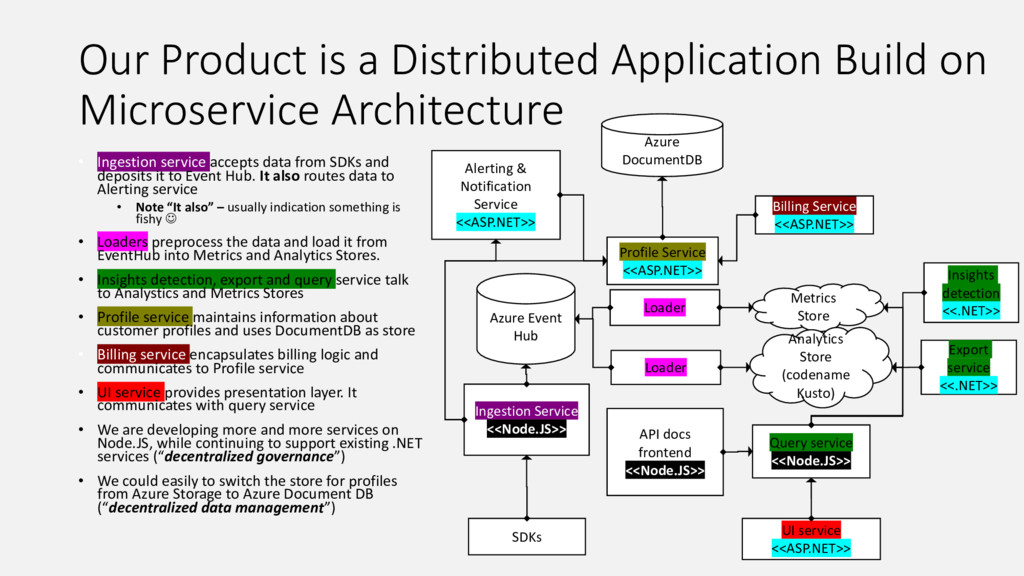
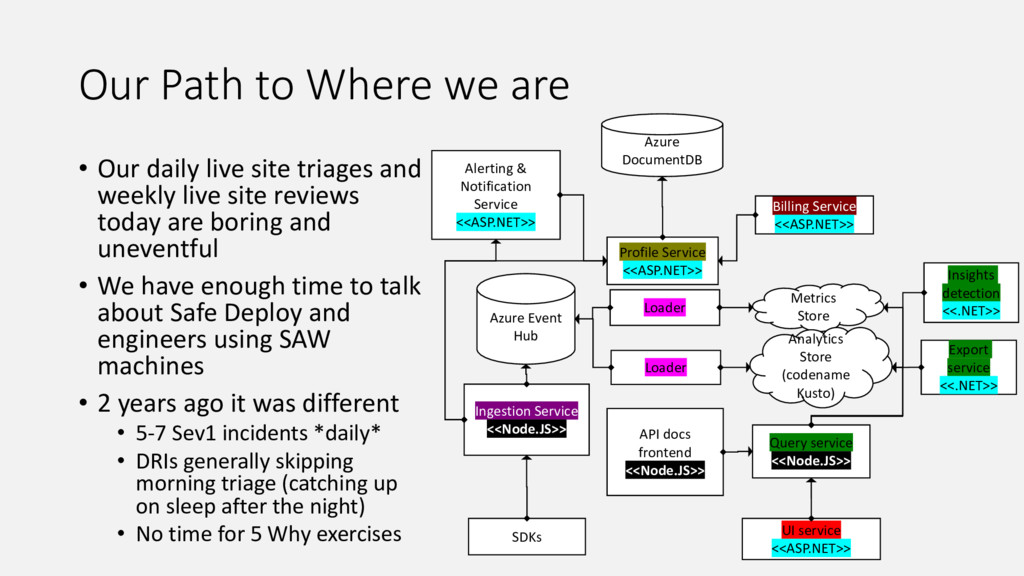
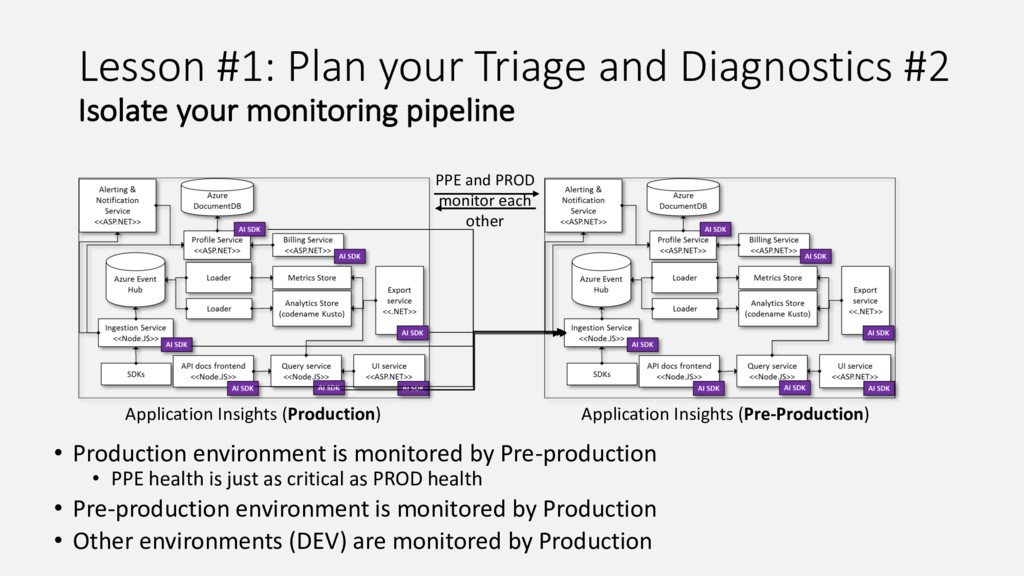
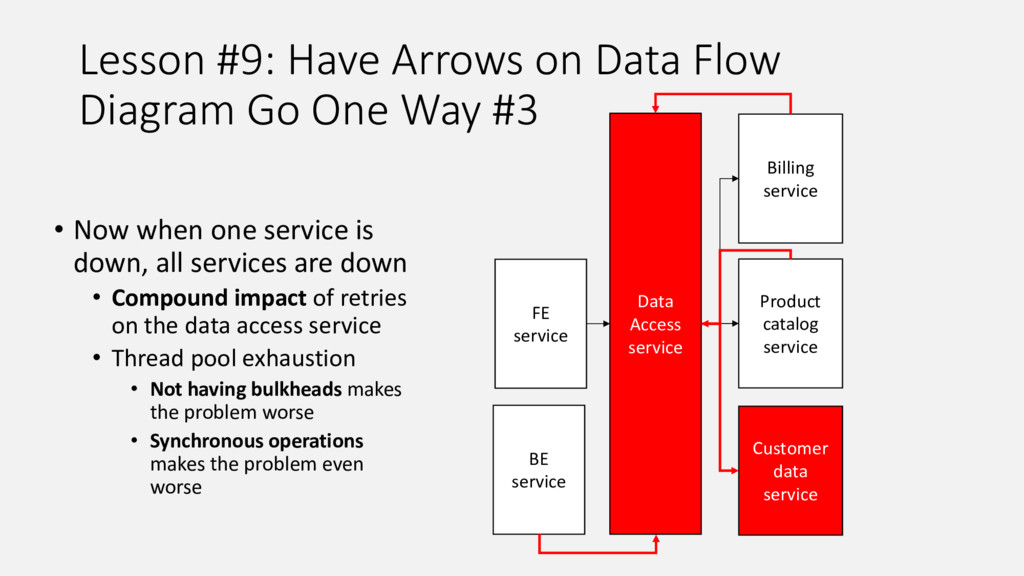
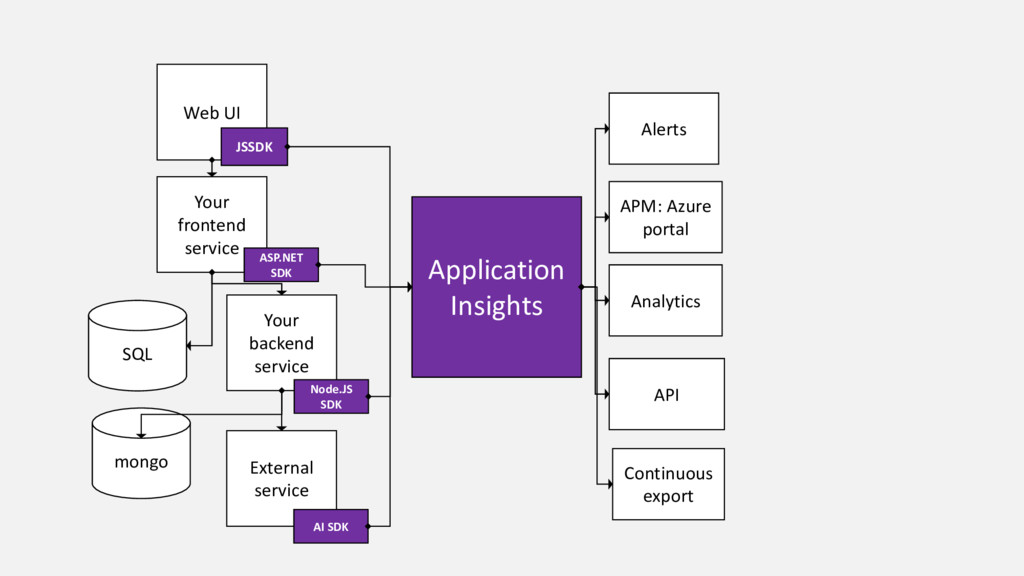
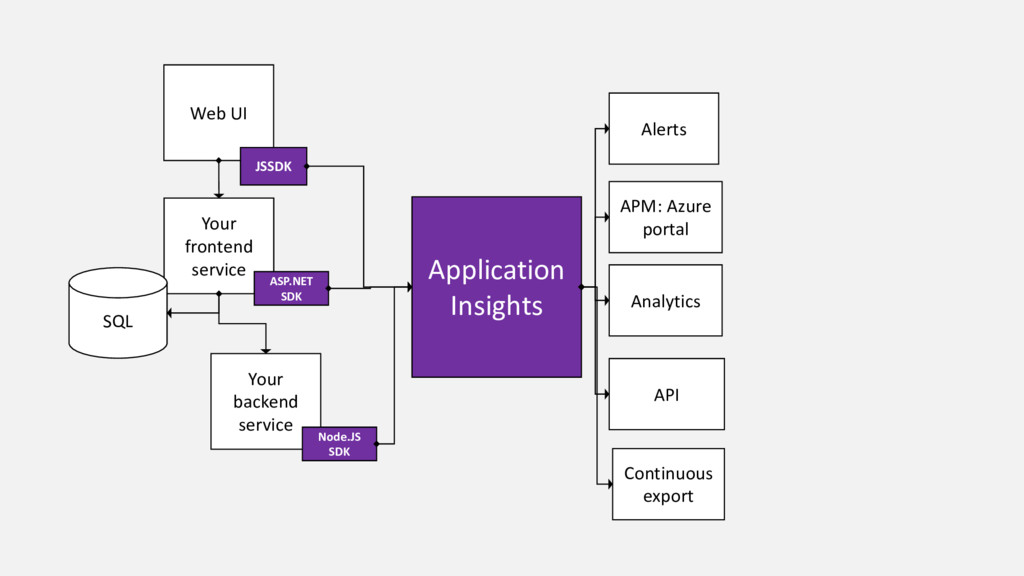
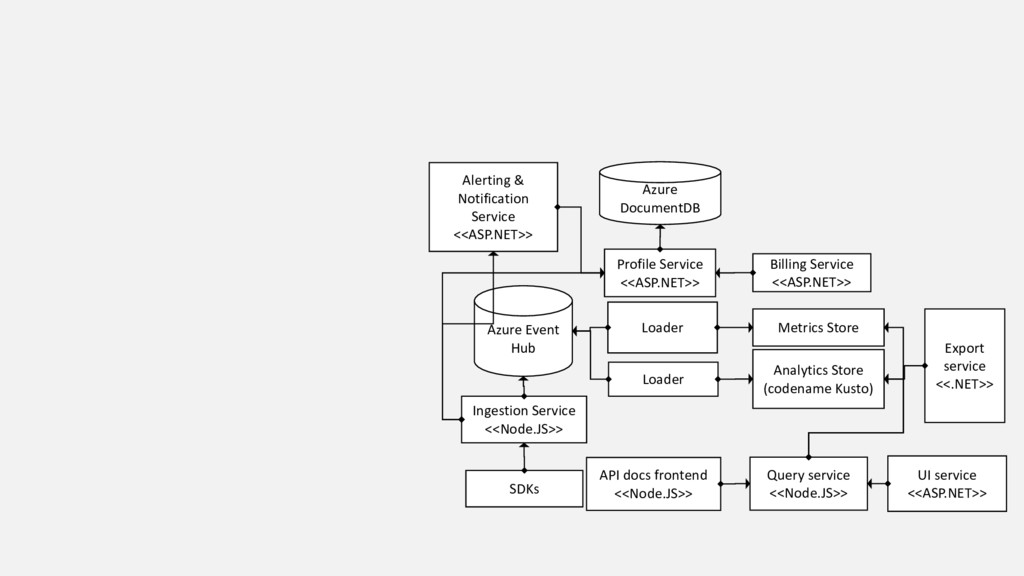
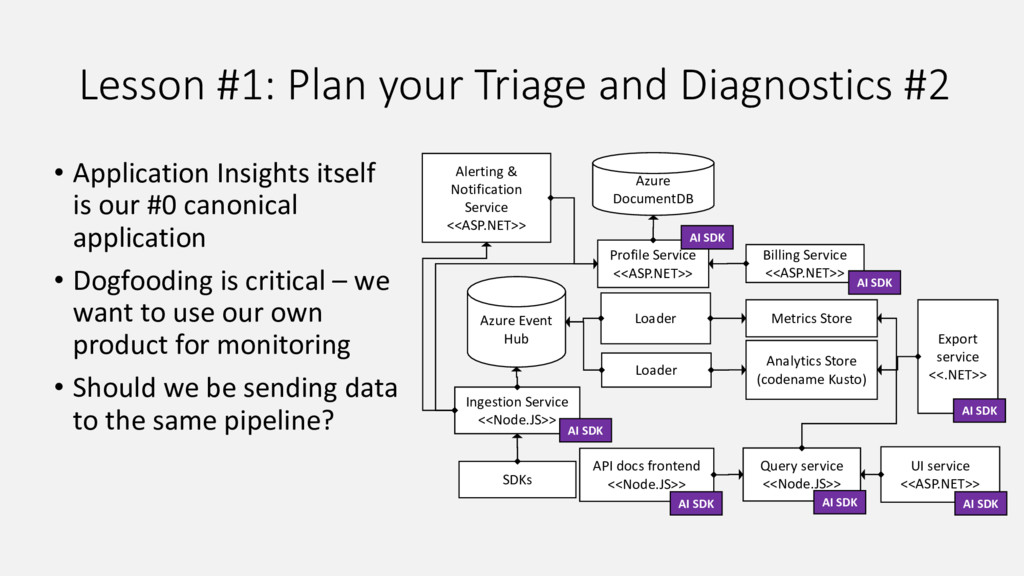
Our product, Microsoft Application Insights, is a service that collects telemetry data that customers are sending to us, processes and aggregates it, and makes aggregated data available for query. Internally we have a microservice architecture with each service of the pipeline responsible for doing its share and passing the data to the next service in the pipeline. This talk summarizes lessons we learnt as we improved our live site operations and stability from having on average 5-7 Sev1-2 incidents daily 2 years ago to the same number of incidents per month. Every incident we had offered unique opportunity to learn how to improve our system and also how to build our product such that it is easier to detect and diagnose similar issues for our customers.
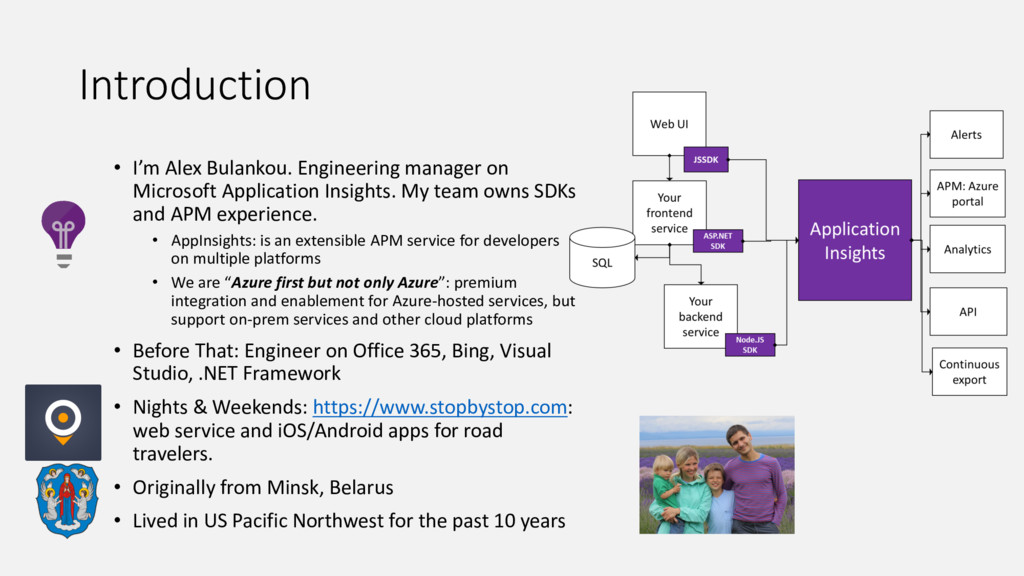
Alex is a software development manager at Microsoft Application Insights, a service that helps to detect, triage and diagnose issues with web applications and services. Prior to that Alex was a developer on Visual Studio, Bing and Office 365 teams building UX and data visualizations for client and web platforms. As a hobby Alex is bootstrapping an Open Street Map service that helps road travellers find places to stop along the way to their destination: www.stopbystop.com.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
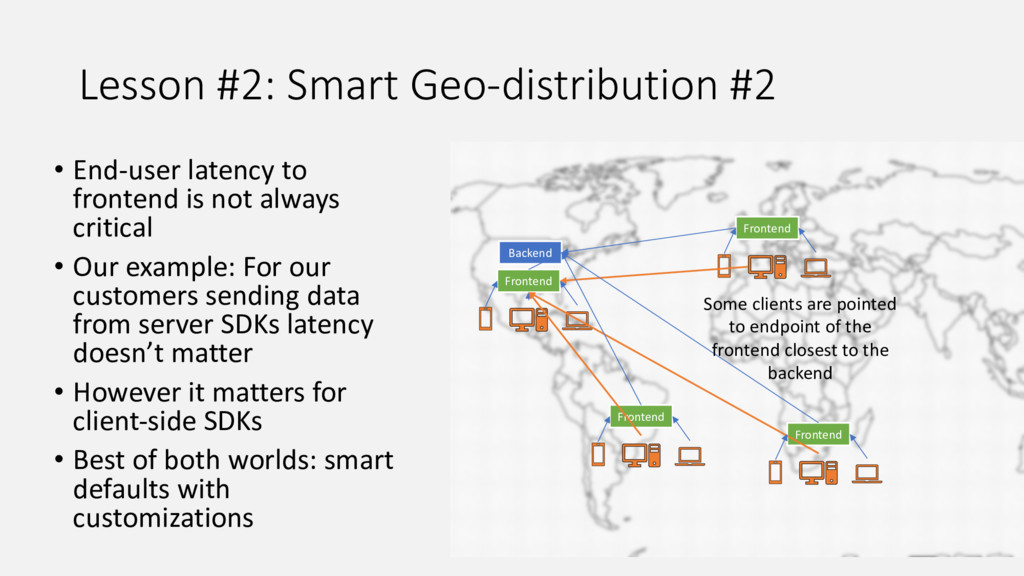{kind=link}
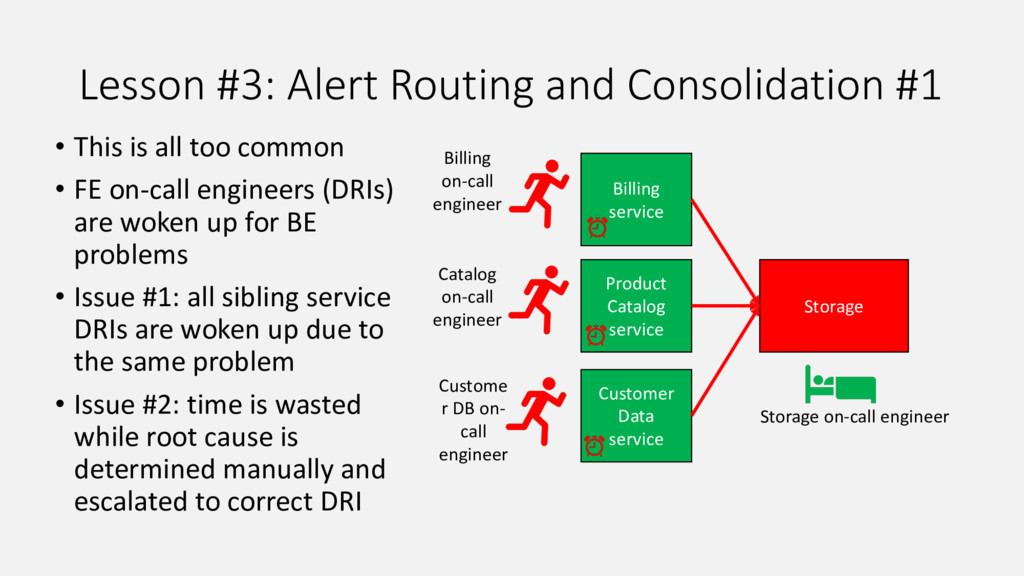{kind=link}
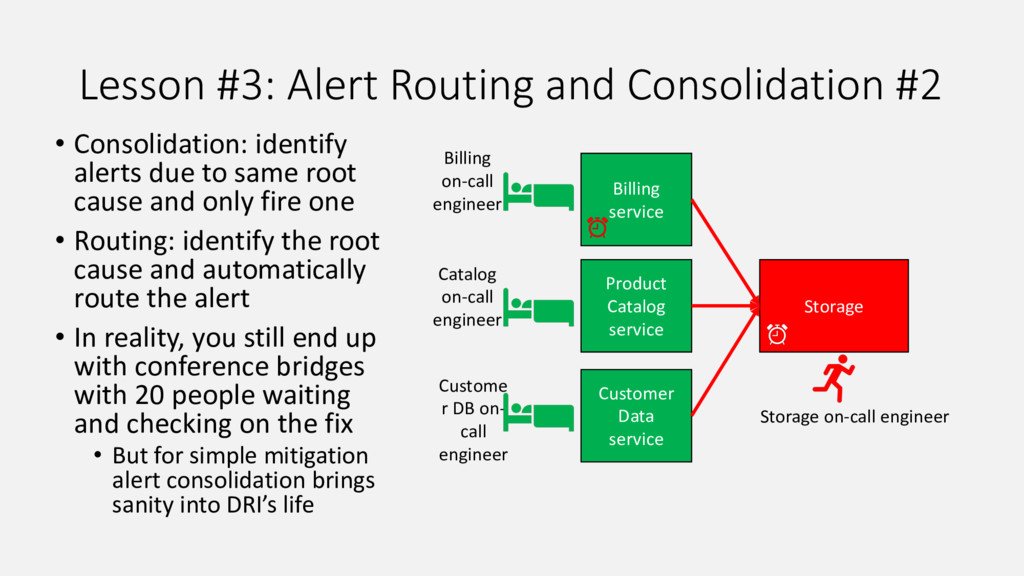{kind=link}
{kind=link}
{kind=link}
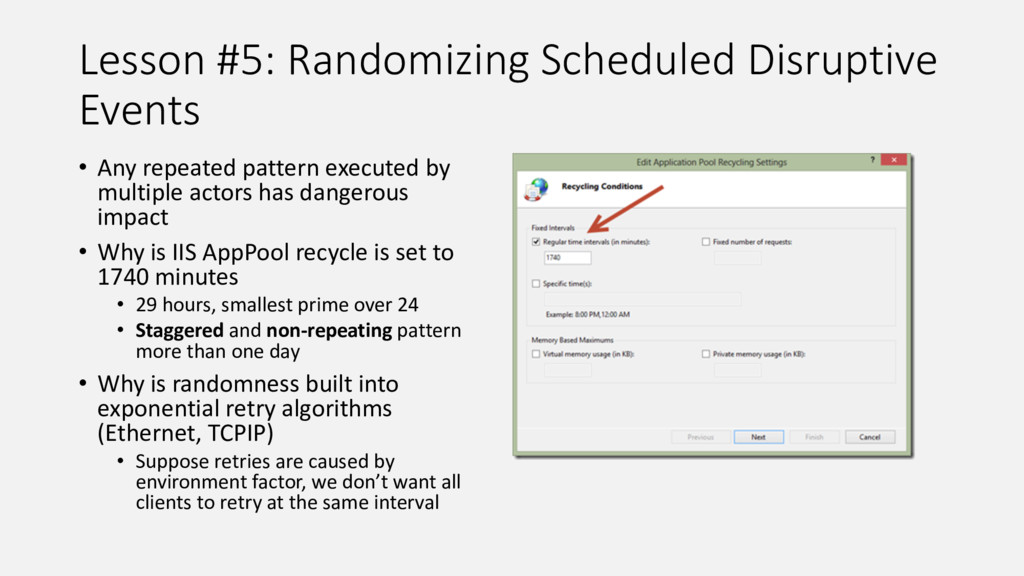{kind=link}
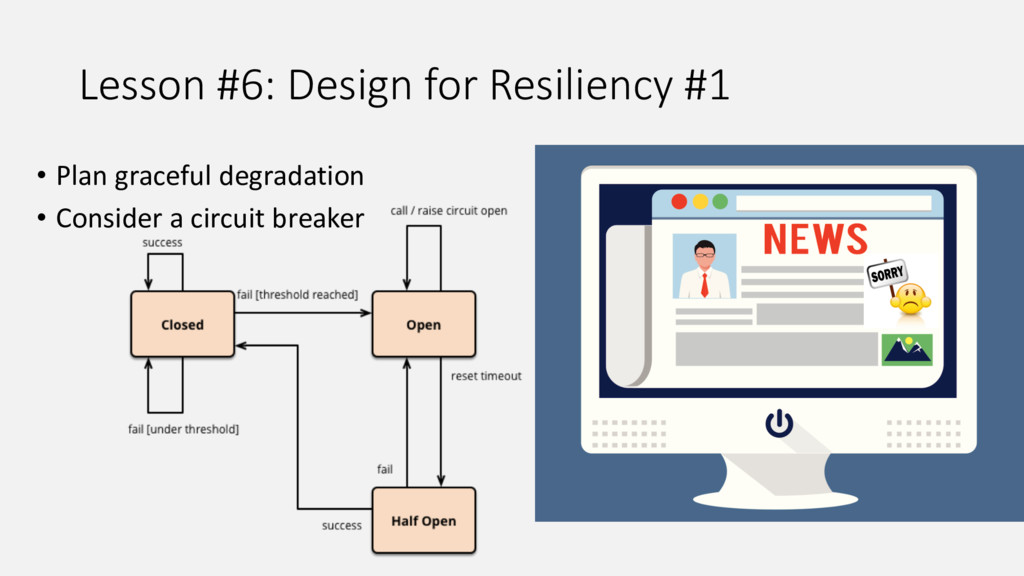{kind=link}
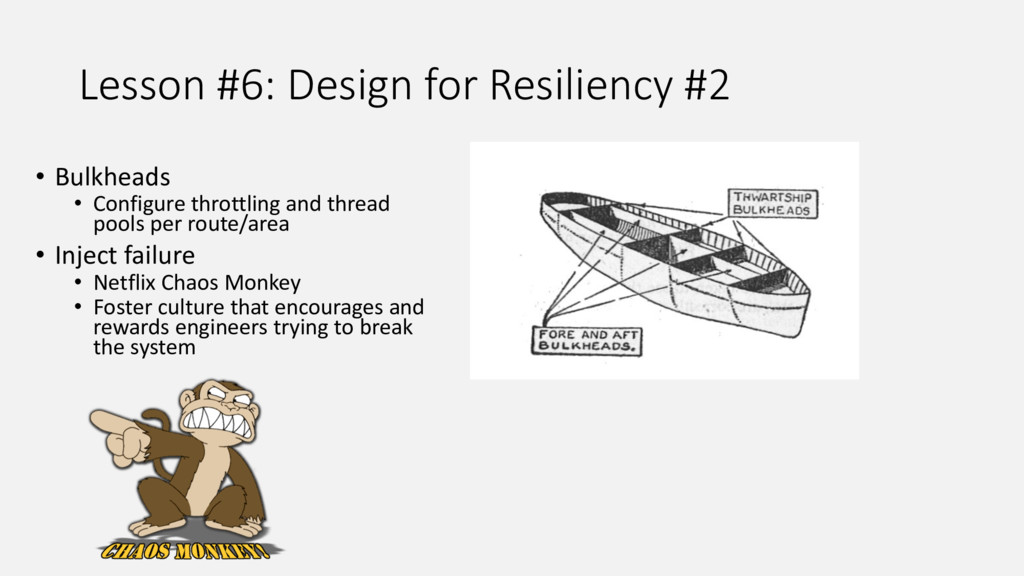{kind=link}
{kind=link}
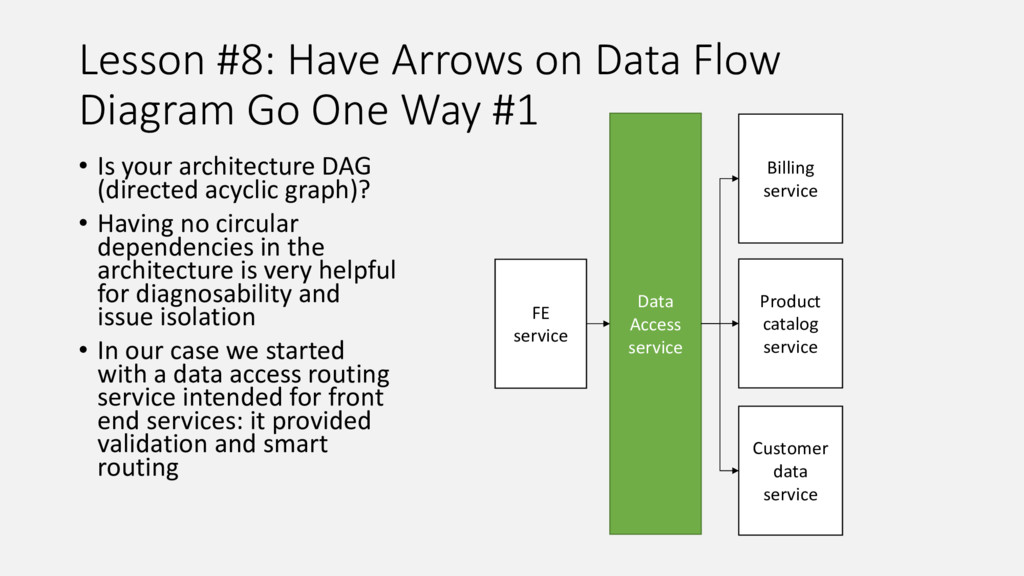{kind=link}
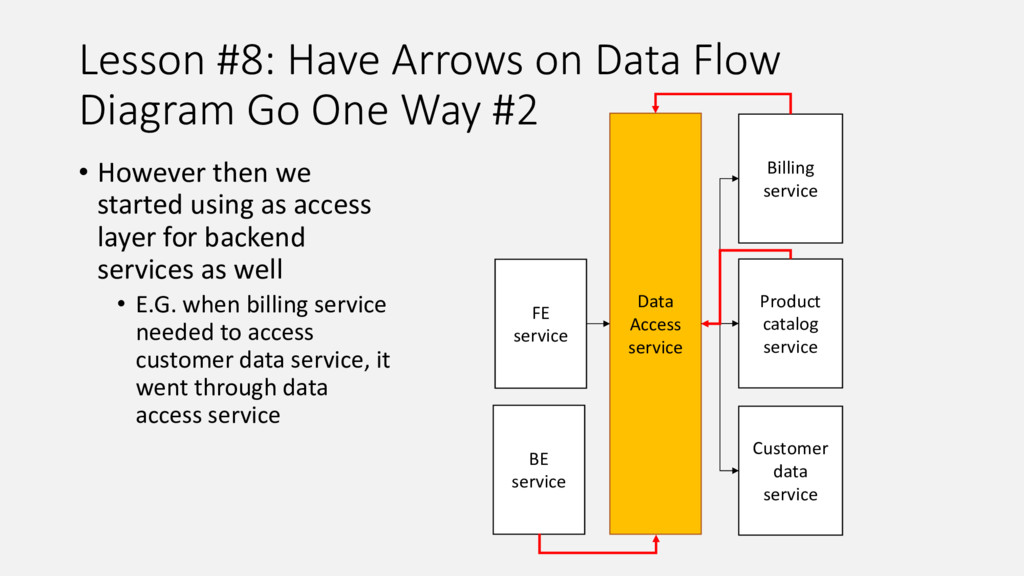{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}