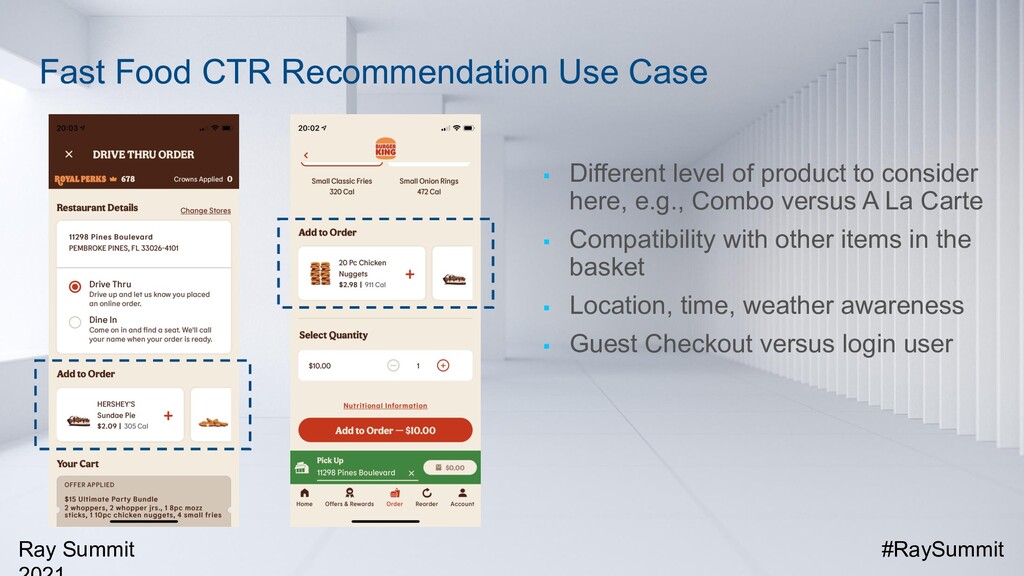
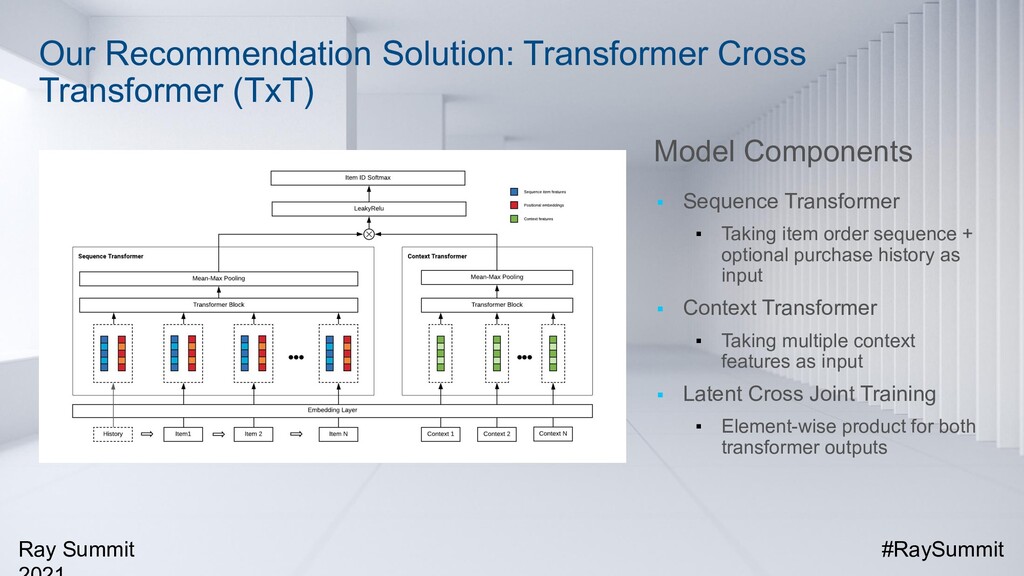
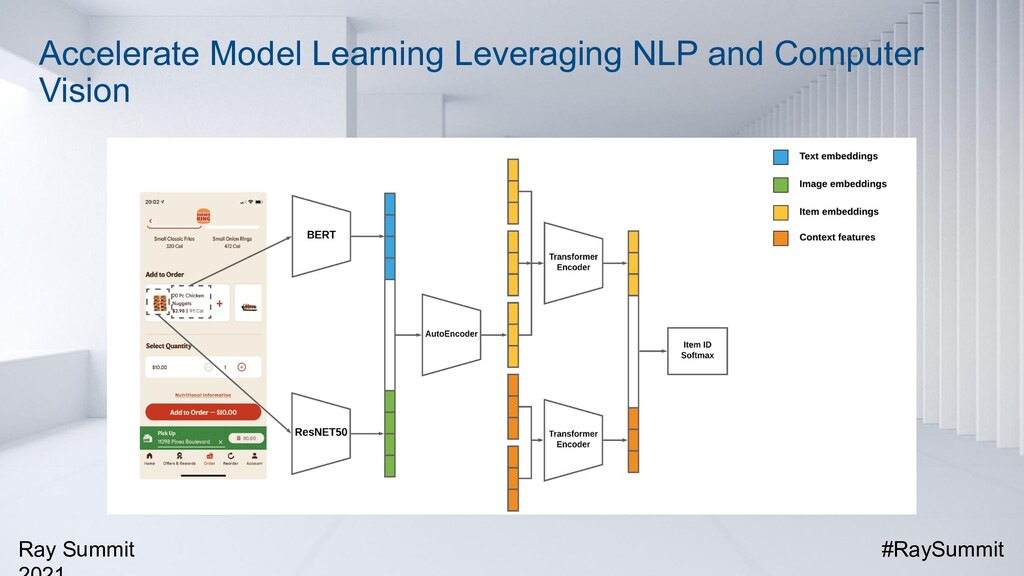
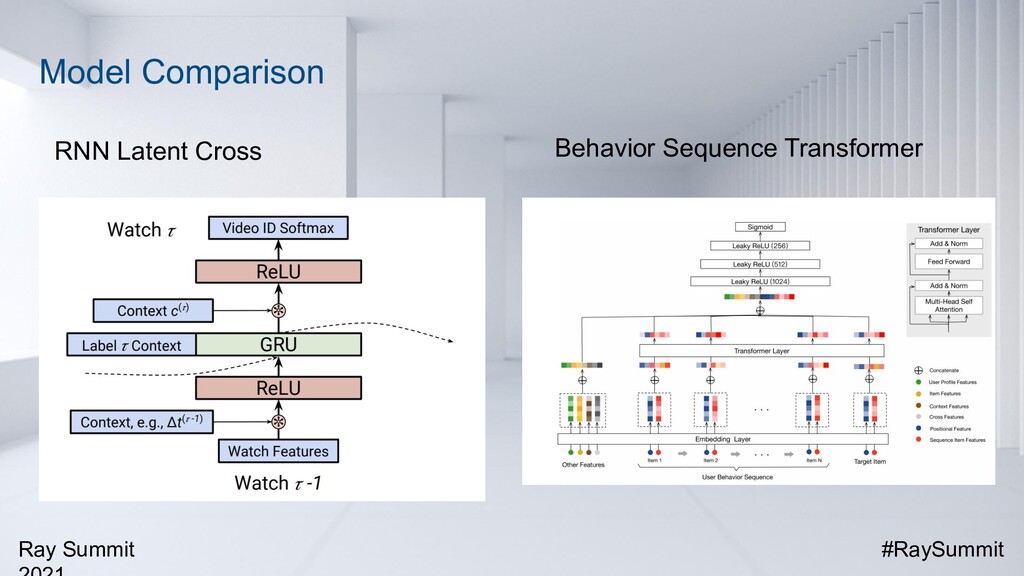
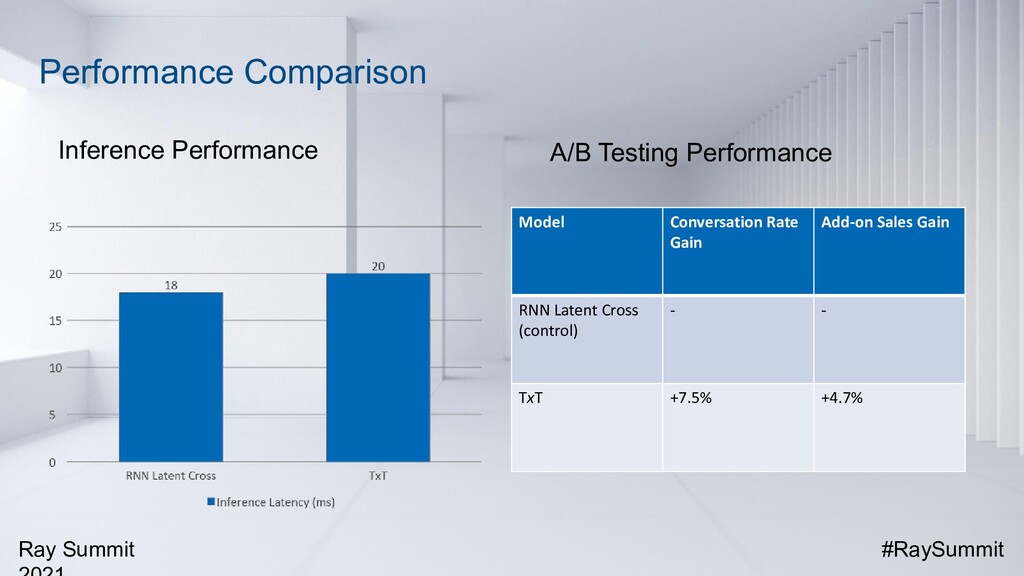
For fast food recommendation, user behavior sequences and context features (such as time, weather, and location) are both important factors to be taken into consideration. At Burger King, we have developed a new state-of-the-art recommendation model called Transformer Cross Transformer (TxT). It applies Transformer encoders to capture both user behavior sequences and complicated context features and combines both transformers through the latent cross for joint context-aware fast food recommendations. Online A/B testings on mobile apps show that TxT can significantly lift the Click-Through Rate (CTR) compared with existing methods results. TxT has also been successfully applied to other fast food recommendation use cases outside of Burger King.
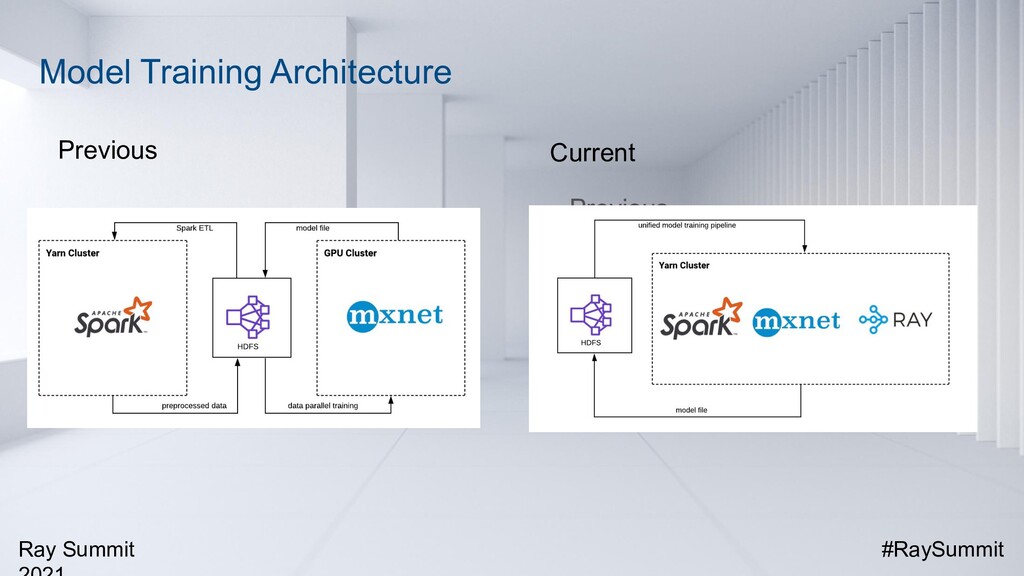
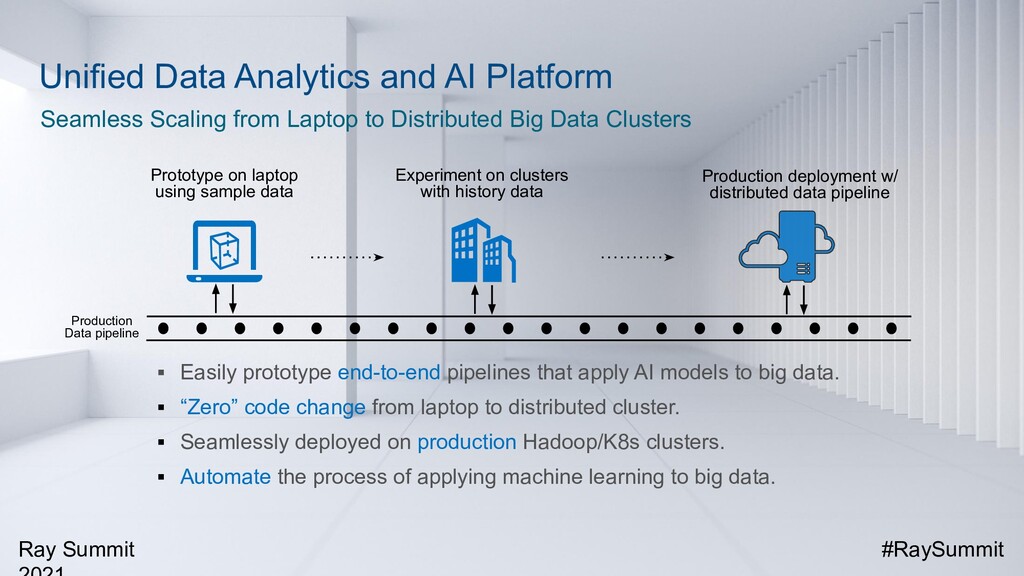
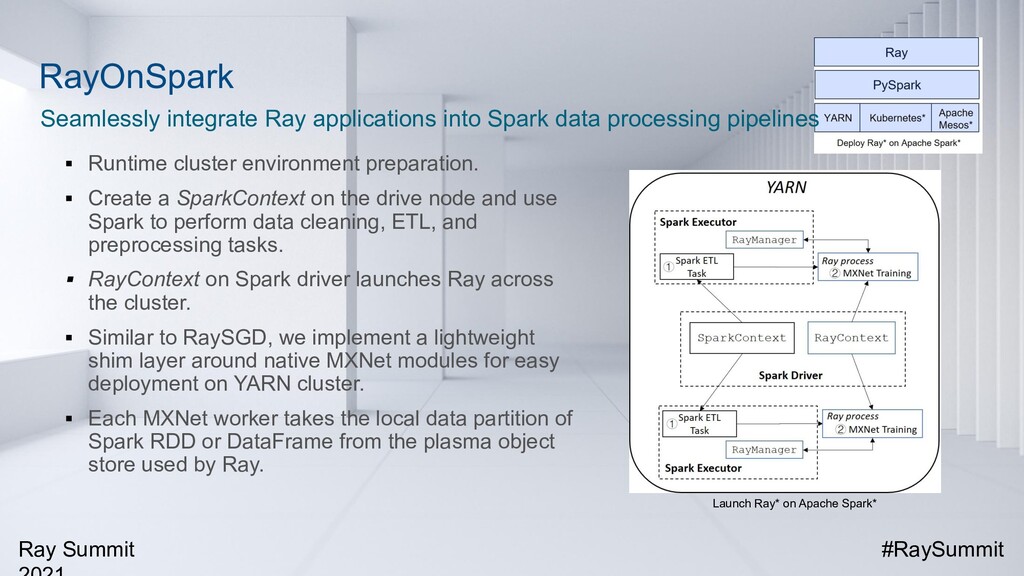
In addition, we have built an end-to-end recommendation pipeline leveraging Ray, Apache Spark and Apache MXNet, which integrates data processing (with Spark) and distributed training (with MXNet and Ray) into a unified data analytics and AI pipeline, running on the same big data cluster where the data is stored and processed. Such a unified system has been proven to be efficient, scalable, and easy to maintain in the production environment.
In this session, we will elaborate on our model topology and discuss the implementation details of our end-to-end recommendation pipeline. We will also share our practical experience in successfully building such a mobile order recommendation system with Ray and Spark on big data platforms.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}