Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
TensorFlowで文字認識にチャレンジ! / Japanese Character Re...
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
moonlight-aska
December 11, 2016
64
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
TensorFlowで文字認識にチャレンジ! / Japanese Character Recognition with TensorFlow
2016年12月11日開催の「TensorFlow勉強会#11」のLT資料です.
moonlight-aska
December 11, 2016
More Decks by moonlight-aska
See All by moonlight-aska
Create Your Own AI with Dify×Gemma3
aska
0
71
Generative AI Prototyping
aska
0
28
【入門】プロンプトの書き方のコツ / Tips for writing prompts
aska
0
230
CHATGPT。はじめの一歩 / ChatGPT. Get Started
aska
0
150
「Kingyo AI Navi」アプリ / Kingyo AI Navi App
aska
0
280
Kingo AI Navi LINEをもっと使い倒せ!!
aska
0
160
Depth画像で物体検知やってみたー。/ Objects Detection with Depth Images
aska
0
840
Kingyo AI Naviアプリ開発 / Kingyo AI Navi App
aska
0
460
AutoML Vision Edgeで金魚分類モデルを学習してみた / Kingyo Classification Model with AutoML Vision Edge
aska
0
590
Featured
See All Featured
Redefining SEO in the New Era of Traffic Generation
szymonslowik
1
370
Digital Ethics as a Driver of Design Innovation
axbom
PRO
1
350
Applied NLP in the Age of Generative AI
inesmontani
PRO
4
2.4k
The Curse of the Amulet
leimatthew05
2
13k
WCS-LA-2024
lcolladotor
0
750
Agile that works and the tools we love
rasmusluckow
331
22k
Practical Tips for Bootstrapping Information Extraction Pipelines
honnibal
25
2k
Art, The Web, and Tiny UX
lynnandtonic
304
22k
We Have a Design System, Now What?
morganepeng
55
8.2k
GraphQLとの向き合い方2022年版
quramy
50
15k
The World Runs on Bad Software
bkeepers
PRO
72
12k
Keith and Marios Guide to Fast Websites
keithpitt
413
23k
Transcript
TensorFlowで 文字認識にチャレンジ! 2016/12/11 Moonlight 明日香 TensorFlow勉強会#11 LT
自己紹介 Moonlight 明日香 鶴田 彰 関西の外資系家電メーカー勤務 昔は,
・パターン認識(音声, 文字, etc) ・ユーザ適応(レコメンド, etc) なども・・・ 最近は, 週末プログラマとして また機械学習に再チャレンジ中! Twitter @moonlight_aska Blog:みらいテックラボ http://mirai-tec.hatenablog.com Wiki : Androidプログラマへの道 ~Moonlight 明日香~ http://seesaawiki.jp/w/moonlight_aska/
目次 1. 文字認識とは 2. 特徴量の抽出 3. モデル構造 4. 学習と評価 5.
実装ポイント 6. 最後に
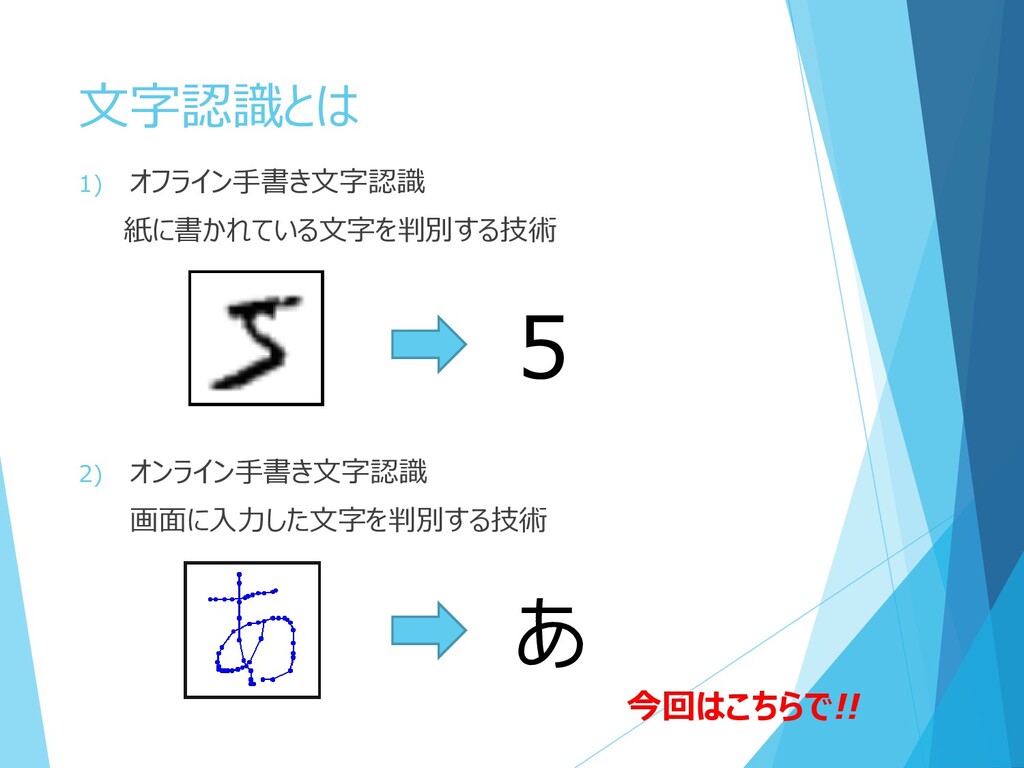
1) オフライン手書き文字認識 紙に書かれている文字を判別する技術 2) オンライン手書き文字認識 画面に入力した文字を判別する技術 文字認識とは あ 5 今回はこちらで!!
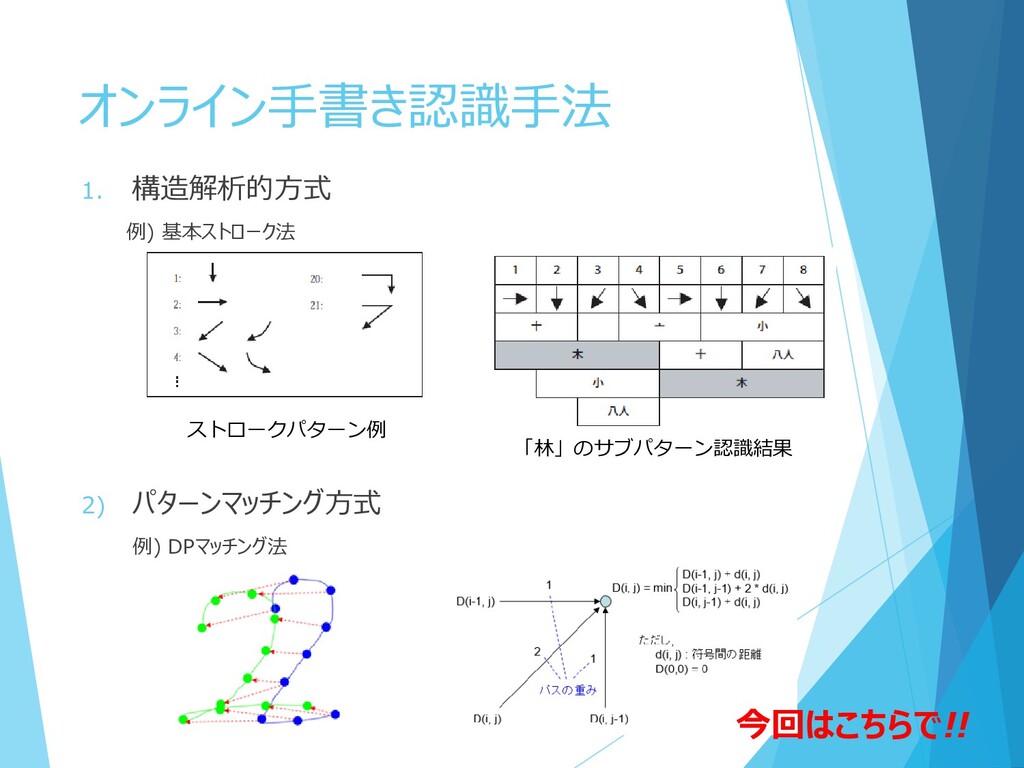
オンライン手書き認識手法 1. 構造解析的方式 例) 基本ストローク法 2) パターンマッチング方式 例) DPマッチング法 ストロークパターン例
「林」のサブパターン認識結果 今回はこちらで!!
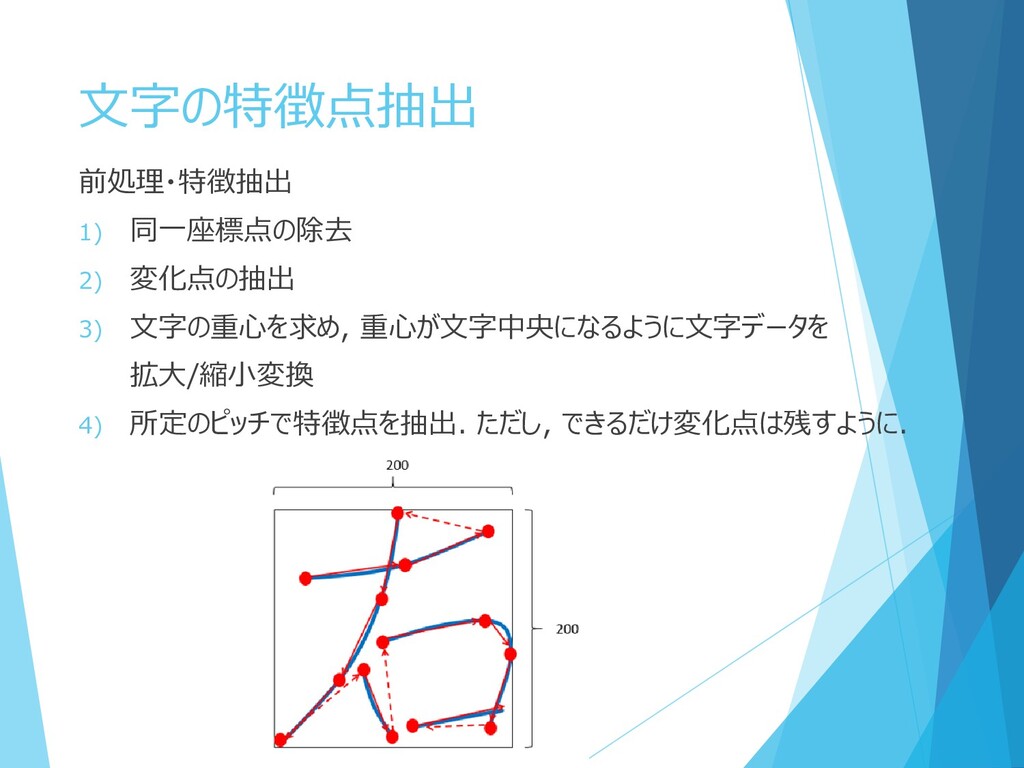
文字の特徴点抽出 前処理・特徴抽出 1) 同一座標点の除去 2) 変化点の抽出 3) 文字の重心を求め, 重心が文字中央になるように文字データを 拡大/縮小変換
4) 所定のピッチで特徴点を抽出. ただし, できるだけ変化点は残すように.
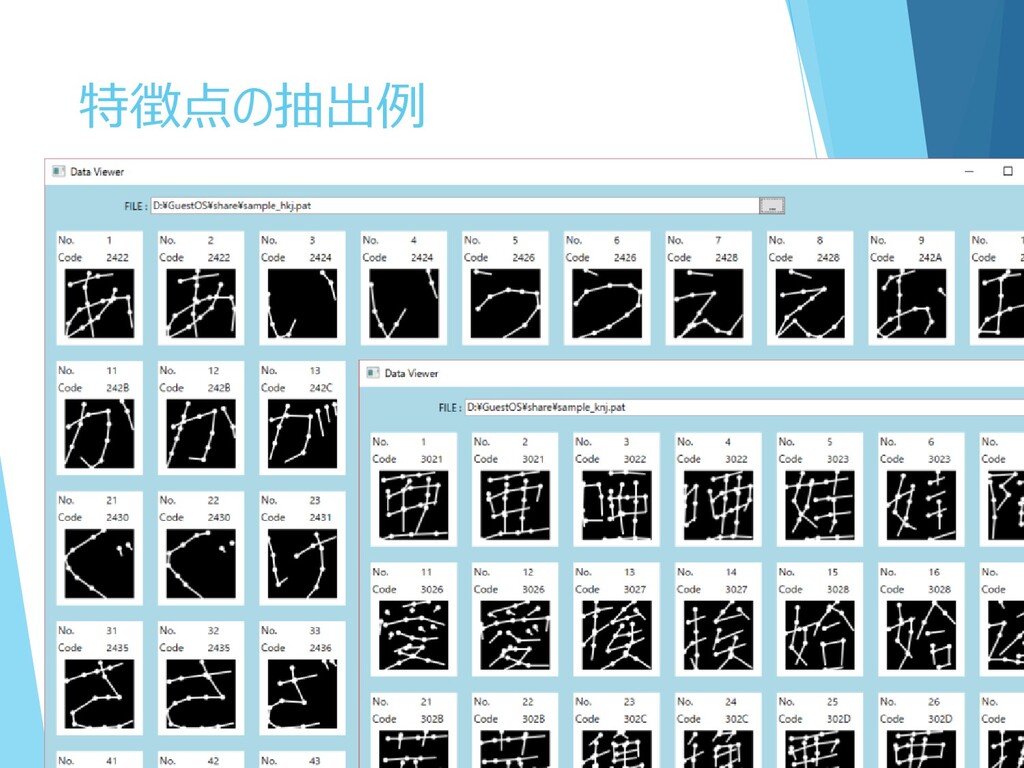
特徴点の抽出例
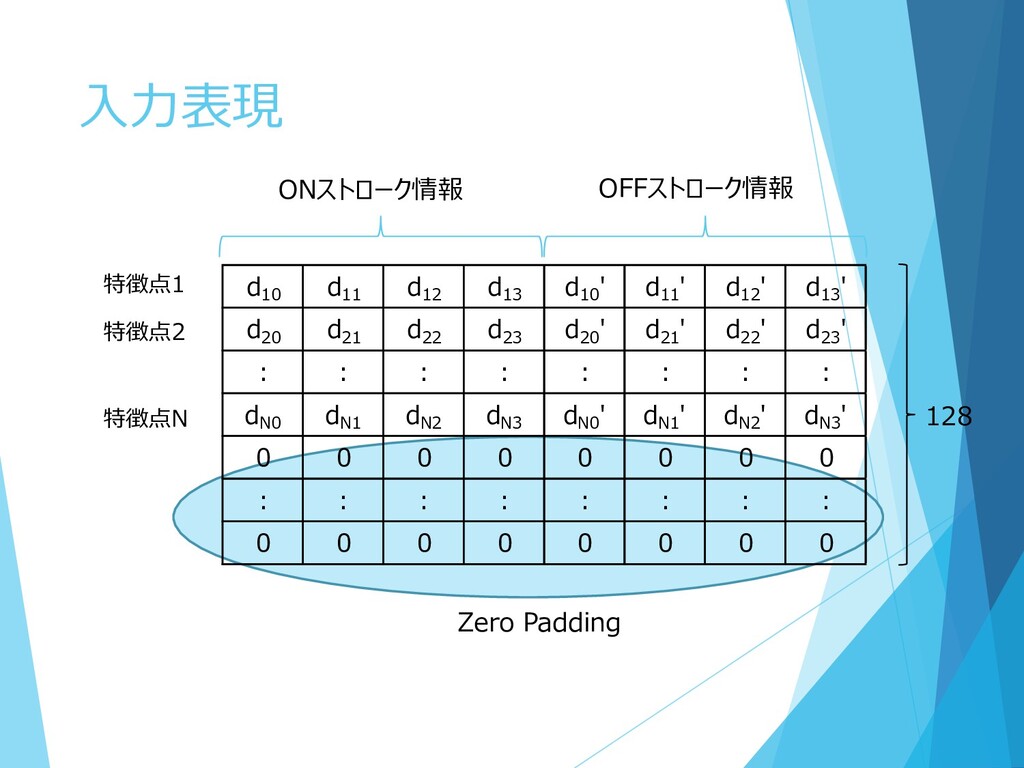
特徴点表現 1) 文字枠内の座標 2) ストロークの移動方向 3) ストロークのON/OFF状態 特徴ベクトル
DNNは何を使うか? 画像データ ⇒ CNN (Convolutional Neural Network) 時系列データ ⇒ RNN
(Recurrent Neural Network) ここは CNNでチャレンジ!! 理由1:当時TensorFlow始めたばかりで, CNNのチュートリアル しかよく知らなかった!! 理由2:自然言語処理(NLP)の分野で, CNNを適用したという 記事があった. http://www.wildml.com/2015/11/understanding- convolutional-neural-networks-for-nlp
入力表現 128 d10 d11 d12 d13 d10 ' d11 '
d12 ' d13 ' d20 d21 d22 d23 d20 ' d21 ' d22 ' d23 ' : : : : : : : : dN0 dN1 dN2 dN3 dN0 ' dN1 ' dN2 ' dN3 ' 0 0 0 0 0 0 0 0 : : : : : : : : 0 0 0 0 0 0 0 0 特徴点1 特徴点2 特徴点N Zero Padding ONストローク情報 OFFストローク情報
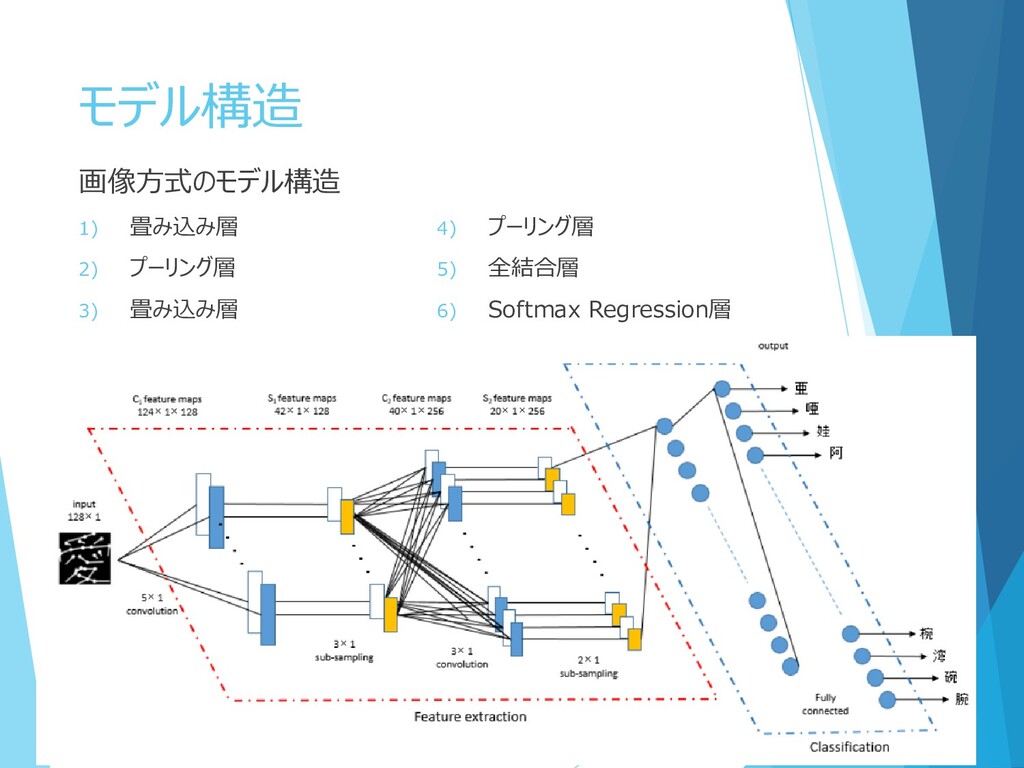
モデル構造 画像方式のモデル構造 1) 畳み込み層 2) プーリング層 3) 畳み込み層 4) プーリング層
5) 全結合層 6) Softmax Regression層
学習と評価 [学習条件] • 認識対象:ひらがな73文字種+漢字2,965文字種(JIS第一水準) • 学習データ:約340,000(ひらがな約10,000, 漢字約330,000) • 学習回数:ミニバッチ(100サンプル)×100,000回 [認識条件]
• 評価データ:ひらがな2,010, 漢字29,471 [実験結果] 方式 対象 1位 累積(5位) 筆点列 ひらがな 97.56% 99.95% 漢字 95.95% 98.93% 画像 ひらがな 95.37% 99.80% 漢字 95.71% 99.13%
文字認識の難しさ ★画数の少ない文字に類似文字が多い [例1] 同じ形状の文字 ・ひらがらの「へ」とカタカナの「ヘ」 ・記号「+」と漢字「十」 ・カタカナ「カ」と漢字「力」 ・数字「1」と英字「I」,「l」と記号「|」 : [例2]
類似した形状の文字 ・カタカナ「ス」, 「ヌ」と漢字「又」 ・カタカナ「フ」or「ワ」と数字「7」 ・漢字「土」と「士」 ・漢字「乙」と英字「z」, 「Z」 : 認識性能upには言語処理が必須!!
実装ポイント(1) 基本はDeep MNIST for Expertsベース ポイント1: One-Hotをミニバッチ毎に生成 [コード] for i
in range(ITELATION_NUM): # ミニバッチのデータ idxs = random.sample(xrange(num1), MINI_BATCH_SIZE) batch_xs = dat1[idxs] ys = label1[idxs] # JISコード batch_ys = np.zeros((MINI_BATCH_SIZE, JP_CATEGORY_SIZE)) for j in range(MINI_BATCH_SIZE): batch_ys[j][jp.getIdx(ys[j])] = 1
実装ポイント(1) ID ⇒ 漢字表記 self.code = np.array([ '_', # 0
[0x2121] '、', # 1 [0x2122] '。', # 2 [0x2123] ',', # 3 [0x2124] '・', # 4 [0x2126] ':', # 5 [0x2127] : '麒', # 3410 [0x734a] '黎', # 3411 [0x7355] '齟', # 3412 [0x7372] '齬', # 3413 [0x7377] ]) JISコード ⇒ ID self.index = np.array([ 0, # [0x0000] 0, # [0x0001] 0, # [0x0002] : 0, # [0x2121] 1, # [0x2122] 2, # [0x2123] 3, # [0x2124] : 0, # [0x7f7e] 0, # [0x7f7f] ])
実装ポイント(2) ポイント2: 識別結果を分かり易く [コード] test_res = res.Accuracy(CANDIDATE_MAX) for i in
range(num2): label2 = np.zeros((1,JP_CATEGORY_SIZE)) label2[0][jp.getIdx(code[i])] = 1 cand = sess.run(y_conv, feed_dict={x: dat2[[i]], y_: label2, keep_prob: 1.0}) test_res.setResult(i, cand, code[i]) test_res.calcAccuracy(num2)
実装ポイント(2) def _setResult(self, no, res, label): jp = mj.Japanese() correct
= jp.getCode(label) print('--- No. %5d %s ---' % ((no+1), correct)) for i in range(self.order): idx = np.argsort(res)[0][::-1][i] code = jp.getCode2(idx) if code == correct: self.rank[i] += 1 print('* %d位 : %s (%f)' % ((i+1), code, np.sort(res)[0][::-1][i])) else: print(' %d位 : %s (%f)' % ((i+1), code, np.sort(res)[0][::-1][i])) --- No. 29487 腕 --- * 1位 : 腕 (0.999989) 2位 : 脇 (0.000008) 3位 : 腰 (0.000001) 4位 : 肺 (0.000001) 5位 : 胸 (0.000000) --- No. 29488 腕 --- 1位 : 脇 (0.923074) * 2位 : 腕 (0.076144) 3位 : 閥 (0.000144) 4位 : 腺 (0.000126) 5位 : 畷 (0.000102)
最後に • 特徴量やモデル構造も大事だが, やはり最後は学習データの 量が効く. • やはり, GPUマシンはほしい!! 詳しくは, 「TensorFlow
文字認識」で検索.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![学習と評価 [学習条件] • 認識対象:ひらがな73文字種+漢字2,965文字種(JIS第一水準) • 学習データ:約340,000(ひらがな約10,000, 漢字約330,000) • 学習回数:ミニバッチ(100サンプル)×100,000回 [認識条件]](https://files.speakerdeck.com/presentations/2e35ecd17c794265b25b77cf9f245511/slide_11.jpg){kind=link}
![文字認識の難しさ ★画数の少ない文字に類似文字が多い [例1] 同じ形状の文字 ・ひらがらの「へ」とカタカナの「ヘ」 ・記号「+」と漢字「十」 ・カタカナ「カ」と漢字「力」 ・数字「1」と英字「I」,「l」と記号「|」 : [例2]](https://files.speakerdeck.com/presentations/2e35ecd17c794265b25b77cf9f245511/slide_12.jpg){kind=link}
![実装ポイント(1) 基本はDeep MNIST for Expertsベース ポイント1: One-Hotをミニバッチ毎に生成 [コード] for i](https://files.speakerdeck.com/presentations/2e35ecd17c794265b25b77cf9f245511/slide_13.jpg){kind=link}
{kind=link}
![実装ポイント(2) ポイント2: 識別結果を分かり易く [コード] test_res = res.Accuracy(CANDIDATE_MAX) for i in](https://files.speakerdeck.com/presentations/2e35ecd17c794265b25b77cf9f245511/slide_15.jpg){kind=link}
{kind=link}
{kind=link}