free large-scale Japanese speech corpus for end-to-end speech synthesis," arXiv preprint, 1711.00354, 2017. A. Radford, J. W. Kim, T. Xu, G. Brockman, C. McLeavey, and I. Sutskever, “Robust Speech Recognition via Large-Scale Weak Supervision,” Tech. Rep., OpenAI, 2022. A. Baevski, Y. Zhou, A. Mohamed, and M. Auli, “wav2vec 2.0: A framework for self- supervised learning of speech representations,” in Advances in Neural Information Processing Systems (NeurIPS), 2020. S. Takamichi, L. K¨urzinger, T. Saeki, S. Shiota, and S. Watanabe, “Jtubespeech: corpus of japanese speech collected from youtube for speech recognition and speaker verification,” arXiv preprint arXiv:2112.09323, 2021. 1. 2. 3. 4. Copyright 2023 The Asahi Shimbun Company. 26
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![なぜ音声認識に取り組んでいるのか ✔︎ 大手クラウド音声認識APIは、Common Voiceやjsut[1]などのデータセットに 対してWERで9.3%-11.0%に対し、朝日新聞独自の評価データセットに対しては 20.5%と性能が良くなかった。 さらに、アンケートの結果93%のユーザーが大手クラウド音声認識APIに対して 精度の向上を求めていることも判明。 ✔︎ 基本的にオフラインでの文字起こしはできない。今後のサービス像を考えた](https://files.speakerdeck.com/presentations/c7382e9a17224a86a8ce6dca932e3826/slide_13.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
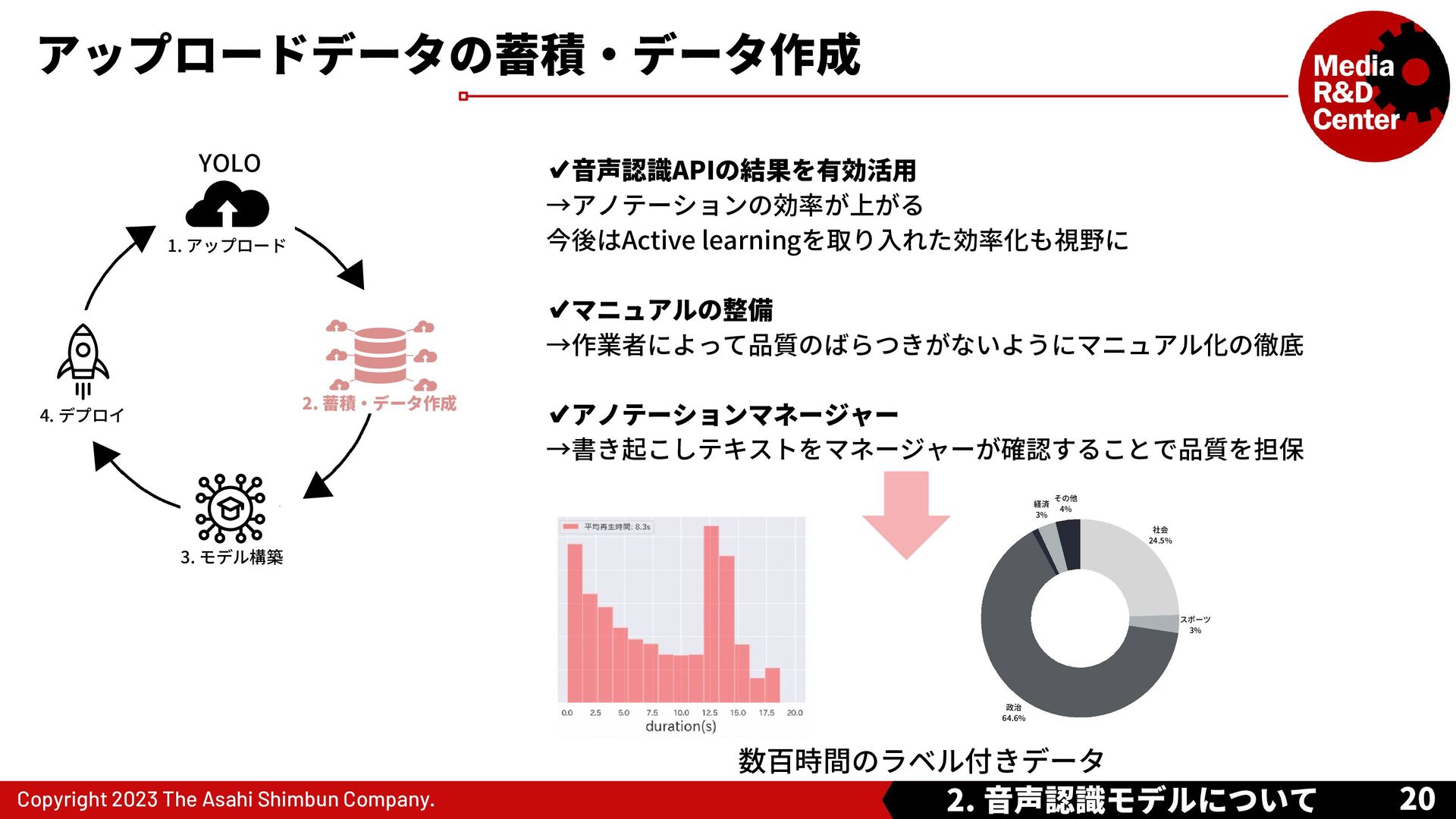{kind=link}
![モデル構築 wav2vec 2.0[2]とWhisper[3]を使用 ラベル付きデータでFine-tuning データセットの大きさ 25.5h, 141h 評価データセット 朝日評価データセット JTubeSpeech[4]](https://files.speakerdeck.com/presentations/c7382e9a17224a86a8ce6dca932e3826/slide_20.jpg){kind=link}
{kind=link}
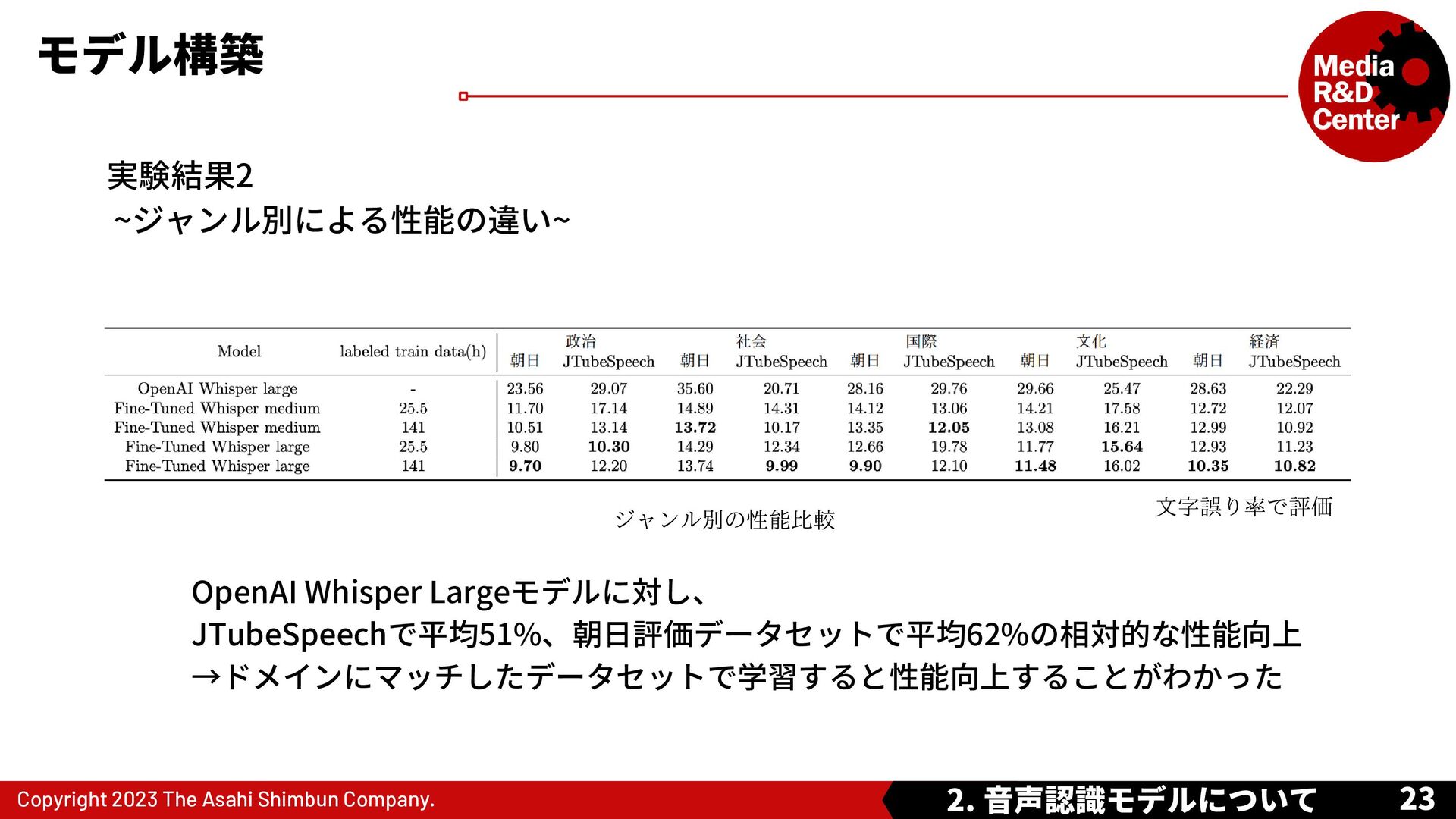{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}