Predicted Cloud Spend / Consumption - an #EnsembleLearning Approach
an @Azure #machinelearning / #deeplearning use case walk through - How to avoid #spuriousCorrelations, understand drivers of cloud spend (consumption) and accurately predicted future spend based on those drivers.
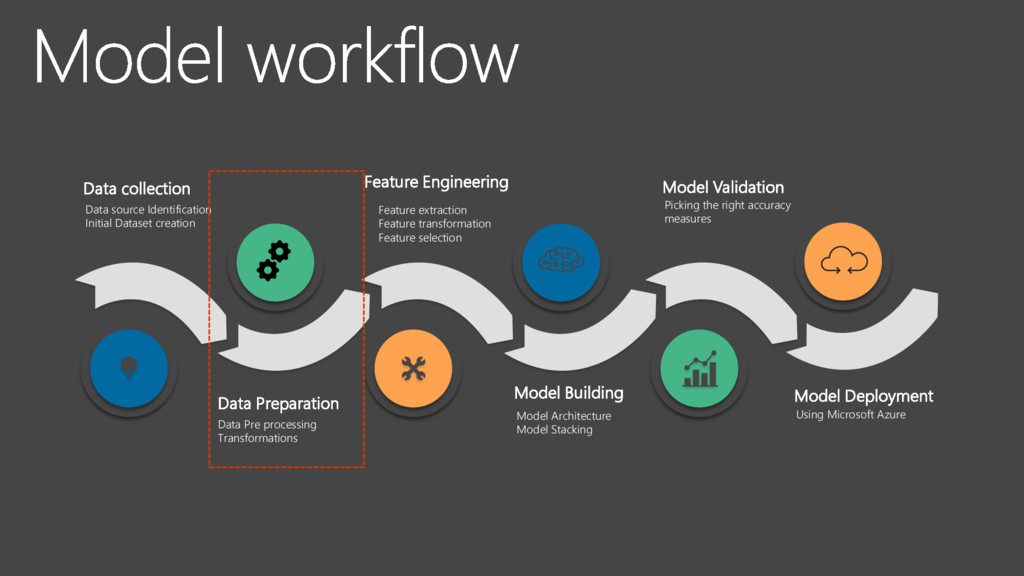
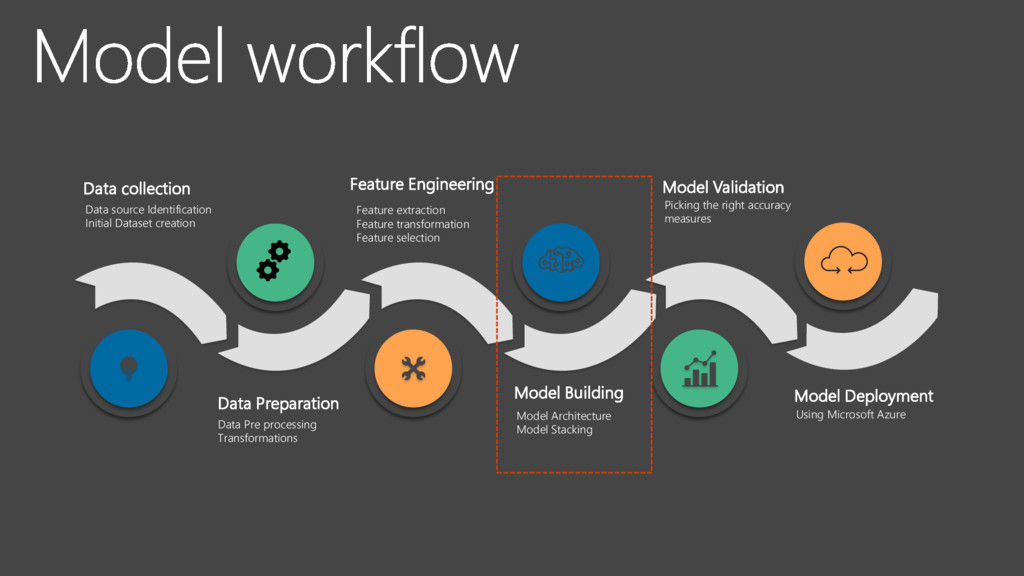
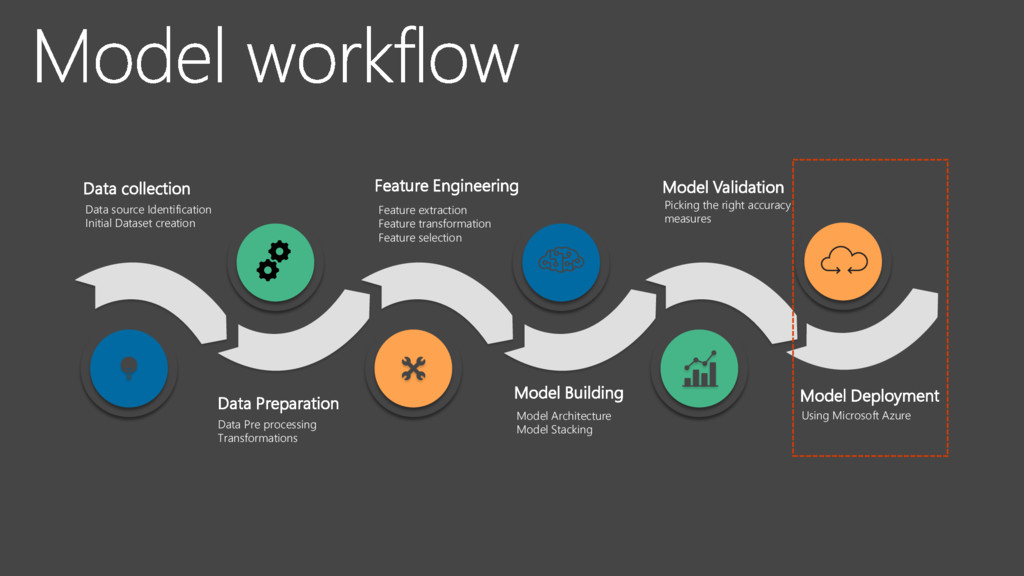
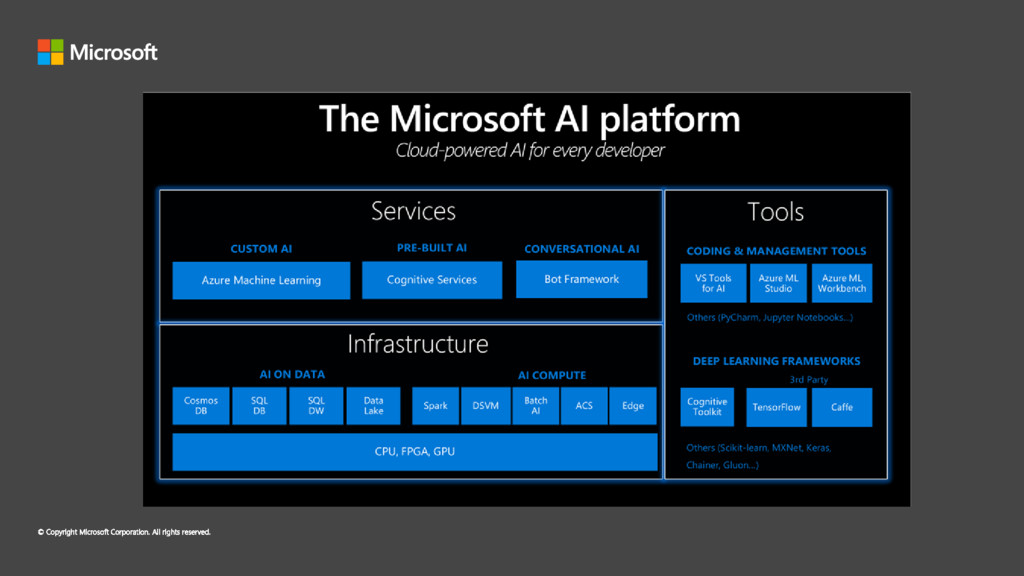
Identification Initial Dataset creation Feature Engineering Feature extraction Feature transformation Feature selection Model Building Model Architecture Model Stacking Model Validation Picking the right accuracy measures Model Deployment Using Microsoft Azure
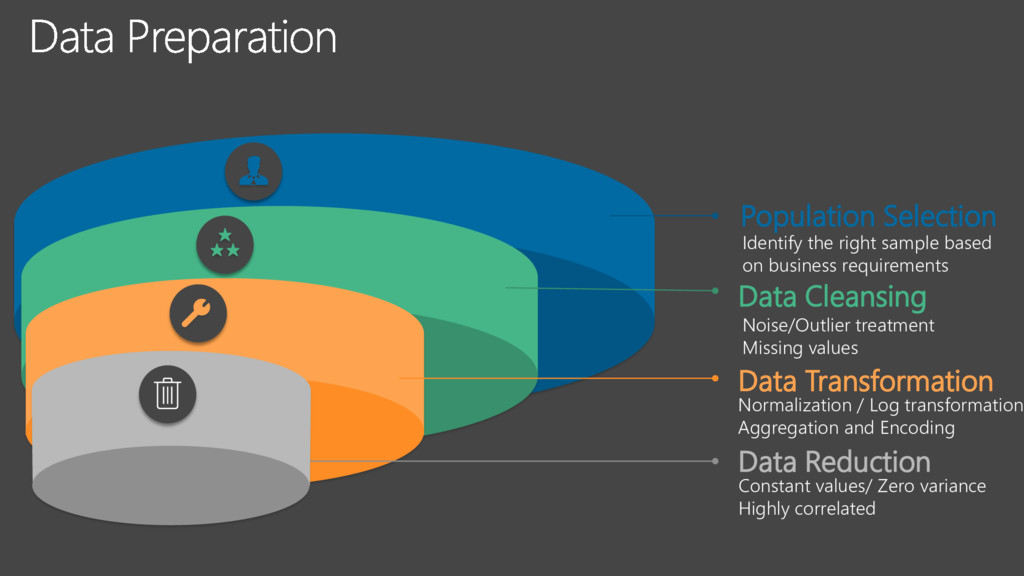
Noise/Outlier treatment Missing values Data Cleansing Normalization / Log transformation Aggregation and Encoding Data Transformation Constant values/ Zero variance Highly correlated Data Reduction
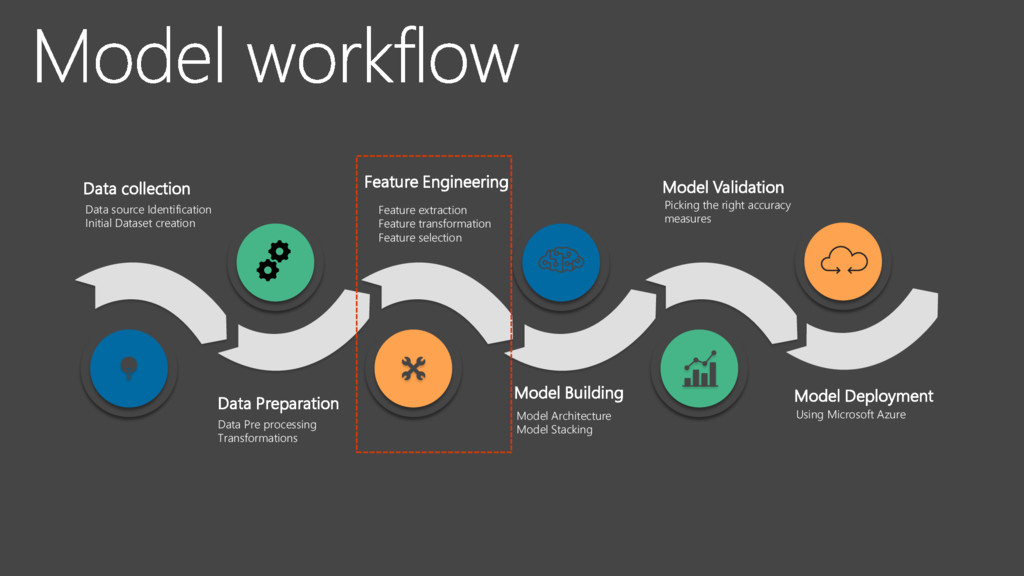
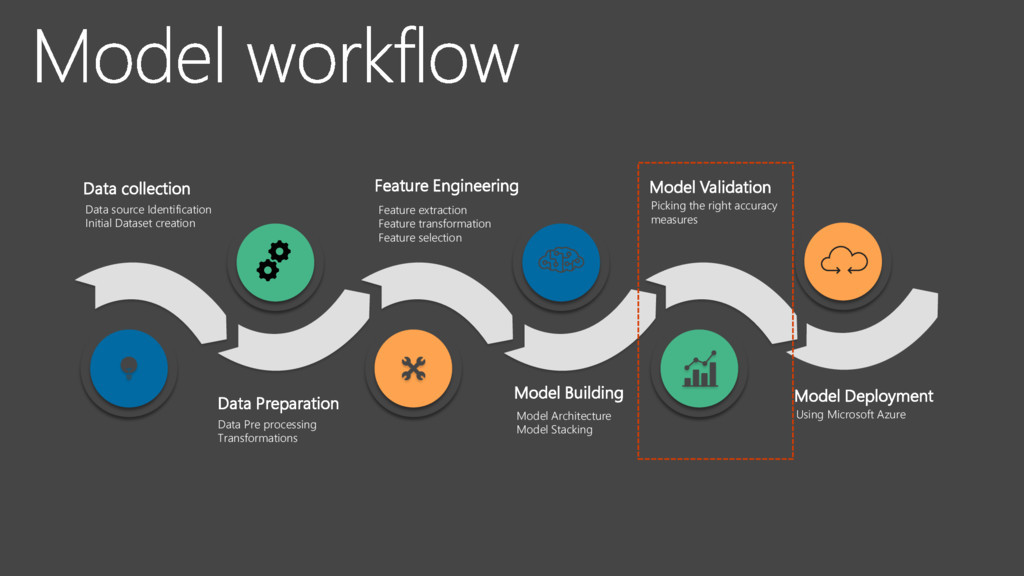
Identification Initial Dataset creation Feature Engineering Feature extraction Feature transformation Feature selection Model Building Model Architecture Model Stacking Model Validation Picking the right accuracy measures Model Deployment Using Microsoft Azure
historic run rate (spending/rate) are more likely to spend more on Azure Prior Spend Customers subscribed to higher tier offers are likely to spend more on Azure What offer they subscribed to.. Customers from developed countries are likely to have higher spend Customers from tech dominant states/regions are more likely to spend more What country they belong to.. Customer associated with professional services, tech industry are more likely to spend more on Azure Which industry they belong to..
Identification Initial Dataset creation Feature Engineering Feature extraction Feature transformation Feature selection Model Building Model Architecture Model Stacking Model Validation Picking the right accuracy measures Model Deployment Using Microsoft Azure
Identification Initial Dataset creation Feature Engineering Feature extraction Feature transformation Feature selection Model Building Model Architecture Model Stacking Model Validation Picking the right accuracy measures Model Deployment Using Microsoft Azure
Identification Initial Dataset creation Feature Engineering Feature extraction Feature transformation Feature selection Model Building Model Architecture Model Stacking Model Validation Picking the right accuracy measures Model Deployment Using Microsoft Azure
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}