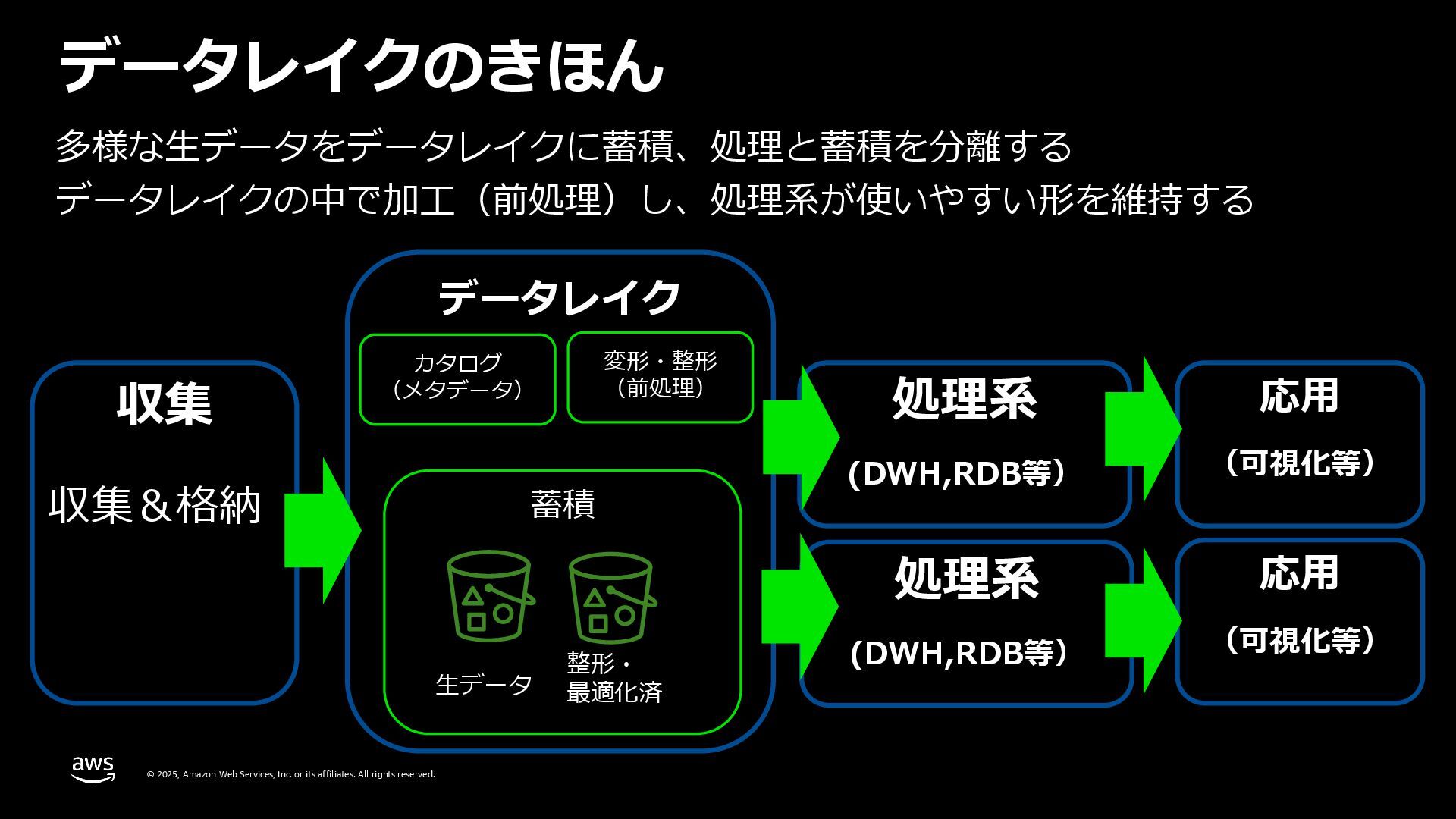
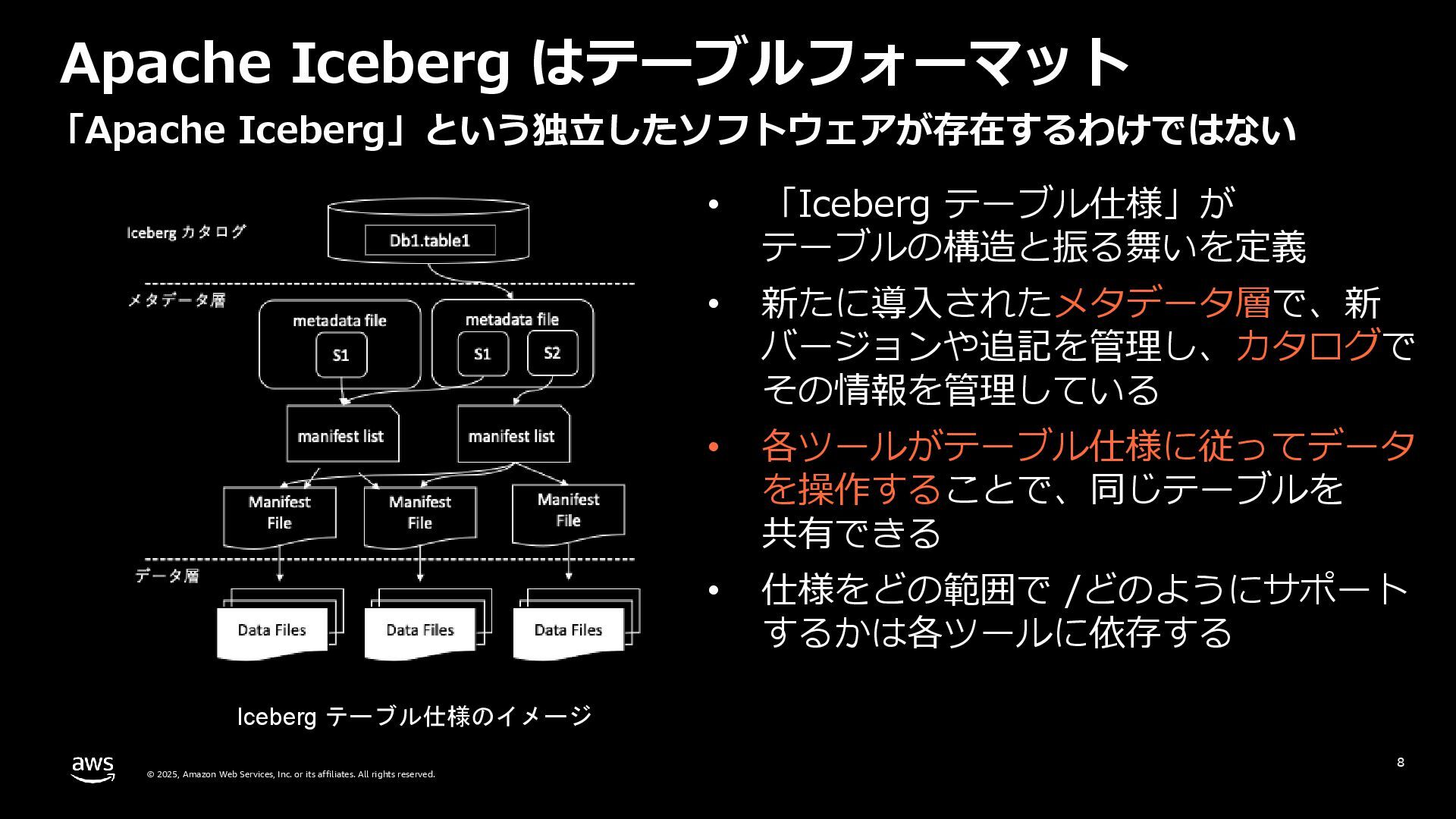
Serverless Days Tokyo 2025 Day 2(2025.9.21)での「Apache Icebergを体験しよう! サーバーレスのAthenaとS3で Iceberg に入門する」の説明資料です。Icebergの基本的な内容と、AWS上でIcebergを使う上で基本的な考え方を説明したものです。
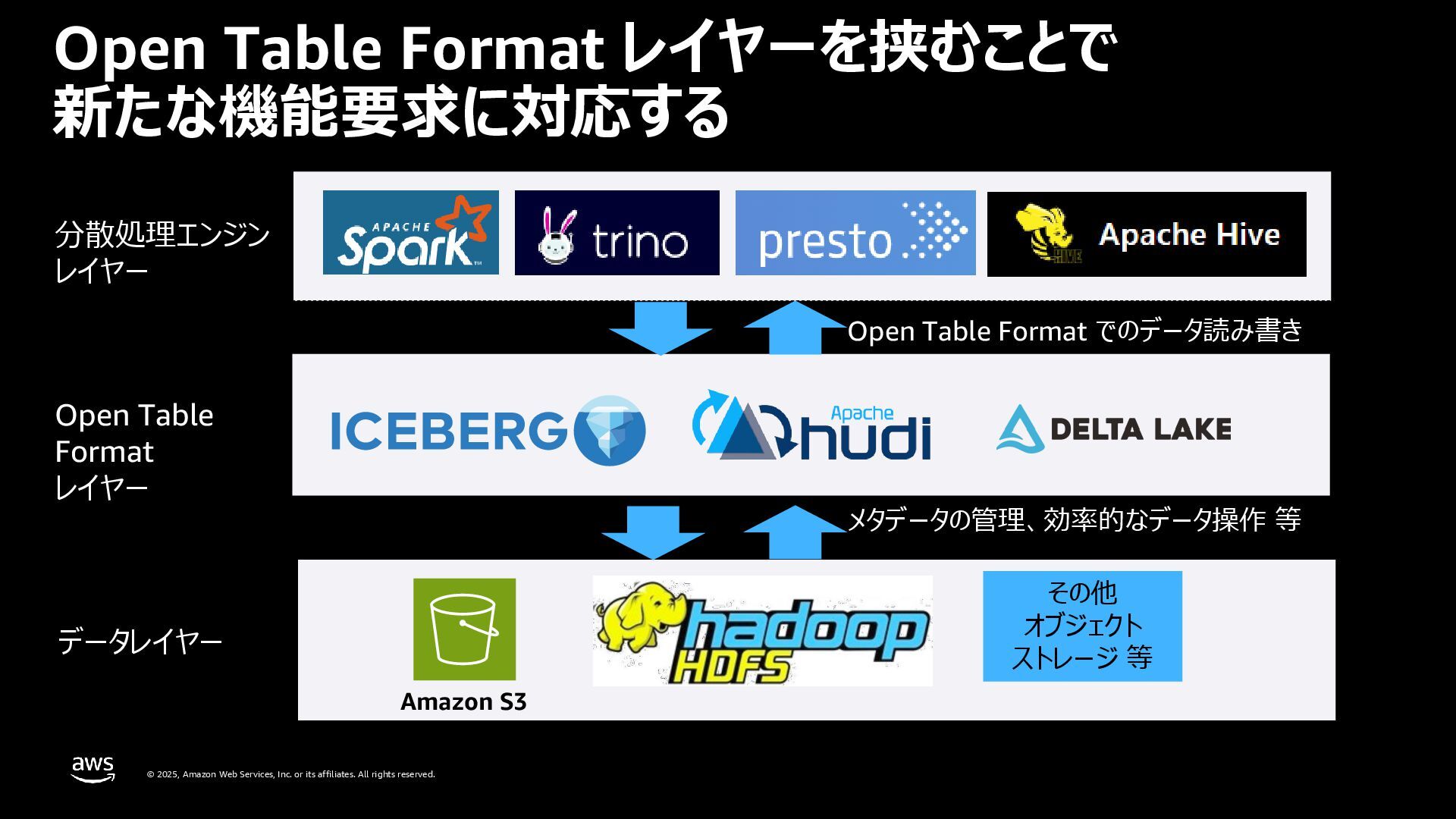
rights reserved. Open Table Format レイヤーを挟むことで 新たな機能要求に対応する Amazon S3 その他 オブジェクト ストレージ 等 Open Table Format レイヤー Open Table Format でのデータ読み書き メタデータの管理、効率的なデータ操作 等 分散処理エンジン レイヤー データレイヤー
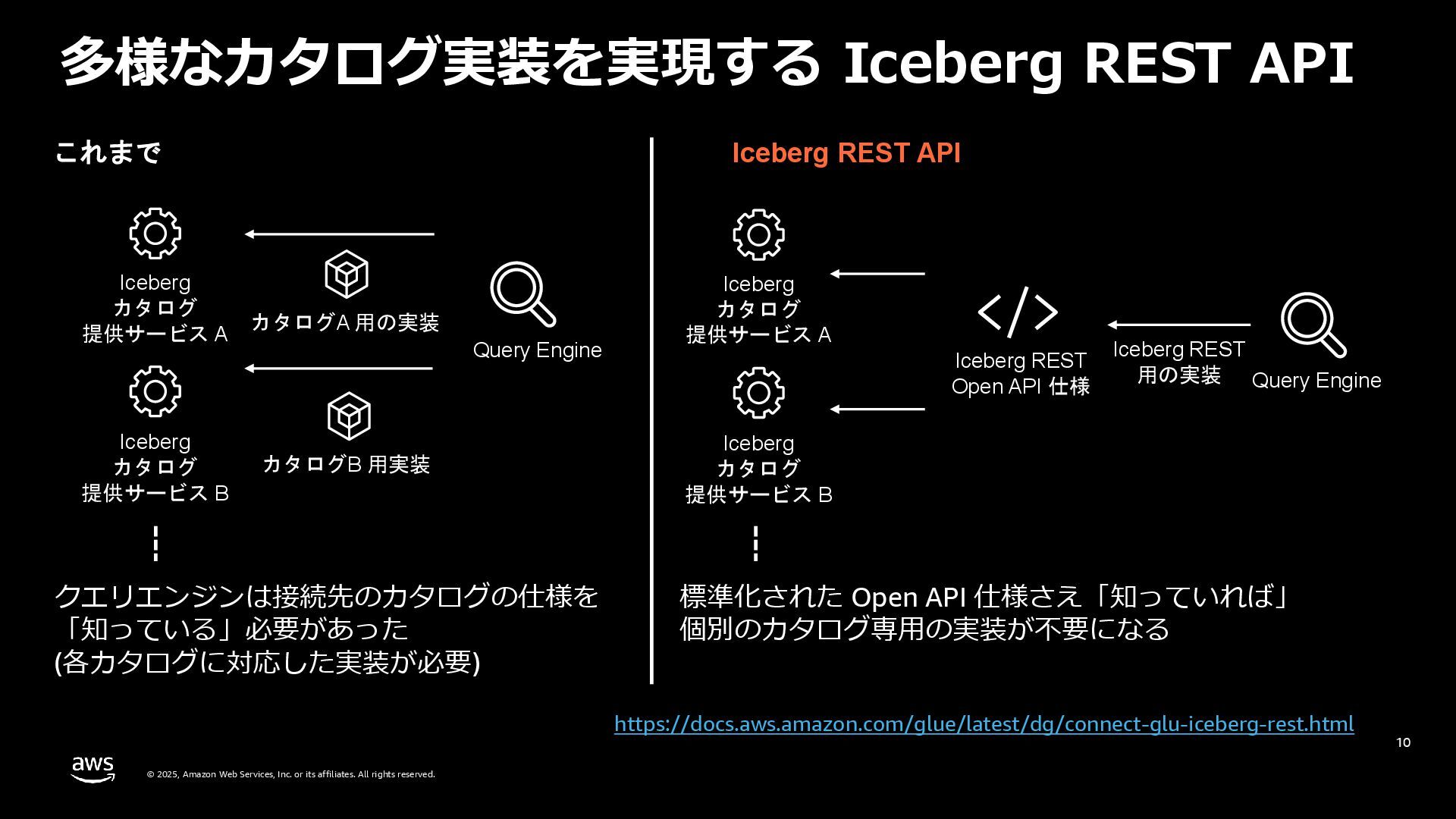
rights reserved. 多様なカタログ実装を実現する Iceberg REST API 10 https://docs.aws.amazon.com/glue/latest/dg/connect-glu-iceberg-rest.html Query Engine Iceberg カタログ 提供サービス A Iceberg カタログ 提供サービス B カタログA 用の実装 カタログB 用実装 これまで Iceberg REST API Query Engine Iceberg REST Open API 仕様 Iceberg REST 用の実装 クエリエンジンは接続先のカタログの仕様を 「知っている」必要があった (各カタログに対応した実装が必要) 標準化された Open API 仕様さえ「知っていれば」 個別のカタログ専用の実装が不要になる Iceberg カタログ 提供サービス A Iceberg カタログ 提供サービス B
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}