Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
AIによるソフトウェア品質保証の現在地点とこれから
Search
Autify
March 28, 2025
Technology
540
1
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
AIによるソフトウェア品質保証の現在地点とこれから
Autify
March 28, 2025
More Decks by Autify
See All by Autify
プロセスの目線からみる「自動テストの安定化」
autifyhq
0
290
AI駆動開発カンファレンスAutumn2025 _AI駆動開発にはAI駆動品質保証
autifyhq
1
340
ベストプラクティスを適用するとシナリオはどう変化するのか
autifyhq
0
570
Pro Serviceチームの身近なAI活用事例 (JaSST'25 Hokkaido スポンサーセッション)
autifyhq
0
74
オーティファイ会社紹介資料 / Autify Company Deck
autifyhq
10
150k
Autify Company Deck
autifyhq
2
53k
事業継続を支える自動テストの考え方(レバレジーズ様勉強会版)
autifyhq
0
650
自動テストの世界に、この5年間で起きたこと
autifyhq
11
18k
読みやすいテストコードの書き方
autifyhq
0
720
Other Decks in Technology
See All in Technology
データベース研修【MIXI 26新卒技術研修】
mixi_engineers
PRO
1
500
クラウドを使う側から、作る側へ / 大吉祥寺.pm 2026前夜祭
fujiwara3
7
1.6k
DevOps Agentで運用判断をチーム資産にする ~Agent InstructionsとAgent Skillを継続的に育てる~
fujioka6789
0
130
テックカンファレンス三大ステークホルダーの文化人類学 ─ 違いを認め合う関係性作り
bash0c7
4
890
AWS環境のセキュリティ不安を解消した企業事例 ~よくある課題と対策を一挙公開~
asanoharuki
0
220
歴史から理解するクラウドインフラのしくみ
kizawa2020
0
180
Flutter研修【MIXI 26新卒技術研修】
mixi_engineers
PRO
1
220
カメラ×AIで挑む「ホワイト物流」― 車両管理、自動化の壁と突破口【SORACOM Discovery 2026】
soracom
PRO
0
140
システム監視を 「システムを監視するだけ」で 終わらせないために
seiud
0
130
AI時代におけるエンジニアの新たな役割──FDEとクオリアの探求/登壇資料(戸井田 裕貴)
hacobu
PRO
0
570
オートマトンと字句解析でRoslynを読む
tomokusaba
0
110
なぜ、あなたのAPIは使われないのか? AX時代の設計原則、ガードレール、運用体制
yokawasa
1
240
Featured
See All Featured
The Limits of Empathy - UXLibs8
cassininazir
1
550
Jess Joyce - The Pitfalls of Following Frameworks
techseoconnect
PRO
1
310
Rails Girls Zürich Keynote
gr2m
96
14k
How to build a perfect <img>
jonoalderson
1
5.8k
Git: the NoSQL Database
bkeepers
PRO
432
67k
New Earth Scene 8
popppiees
3
2.4k
The innovator’s Mindset - Leading Through an Era of Exponential Change - McGill University 2025
jdejongh
PRO
1
230
Claude Code のすすめ
schroneko
67
230k
Building Flexible Design Systems
yeseniaperezcruz
330
40k
Let's Do A Bunch of Simple Stuff to Make Websites Faster
chriscoyier
508
140k
Navigating the moral maze — ethical principles for Al-driven product design
skipperchong
2
430
Side Projects
sachag
455
43k
Transcript
AI powered Quality Engineering Platform 2024.06.20 AIによるソフトウェア品質保証の現在地点とこれから 2025.3.28 AI powered
Quality Engineering Platform
JaSST’24 Tokai「大規模言語モデル・対話型生成AIによるテスト支援の広さと深さ」 はじめに
AI-powered Quality Engineering Platform AutifyはAI, 生成AIを活用したプロダクトと 品質保証のプロフェッショナルがテストプロセスのすべてをサポート
学術界・産業界におけるAI × テストの第一人者たちの意見交換を聞くことで • 生成AIと品質保証の関係について外観が分かる • アカデミアと産業界でどのような試行錯誤がなされているのかが分かる • 自動化・生成AI利用が前提のソフトウェアテストのあるべき姿を理解できる このセッションのゴール
スピーカー紹介 石川 冬樹 国立情報学研究所 松浦 隼人 Autify Genesis プロダクトマネージャー 守屋
敬太 Autify NoCode プロダクトマネージャー 末村 拓也 Autify 品質エバンジェリスト モデレーター
石川先生発表
背景共有(石川): AI4QA(学術、基礎・原則の視点) 石川の立場 • 先端の論文把握・先端の研究(AI・自動運転のためのテスト自動生成、形式手法など) • トップエスイー、日科技連SQiPなどで現場の技術者との議論・実践研究 • 企業との共同研究(LLM/AIの活用に関する活動要請は増え続けている) →
石川視点での現状の感覚 • LLM自体とその活用手段の先端はかなり速く進化 • テスト支援の学術研究も高度なものから実証評価まで多数 • LLMベースのAIは「それなりに動くもの」を簡単に作れる → 学術研究に依存せず個人・企業での取り組みが速い(or 二極化している?) → 評価の難しさ・コストが高く、評価・改善のサイクル(LLMOps)確立が課題? 前提メモ:大規模言語モデル (LLM) に 基づくGPT/ChatGPTなどの対話型生成AI で新たにできるようになったことを みんな議論しているはず ※ 以降の資料はJaSST’24 Tokai 資料より抜粋(石川のSpeaker Deck上にあり)
背景共有(石川):学術研究のごくごく一例 画面やこれまでのテスト内容を説明するAIと、それを 受けて次のアクションを決めるAIの 掛け合いでアプリの自動探索テスト [ Liu+, ICSE’24 ] バグレポート内の再現手順を、形式化し 知識グラフとして構造化する
(そうすれば統計分析、類似検索、 テスト生成などは簡単にできる) [ Su+, ICSE’24 ] 画像認識AIが間違えそうな状況をLLMが検討、 画像生成AIを使って実際にテスト、結果を 踏まえてLLMが再検討という探索的テスト [ 鳥越+, FOSE’24 ]
• 一通りのタスクが何でもできる ◦ ただし,LLMだけにやらせる・End-to-Endでやらせればよいとは限らない • 不定型・不完全なものでも「常識」でさばいてくれる → 必要な準備・適用の前提が低く、今までのAIと違うことができる ◦ データのフォーマット・スキーマなどの統一・形式化や,
大量データを用いた事前訓練などが(従来よりは)なくてもよい ◦ 日本語における言葉・言い回しのぶれを苦にしない ◦ 明文化していないことも,一般的な「常識」なら補完してくれる ◦ 構造化・形式化されたデータを扱う従来技術にもつなげられる 背景共有(石川): LLM・対話型生成 AIによる支援の特徴
• タスク特化のアルゴリズム ◦ 例:All-Pair制約と禁則条件を満たす組み合わせテストスイートの生成 • モデルを前提とした手法 ◦ 例:状態遷移モデルから特定のカバレッジ条件を満たすテストスイートの生成 • 論理推論を活用した技術
◦ 例:特定パスを通す・カバレッジを上げるテスト入力の生成 • 従来の機械学習型AI(タスクに特化した訓練を実施) ◦ 例:画面の画像から構成部品の自動抽出 • 進化計算・強化学習など探索・最適化技術の活用 ◦ 例:カバレッジなどテスト目的に応じたテストスイートの探索(EvoSuite, Sapienzなど) ◦ 例:スマホアプリの強化学習による自動テスト 背景共有(石川):これまでのテスト技術も強力!
• 既存技術が求める定型入力の作成をLLMに支援させる ◦ 例:UMLなど厳密な文法でのモデルを作る • 既存技術の出力をLLMに修正させる ◦ 例:カバレッジは上がるが不自然だったり読みづらかったりするテストコードを修正する • 既存技術の出力をLLMに説明させる
◦ 例:機械的な出力を要約させる・ステークホルダー向けに言い換えさせる • LLMによる生成を探索的・進化的に行う ◦ 例:プロンプトも自動で変えつつ,誤り・不足を減らしていく → 多様なポテンシャルがある! ※ 一方で推論モデル・エージェント(問題分割や検証と再試行を繰り返すなど)による タスク遂行能力もかなり進化、それで大半のタスクは済むという説も? 問いかけ(石川): LLM+既存技術の様々なポテンシャル
• プロンプトと入出力を模索して「やらせてみる」のは簡単 ◦ これはスピード勝負,うだうだ言わずに試した方がよい ◦ 「人間が確認し必要に応じて修正してね」と言うのは簡単 → 評価・改善のサイクルを繰り返せるのか?? → 『「テストのためのLLM/AI」のためのテスト』が必要!!
◦ 「AIがテストを生成します」の一言で済むわけがない ◦ 何をもって「よいテストが作れた」「十分なテスト能力を持つ」と見なす? ◦ 評価ベンチマークの準備が高コスト ◦ カバレッジなどの数値指標を超えて、人間らしい「よさ」を追及する場合、評価が大変 ◦ これらは「LLM/AIのテスト」で活発に議論されている話題: LLM-as-a-Judge, LLMOps などなど 問いかけ(石川):継続的な評価・改善に向けて
松浦さん発表
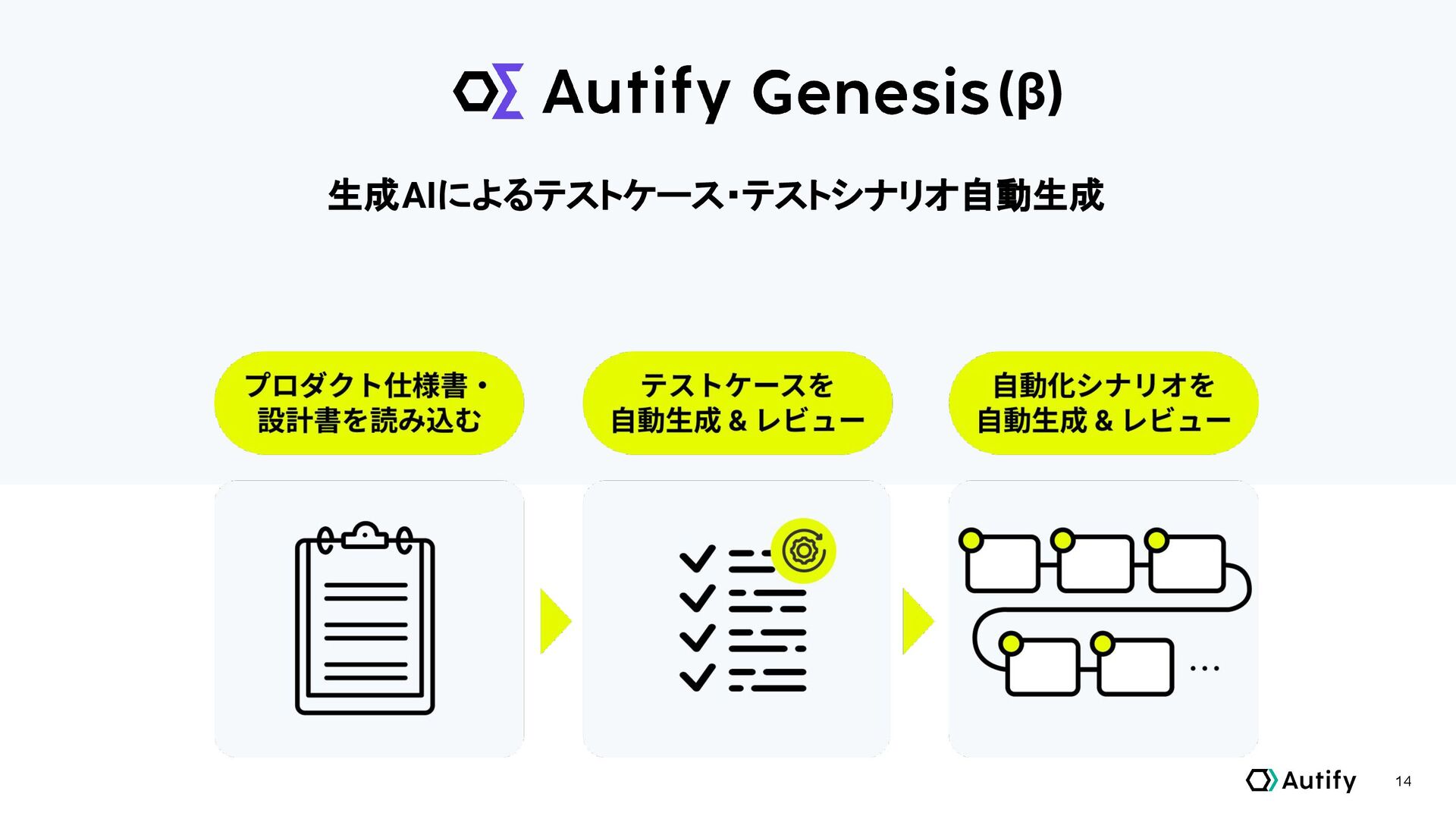
14 (β) 生成AIによるテストケース・テストシナリオ自動生成
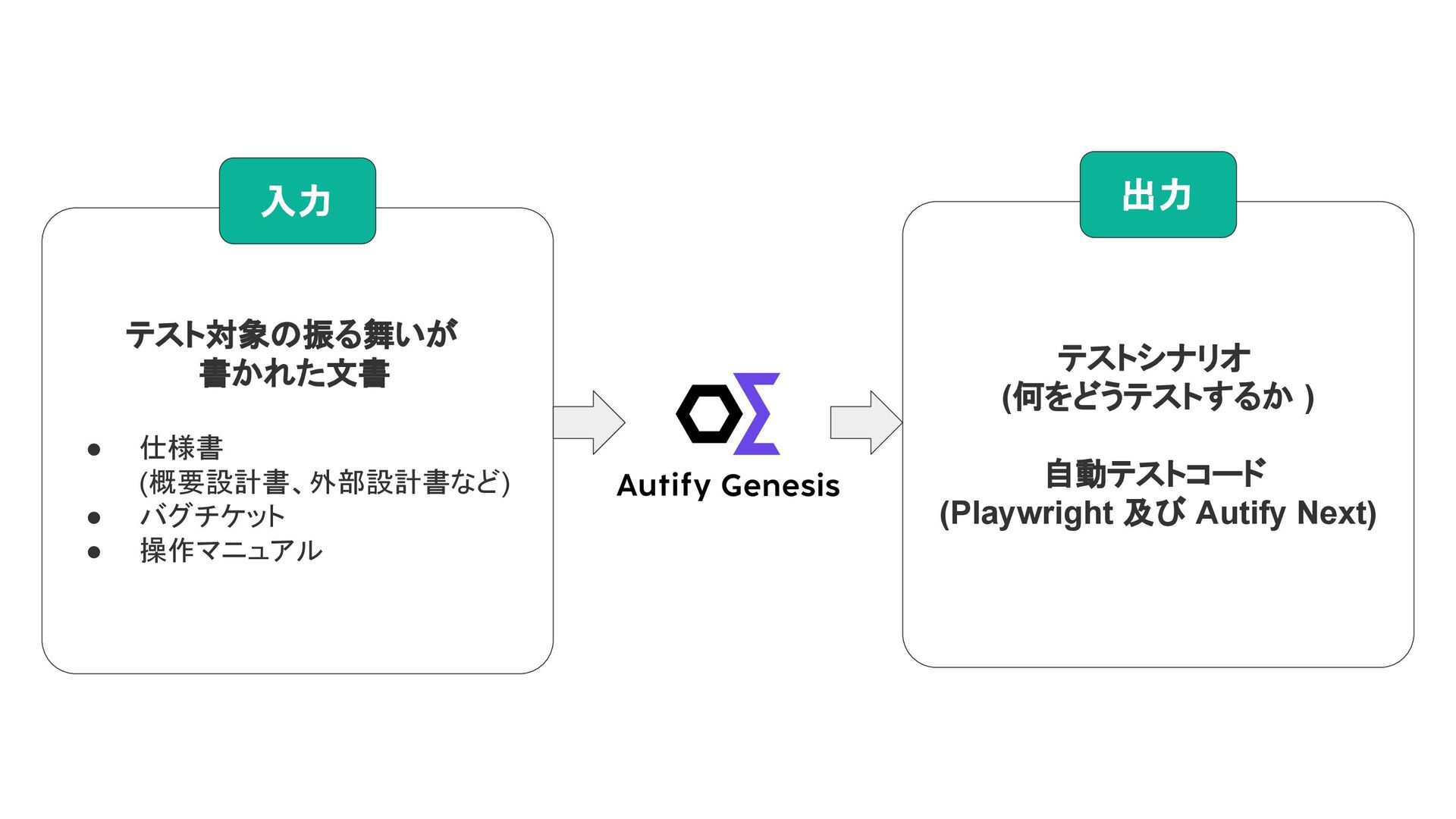
Autify Genesisの入力と出力 テスト対象の振る舞いが 書かれた文書 • 仕様書 (概要設計書、外部設計書など) • バグチケット •
操作マニュアル 入力 テストシナリオ (何をどうテストするか ) 自動テストコード (Playwright 及び Autify Next) 出力
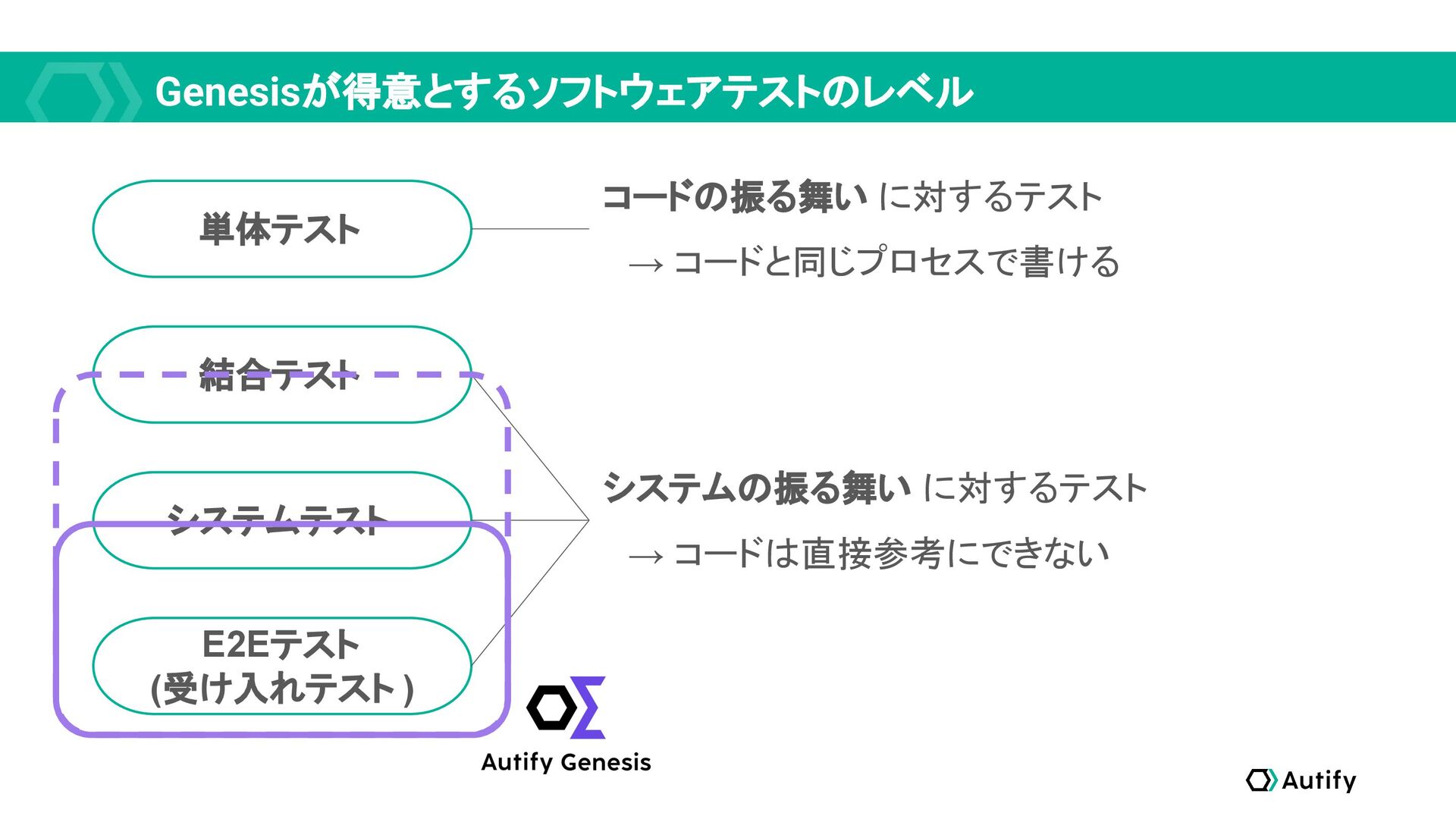
Genesisが得意とするソフトウェアテストのレベル 単体テスト 結合テスト システムテスト E2Eテスト (受け入れテスト ) コードの振る舞い に対するテスト →
コードと同じプロセスで書ける システムの振る舞い に対するテスト → コードは直接参考にできない
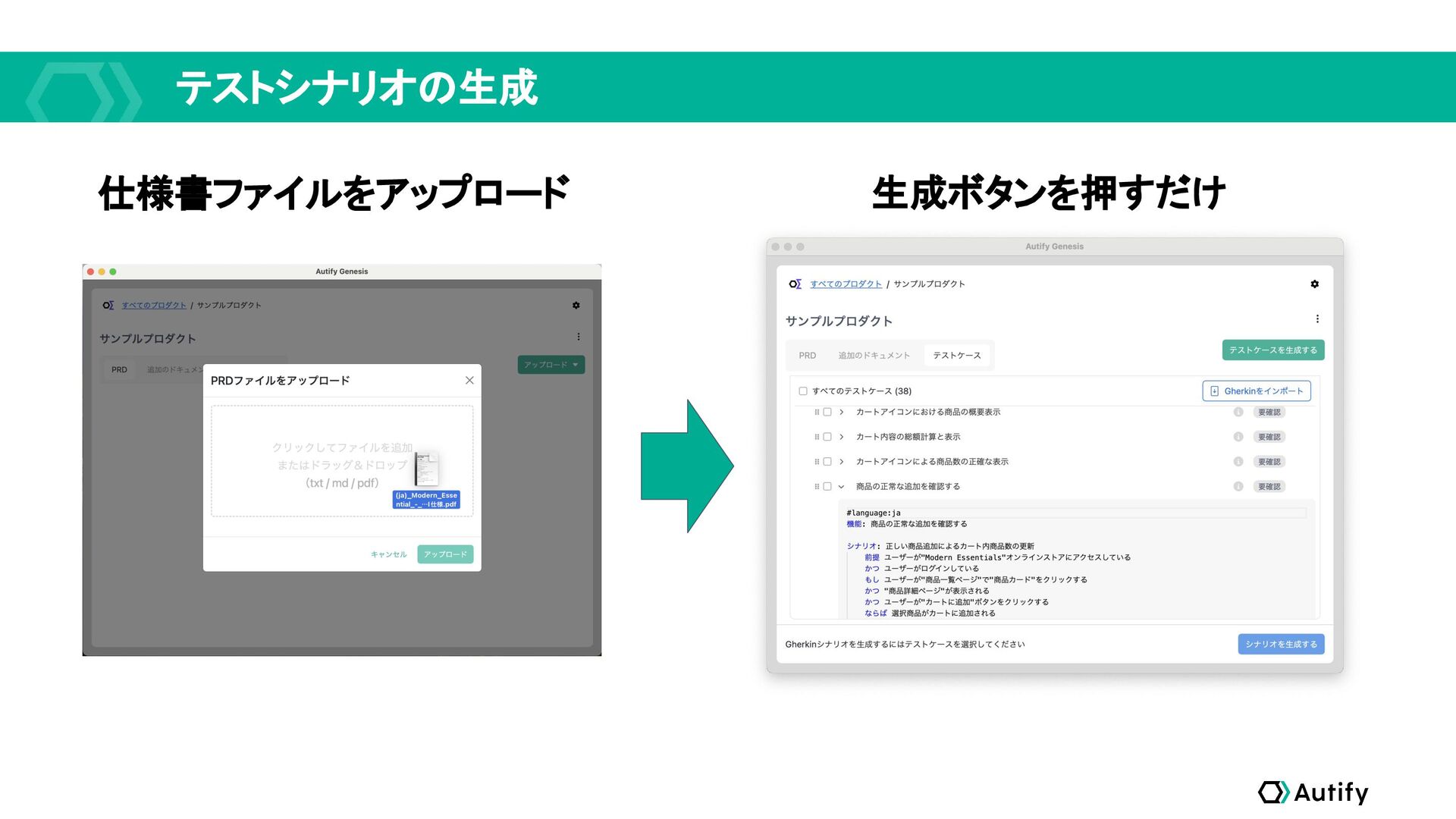
テストシナリオの生成 仕様書ファイルをアップロード 生成ボタンを押すだけ
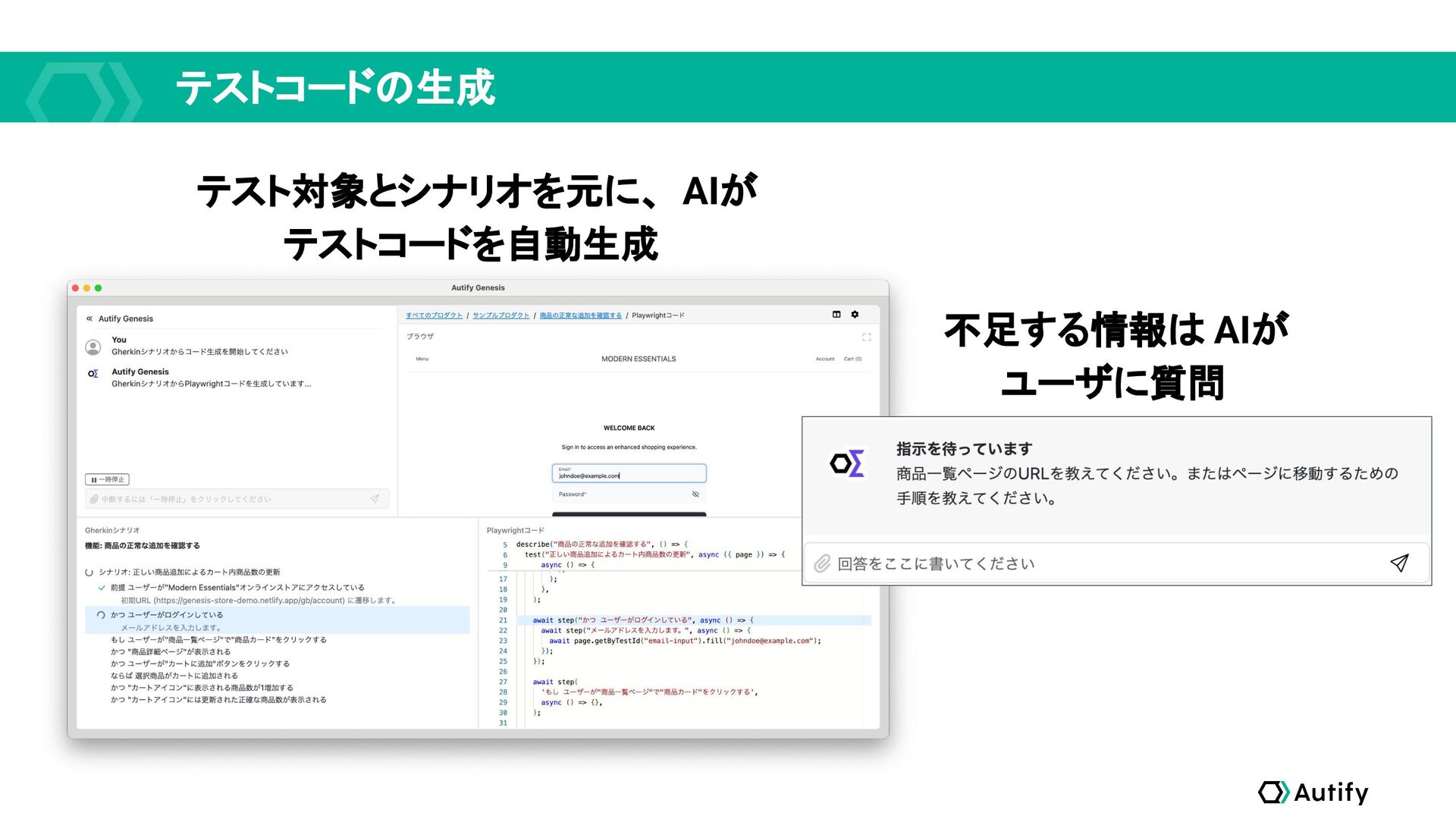
テストコードの生成 テスト対象とシナリオを元に、 AIが テストコードを自動生成 不足する情報は AIが ユーザに質問
• 出力に関する疑問 ◦ テストシナリオ ▪ カバレッジは十分なのか、適切なテスト手法を利用できているか ▪ テスト観点が網羅されているか ◦ テストコード
▪ 意図した通りにテストを行うコードになっているか ▪ メンテナンスしやすいコードになっているか ▪ ユーザへの質問の数は最小化されているか Genesisにおける課題 = 人間とAIとのスムーズな協働 明確な答えがない中での品質保証
• 入力に関する疑問 ◦ 仕様書はしっかり網羅的に書けているのか ◦ あいまいさ、矛盾はないか ◦ AIは仕様書を全て理解できているのか Genesisにおける課題 =
人間とAIとのスムーズな協働 出力を高品質にするには 入力のあるべき姿も提示する必要がある
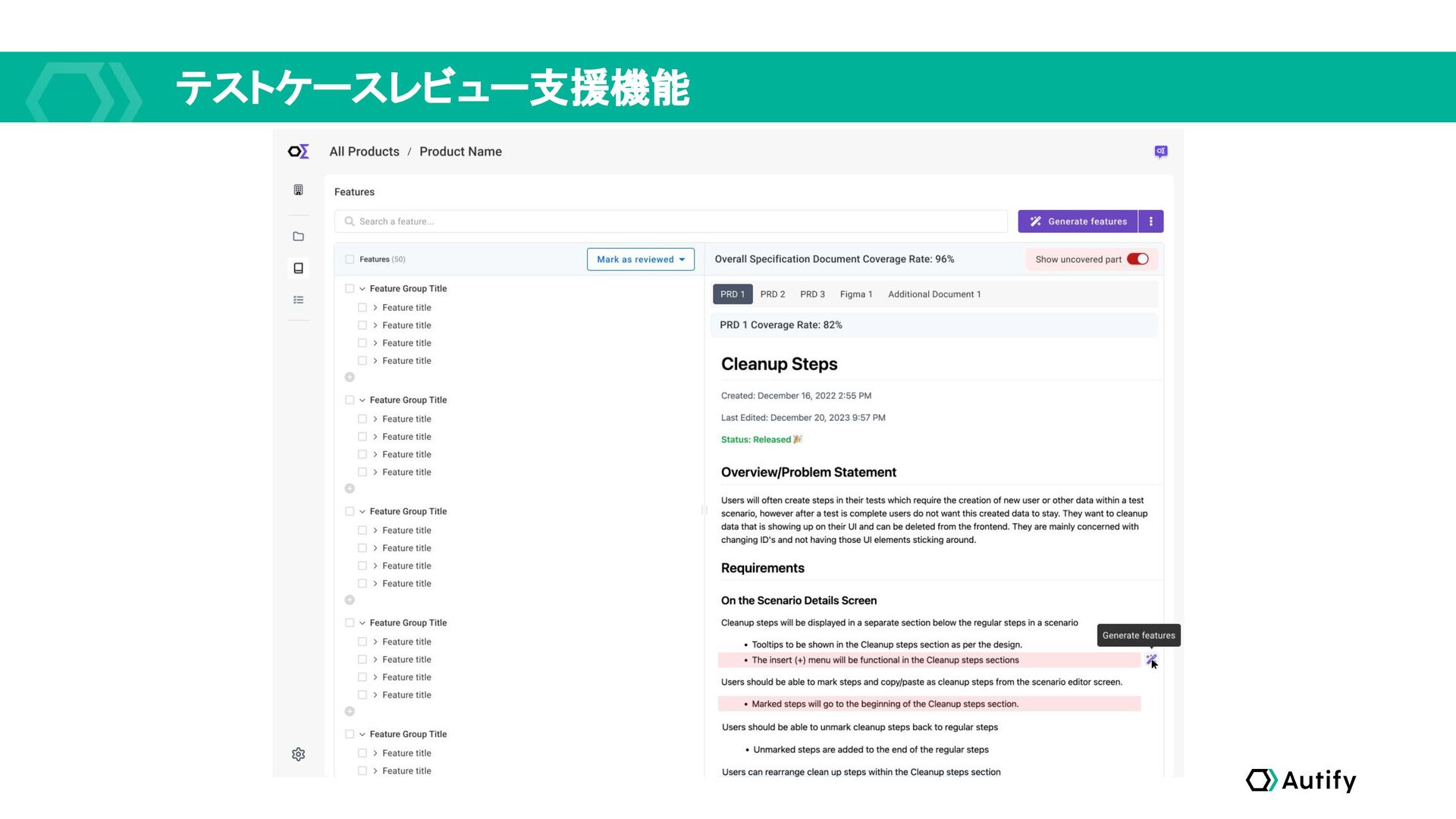
テストケースレビュー支援機能
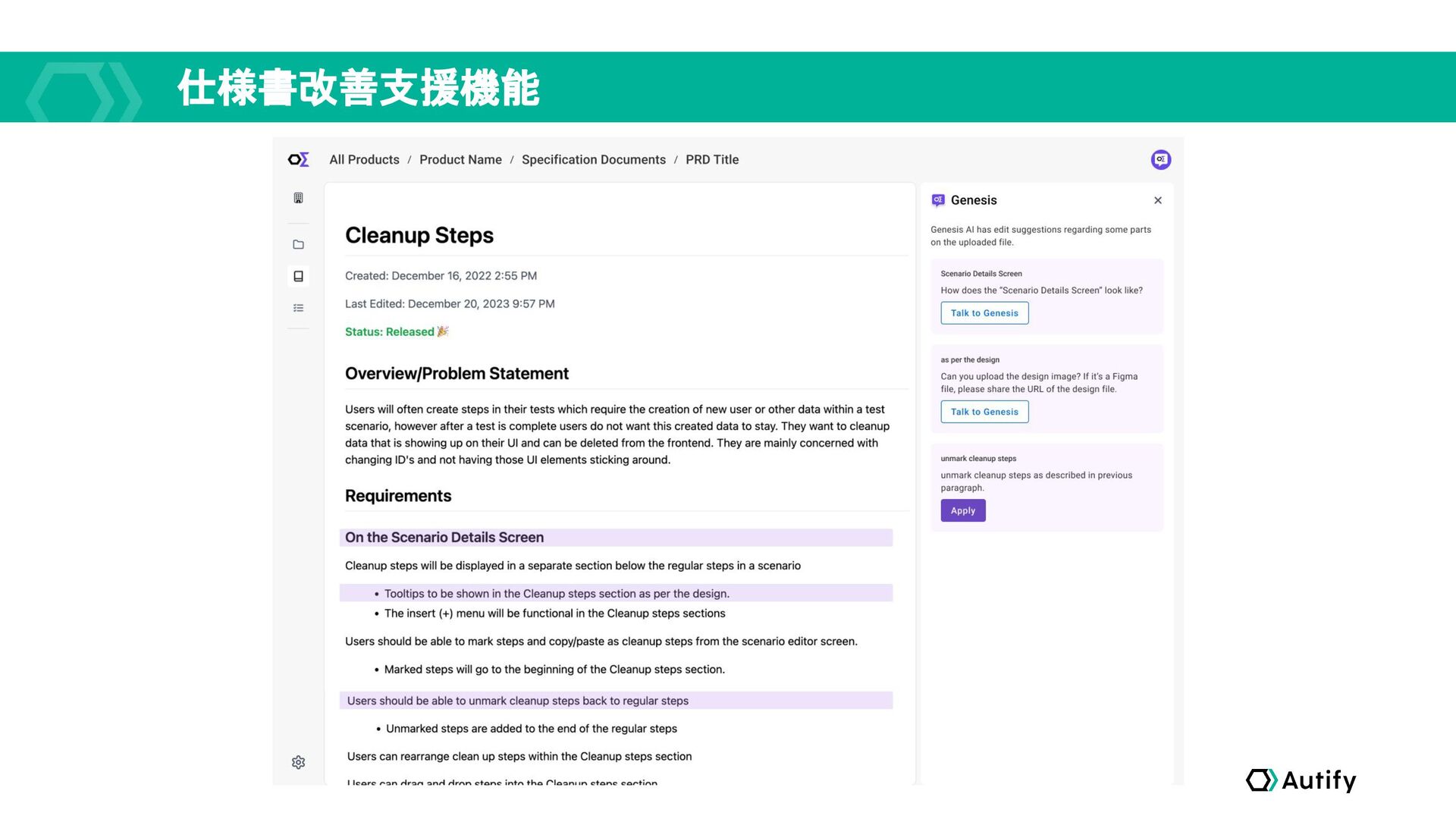
仕様書改善支援機能
守屋さん発表
Autify NoCode について ノーコードで誰でも簡単 自動でメンテナンス ノーコードテスト自動化ツール
課題:手動テストのテストケースを 自動テストに置き換えるのが難しい 「画面が正常に表示されていることを確認する」を どう自動化する? NoCodeプロダクトにおける課題
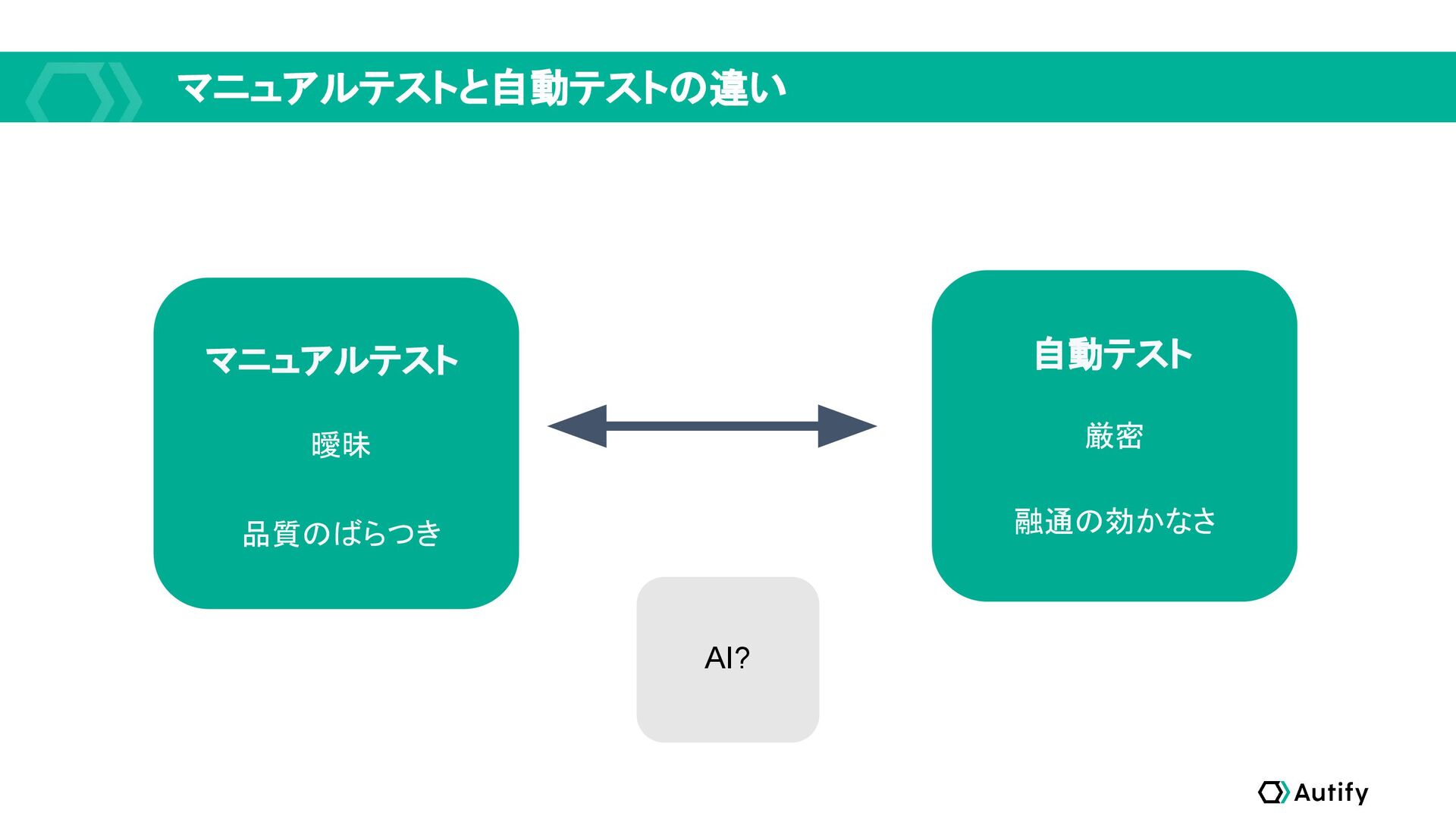
曖昧 マニュアルテストと自動テストの違い 厳密 品質のばらつき 融通の効かなさ マニュアルテスト 自動テスト AI?
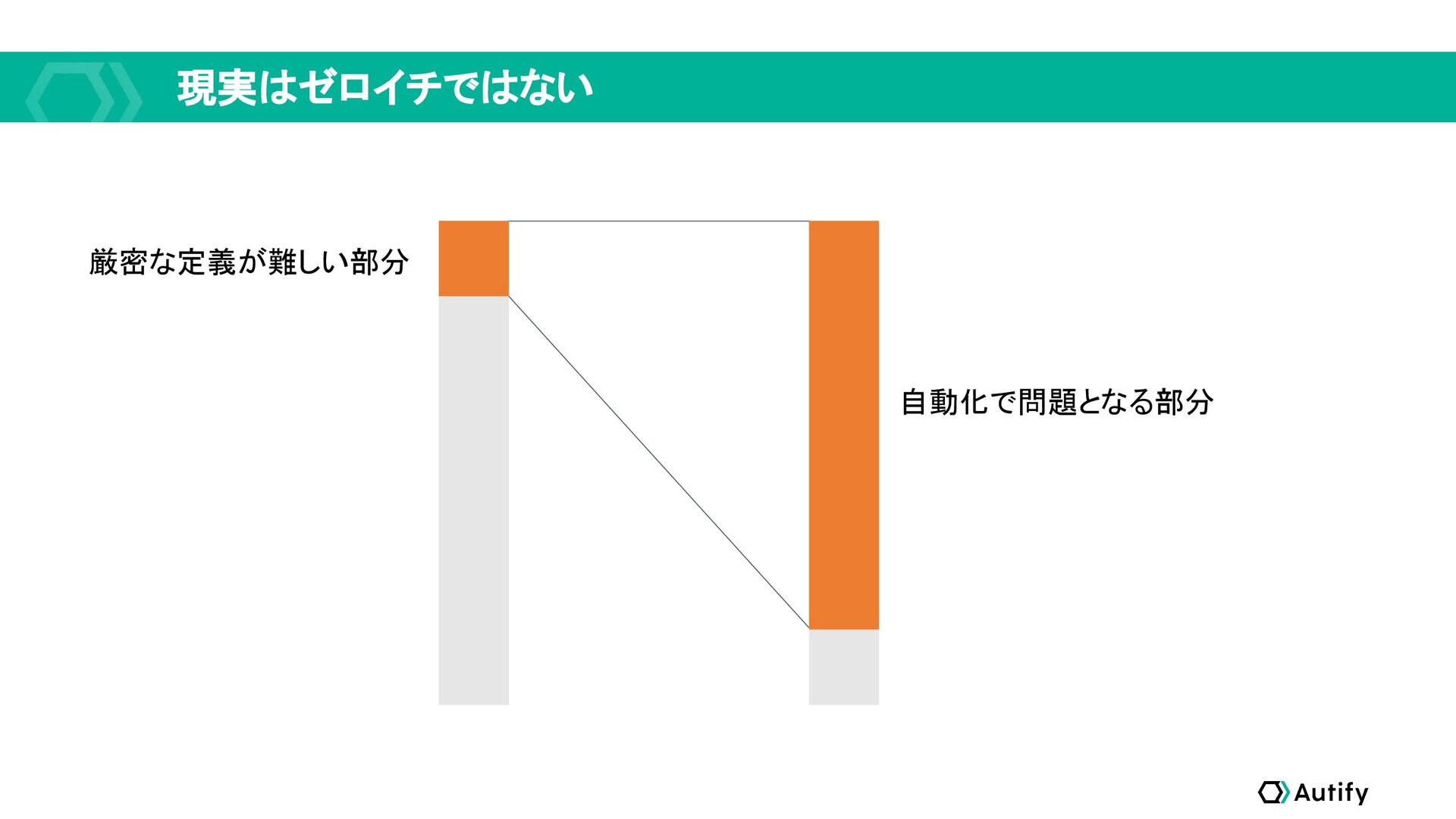
現実はゼロイチではない 厳密な定義が難しい部分 自動化で問題となる部分
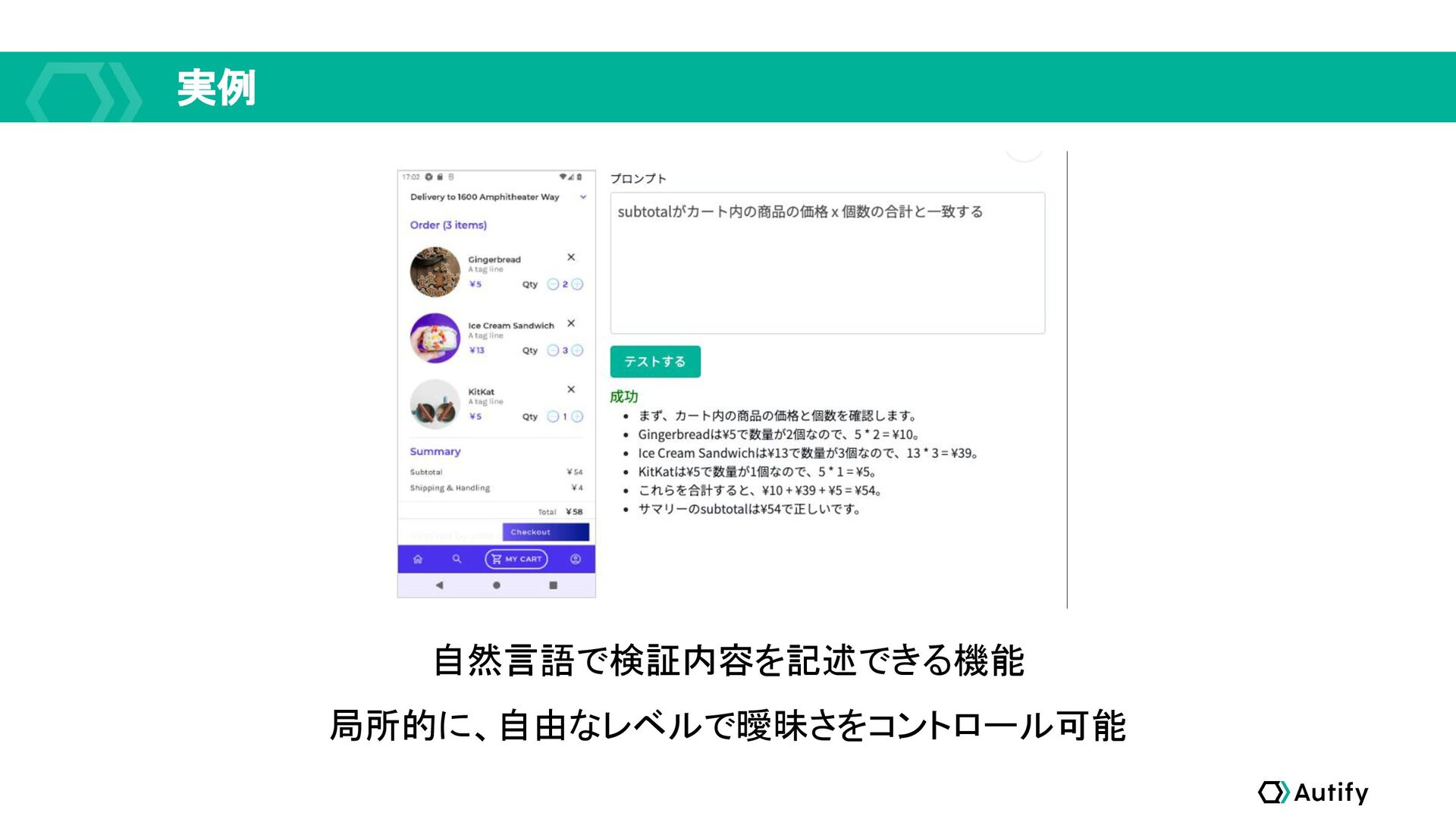
自然言語で検証内容を記述できる機能 局所的に、自由なレベルで曖昧さをコントロール可能 実例
AIモデルの品質は継続的に向上していく。 ただし責任を取るのは人間。 期待値のすり合わせが必要 どのようにして期待値を適切に表現できるか どうすれば守りたい「品質」を定義し、 AIへ移譲ができるか? 今後の可能性
パネルディスカッション
生成AI時代に、ソフトウェアテストはどのようにあるべきか? パネルディスカッション
生成AI時代に、QA・テストエンジニアには何が求められるのか? パネルディスカッション
既存のテストツールと生成 AIのツールは共存していくのか それとも食い合っていくのか? パネルディスカッション
理想の未来にできるだけ近づくために、 学術界と産業界はどのようにコラボレーションできるか? パネルディスカッション
技術の力で世界中の人々の創造性を高める
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![背景共有(石川):学術研究のごくごく一例 画面やこれまでのテスト内容を説明するAIと、それを 受けて次のアクションを決めるAIの 掛け合いでアプリの自動探索テスト [ Liu+, ICSE’24 ] バグレポート内の再現手順を、形式化し 知識グラフとして構造化する](https://files.speakerdeck.com/presentations/fd63cd07db0649a69ce99f93cd80ec19/slide_7.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}