title text, data hstore); INSERT INTO widgets (id, text, data) VALUES (1, 'Object One', 'model => "8973-b", scale => 2'); SELECT * FROM widgets WHERE data->'scale' = '2'; id | title | data ----+------------+--------------------------------- 1 | Object One | "model"=>"8973-b", "scale"=>"2"
data ?| ARRAY['model', 'diagram']; title | model ------------+-------- Object One | 8973-b CREATE INDEX ON widgets USING gin (data); CREATE INDEX ON widgets ((data->'scale'));
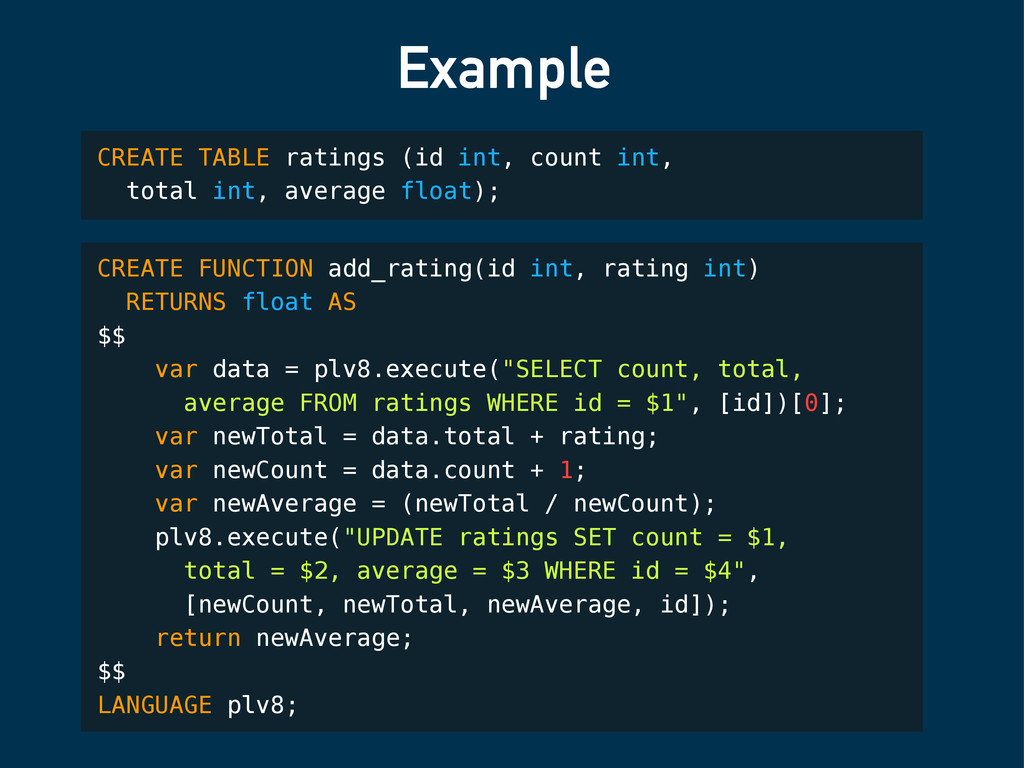
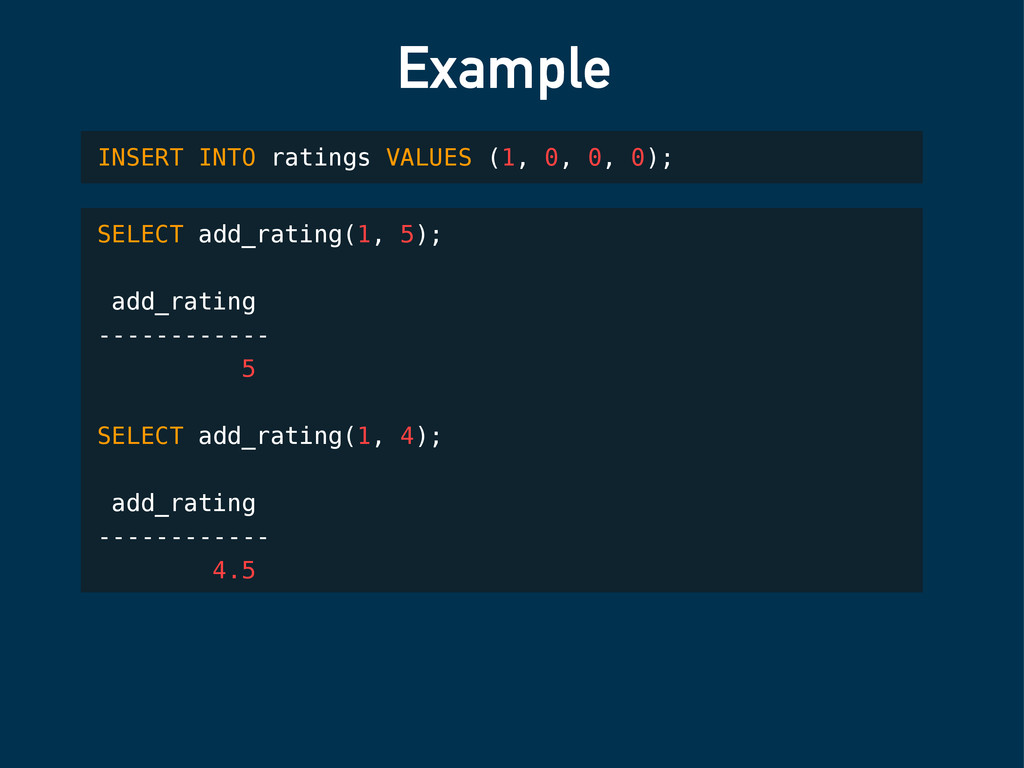
$$ var data = plv8.execute("SELECT count, total, average FROM ratings WHERE id = $1", [id])[0]; var newTotal = data.total + rating; var newCount = data.count + 1; var newAverage = (newTotal / newCount); plv8.execute("UPDATE ratings SET count = $1, total = $2, average = $3 WHERE id = $4", [newCount, newTotal, newAverage, id]); return newAverage; $$ LANGUAGE plv8; CREATE TABLE ratings (id int, count int, total int, average float);
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Thanks! Andrew Godwin @andrewgodwin [email protected]](https://files.speakerdeck.com/presentations/d07d30401a3301319b734e4ebe2f16c3/slide_32.jpg){kind=link}