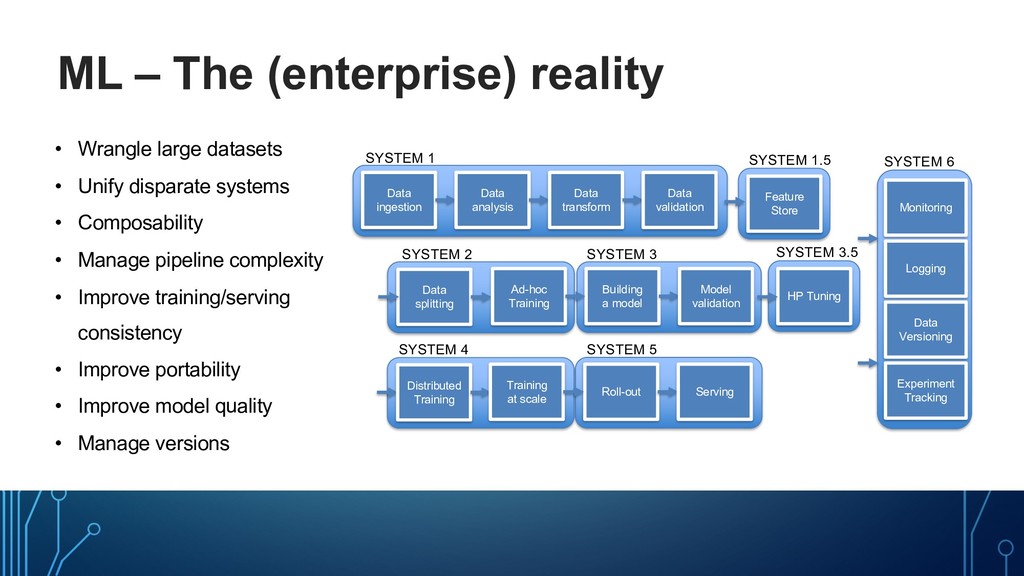
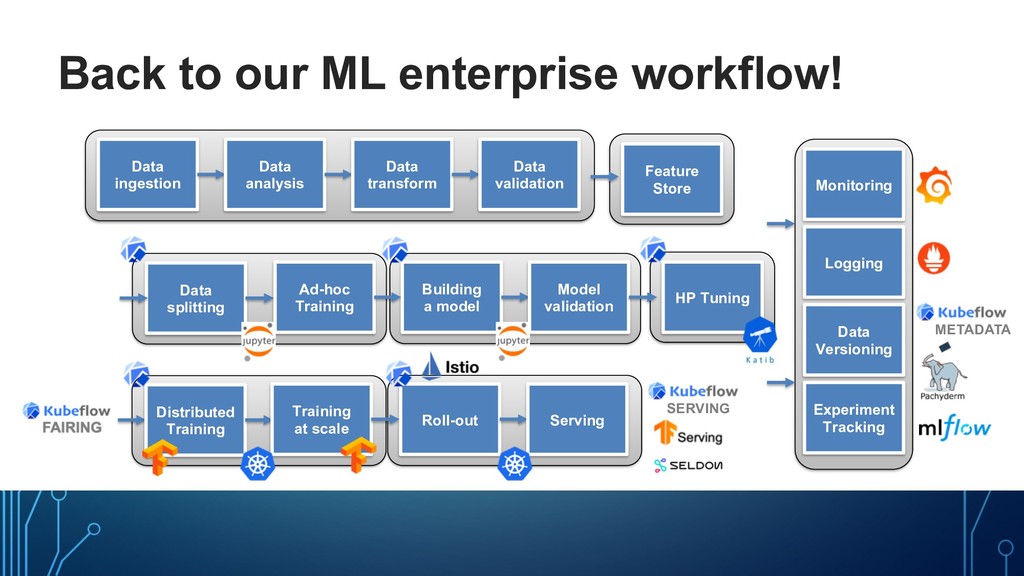
Unify disparate systems • Composability • Manage pipeline complexity • Improve training/serving consistency • Improve portability • Improve model quality • Manage versions Building a model Data ingestion Data analysis Data transform Data validation Data splitting Ad-hoc Training Model validation Logging Roll-out Serving Monitoring Distributed Training Training at scale Data Versioning HP Tuning Experiment Tracking Feature Store SYSTEM 1 SYSTEM 2 SYSTEM 3 SYSTEM 4 SYSTEM 5 SYSTEM 6 SYSTEM 3.5 SYSTEM 1.5
schedule and monitor workflows. The Kubeflow project is dedicated to making deployments of machine learning (ML) workflows on Kubernetes simple, portable and scalable. TensorFlow Extended (TFX) is an end-to-end platform for deploying production ML pipelines. MLflow is an open source platform to manage the ML lifecycle, including experimentation, reproducibility and deployment. https://airflow.apache.org/ https://www.kubeflow.org/ https://www.tensorflow.org/ tfx https://mlflow.org/
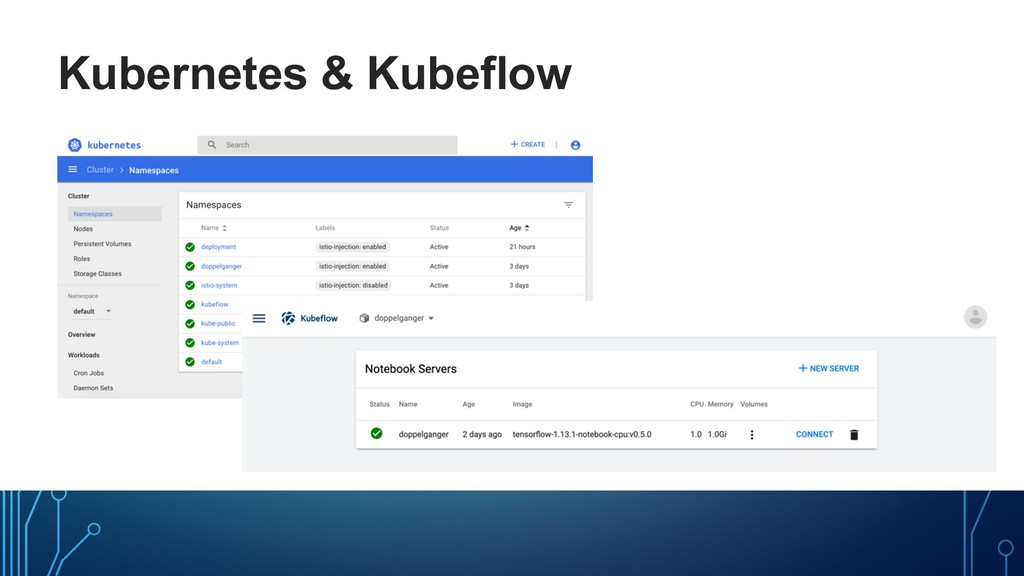
local – dev – test – prod – cloud • Use k8s to manage ML tasks • CRDs (UDTs) for distributed training • Adopt k8s patterns • Microservices • Manage infrastructure declaratively • Support for multiple ML frameworks • Tensorflow, Pytorch, Scikit, Xgboost, etc. Machine Learning on Kubernetes
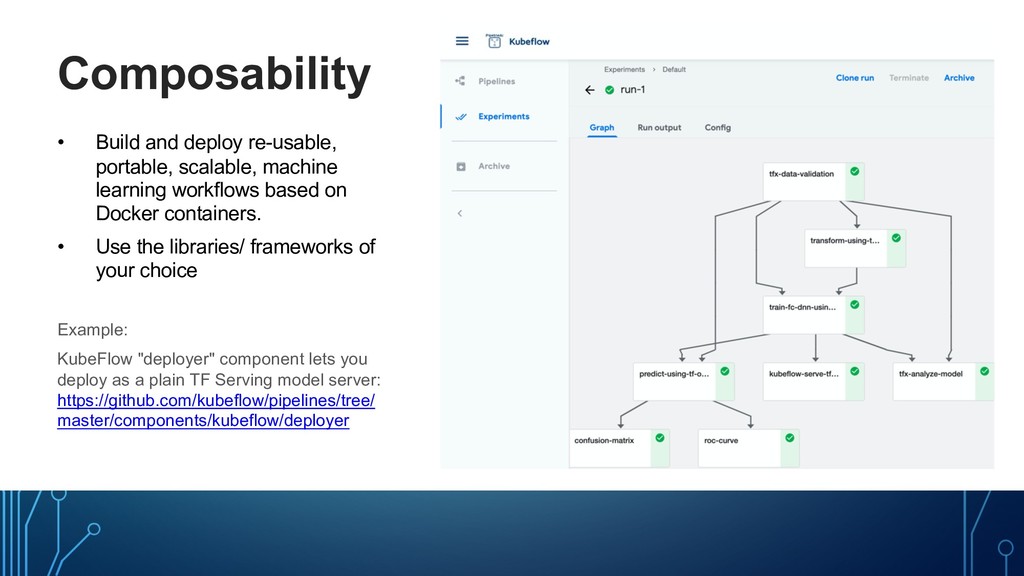
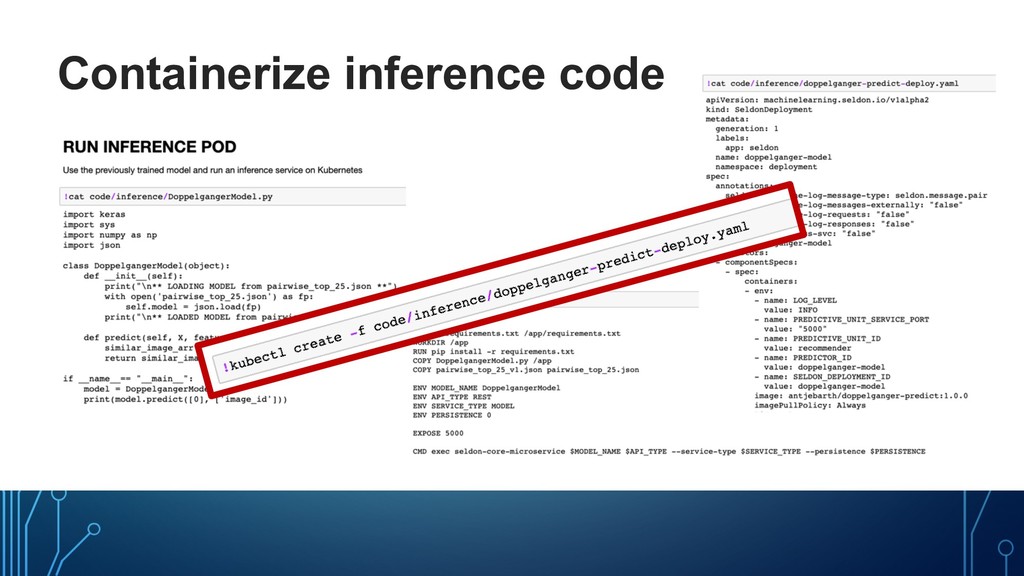
workflows based on Docker containers. • Use the libraries/ frameworks of your choice Example: KubeFlow "deployer" component lets you deploy as a plain TF Serving model server: https://github.com/kubeflow/pipelines/tree/ master/components/kubeflow/deployer
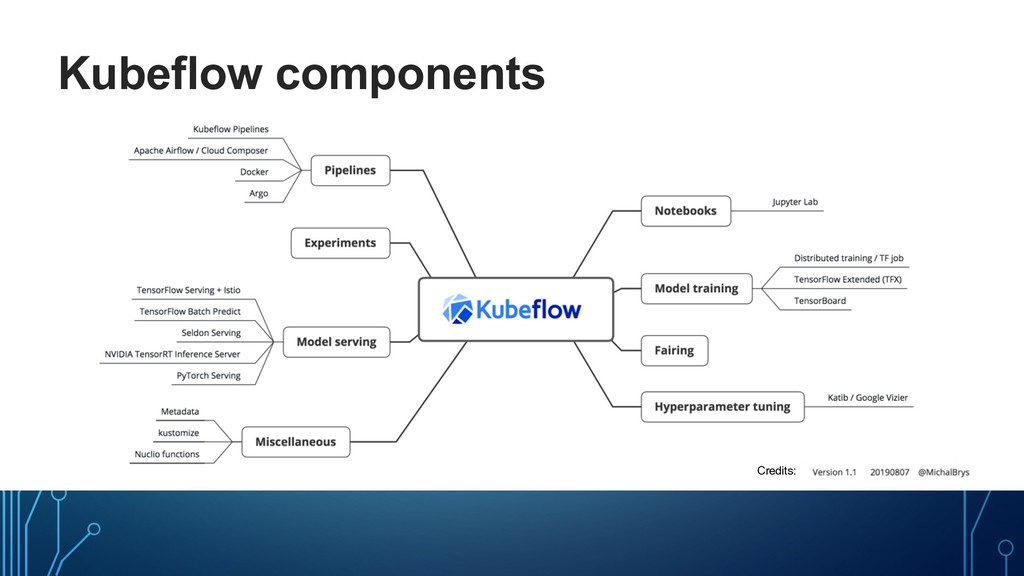
model Data ingestion Data analysis Data transform Data validation Data splitting Ad-hoc Training Model validation Logging Roll-out Serving Monitoring Distributed Training Training at scale Data Versioning HP Tuning Experiment Tracking Feature Store
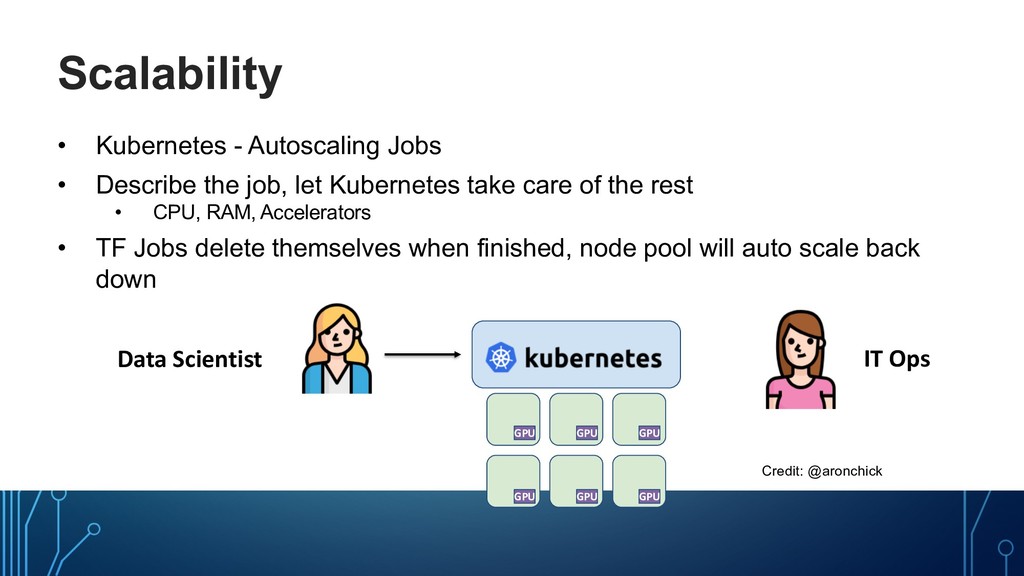
let Kubernetes take care of the rest • CPU, RAM, Accelerators • TF Jobs delete themselves when finished, node pool will auto scale back down Model works great! But I need six nodes. Data Scientist IT Ops Credit: @aronchick
let Kubernetes take care of the rest • CPU, RAM, Accelerators • TF Jobs delete themselves when finished, node pool will auto scale back down Data Scientist IT Ops apiVersion: "kubeflow.org/v1alpha1" kind: "TFJob" spec: replicaSpecs: replicas: 6 CPU: 1 GPU: 1 containers: gcr.io/myco/myjob:1.0 Credit: @aronchick
let Kubernetes take care of the rest • CPU, RAM, Accelerators • TF Jobs delete themselves when finished, node pool will auto scale back down Data Scientist IT Ops GPU GPU GPU GPU GPU GPU Credit: @aronchick
let Kubernetes take care of the rest • CPU, RAM, Accelerators • TF Jobs delete themselves when finished, node pool will auto scale back down Job’s done! Data Scientist IT Ops Credit: @aronchick
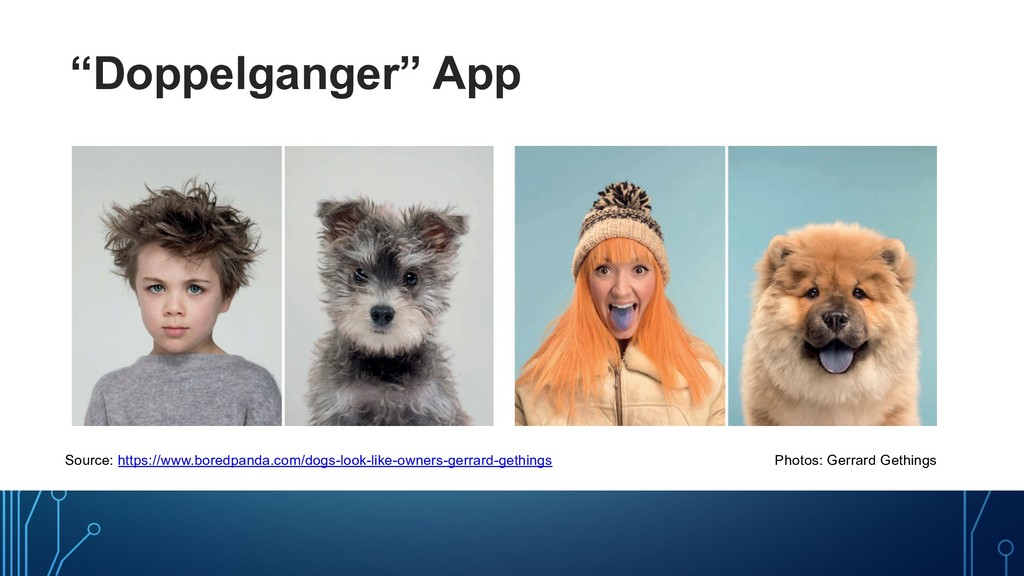
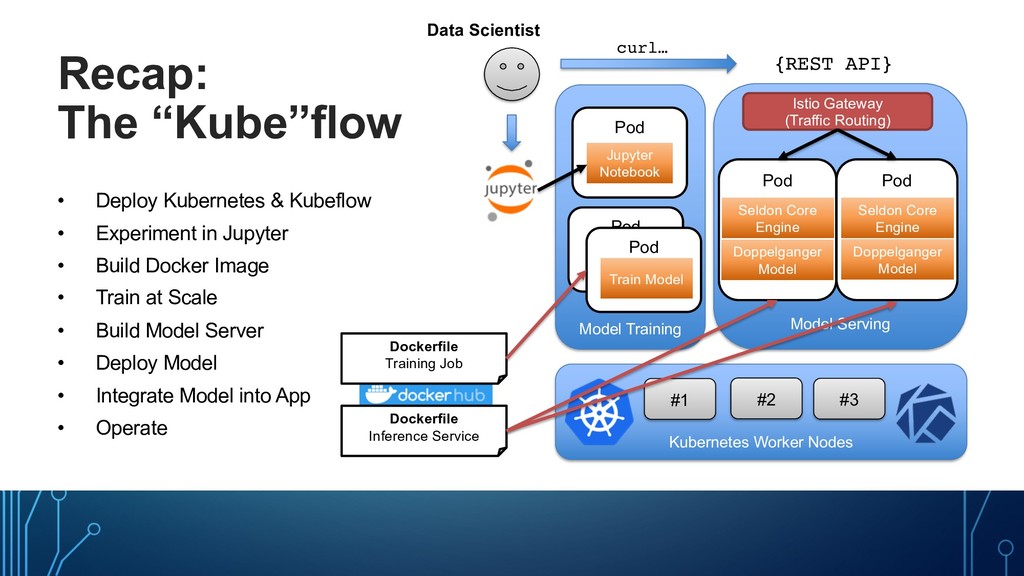
in Jupyter • Build Docker Image • Train at Scale • Build Model Server • Deploy Model • Integrate Model into App • Operate Model Training Model Serving Pod Pod Pod Kubernetes Worker Nodes #1 #2 #3 Jupyter Notebook Seldon Core Engine Seldon Core Engine Doppelganger Model Doppelganger Model Istio Gateway (Traffic Routing) {REST API} curl… Dockerfile Training Job Dockerfile Inference Service Data Scientist Pod Train Model Pod Train Model
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Run predictions curl http://c0198e9d-istiosystem-istio-2af2-1928351968.eu-central- 1.elb.amazonaws.com/seldon/deployment/doppelganger- model/api/v0.1/predictions -d '{"data":{"ndarray":[[0]]}}' -H "Content-Type:](https://files.speakerdeck.com/presentations/843de53c780c4a9f94e96b7d9f64f327/slide_40.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}