Open Annotation: Annotating Scholarly Communication on the Web Robert Sanderson [email protected] Los Alamos National Laboratory @azaroth42 Herbert Van de Sompel [email protected] Los Alamos National Laboratory @hvdsomp http://www.openannotation.org/ This research is funded, in part, by the Andrew W. Mellon Foundation
Scholarly Communication Scholarly Communication is increasingly: • Online • Open • Distributed • Collaborative • Data-Oriented Annotation is a scholarly primitive, spanning discipline and level. Need to ensure that Digital Annotations fall under these headings! • Apply the standards and architecture of the World Wide Web to the Annotation use case. • Even if scholar doesn’t share annotations with others, she will want to access them from different tools and environments.
Open Annotation Collaboration http://www.openannotation.org/ Focus on interoperable sharing of annotations • Web-centric and open, not locked down silos • Create, consume and interact in different environments • Build from a simple model for simple cases, to more detailed for complex scholarly annotation requirements The Collaboration: • Los Alamos National Laboratory • University of Illinois at Urbana-Champaign • University of Queensland • University of Maryland • George Mason University • … plus many adopters and partners
Open Annotation Data Model Design Guidelines: • Based on the Architecture of the World Wide Web • … and on Linked Open Data • Should be general enough for ease of adoption • … and rich enough to cover scholarly use cases Status: Beta, with 9 ongoing funded experiments to inform 1.0 Hardest part: Define what an Annotation is! • "Aboutness" is key to distinguish from general metadata A document that describes how one resource is about one or more other resources, or part(s) thereof.
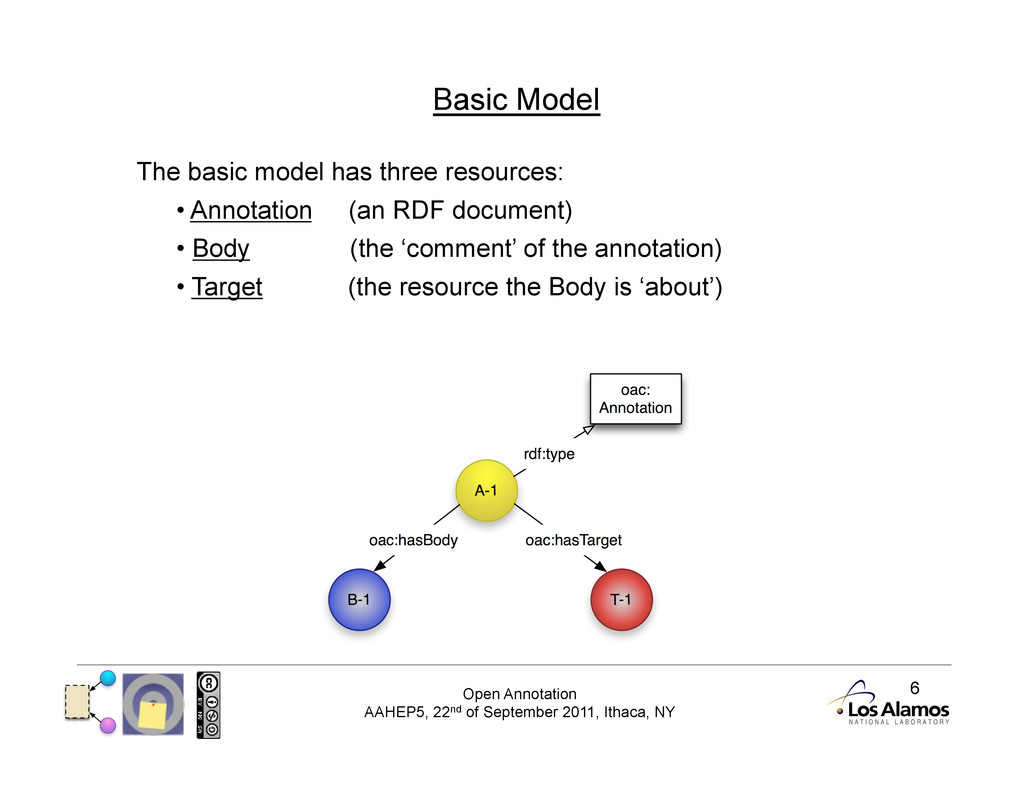
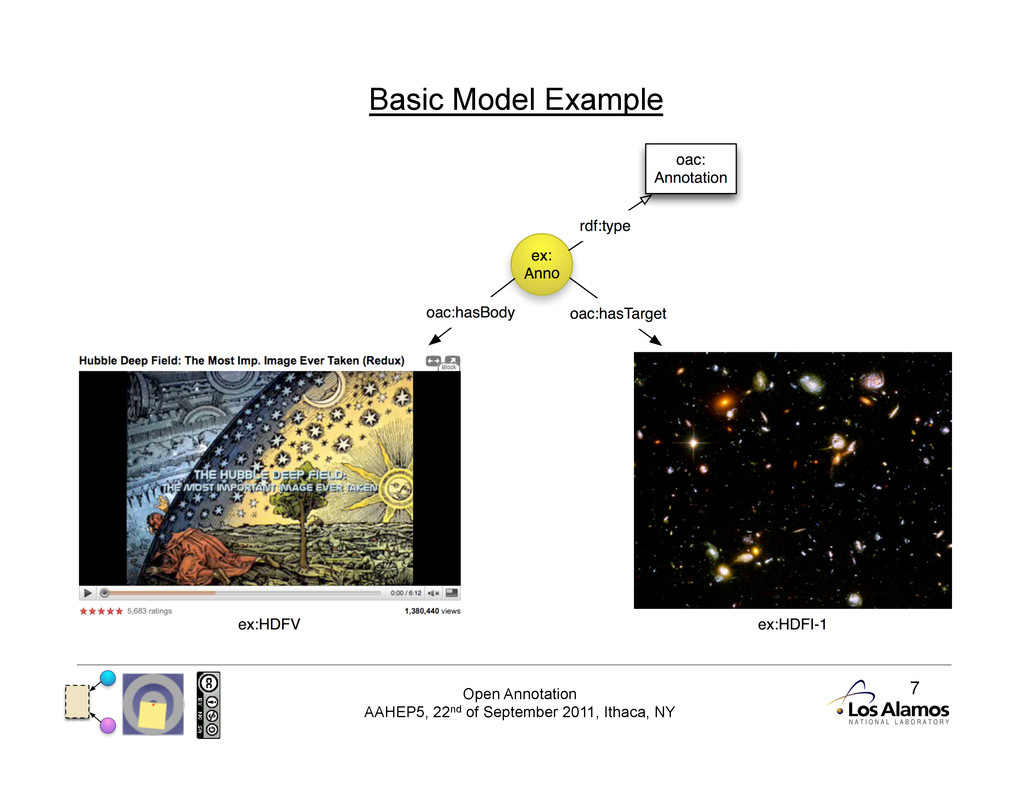
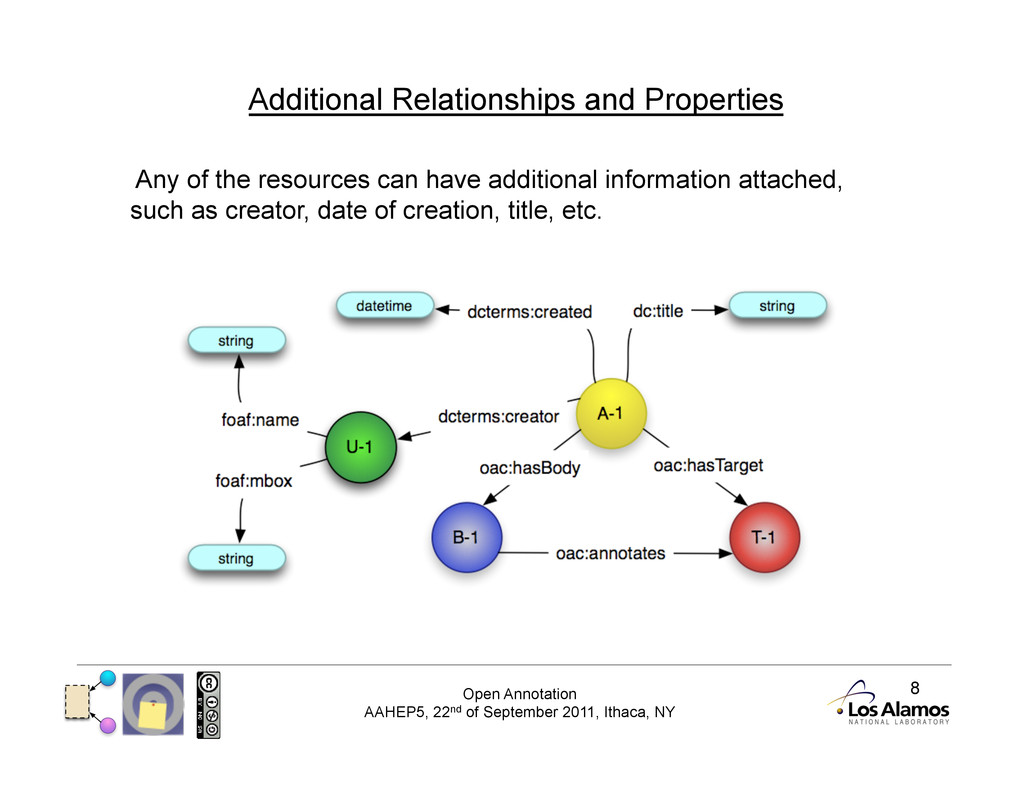
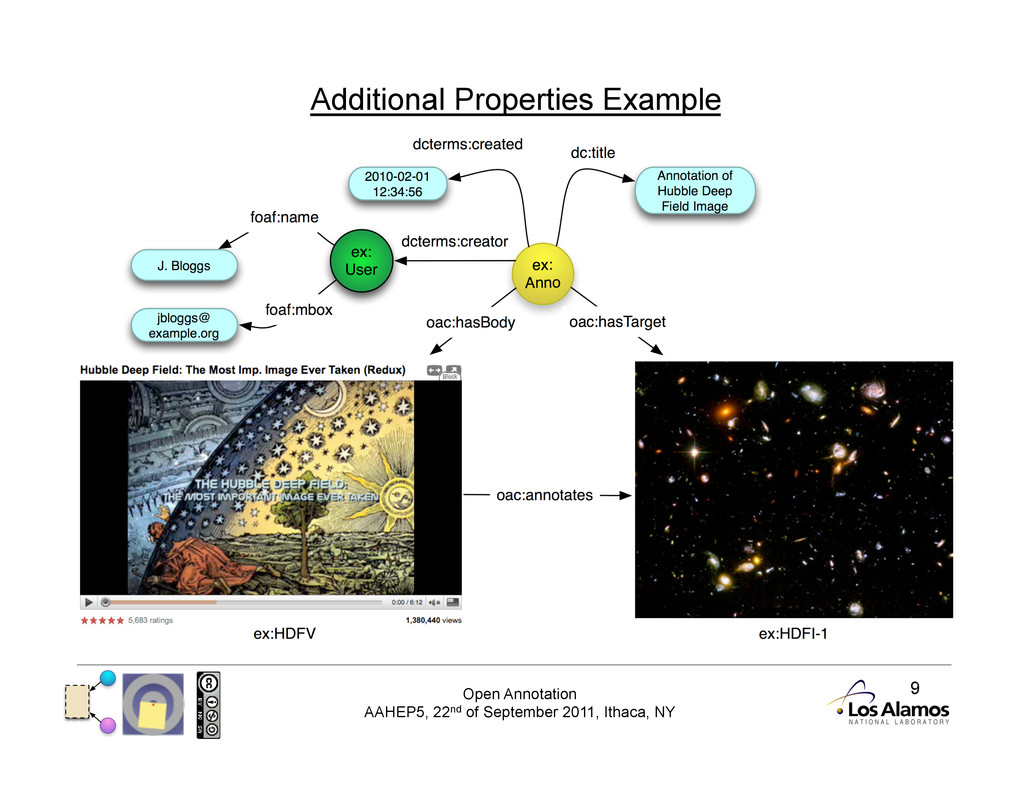
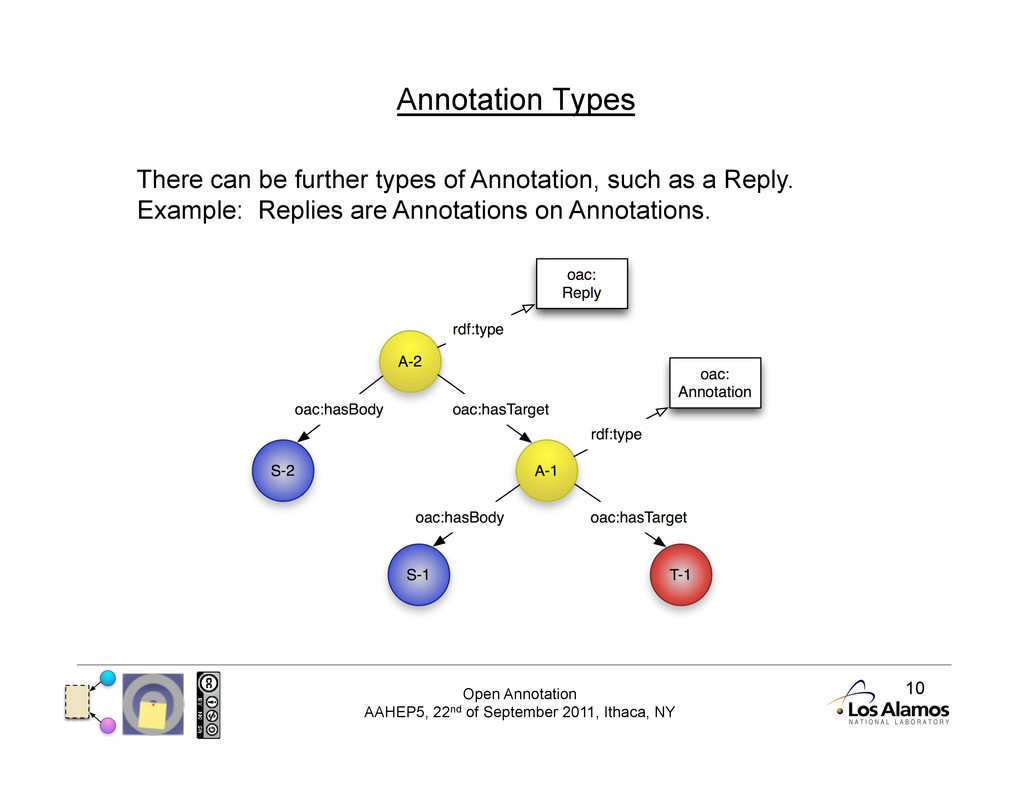
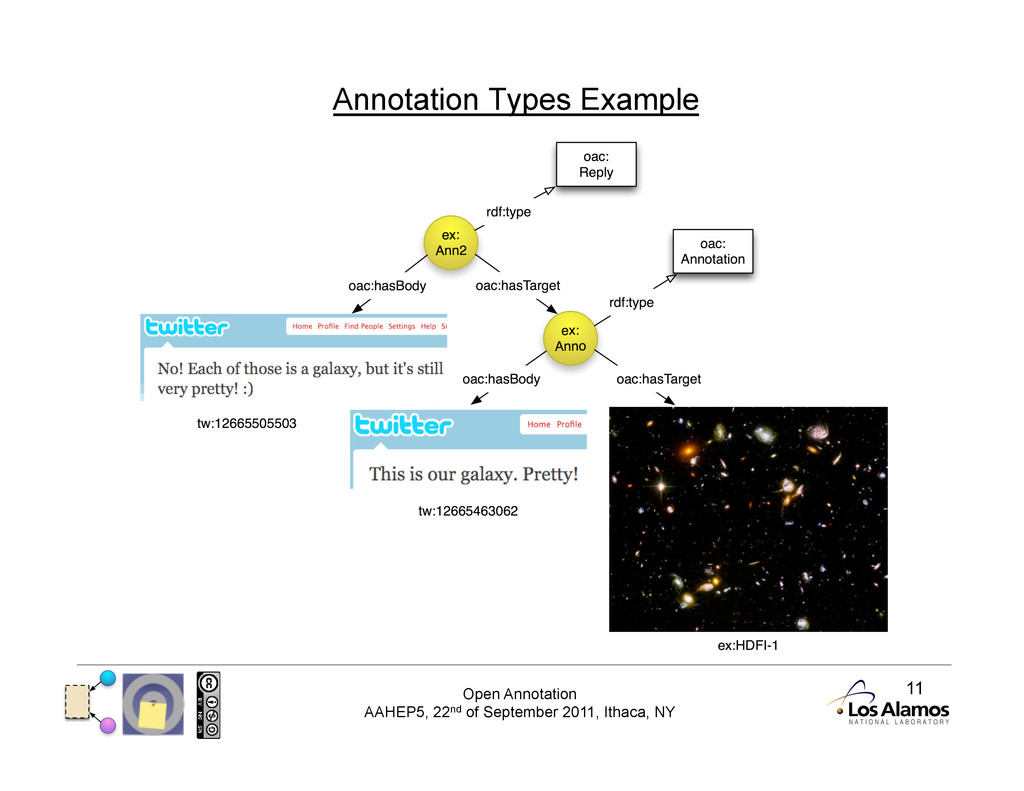
Basic Model The basic model has three resources: • Annotation (an RDF document) • Body (the ‘comment’ of the annotation) • Target (the resource the Body is ‘about’)
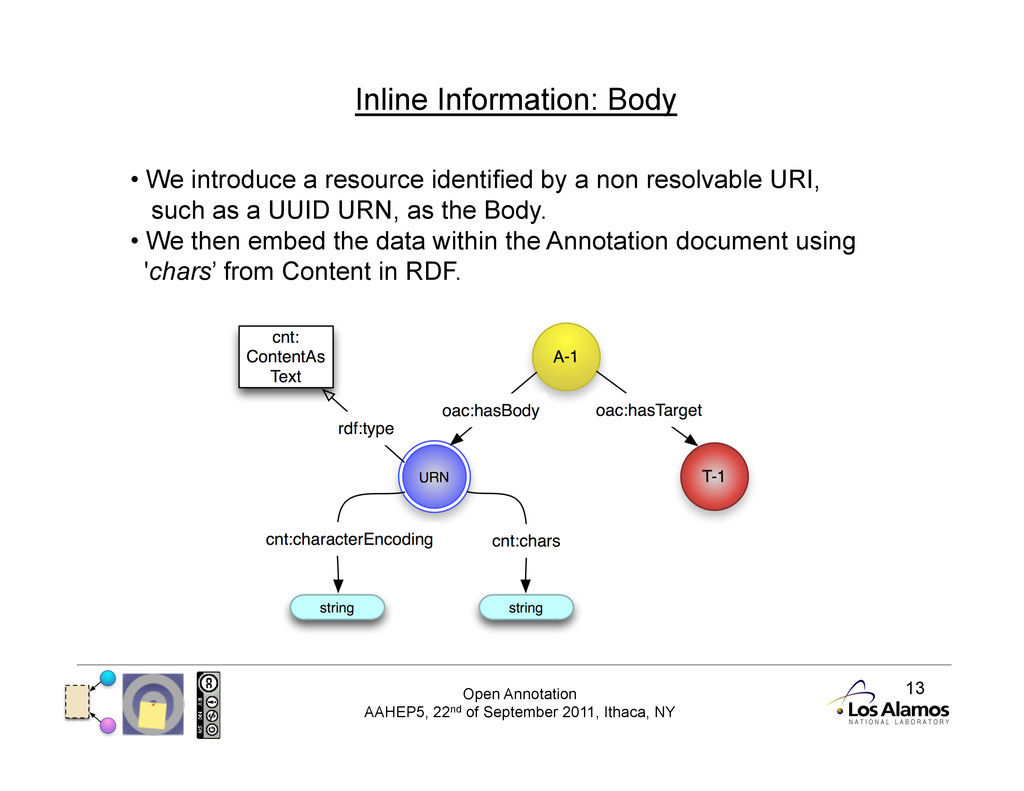
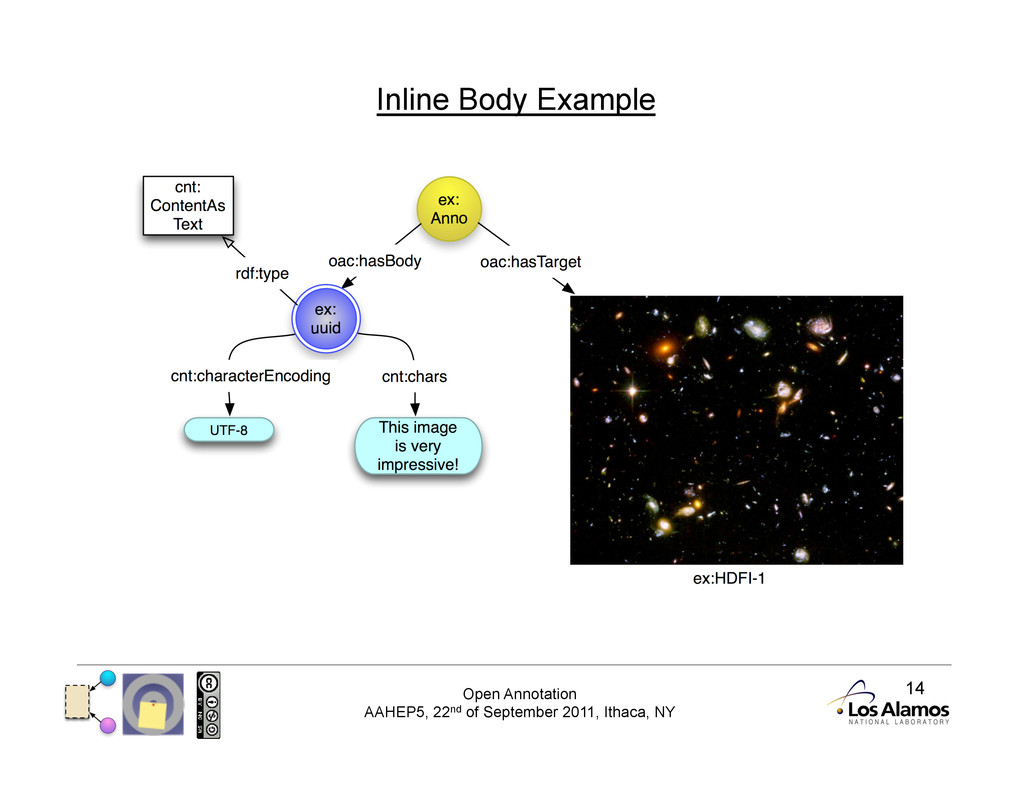
Inline Information It is important to be able to have content contained within the Annotation document for Client Autonomy: • Clients may be unable to mint new URIs for every resource • Clients may wish to transmit only a single document • Third parties can generate new URIs if the client does not The W3C has a Content in RDF specification: • http://www.w3.org/TR/Content-in-RDF10/
Inline Information: Body • We introduce a resource identified by a non resolvable URI, such as a UUID URN, as the Body. • We then embed the data within the Annotation document using 'chars’ from Content in RDF.
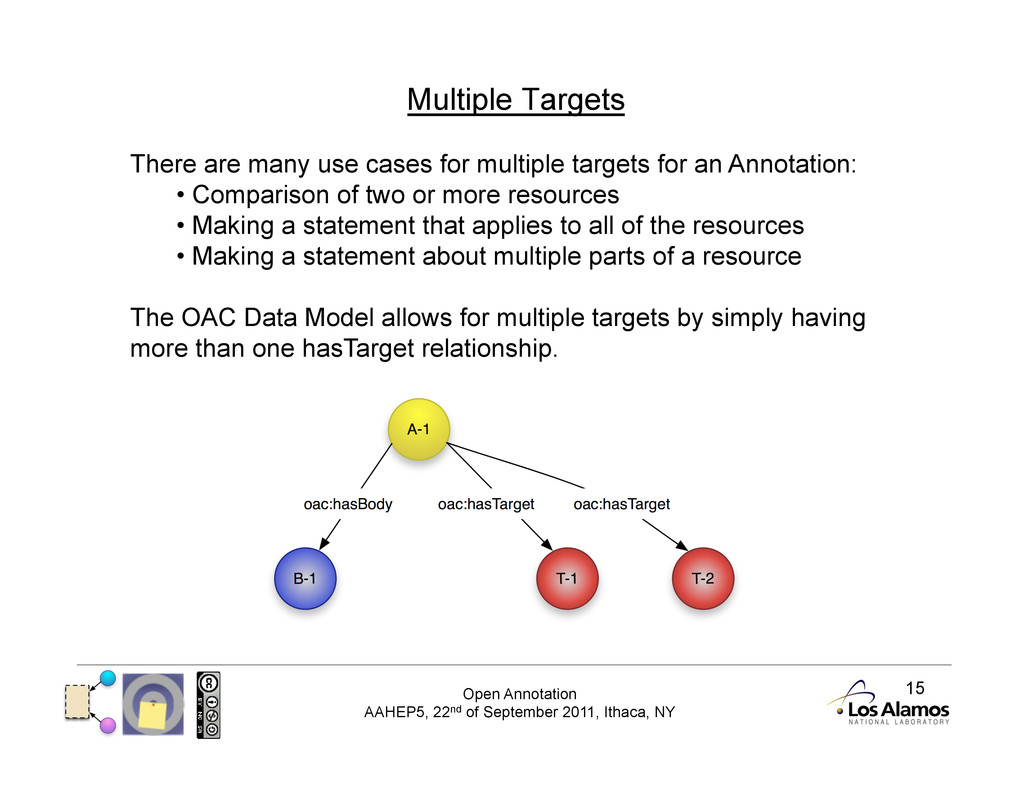
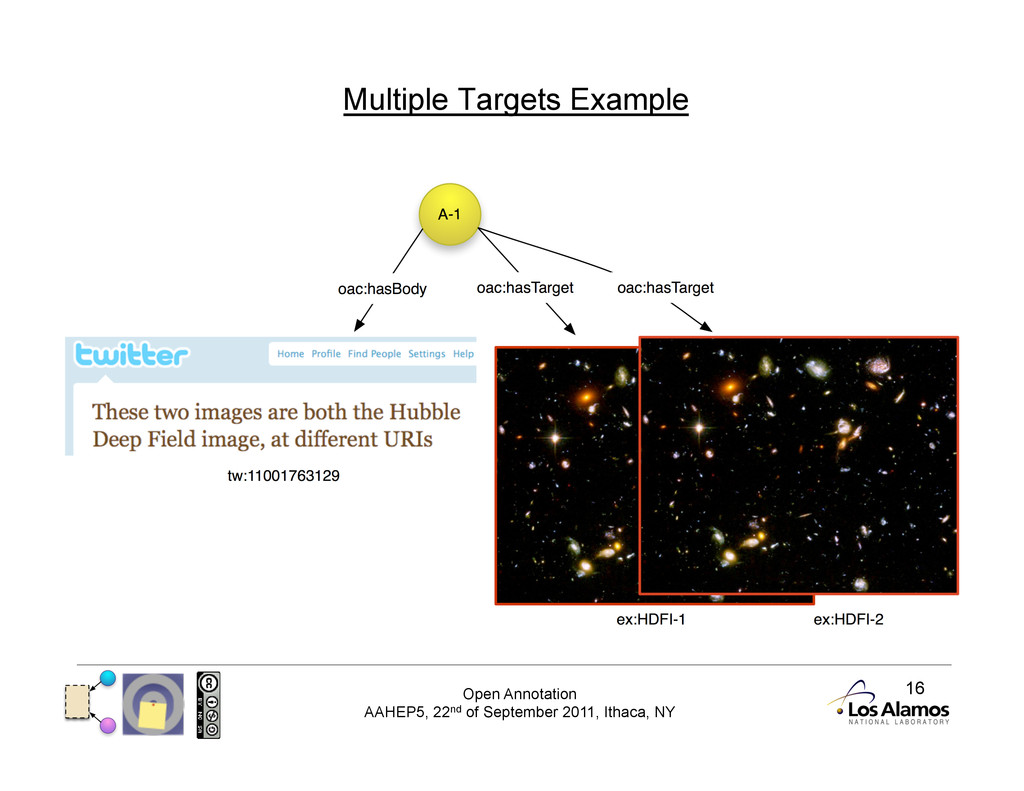
Multiple Targets There are many use cases for multiple targets for an Annotation: • Comparison of two or more resources • Making a statement that applies to all of the resources • Making a statement about multiple parts of a resource The OAC Data Model allows for multiple targets by simply having more than one hasTarget relationship.
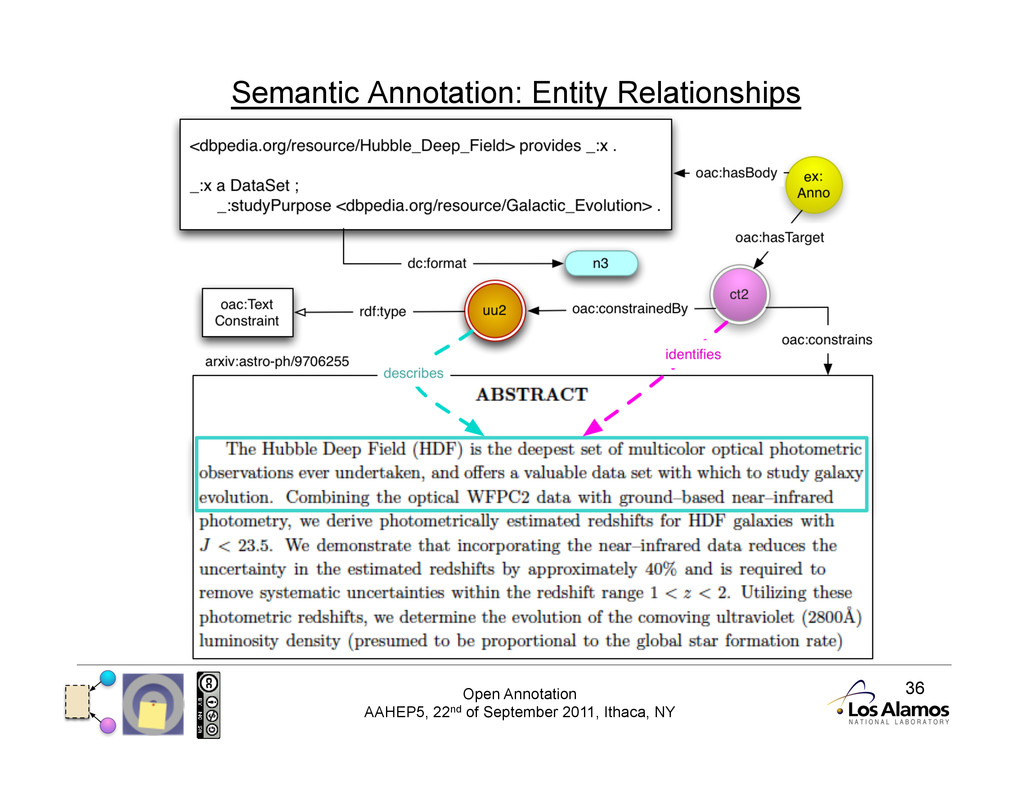
Segments of Resources Most annotations are about part of a resource Different segments for different media types: • Text: paragraph, arbitrary span of words • Image: rectangular or arbitrary shaped area • Audio: start and end time points, track name/number • Video: area and time points • Other: slice of a data set, volume in a 3d object, …
Segments of Resources Web Architecture Segmentation: • A URI with a Fragment identifies part of the resource: • IETF Mime-type fragment identifiers; eg xpointer • W3C Media Fragments URI specification for simple segments of media: http://www.w3.org/TR/media-frags/ We introduce a method of constraining resources: • Introduce an approach for arbitrarily complex segments that cannot be expressed using Fragments • Can be applied to Body or Target resource
Segments of Resources: IETF Fragment URIs URI Fragments are a syntax for creating subsidiary URIs that identify part of the main resource The syntax is defined per media type: • X/HTML: The named anchor or identified element • XML: An XPointer to the element(s) • PDF: Many options, especially page and viewrect • Plain Text: Either by character position or line position
Segments of Resources: W3C Media Fragments Media Fragments allow anyone to create URIs that identify part of an image, audio or video resource. The most common case is for rectangular areas of images: • http://www.example.org/image.jpg#xywh=50,100,640,480 Link to the full resource as well, for all Fragment URIs
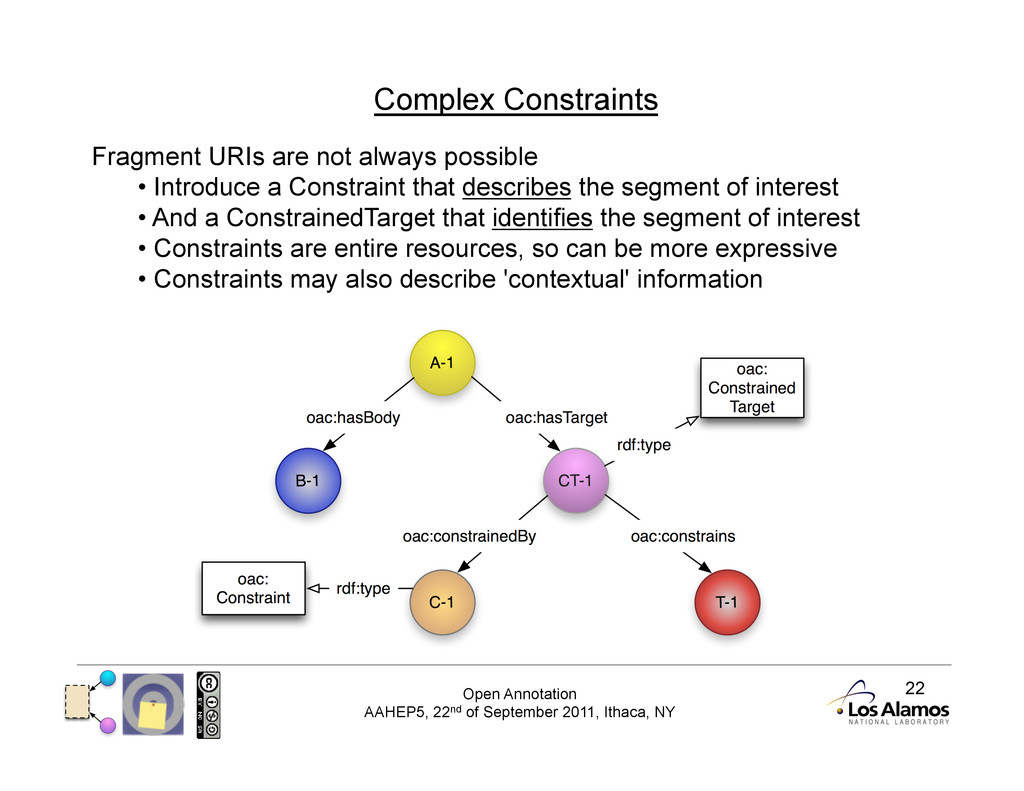
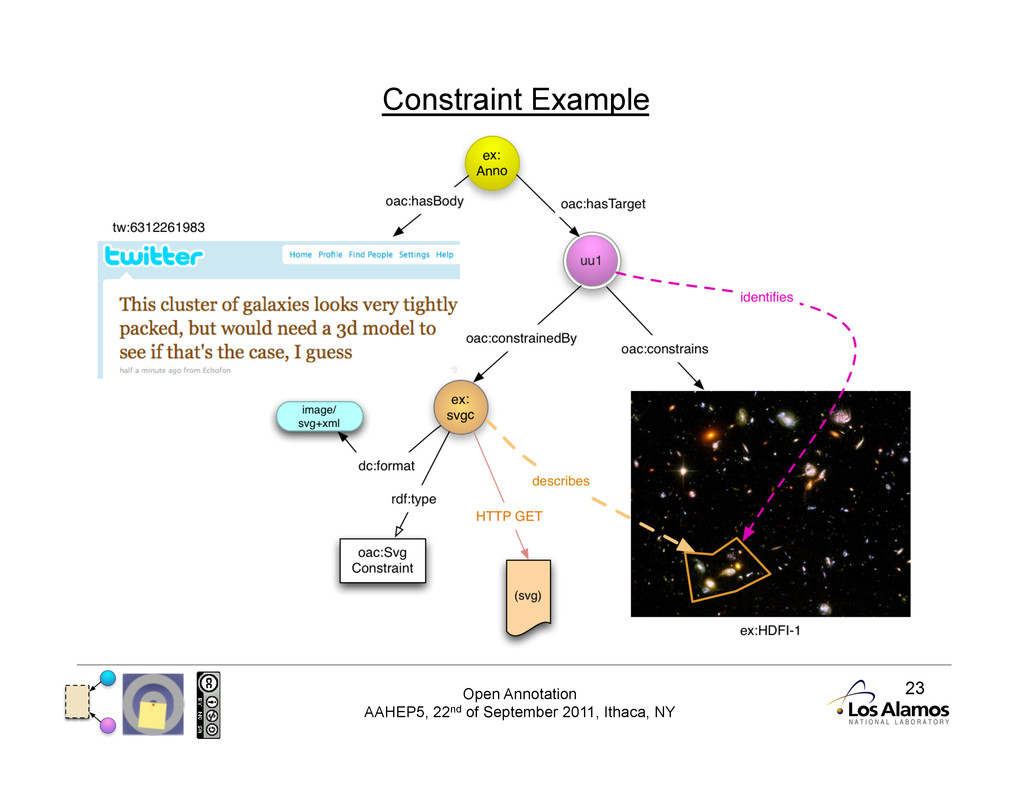
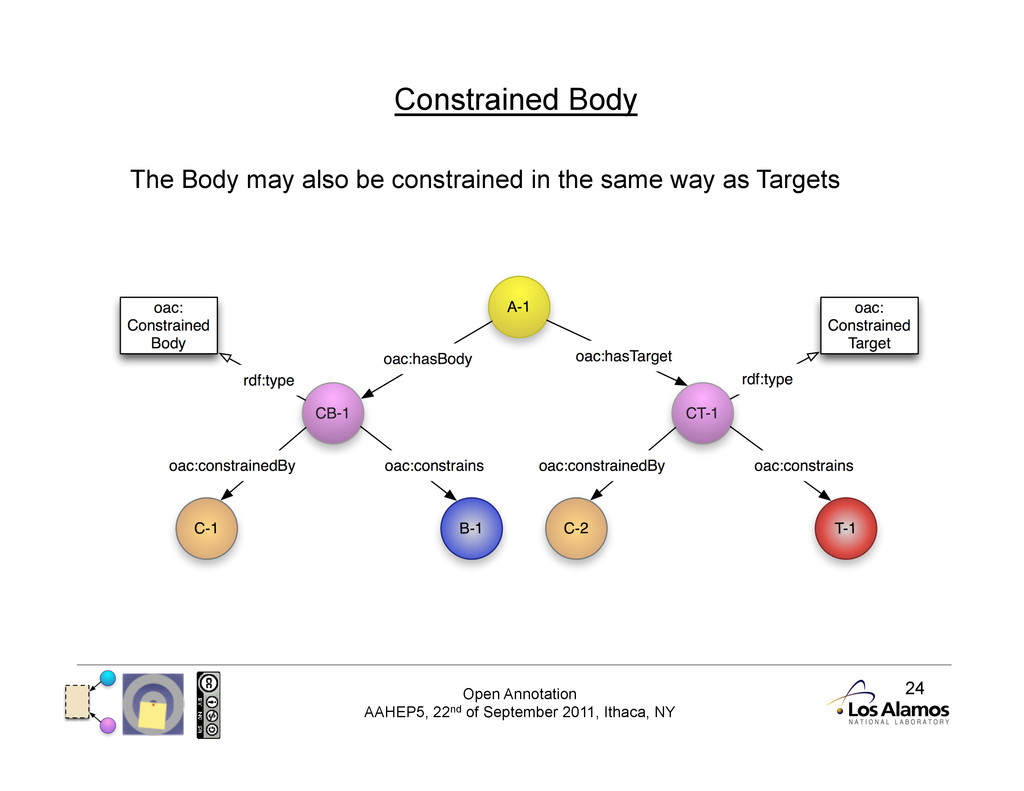
Complex Constraints Fragment URIs are not always possible • Introduce a Constraint that describes the segment of interest • And a ConstrainedTarget that identifies the segment of interest • Constraints are entire resources, so can be more expressive • Constraints may also describe 'contextual' information
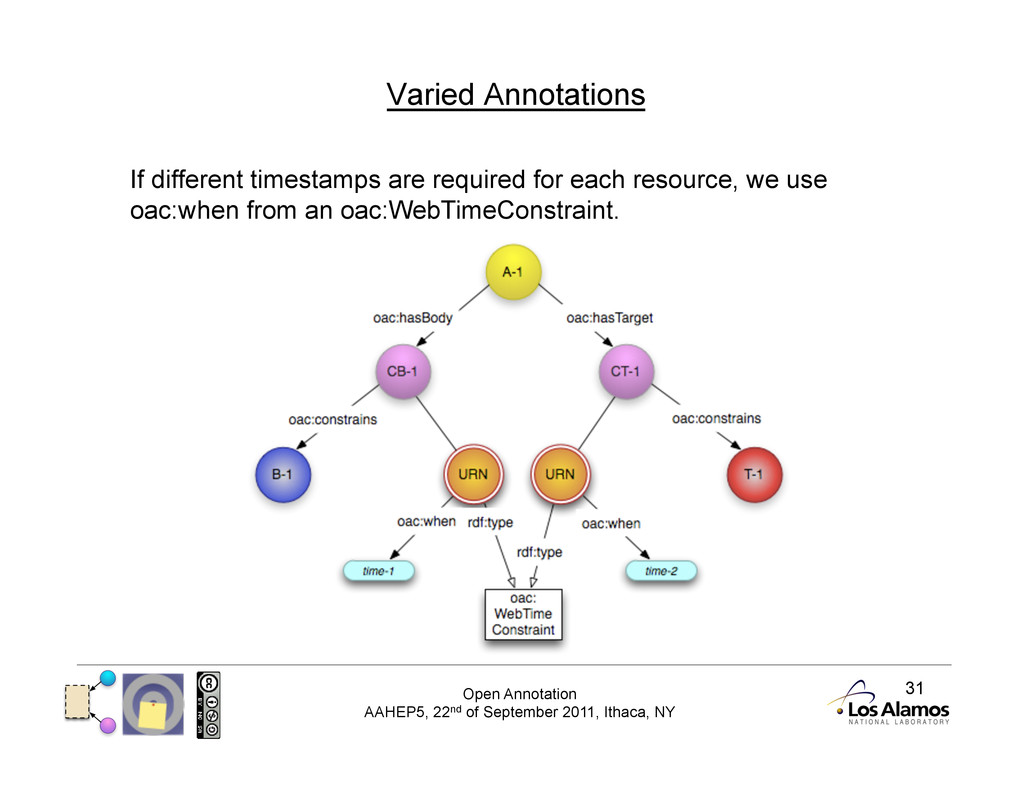
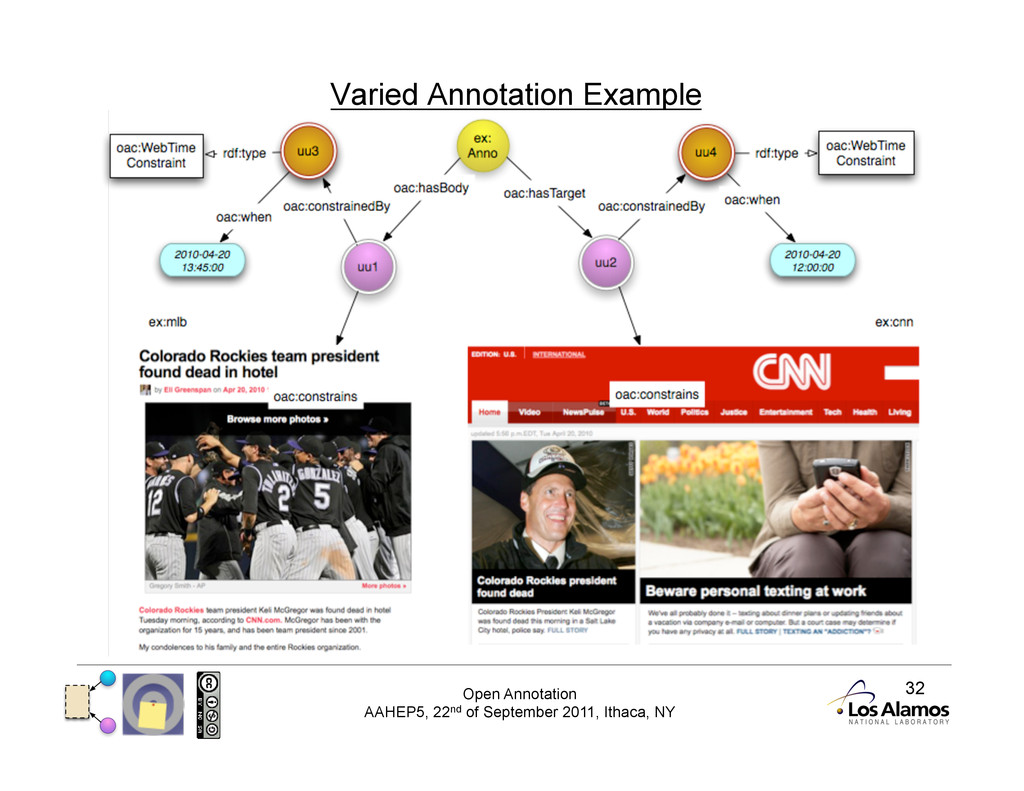
Annotations and Time There are three different types of Annotation with respect to Time: • Timeless Annotations • These are always relevant, regardless of the current state of the resources. This is the base model. • Uniform Annotations • There is a single timestamp at which all of the resources should be considered. • Varied Annotations • Each of the resources (Body, Targets) should be considered at a different time. 2
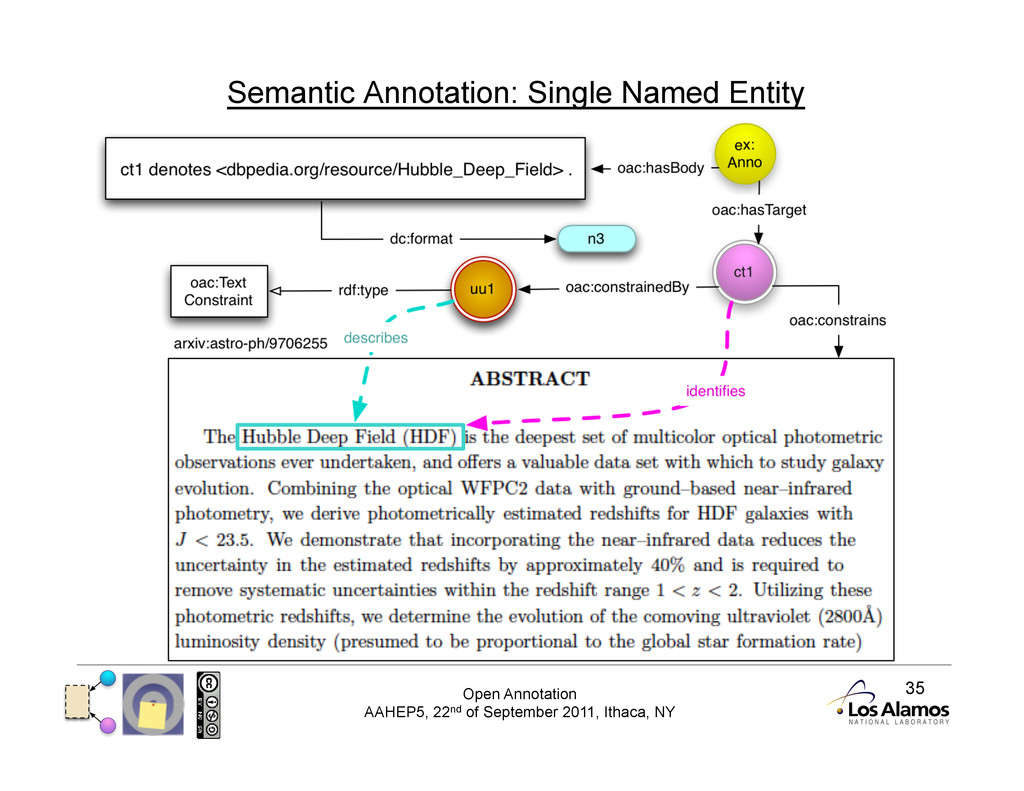
Annotations for/by Machines? • The Body consists of one or more Statements • Human understandable: Text, Image, Video, Symbols, … • Machine understandable: Data • Humans can infer relationships and context, Machines cannot • Need to be as explicit as possible • Need structured information • When would we do this? • Attaching data to another resource • Nano-Publications: publication of data for further processing • Semantic Annotations 3
Advantages of this Approach 3 • Only uses existing OAC constructions • No new ‘isTopicOf’ or similar shortcut relationships • Creator of Body is not confused with Creator of Annotation! • Aligns very closely with human annotation practices • Consistent model that scales from resource to part of resource • Can annotate data extracted at most appropriate level • Could extract from sentence/paragraph/section/entire text • Consistent model that allows association of any amount of data: • From Single Entity • To scholarly discourse extraction from entire document
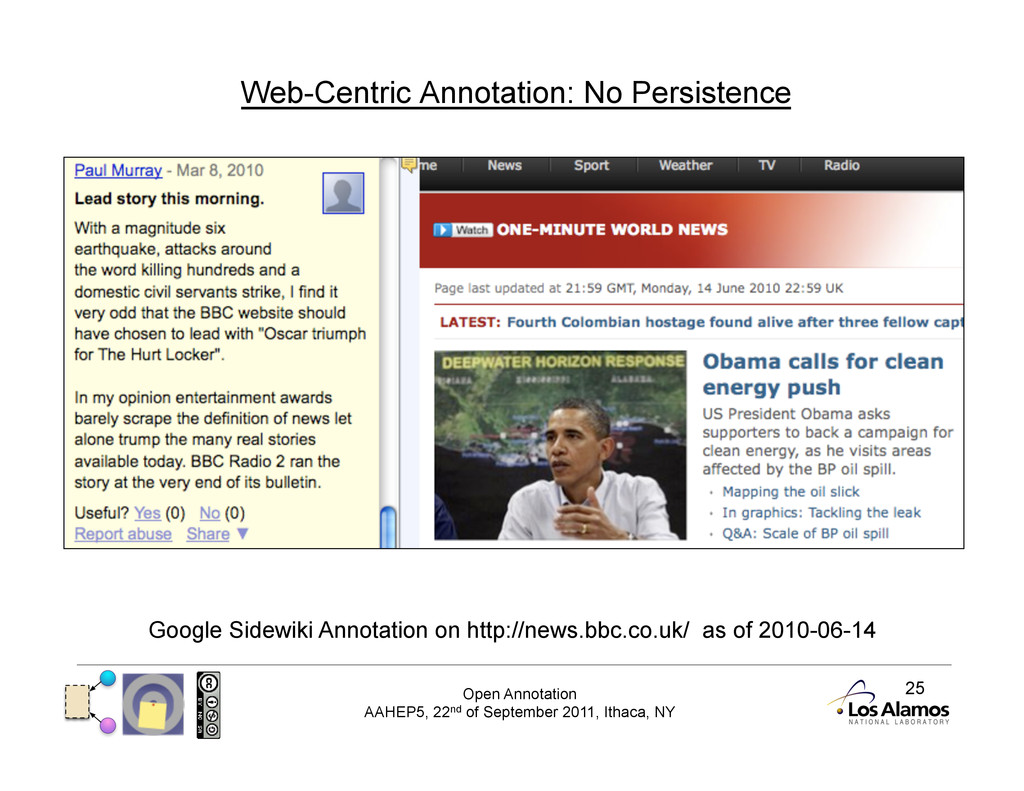
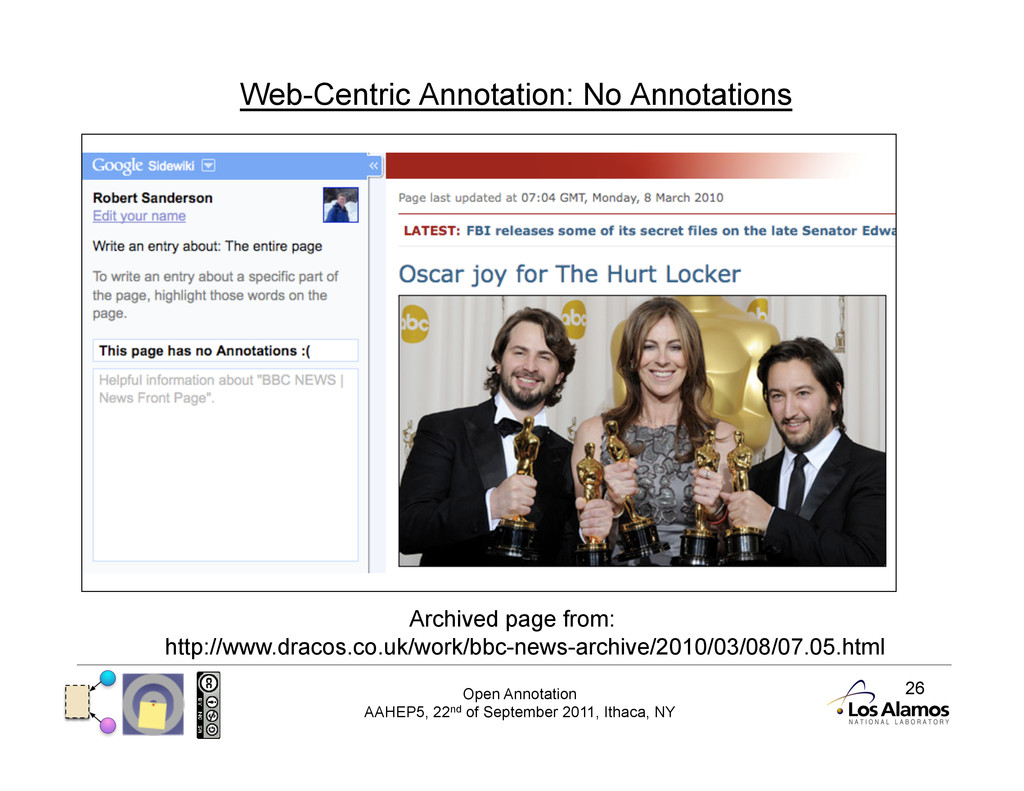
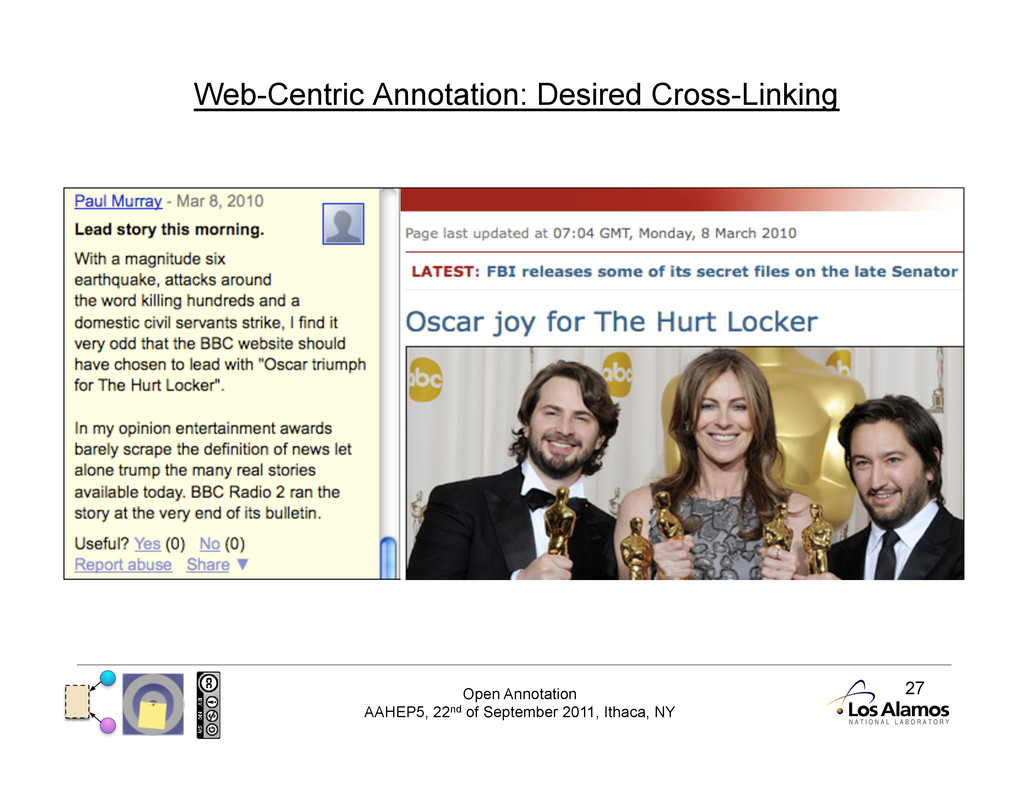
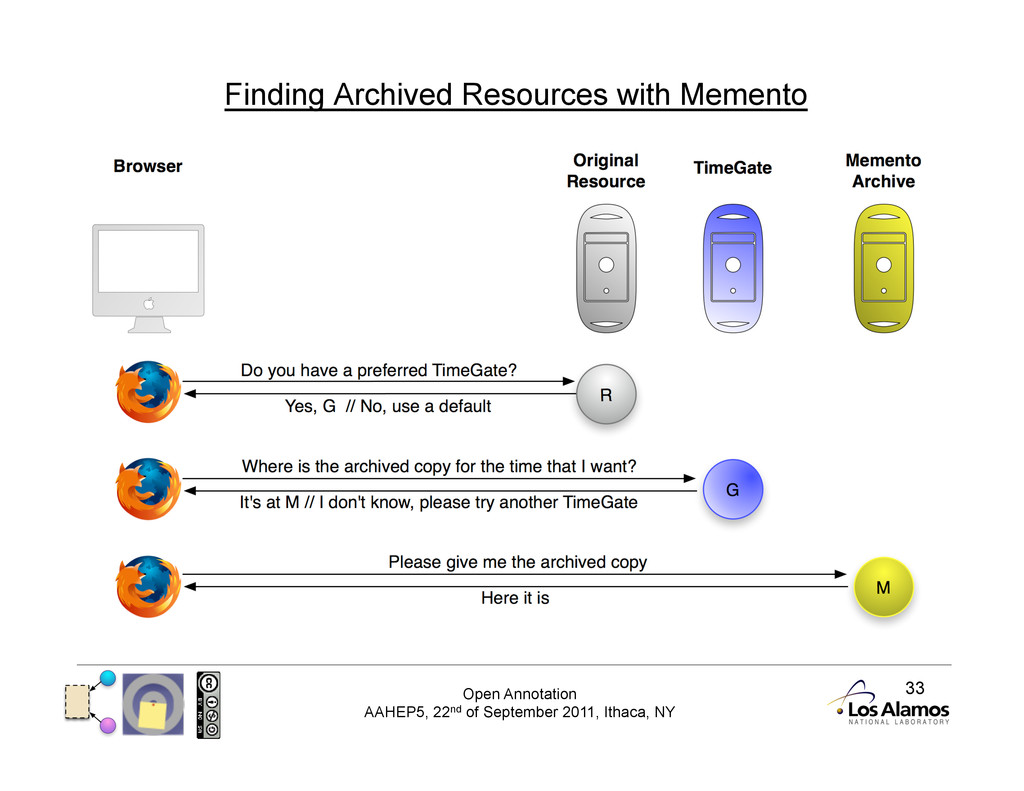
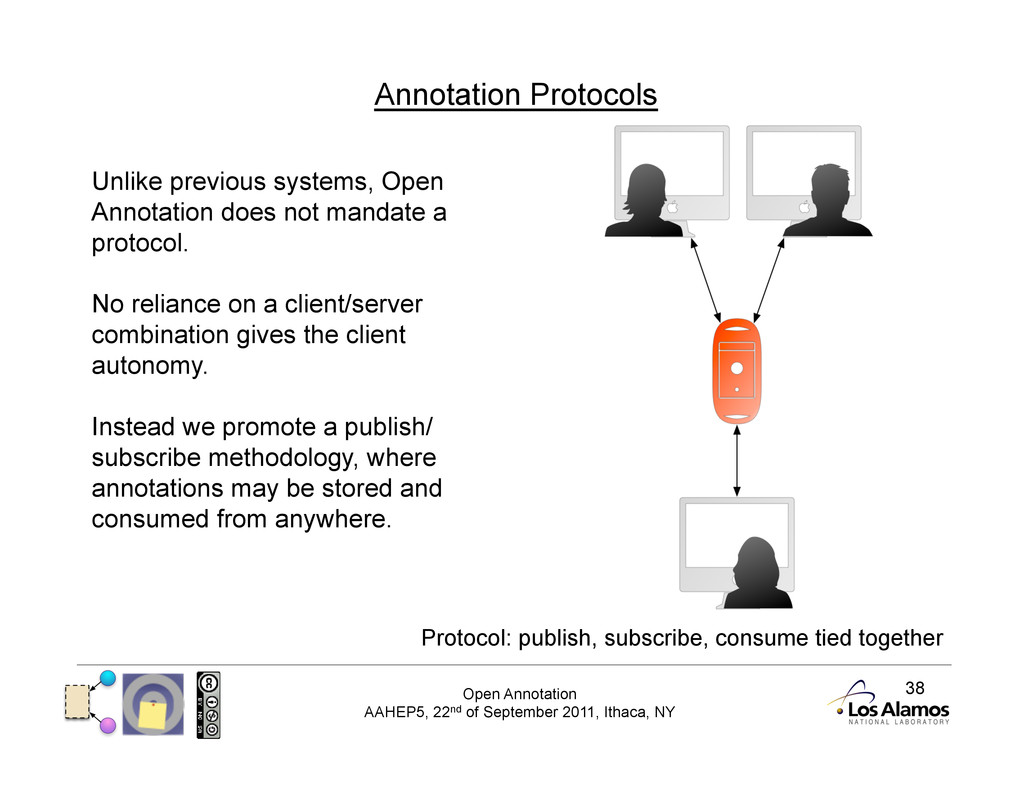
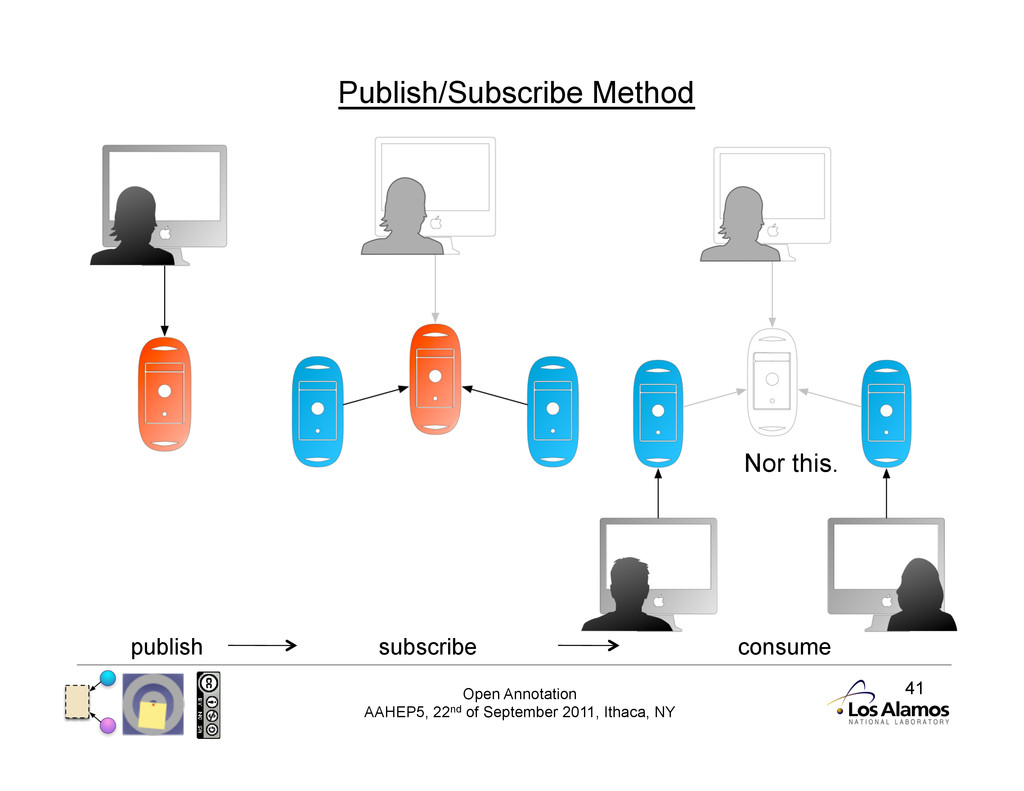
Annotation Protocols Protocol: publish, subscribe, consume tied together Unlike previous systems, Open Annotation does not mandate a protocol. No reliance on a client/server combination gives the client autonomy. Instead we promote a publish/ subscribe methodology, where annotations may be stored and consumed from anywhere.
4 Publish/Subscribe Advantages • Client can use most appropriate method for transferring annotation to storage service • May already be specified in certain domains • Can use existing services without requiring direct adoption • Annotations are web resources in their own right • Can be protected for limited access using existing technology • Have their own URIs by necessity, not good-will of service • Promotes a market-place of services • Archiving Annotations and resources for preservation • Enriching with additional metadata and information • Aggregation and curation to provide trusted annotation feeds
4 Demo! http://www.shared-canvas.org/impl/demo3/ • Took the PDF of Dirac’s thesis on Quantum Mechanics and split into individual page images • Allow transcription by annotation, and commentary by annotation • Allows storage at different services, both public and private
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}