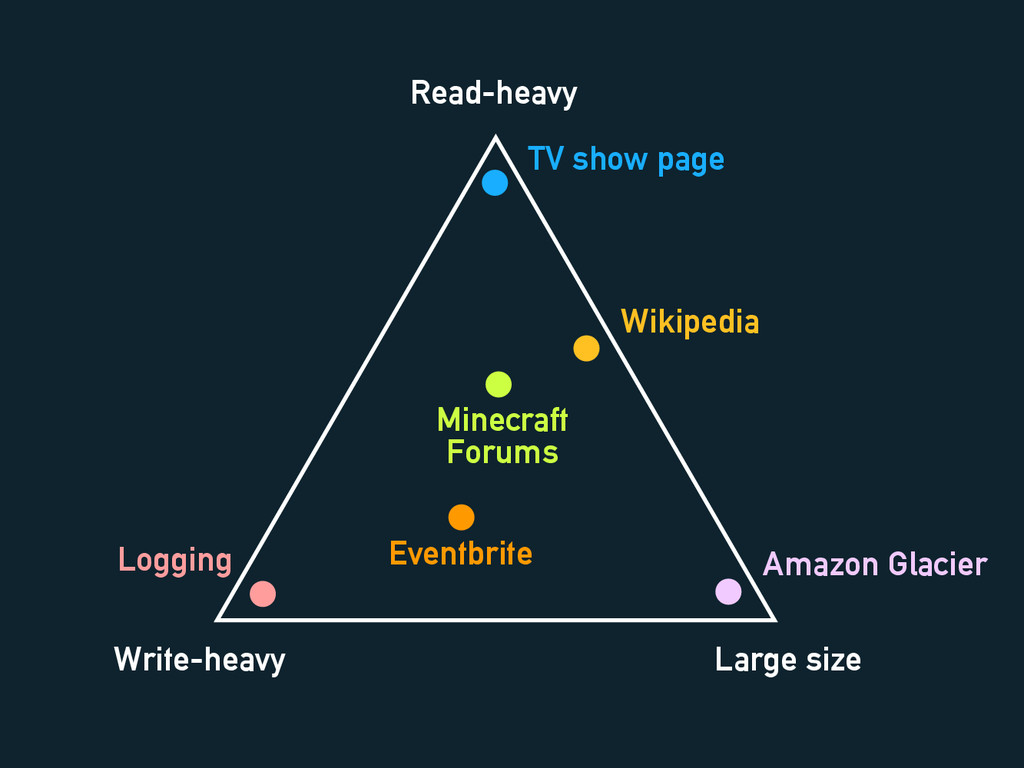
Load Shapes
Read-heavy Write-heavy Large size
Read-heavy Write-heavy Large size Wikipedia TV show page Minecraft Forums
Amazon Glacier Eventbrite Logging
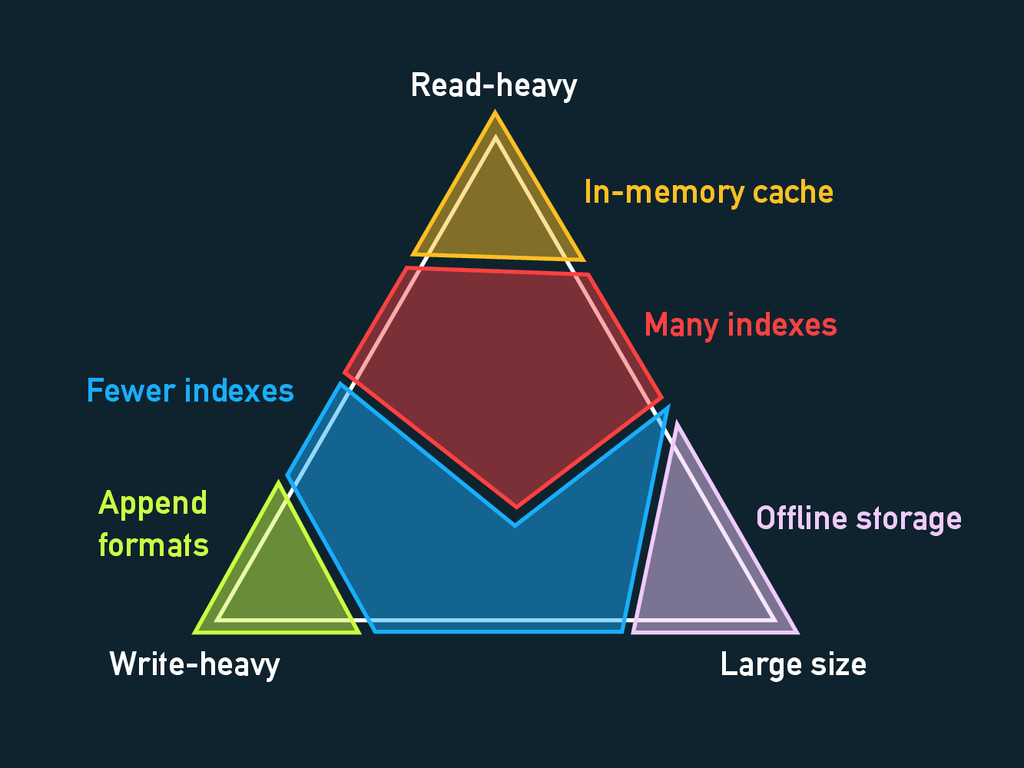
Read-heavy Write-heavy Large size Offline storage Append formats In-memory cache
Many indexes Fewer indexes
Your load changes over time Scaling is not just a
flat multiplier
General Advice Write heavy → Fewer indexes Read heavy →
Denormalise Keep large data away from read/write heavy data Blob stores/filesystems are DBs too
Lessons They're near the end so you remember them.
Re-evaulate as you grow Different things matter at different sizes
Adding NULL columns is great Always prefer this if nothing
else
You'll need more than one DBMS But don't use too
many, you'll be swamped
Indexes aren't free You pay the price at write/restore time
Relational DBs are flexible They can do a lot more
than JOINing normalised tables
Thanks! Andrew Godwin @andrewgodwin eventbrite.com/jobs are hiring:
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}