What does Machine Learning In Production mean? What are the challenges? How organizations like Uber, Amazon, Google have built their Machine Learning Pipeline? A survey of the Machine Learning In Production Landscape as of July 2018
is in production it starts degrading • Same model rarely gets deployed twice • It's hard to know how well the model is doing • Often, the real modeling work only starts in production Source : https://www.slideshare.net/DavidTalby/when-models-go-rogue-hard-earned-lessons-about-using- machine-learning-in-production
with historical data. Re-train to keep it fresh. • Online • Model is constantly being updated as new data arrives. • Predictions • Batch • Based on its input data, generates a table of predictions. Schedule a service to run regularly & output predictions to DB. • On demand • Predictions being made in real-time using input data that is available at time prediction. Web Service, Real Time Streaming Analytics.
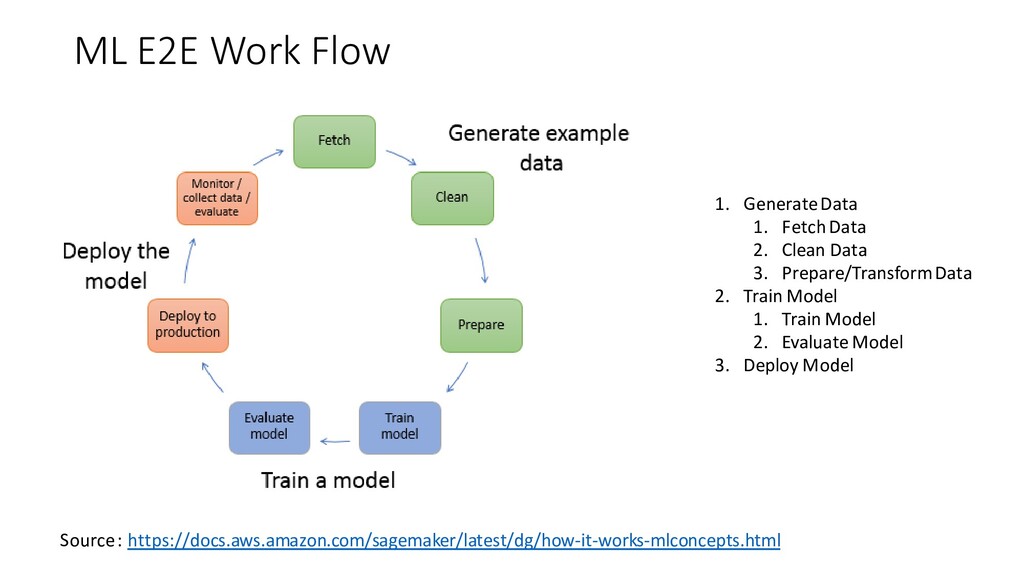
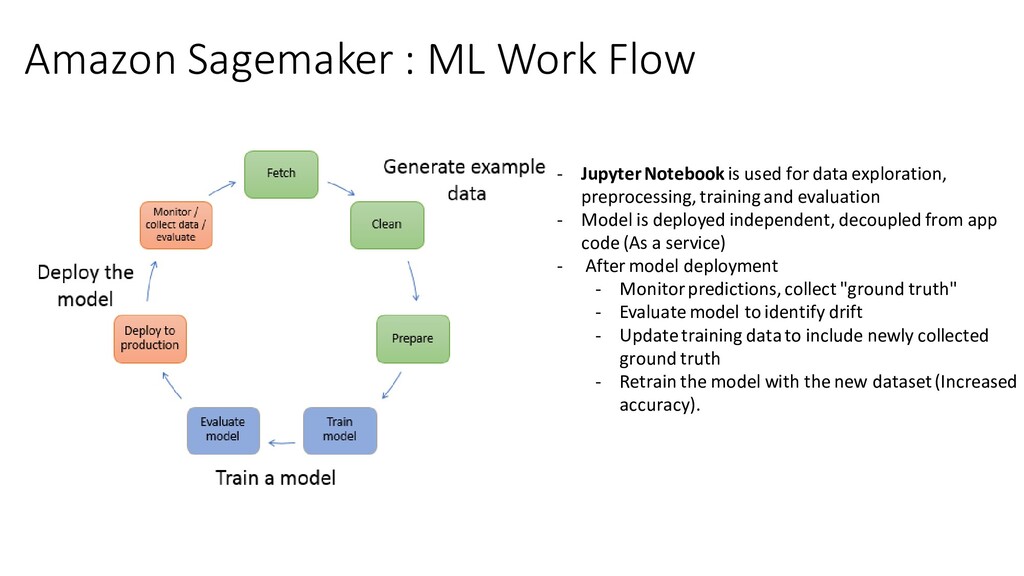
2. Clean Data 3. Prepare/Transform Data 2. Train Model 1. Train Model 2. Evaluate Model 3. Deploy Model Source : https://docs.aws.amazon.com/sagemaker/latest/dg/how-it-works-mlconcepts.html
for data exploration, preprocessing, training and evaluation - Model is deployed independent, decoupled from app code (As a service) - After model deployment - Monitor predictions, collect "ground truth" - Evaluate model to identify drift - Update training data to include newly collected ground truth - Retrain the model with the new dataset (Increased accuracy).
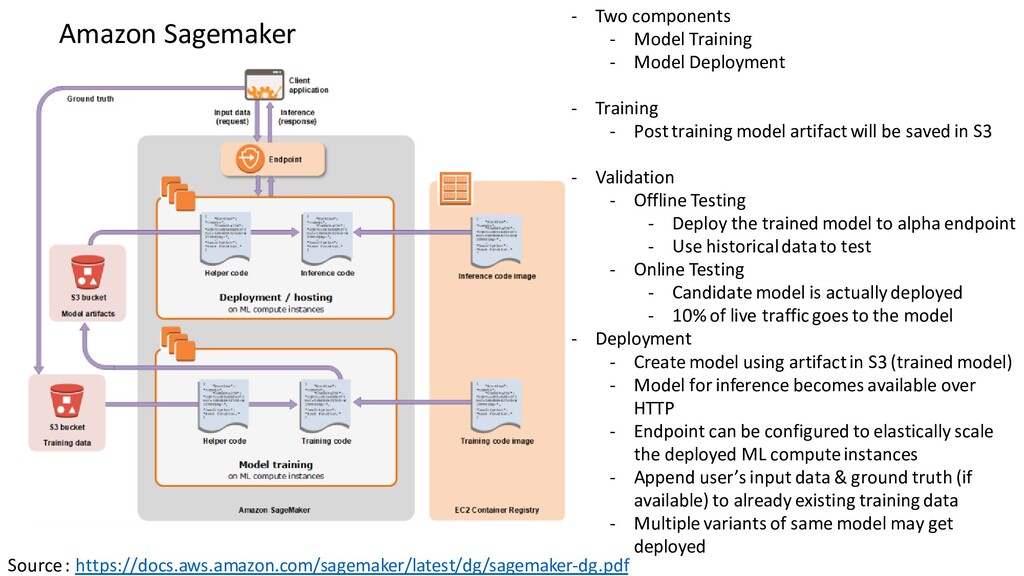
Deployment - Training - Post training model artifact will be saved in S3 - Validation - Offline Testing - Deploy the trained model to alpha endpoint - Use historical data to test - Online Testing - Candidate model is actually deployed - 10% of live traffic goes to the model - Deployment - Create model using artifact in S3 (trained model) - Model for inference becomes available over HTTP - Endpoint can be configured to elastically scale the deployed ML compute instances - Append user’s input data & ground truth (if available) to already existing training data - Multiple variants of same model may get deployed Source : https://docs.aws.amazon.com/sagemaker/latest/dg/sagemaker-dg.pdf
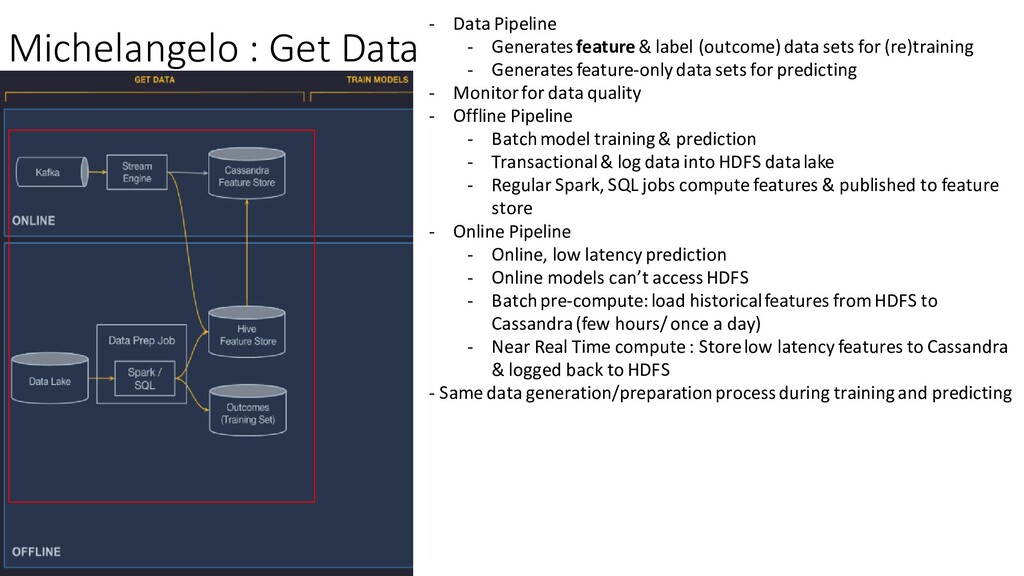
& label (outcome) data sets for (re)training - Generates feature-only data sets for predicting - Monitor for data quality - Offline Pipeline - Batch model training & prediction - Transactional & log data into HDFS data lake - Regular Spark, SQL jobs compute features & published to feature store - Online Pipeline - Online, low latency prediction - Online models can’t access HDFS - Batch pre-compute: load historical features from HDFS to Cassandra (few hours/ once a day) - Near Real Time compute : Store low latency features to Cassandra & logged back to HDFS - Same data generation/preparation process during training and predicting
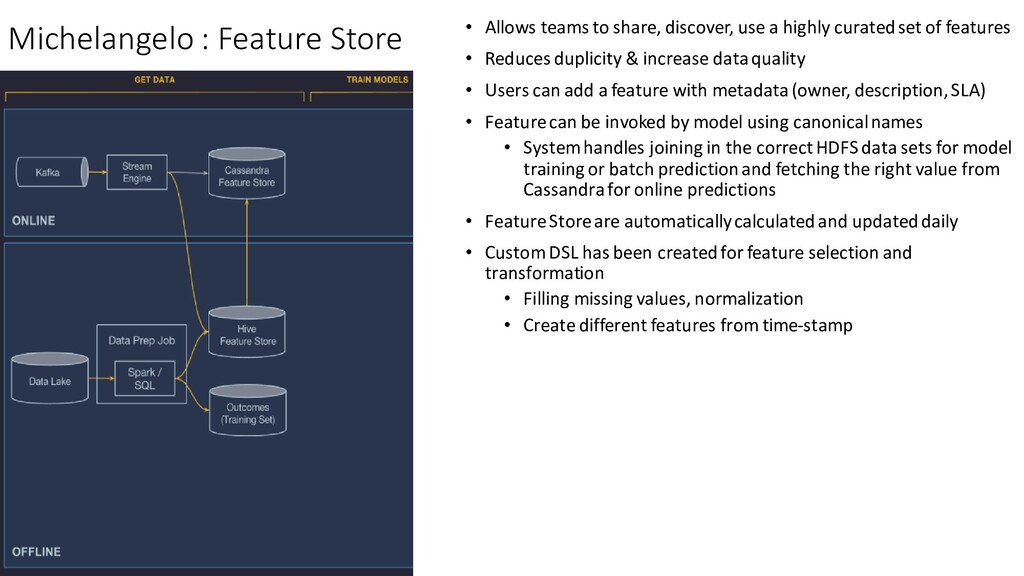
set of features • Reduces duplicity & increase data quality • Users can add a feature with metadata (owner, description, SLA) • Feature can be invoked by model using canonical names • System handles joining in the correct HDFS data sets for model training or batch prediction and fetching the right value from Cassandra for online predictions • Feature Store are automatically calculated and updated daily • Custom DSL has been created for feature selection and transformation • Filling missing values, normalization • Create different features from time-stamp Michelangelo : Feature Store
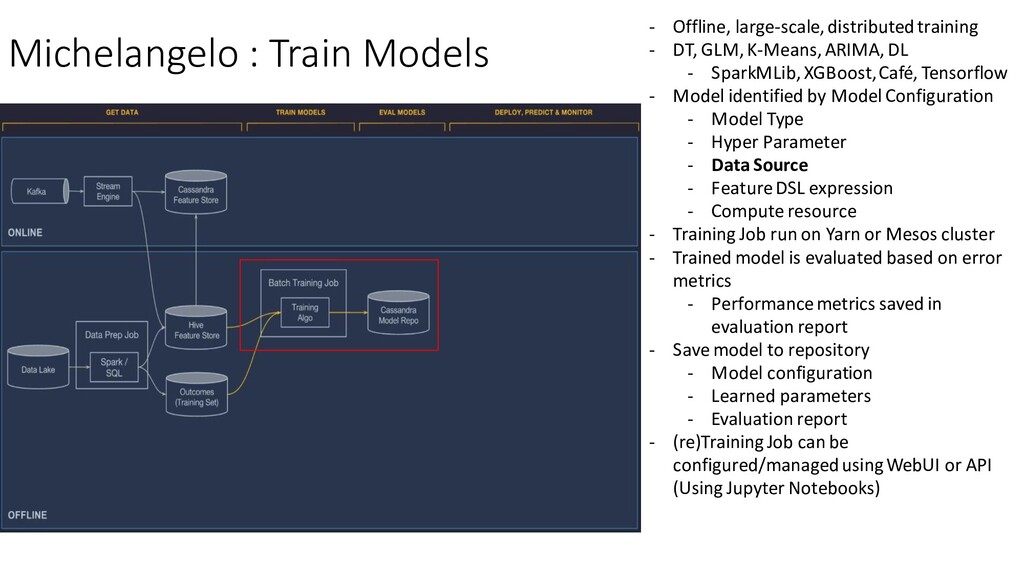
DT, GLM, K-Means, ARIMA, DL - SparkMLib, XGBoost, Café, Tensorflow - Model identified by Model Configuration - Model Type - Hyper Parameter - Data Source - Feature DSL expression - Compute resource - Training Job run on Yarn or Mesos cluster - Trained model is evaluated based on error metrics - Performance metrics saved in evaluation report - Save model to repository - Model configuration - Learned parameters - Evaluation report - (re)Training Job can be configured/managed using WebUI or API (Using Jupyter Notebooks)
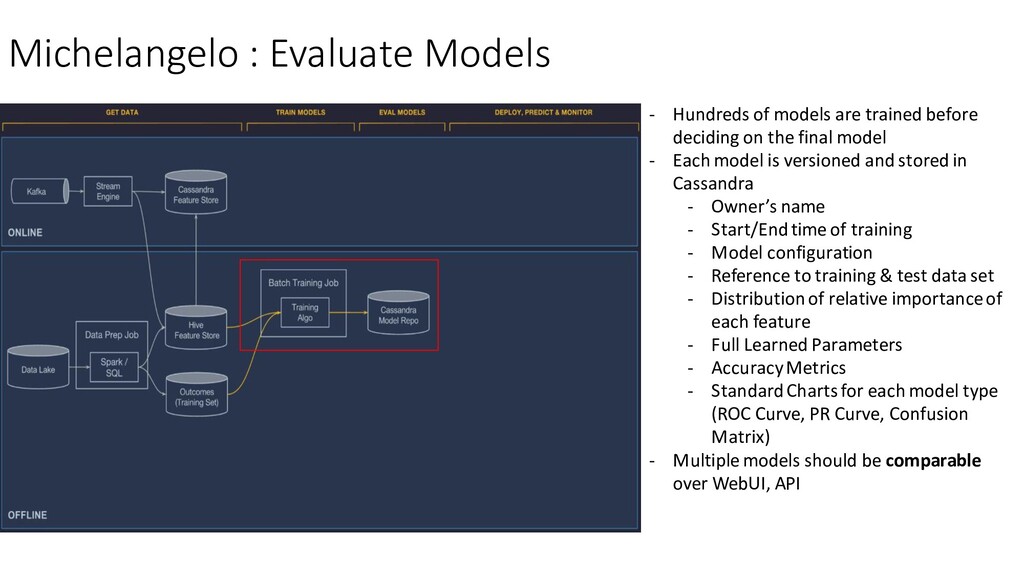
before deciding on the final model - Each model is versioned and stored in Cassandra - Owner’s name - Start/End time of training - Model configuration - Reference to training & test data set - Distribution of relative importance of each feature - Full Learned Parameters - Accuracy Metrics - Standard Charts for each model type (ROC Curve, PR Curve, Confusion Matrix) - Multiple models should be comparable over WebUI, API
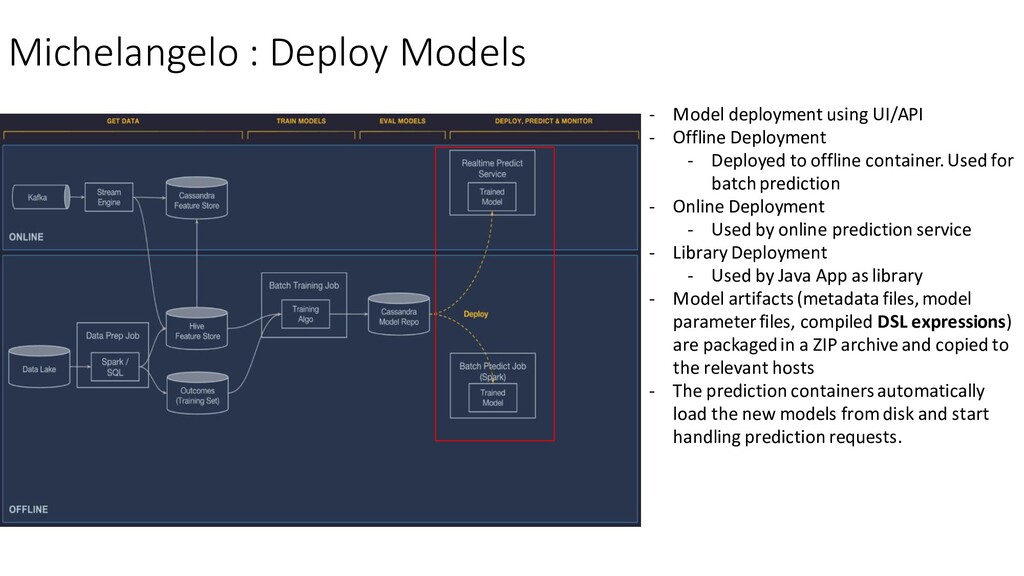
Offline Deployment - Deployed to offline container. Used for batch prediction - Online Deployment - Used by online prediction service - Library Deployment - Used by Java App as library - Model artifacts (metadata files, model parameter files, compiled DSL expressions) are packaged in a ZIP archive and copied to the relevant hosts - The prediction containers automatically load the new models from disk and start handling prediction requests.
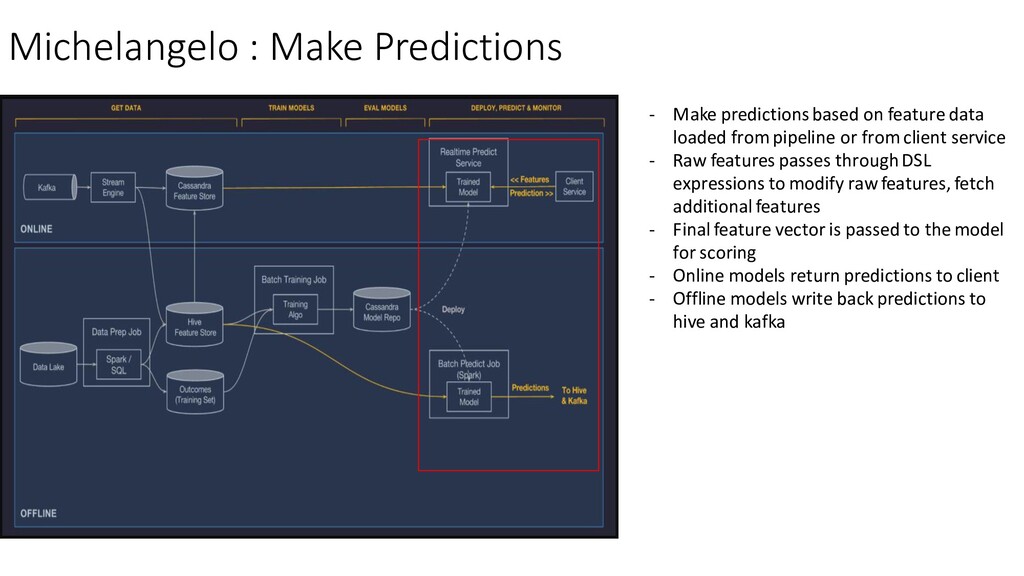
data loaded from pipeline or from client service - Raw features passes through DSL expressions to modify raw features, fetch additional features - Final feature vector is passed to the model for scoring - Online models return predictions to client - Offline models write back predictions to hive and kafka
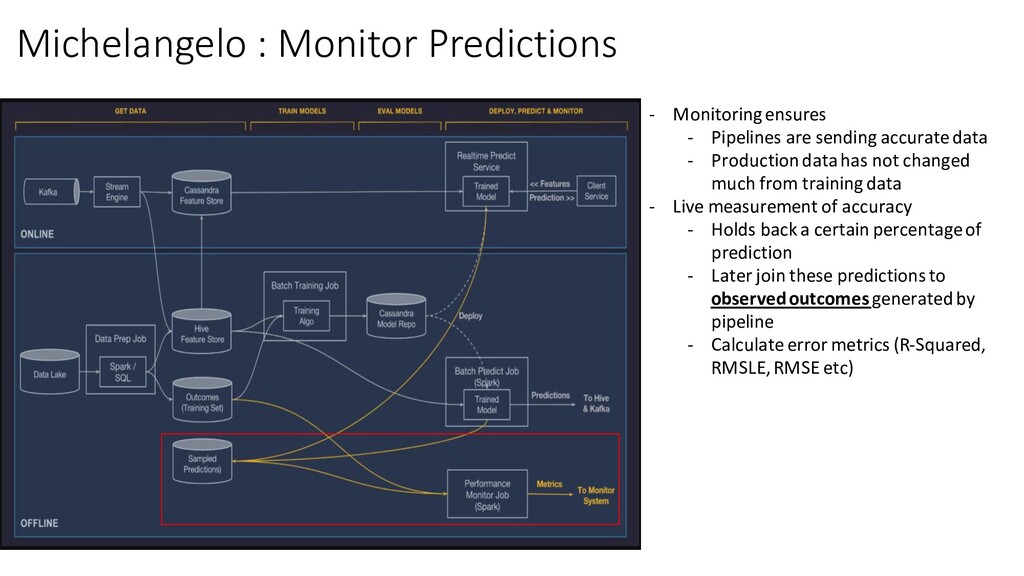
sending accurate data - Production data has not changed much from training data - Live measurement of accuracy - Holds back a certain percentage of prediction - Later join these predictions to observed outcomes generated by pipeline - Calculate error metrics (R-Squared, RMSLE, RMSE etc)
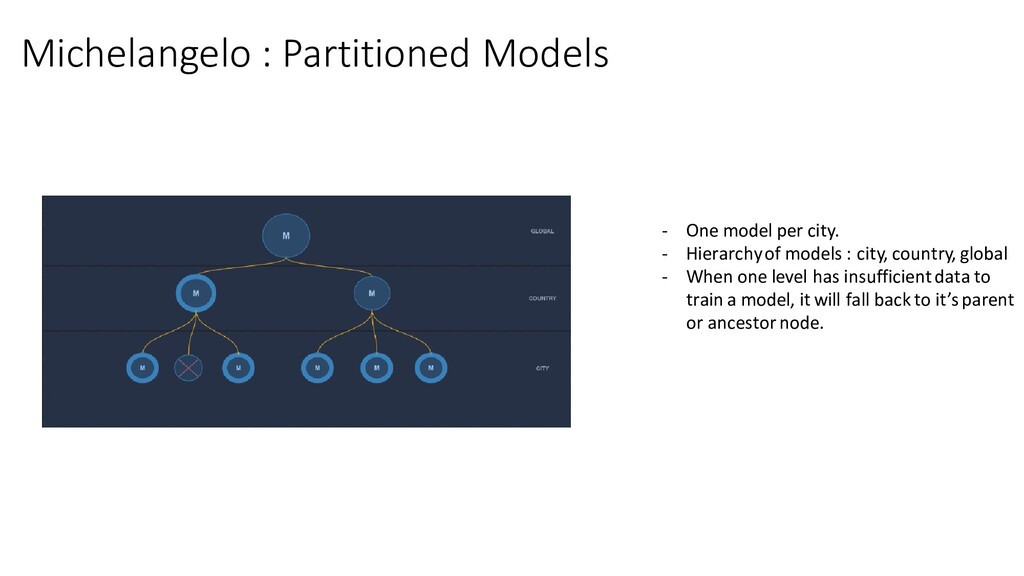
Hierarchy of models : city, country, global - When one level has insufficient data to train a model, it will fall back to it’s parent or ancestor node.
be deployed on a serving container • Transition from old to new models, side by side A/B Testing • A model is specified by UUID & tag (optional) during deployment • Online Model • Client sends feature vector along with model UUID or tag • For tag, model most recently deployed to that tag will make prediction • Batch Model • All deployed models are used to score each batch data set • Prediction records contain the model UUID and optional tag • User can replace an old model with a new model without changing tag • Model gets updated without changing client code • User can upload a new model (new UUID) • Traffic can be gradually switched from old model to new one • A/B testing of models • Users deploy competing models either via UUIDs or tags • Send portions of the traffic to each model • Track performance metrics
stage. Debuggability is important. • Fault tolerance is important • Abstract Machine Learning libraries • Ease of Use : Automating ML WorkFlow through UI. Ability to train, test, deploy models with mouse clicks • ML Systems must be extensible & easy for other systems to interact with programmatically (REST).
based general-purpose machine learning platform implemented at Google [KDD : 2017] • Challenges of building Machine Learning Platforms • One machine learning platform for many different learning tasks (in terms of data representation, storage infrastructure, and machine learning tasks) • Continuous Training and Serving • Continuous training over evolving data (e.g. a moving window over the latest n days) • Human in loop • Simple interface for deployment and monitoring • Production-level reliability and scalability • Resilient to inconsistent data, failures in underlying execution environment • Should be able to handle high data volume during training • Should be able to handle increase in traffic in serving system http://www.kdd.org/kdd2017/papers/view/tfx-a-tensorflow-based-production-scale-machine-learning-platform
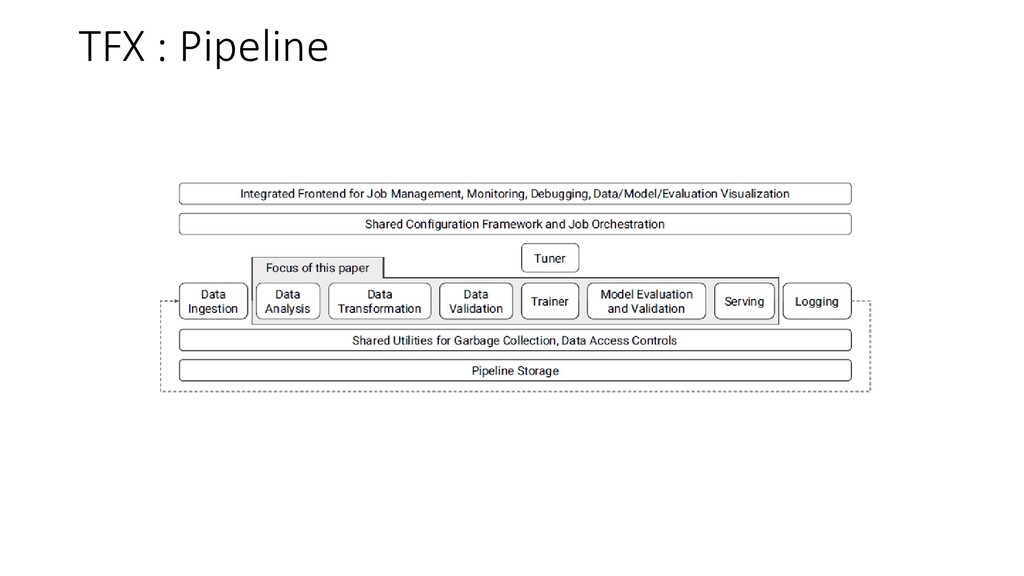
• Understanding data and finding anomalies early is critical for preventing data errors downstream • Rigorous checks for data quality should be a part of any long running development of a machine learning platform • Small bugs in the data can significantly degrade model quality over a period of time in a way that is hard to detect and diagnose TFX : Data Analysis, Transformation & Validation
to the system and generates a set of descriptive statistics on the included features • Statistics about presence of each feature in the data • Number of examples with and without the feature • Distribution of the number of values per example • Statistics over feature values • For continuous features, quantiles, equi-width histograms, mean, standard deviation • For discrete features, top-K values by frequency • Statistics about slices of data (e.g., negative and positive classes) • Cross-feature statistics (correlation and covariance between features)
are there anomalies to be flagged? • Validation is done using a versioned schema • Features present in the data • Expected type of each feature • Expected presence of each feature (minimum count & fraction of examples that must contain feature) • Expected valency of the feature in each example (minimum and maximum number of values) • Expected domain of a feature (Values for a string feature or range for an integer feature) • Validate the properties of specific (training and serving) datasets, flag any deviations from the schema as potential anomalies • Provide actionable suggestions to fix the anomaly • Teams are responsible for maintaining the schema • Users should treat data issues as bugs • Different versions of the schema shows the evolution of the data
production quality models • Often training needs huge datasets (Time & Resource intensive) • Training dataset of 100B data points. Takes several days to train • Warm Starting (Continuous Training) • High Level Model Specification API • Higher level abstraction layer that hides implementation
that automatically evaluates and validates models to ensure that they are "good" before serving them to users • Can help prevent unexpected degradations in the user experience • Avoids real issue in production • Definition of A Good Model • Model is safe to serve • Model should not crash, cause errors in the serving system when being loaded or when sent unexpected inputs • Model shouldn't use too many resources (CPU, RAM) • Has desired production quality • User satisfaction and product health on live traffic • Better measure than the objective function on the training data
of model quality • A/B testing on live traffic is costly and time consuming • Models are evaluated offline on held-out data to determine if they are promising enough to start an online A/B testing • Provides AUC or cost-weighted error • Once satisfied with models' offline performance, A/B testing can be performed with live traffic
Once model is launched in production, automated validation is used to ensure updated model is good • Updated Model receives a small amount of traffic (canary process) • Prediction quality is evaluated by comparing the model quality against a fixed threshold as well as against a baseline model (e.g., the current production model) • Any new model failing these checks is not pushed to serving • Challenges • Canary process will not catch all potential errors. • With changing training data, some variation in models behavior is expected, but is hard to distinguish • Slicing • Useful in both evaluating and validating models • Metrics is computed on a small slice of data with particular feature value (e.g., country=="US") • Metrics on the entire dataset can fail to reflect performance on small slices TFX : Model Validation
learned models to be deployed in production environments • Serving systems for production environments require low latency, high efficiency, horizontal scalability, reliability & robustness • Multitenancy • A single instance of the server to serve multiple machine-learned models concurrently • Performance characteristics of one model has minimal impact on other models TFX : Model Serving
• TensorFlow Serving • Azure ML Service (Not Azure ML Studio) • Azure ML Experimentation • Azure ML Model Management • Azure ML Workbench • MLFlow by Databricks • prediction.io • clipper.ai • SKIL - deeplearning4j • & More…
model re-training. Keep the model fresh. • Save actual data used at prediction time to DB. Keep expanding it. • Use this data for retraining • Evaluate a trained model before deployment • Verify the model crosses a threshold error score on a predefined dataset • Post deployment • Monitor the performance of the model • Business Objective • Error Metrics • Identify cases where the model is struggling • Check if those use cases are needed? • Improve data collection? • Monitor customer feedback to identify cases to improve upon • Monitor distribution of features fed into model at training/prediction time • Identify errors at the data extractors • Nature of the data may be eventually changing • A/B Testing • Between training and deployment, there should be staging environment
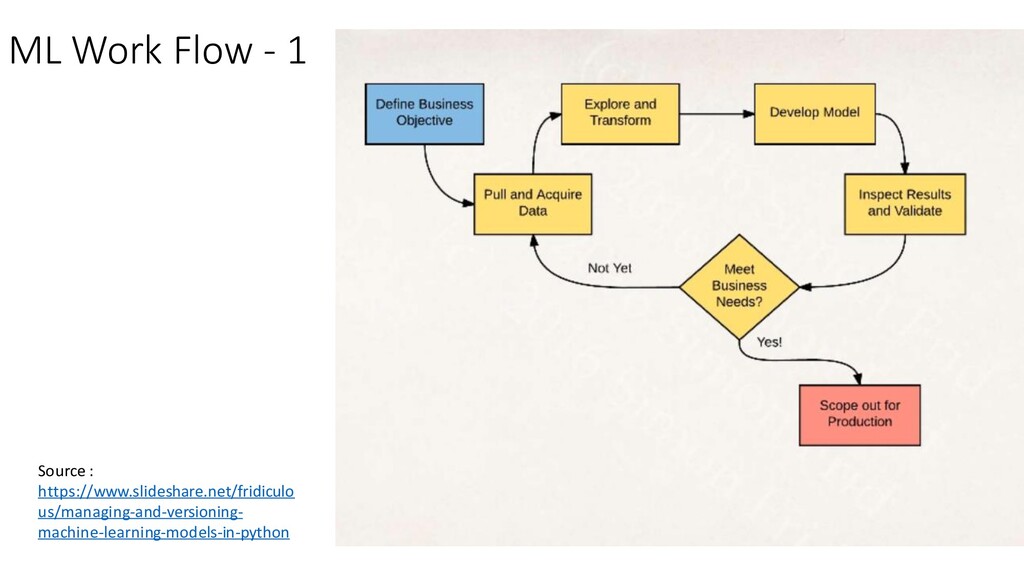
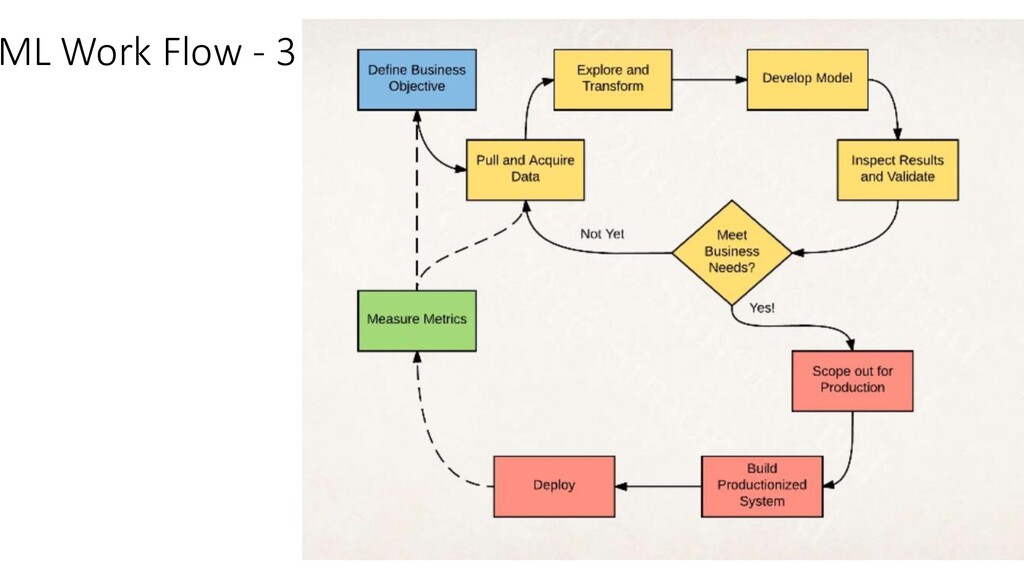
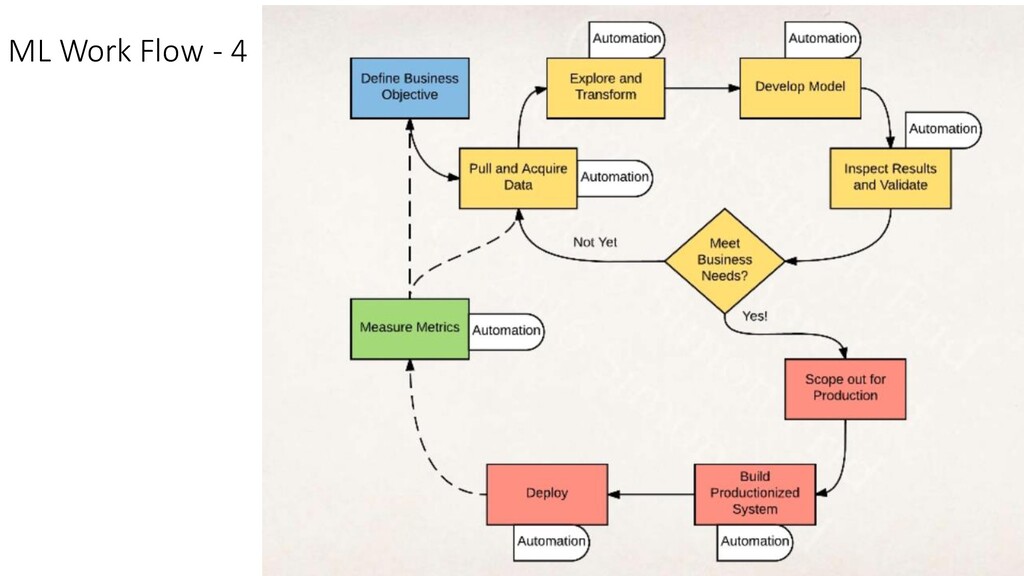
we going to solve? • Description • What kind of ML (Batch/Online)? • Scalability? • How to ensure quality of labeled data? • How do I find out the effectiveness of the model? • What do we need? • Complete ML pipeline covering the whole lifecycle OR • Just separate model training from prediction using existing frameworks • How do we want to use ML (As a service or as a library)? • How important is reproducibility & interpretation? • How to handle customer specific data/behavior?
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}