Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
The Peris of Writing a PaaS
Search
Andrew Godwin
May 10, 2011
Programming
150
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
The Peris of Writing a PaaS
A talk I gave at London Devops in May of 2011.
Andrew Godwin
May 10, 2011
More Decks by Andrew Godwin
See All by Andrew Godwin
Reconciling Everything
andrewgodwin
1
400
Django Through The Years
andrewgodwin
0
330
Writing Maintainable Software At Scale
andrewgodwin
0
530
A Newcomer's Guide To Airflow's Architecture
andrewgodwin
0
430
Async, Python, and the Future
andrewgodwin
2
750
How To Break Django: With Async
andrewgodwin
1
830
Taking Django's ORM Async
andrewgodwin
0
850
The Long Road To Asynchrony
andrewgodwin
0
770
The Scientist & The Engineer
andrewgodwin
1
860
Other Decks in Programming
See All in Programming
仕様書を書く前にハーネスを作る - Agent Native開発は「探索を速く、判定を固く」
gotalab555
3
1.3k
2年かけて Deno に DOMMatrix を実装した話 / How I implemented DOMMatrix in Deno over two years
petamoriken
0
190
torikago - Ruby::Boxで照らすモジュラモノリスの実行境界
se4weed
1
290
SREの積み重ねがAI駆動開発のガードレールになった ― 7つの実践/SRE Guardrails The 7
tomoyakitaura
9
5.9k
What's New in Android 2026
veronikapj
0
240
Embedded SREと共に達成した会員管理システムのAWS移行 - SRE NEXT 2026 ランチスポンサーセッション
niftycorp
PRO
1
3.3k
Built Our Own Background Agent at LayerX #aidevex_findy
layerx
PRO
9
3.8k
【やさしく解説 設計編・中級 #1】一つの車に、運転手は一人 ~ある倉庫システムの事例から~
panda728
PRO
0
200
Prismを使った型安全な暗号化_関数型まつり2026
_fhhmm
0
160
アルゴリズムは何を圧縮しているのか ─ Haskell から育った「圧縮代数」というメンタルモデル
naoya
16
3.7k
わからない話を追いかけたら、プログラミング言語を作る側にいた
ydah
2
130
GDG Korea Android: 2026 I/O Extended ~ What's new in Android development tools
pluu
0
200
Featured
See All Featured
End of SEO as We Know It (SMX Advanced Version)
ipullrank
3
4.3k
We Analyzed 250 Million AI Search Results: Here's What I Found
joshbly
1
1.7k
A designer walks into a library…
pauljervisheath
211
24k
Refactoring Trust on Your Teams (GOTO; Chicago 2020)
rmw
35
3.7k
A Modern Web Designer's Workflow
chriscoyier
698
190k
Building Flexible Design Systems
yeseniaperezcruz
330
40k
Building Experiences: Design Systems, User Experience, and Full Site Editing
marktimemedia
0
560
Leo the Paperboy
mayatellez
8
2k
Design and Strategy: How to Deal with People Who Don’t "Get" Design
morganepeng
133
19k
Conquering PDFs: document understanding beyond plain text
inesmontani
PRO
4
2.9k
Context Engineering - Making Every Token Count
addyosmani
9
1k
The #1 spot is gone: here's how to win anyway
tamaranovitovic
3
1.1k
Transcript
The Perils of Writing a PaaS Andrew Godwin http://www.flickr.com/photos/jannem/2719976702/
Hi, I'm Andrew. Serial Python developer Django core committer Sysadmin
by night
We're ep.io Python Platform-as-a-Service Utility billing PostgreSQL, Redis, Celery, and
more
We built a… prototype. Me and Ben Firshman Three or
four days' hacking at DjangoCon Ran code, had simple deployment
The last 10%... A month or two of hibernation Went
part-time in December Private beta since February Public launch later this year
Why? Why not?
Why? Why not? Lack of good solutions Strong, technical team
Writing backend code is fun
It's a challenge We're still a closed beta 300+ apps,
on 4 servers Some people just have crazy code Security, security, security
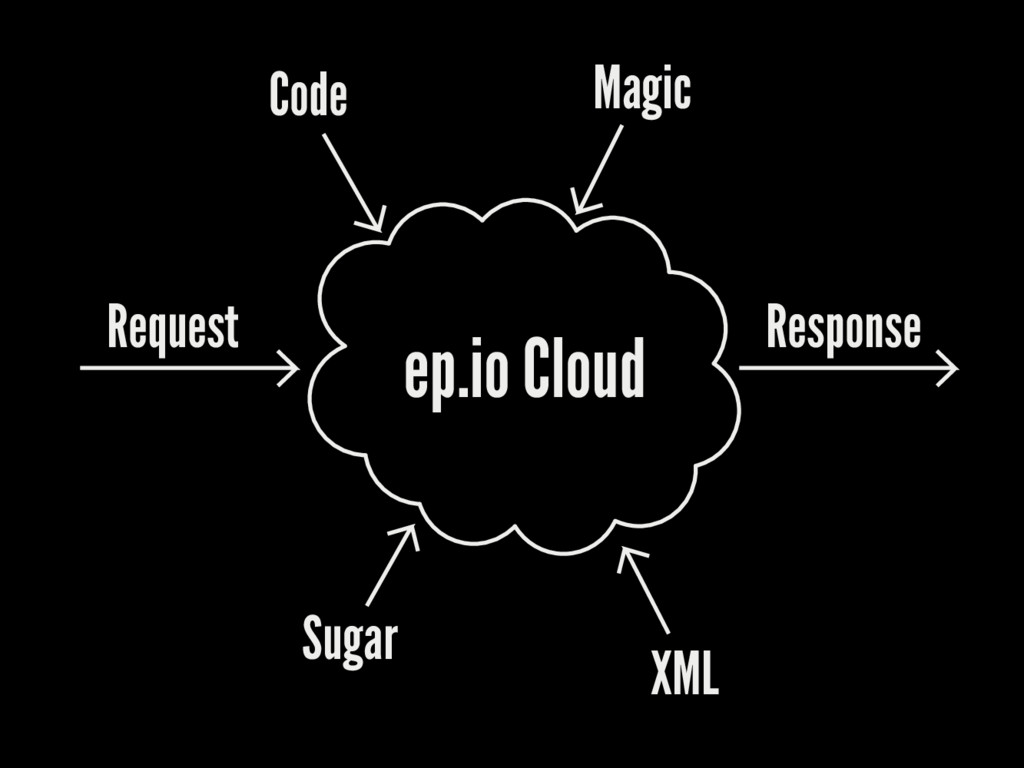
Our Architecture
ep.io Cloud Request Sugar XML Response Code Magic
Balancer Runner Runner Runner App 1 App 2 App 3
App 2 App 4 App 1 Databases File Storage
Load Balancer Started with HaProxy Moved to custom Python loadbalancer
Still needs refinement
Runners Daemon on each machine Nginx + gunicorn for each
app instance Output captured, CPU time measured
Coordinator Analyses whole system Juggles apps between servers Detects dead
servers
PostgreSQL Normal PostgreSQL 9 install Daemon to read query logs,
make users
Redis Custom Redis loadbalancer/manager Starts processes on demand Handles multi-user
security
Upload Receiver SSH endpoint for git, hg, commands Wraps VCSs,
extracts uploaded files Creates filesystem images
Other Services Log aggregation UID assignment Calculate costs
Statistics Queued in Redis Consumed asynchronously Currently stored in Redis,
changing soon Graphed and profiled
Configuration Management Puppet for the simpler stuff Daemons handle complex
stuff Don't try to reinvent the wheel
Monitoring Nagios SaaS monitoring Nagios Emails, texts, pager Several custom
checks
Backups Currently just rdiff-backup Moving to btrfs snapshots + DRBD
HA is not a backup solution
Perils
Initial bad design (To be fair, it was a prototype)
Networks really aren't reliable (Well, EC2's, at least.)
Memory pressure is bad (Prepare to have a fallback. And
another.)
Raw file handles are… fun. (As is the PTY subsystem.
Be very careful.)
Write just enough automation (If a server dies, I now
just go and get a drink)
HaProxy doesn't like 500+ backends (it's not exactly common)
Single redundancy is only so good (and remember, HA is
not backups!)
Future Perils
Payment (Already underway, still hard)
Oversized Sites (we need to get a lot bigger first)
European Servers (people really do want them)
More Databases (how on earth do you measure MongoDB use?)
More Languages (easy to get it working, hard to polish)
The Potential Big Outage (quite useful as a motivational tool)
Thank you. Andrew Godwin @andrewgodwin
[email protected]
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Thank you. Andrew Godwin @andrewgodwin [email protected]](https://files.speakerdeck.com/presentations/2f7b163c02424892aa55c293f487cbd4/slide_37.jpg){kind=link}