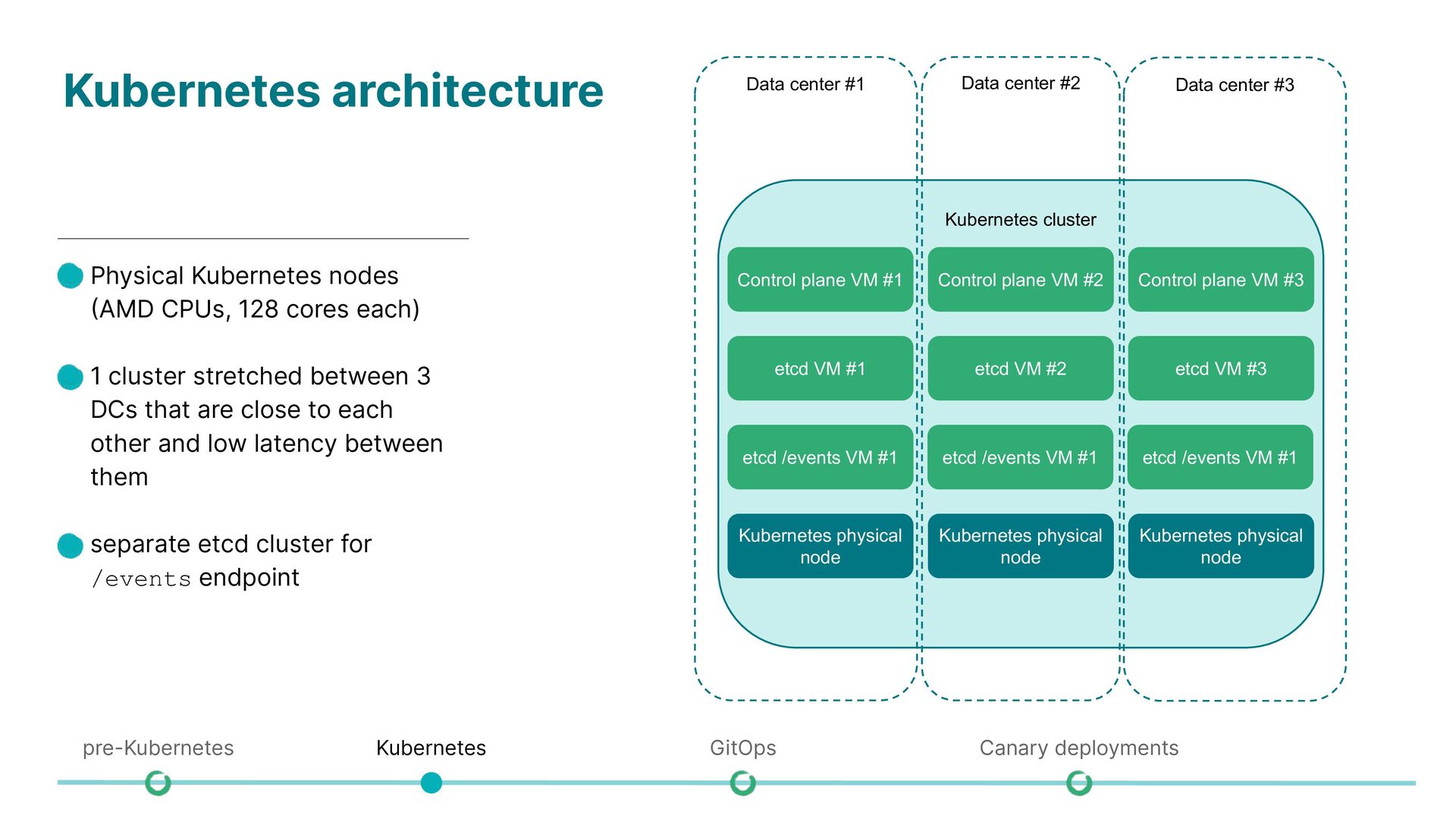
each) • 1 cluster stretched between 3 DCs that are close to each other and low latency between them • separate etcd cluster for /events endpoint Kubernetes cluster Data center #2 Data center #3 Data center #1 Control plane VM #1 Control plane VM #2 Control plane VM #3 etcd VM #1 etcd VM #2 etcd VM #3 etcd /events VM #1 etcd /events VM #1 etcd /events VM #1 Kubernetes physical node Kubernetes physical node Kubernetes physical node pre-Kubernetes Kubernetes GitOps Canary deployments
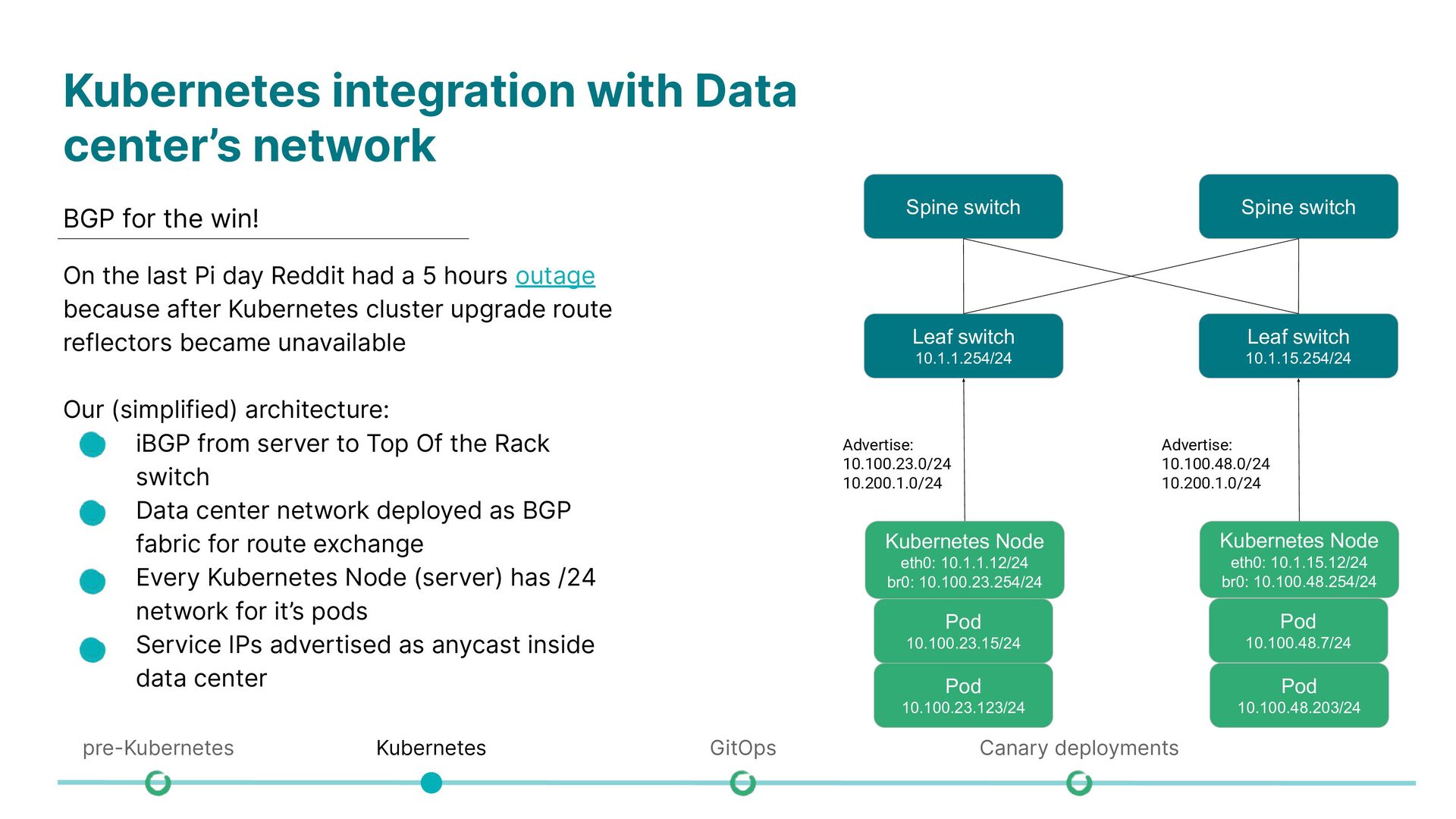
On the last Pi day Reddit had a 5 hours outage because after Kubernetes cluster upgrade route reflectors became unavailable Our (simplified) architecture: • iBGP from server to Top Of the Rack switch • Data center network deployed as BGP fabric for route exchange • Every Kubernetes Node (server) has /24 network for it’s pods • Service IPs advertised as anycast inside data center Leaf switch 10.1.1.254/24 Spine switch Spine switch Leaf switch 10.1.15.254/24 Kubernetes Node eth0: 10.1.1.12/24 br0: 10.100.23.254/24 Pod 10.100.23.15/24 Pod 10.100.23.123/24 Kubernetes Node eth0: 10.1.15.12/24 br0: 10.100.48.254/24 Pod 10.100.48.7/24 Pod 10.100.48.203/24 Advertise: 10.100.23.0/24 10.200.1.0/24 Advertise: 10.100.48.0/24 10.200.1.0/24 pre-Kubernetes Kubernetes GitOps Canary deployments
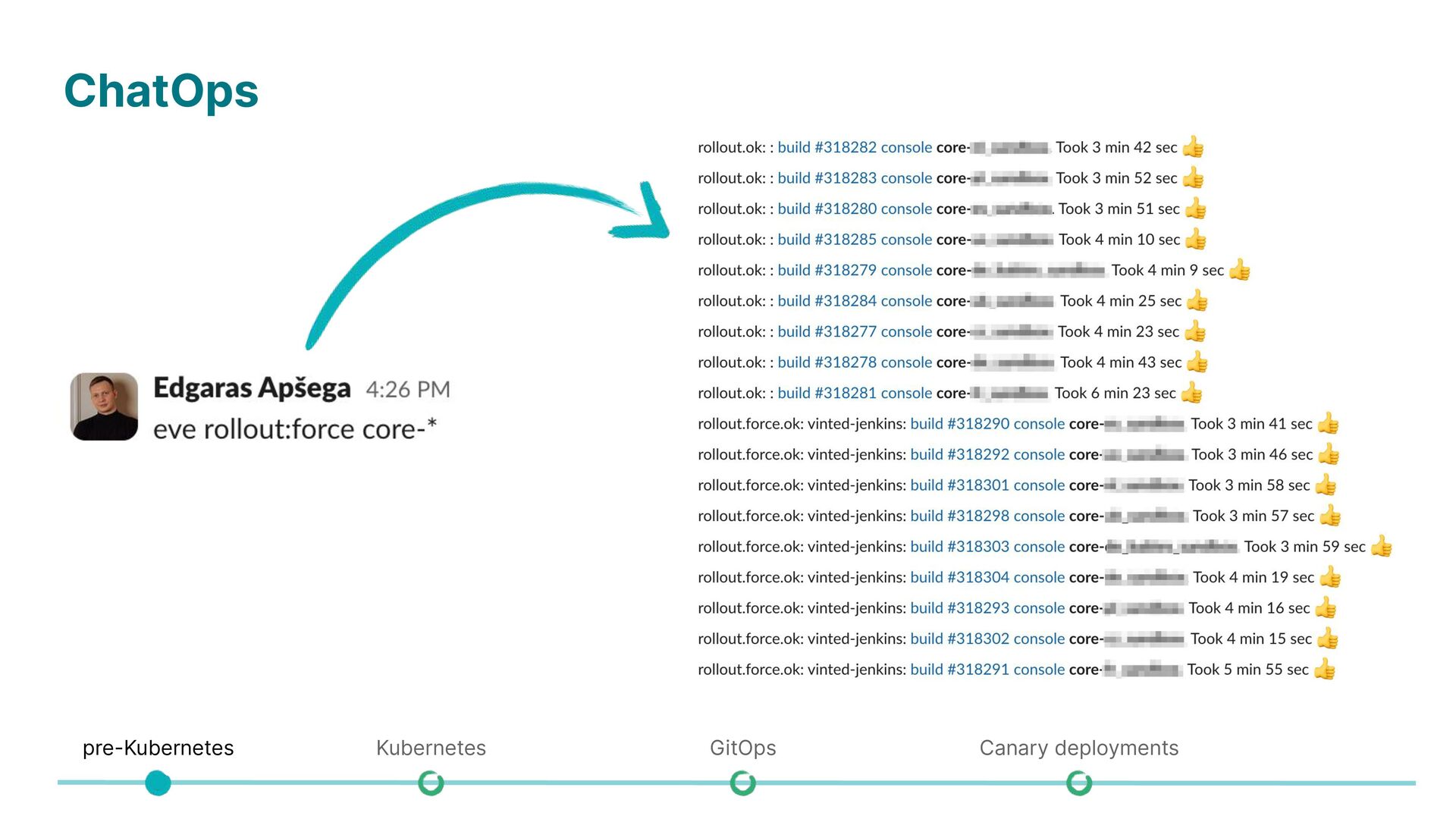
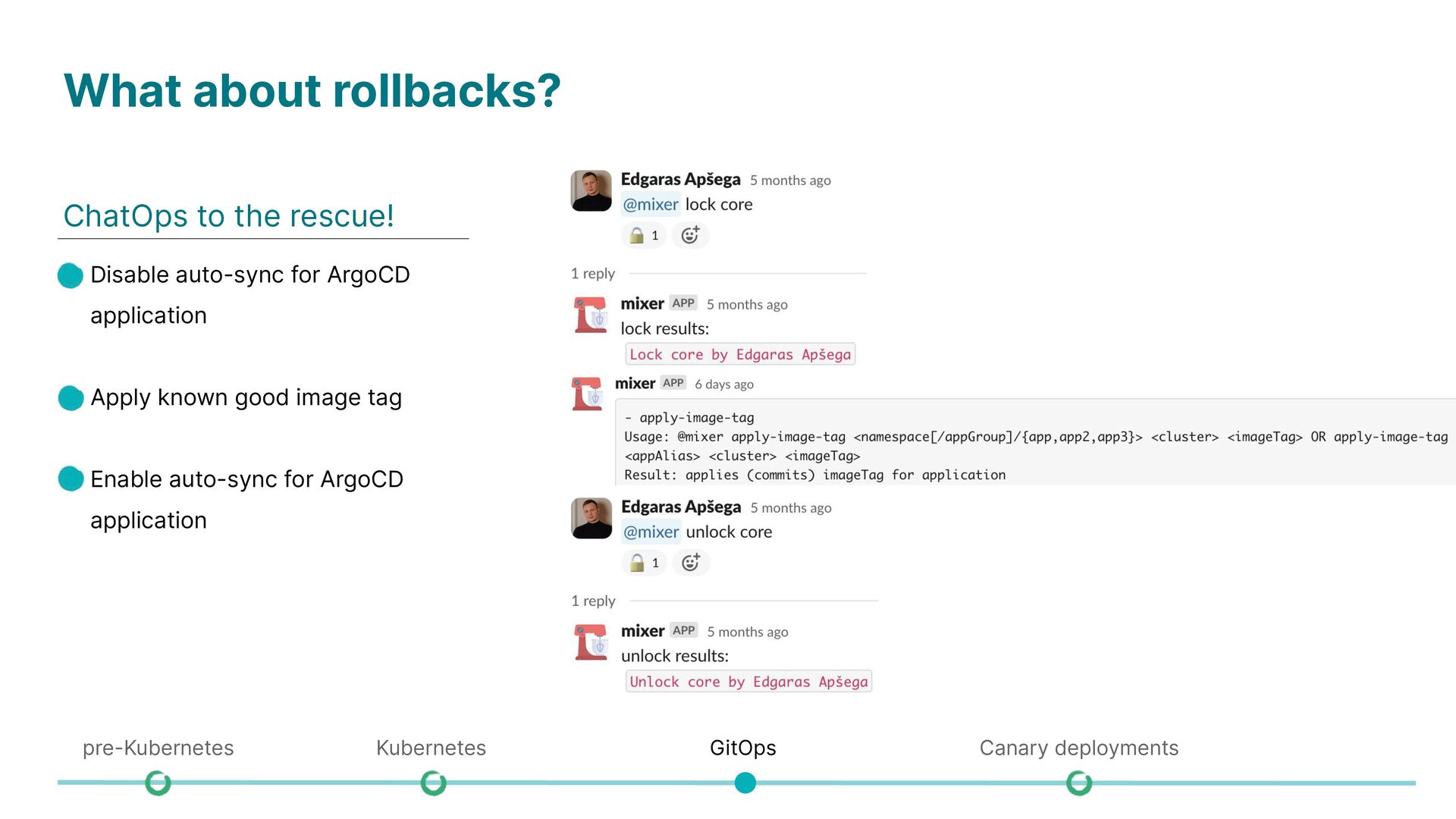
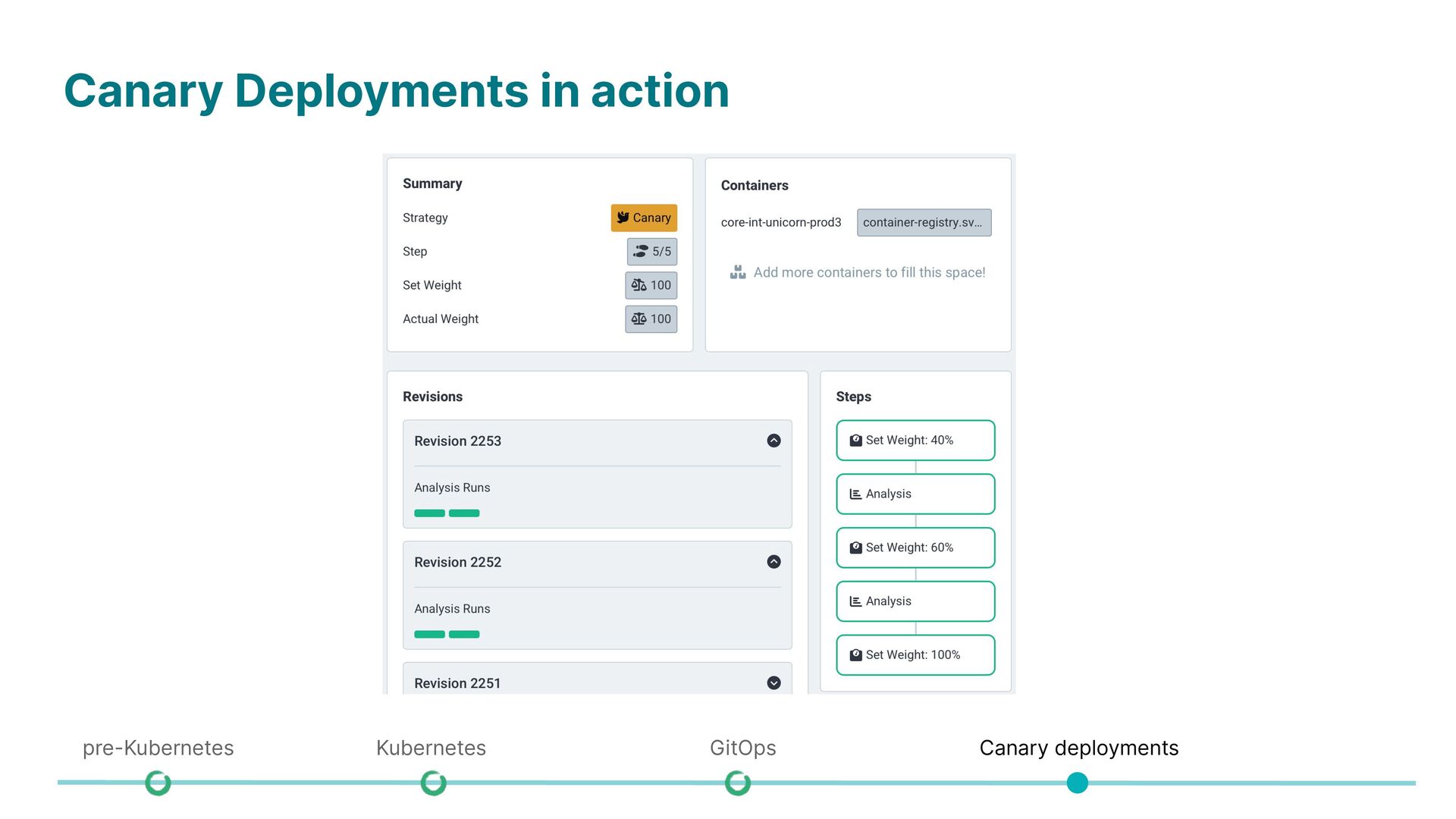
Difficult to manage services running on physical servers (resource isolation, dependency management) • Semi-automatic deployments with using ChatOps • Kubernetes centralizes and automates the management of application isolation, handling resources and dependencies efficiently across physical servers. • Fully automated deployments using GitOps workflow • Automated rollbacks using canary rollouts pre-Kubernetes Kubernetes GitOps Canary deployments
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}