in a high-dimensional space, 768 dimensions. Words with related meanings often appear close together in the embedding space. The figure plots the embeddings of a few semantically related tokens, projected into two dimensions using Principal Component Analysis (PCA). In [ ]: words = ["father","mother","brother","sister", # family ### candidate words ### "man","woman","boy","girl", # gender "dog","cat","horse","cow"] # animals # words = ["London","Paris","Madrid","Rome","Oslo","Berlin" # "UK","France","Spain","Italy","Norway","Germany" # ] # animals tokens = [] ### convert words → tokens ### for w in words: ids = tokenizer.encode(w, add_special_tokens=False) for tid in ids: tokens.append(tokenizer.decode([tid])) vectors = [] ### collect embedding vectors ### for w in tokens: token_id = tokenizer.encode(w, add_special_tokens=False)[0] vec = model.transformer.wte.weight[token_id].detach().cpu().numpy() vectors.append(vec) vectors = np.stack(vectors) X = vectors - vectors.mean(axis=0) ### PCA projection ### U, S, Vt = np.linalg.svd(X, full_matrices=False) coords = X @ Vt[:2].T plt.figure(figsize=(8,6)) ### Plot ### plt.scatter(coords[:,0], coords[:,1]) for i, word in enumerate(tokens): plt.text(coords[i,0], coords[i,1], word, fontsize=11) plt.title("GPT-2 Token Embedding Space"); plt.axis("off"); plt.show() 16/3/26, 17:14 llmtalk_slides slides file://wsl.localhost/Ubuntu/home/afp/docs/llmtalk/talkv2/notebooks/llmtalk_slides.slides.html#/ 19/34
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
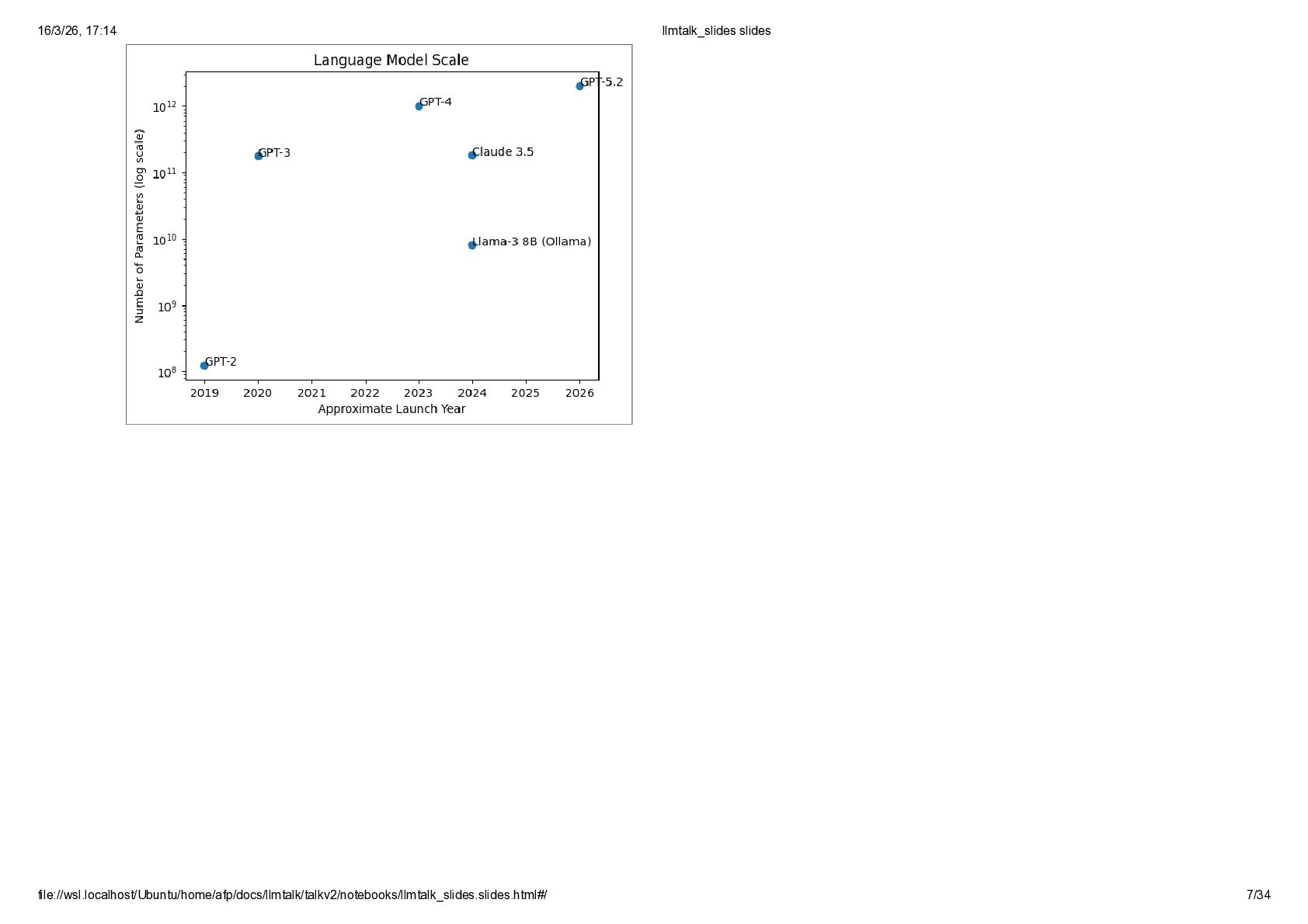
![How does it compare to more recent models? In [22]:](https://files.speakerdeck.com/presentations/33a7425b45fb493bbea4778c3f8fab70/slide_5.jpg){kind=link}
{kind=link}
{kind=link}
![Python Imports In [23]: # imports import os, sys, time,](https://files.speakerdeck.com/presentations/33a7425b45fb493bbea4778c3f8fab70/slide_8.jpg){kind=link}
![Load the Model In [24]: MODEL_NAME = "gpt2" # model](https://files.speakerdeck.com/presentations/33a7425b45fb493bbea4778c3f8fab70/slide_9.jpg){kind=link}
![Run a small prompt with the pretrained model In [25]:](https://files.speakerdeck.com/presentations/33a7425b45fb493bbea4778c3f8fab70/slide_10.jpg){kind=link}
![Run a small prompt many times! In [ ]: print("Prompt:",PROMPT);](https://files.speakerdeck.com/presentations/33a7425b45fb493bbea4778c3f8fab70/slide_11.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
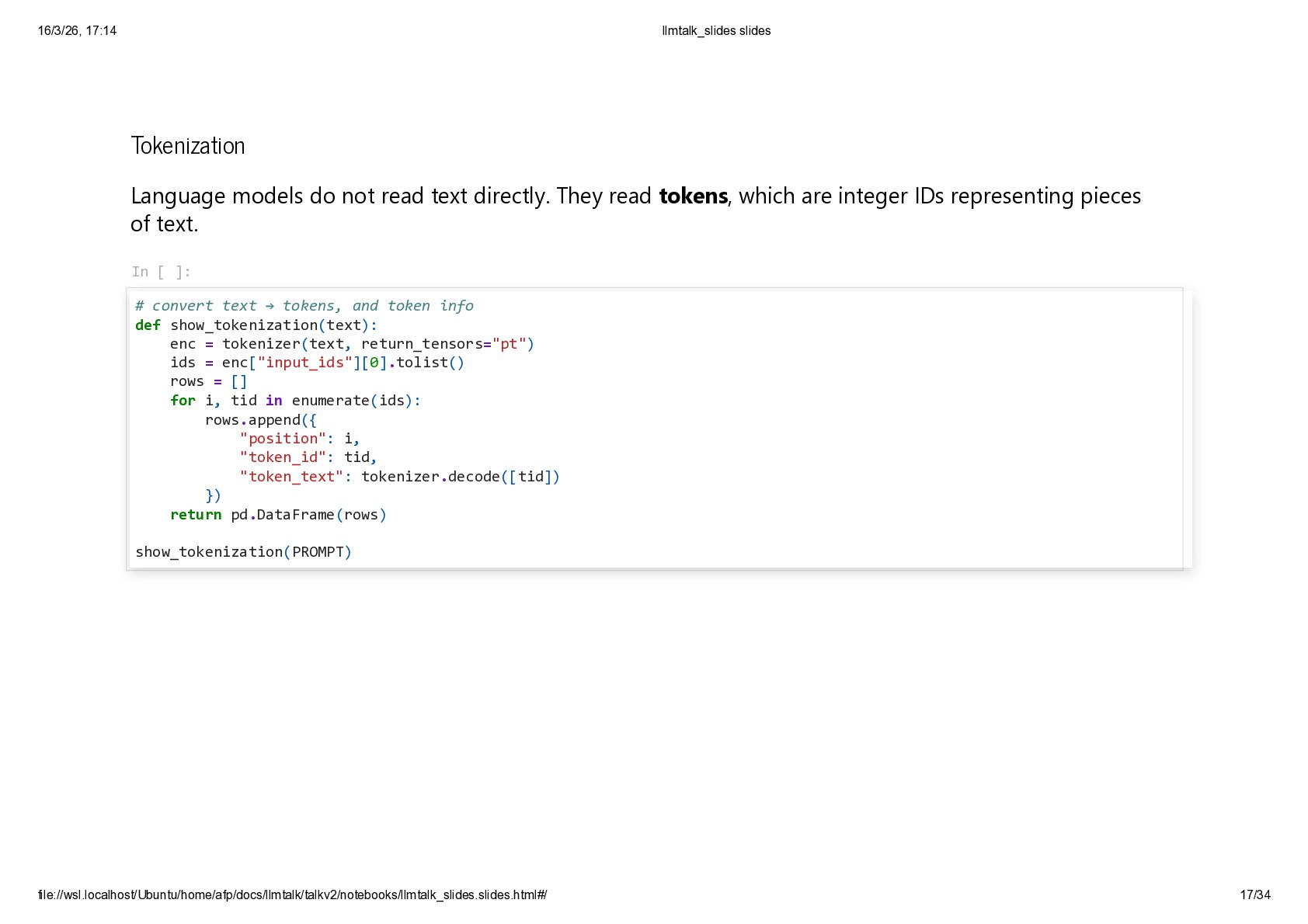{kind=link}
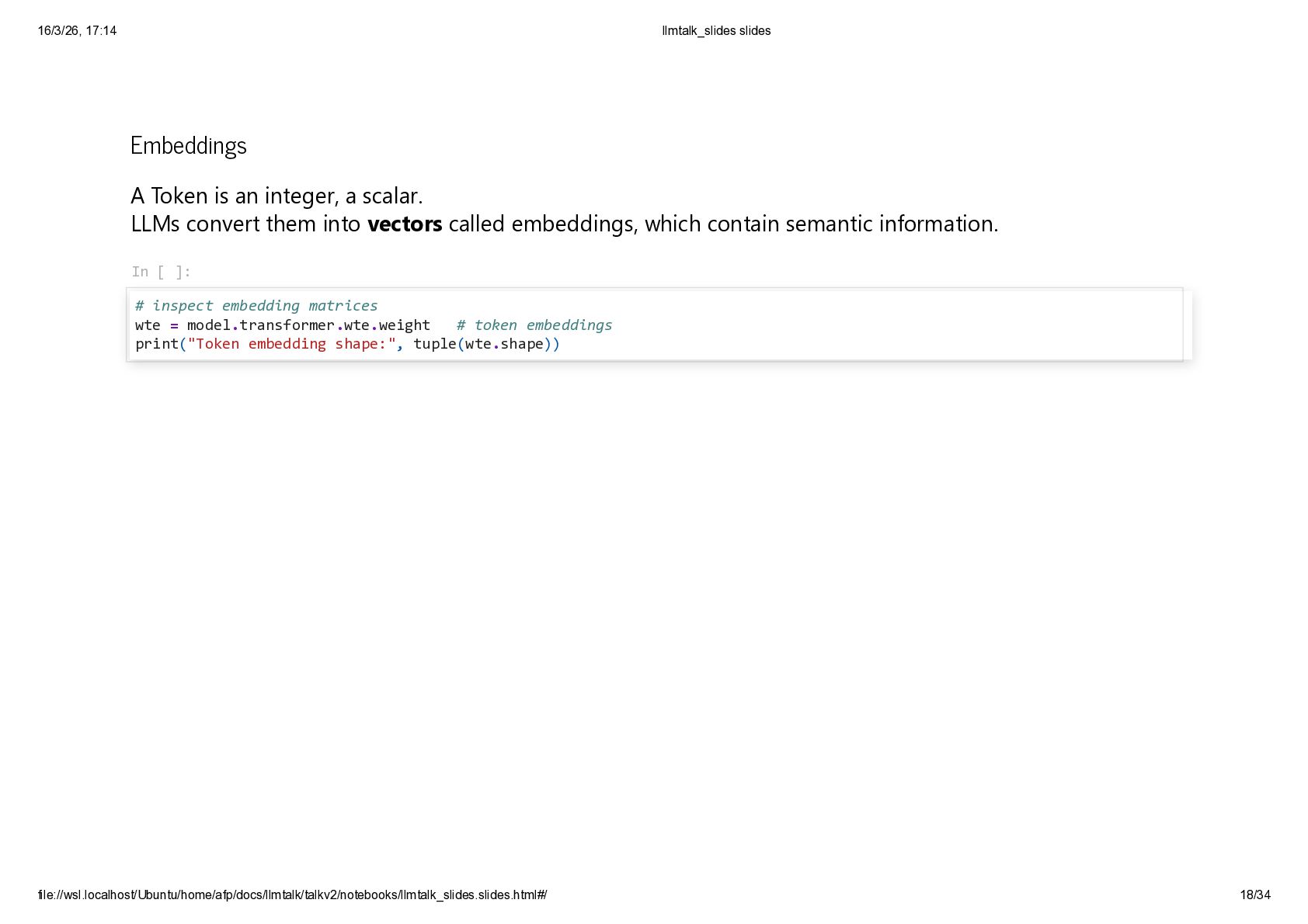{kind=link}
{kind=link}
{kind=link}
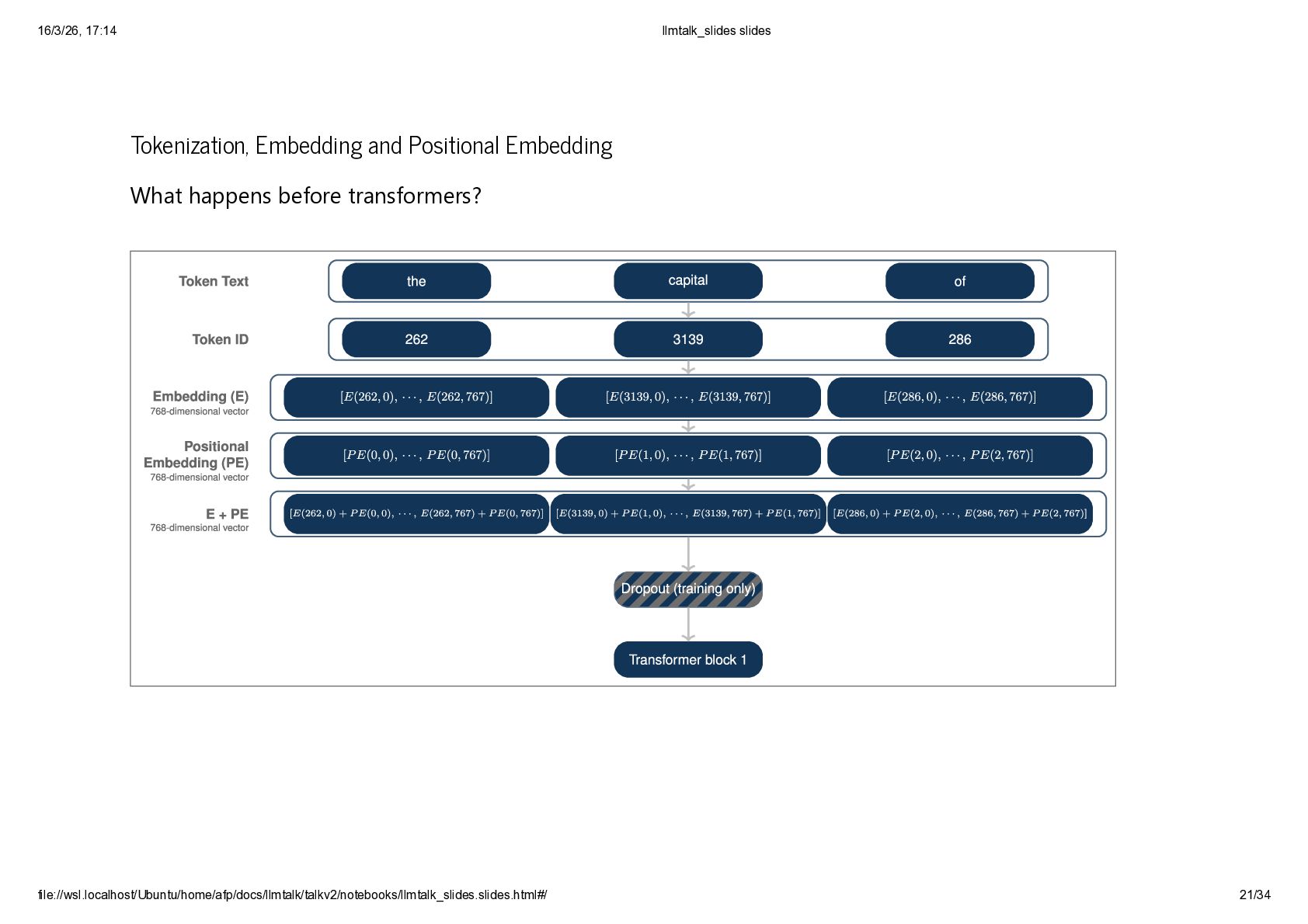{kind=link}
{kind=link}
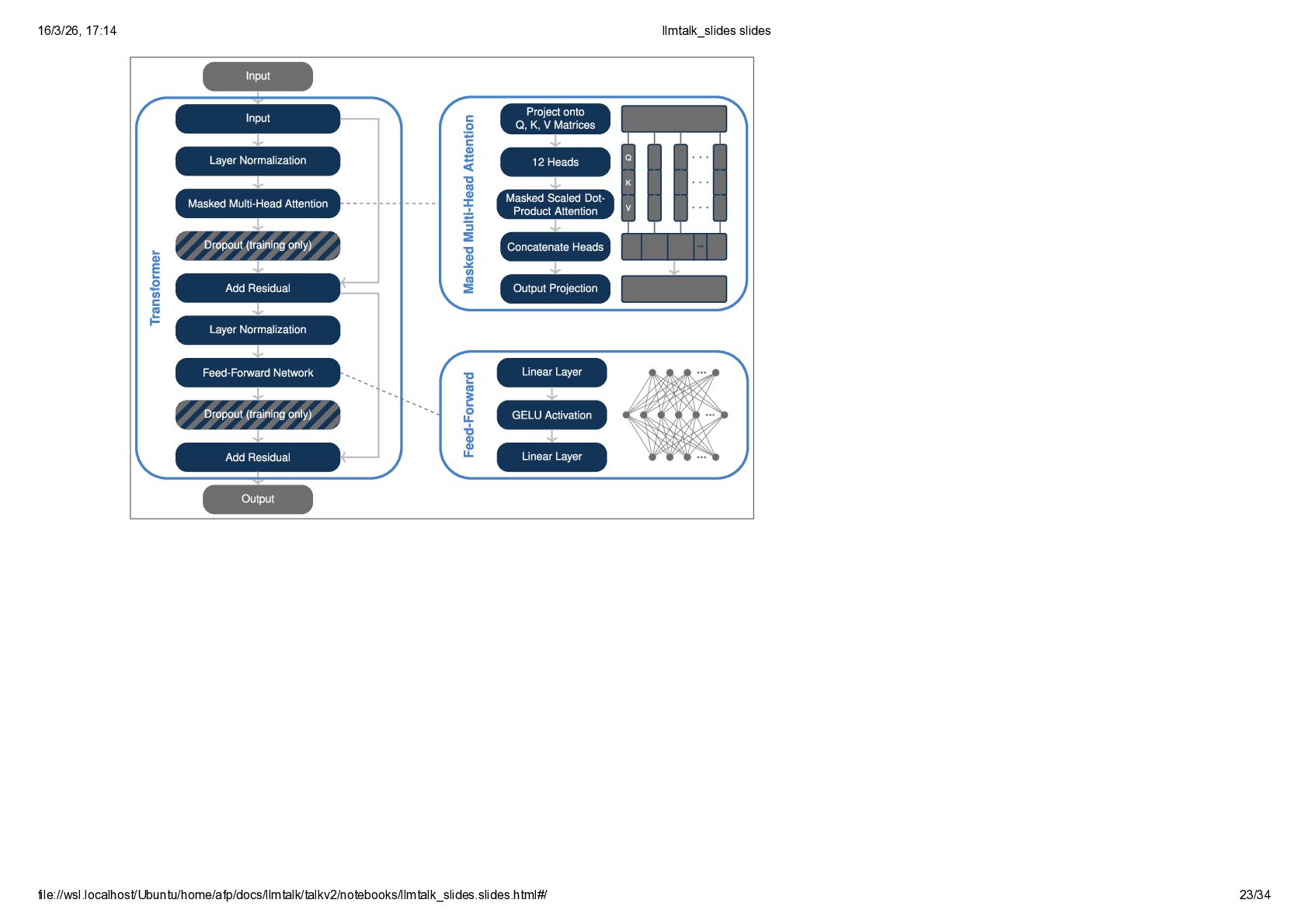{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
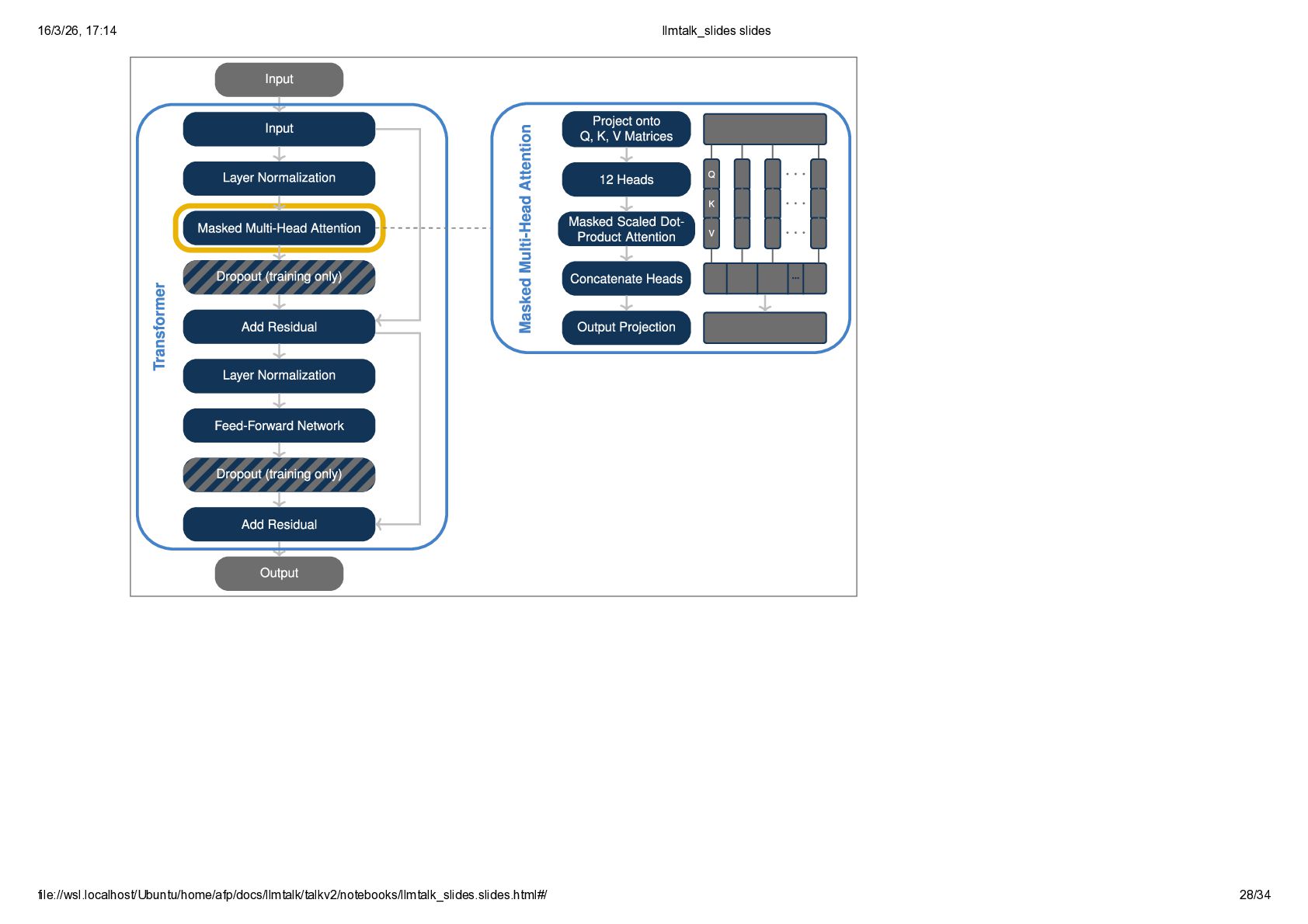{kind=link}
{kind=link}
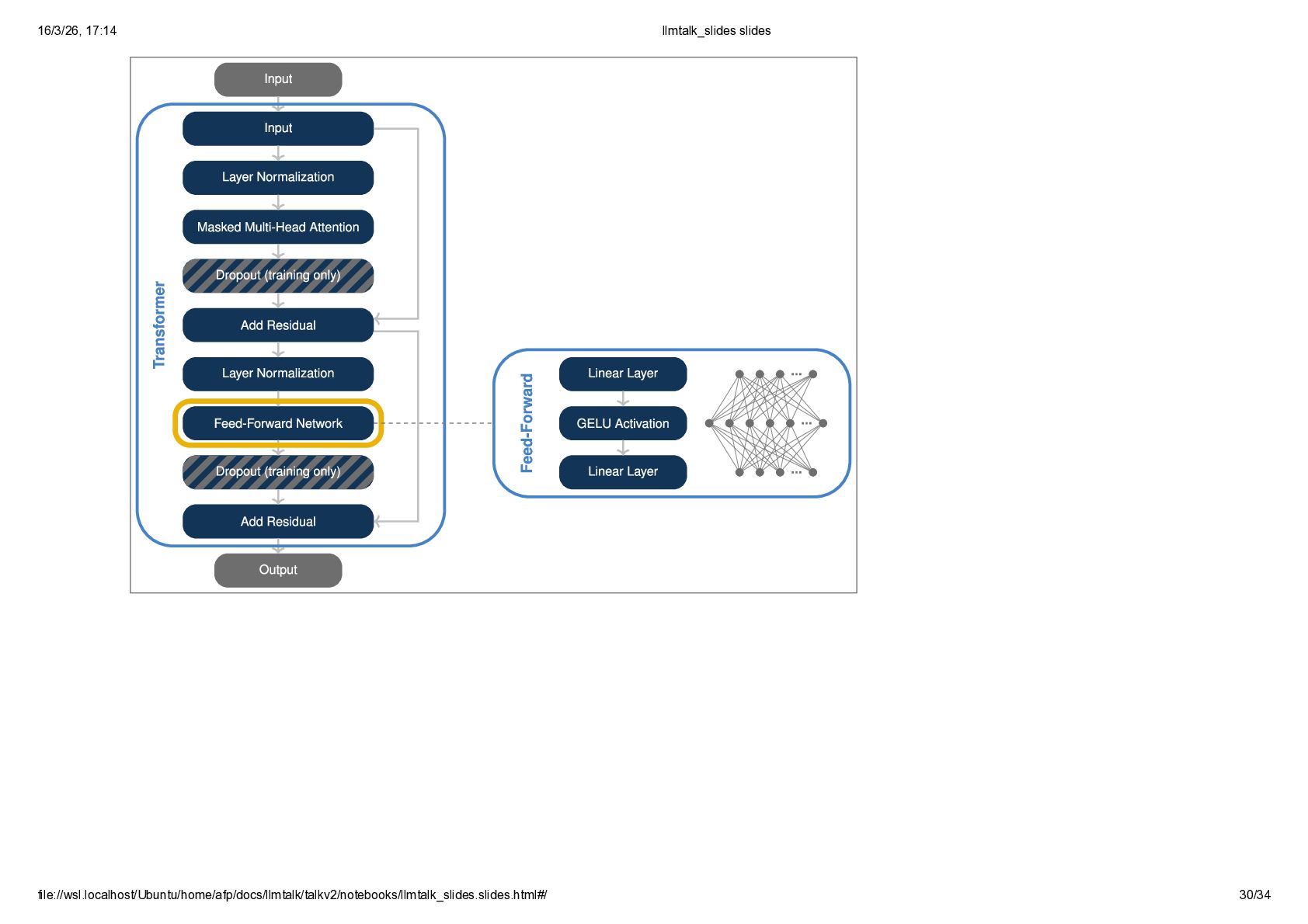{kind=link}
{kind=link}
{kind=link}
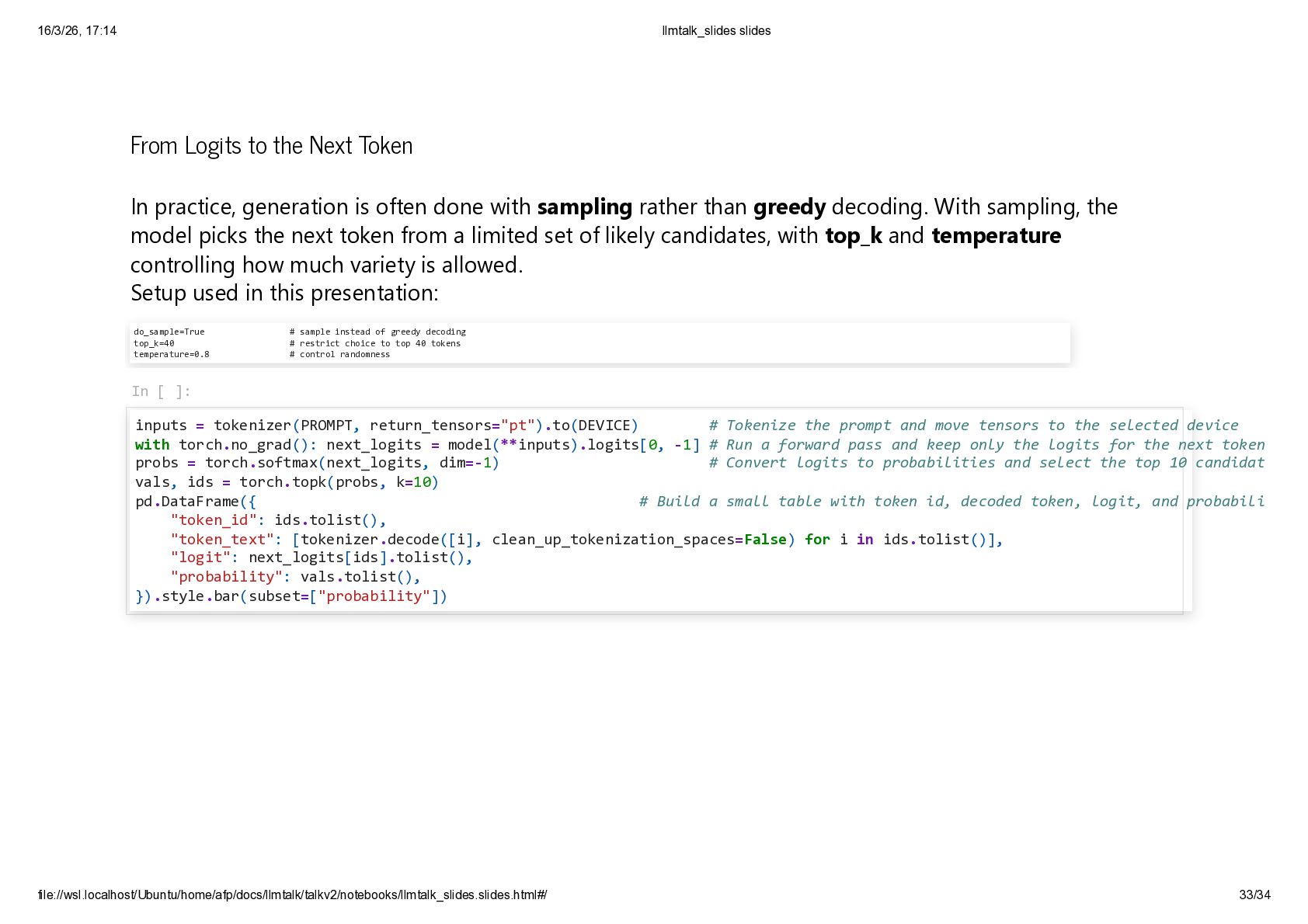{kind=link}
{kind=link}