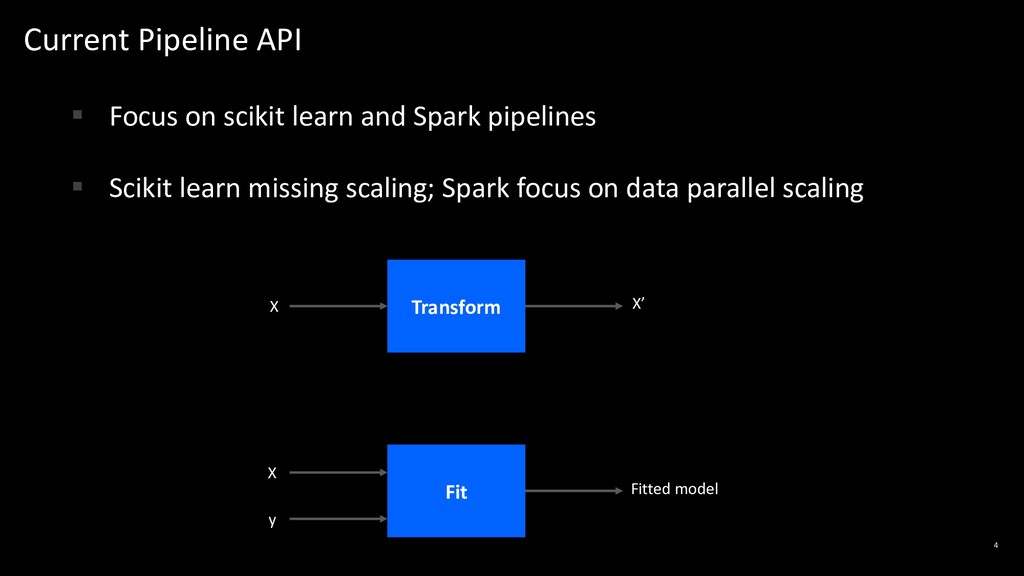
Pipelines have become ubiquitous, as the need for stringing multiple functions to compose applications has gained adoption and popularity. Common pipeline abstractions such as "fit" and "transform" are even shared across divergent platforms such as Python Scikit-Learn and Apache Spark.
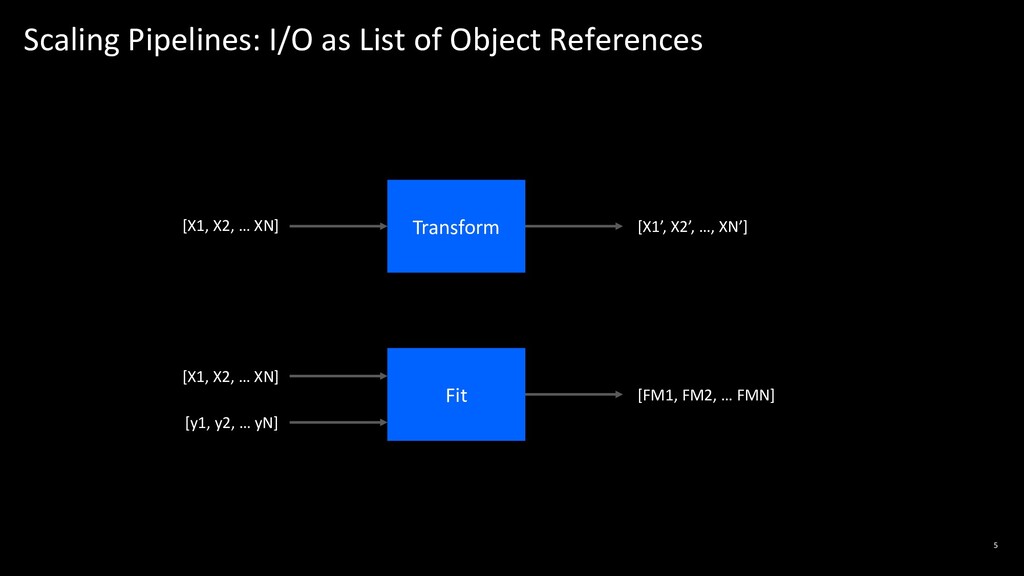
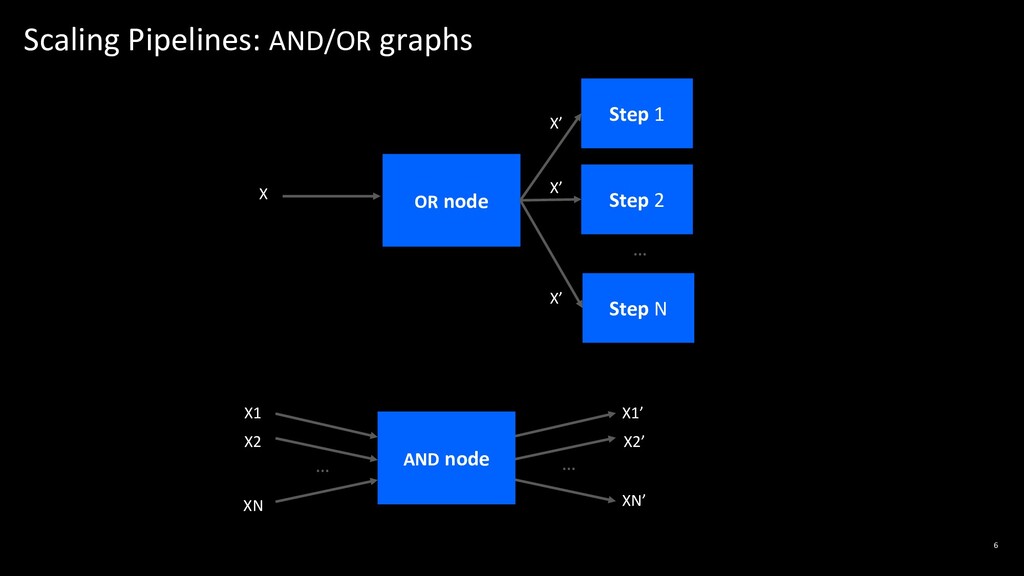
Scaling pipelines at the level of simple functions is desirable for many AI applications, however is not directly supported by Ray's parallelism primitives. In this talk, Raghu will describe a pipeline abstraction that takes advantage of Ray's compute model to efficiently scale arbitrarily complex pipeline workflows. He will demonstrate how this abstraction cleanly unifies pipeline workflows across multiple platforms such as Scikit-Learn and Spark, and achieves nearly optimal scale-out parallelism on pipelined computations.
Attendees will learn how pipelined workflows can be mapped to Ray's compute model and how they can both unify and accelerate their pipelines with Ray.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}