Description (DE):
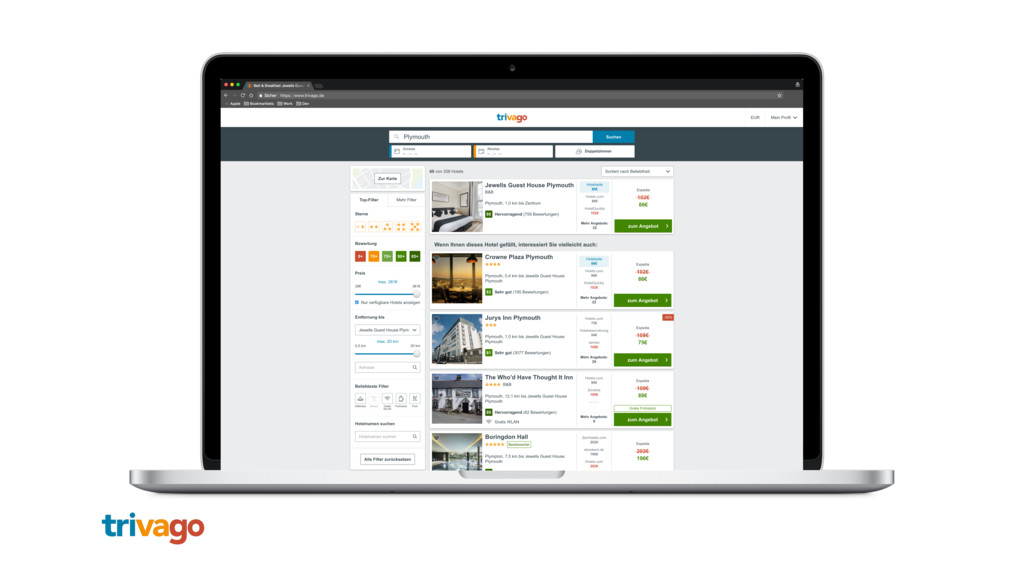
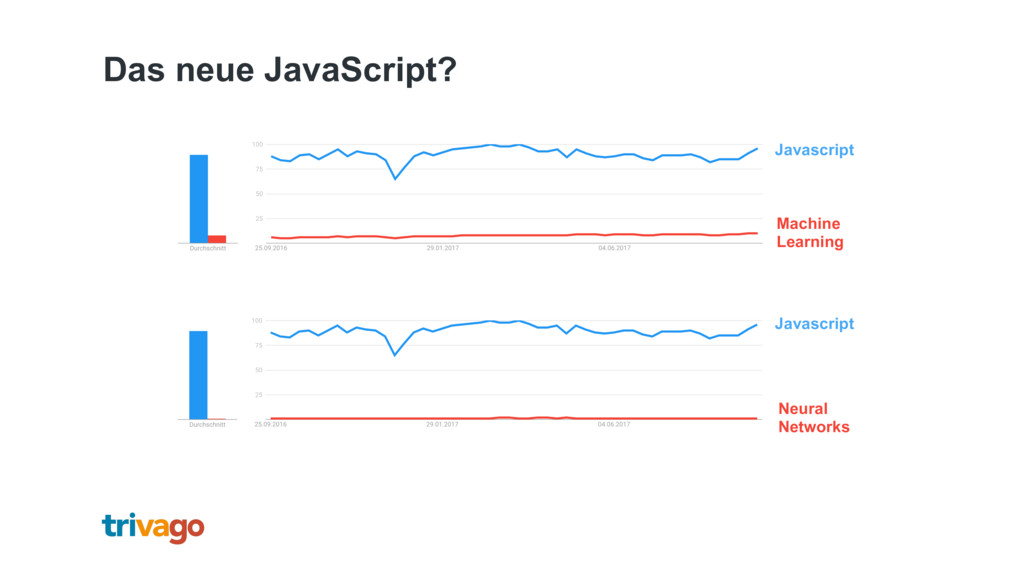
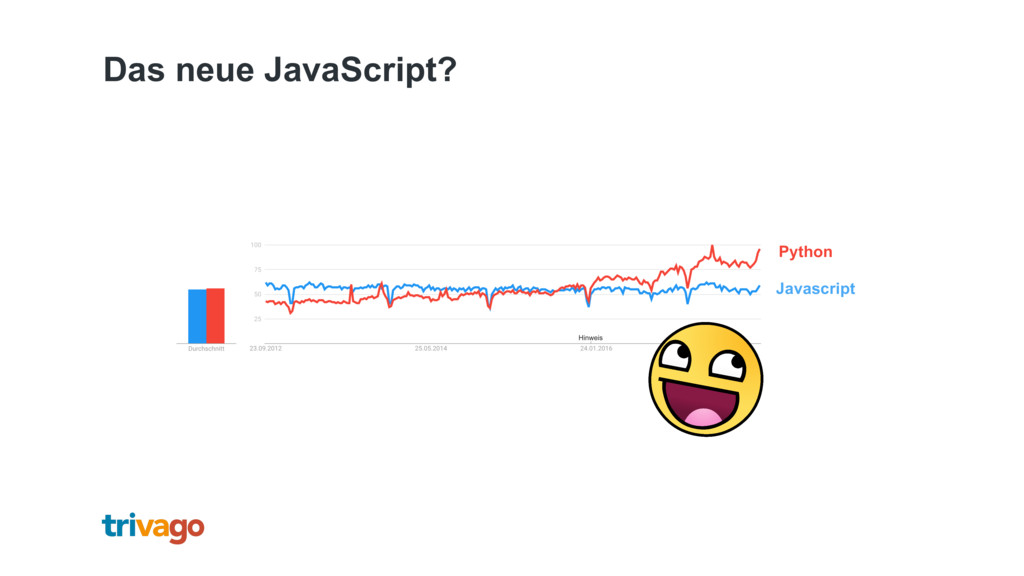
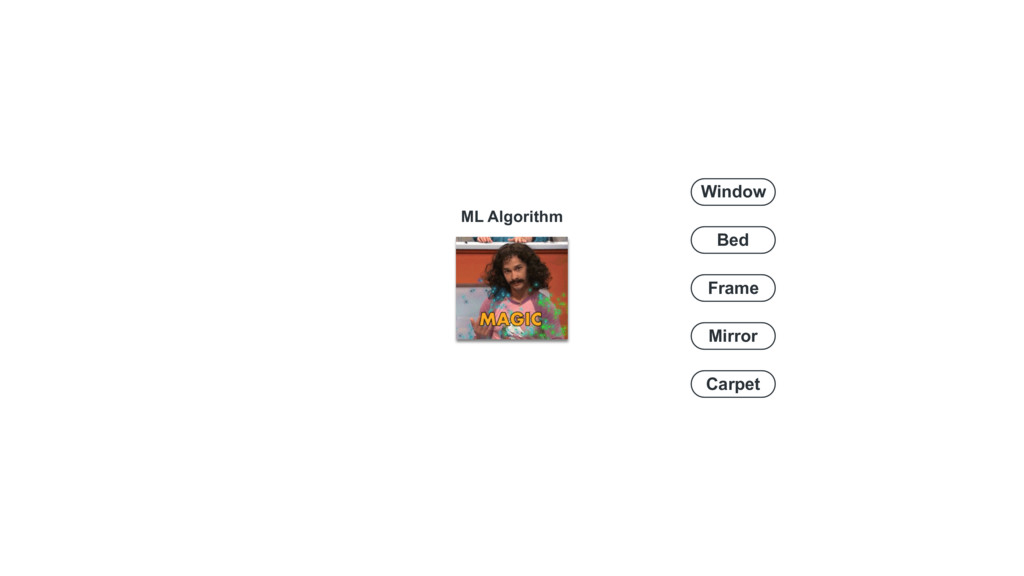
Machine Learning und neurale Netze sind das neue Javascript! Wer heutzutage seine App oder Website nicht dieser besonderen Art von "Magie" anreichert, hat hoffnungslos den Anschluss verpasst. Doch was wäre, wenn hinter der "Magie" nicht viel mehr stecken würde, als ein einfaches Prinzip, mit dem (fast?) jeder von uns bereits vertraut ist? Für alle, die sich bisher noch nicht an dieses Thema getraut haben, gibt es hier einen Blick "hinter die Kulissen" von ML und neuralen Netzen (mit so wenig Mathematik wie nötig - versprochen!)
https://twitter.com/b00giZm
https://www.linkedin.com/in/pcremer
http://company.trivago.com/jobs
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
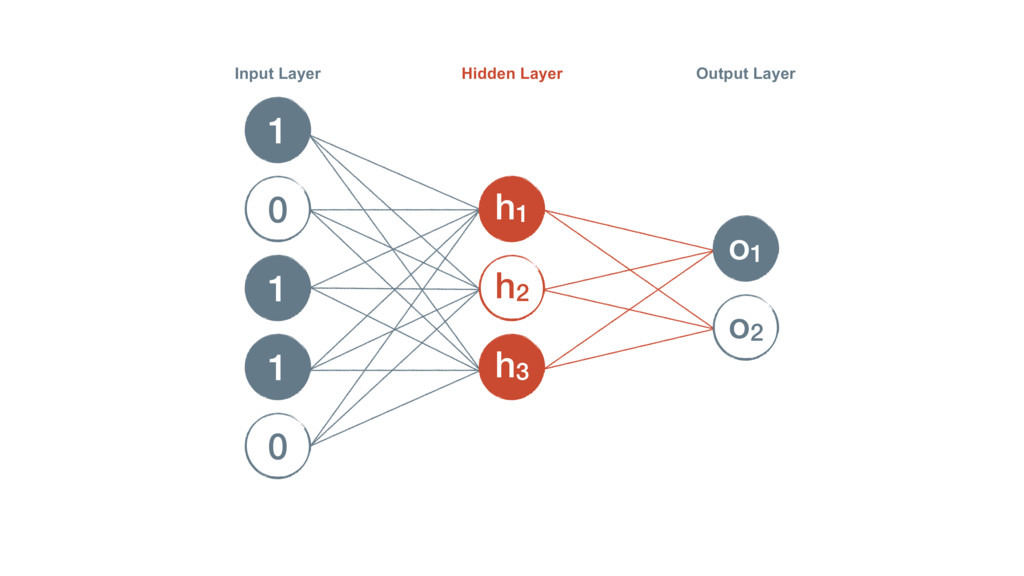{kind=link}
{kind=link}
{kind=link}
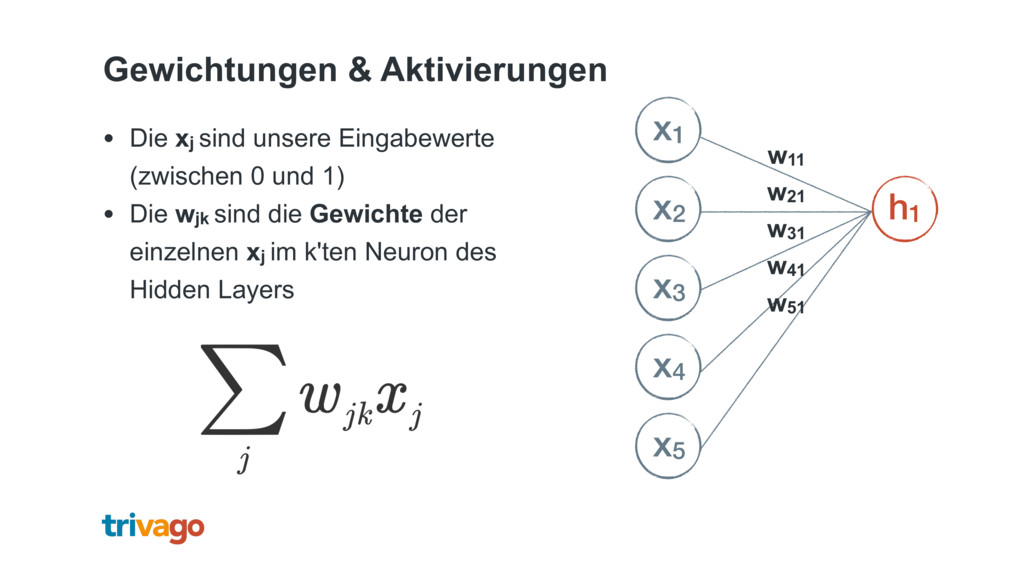{kind=link}
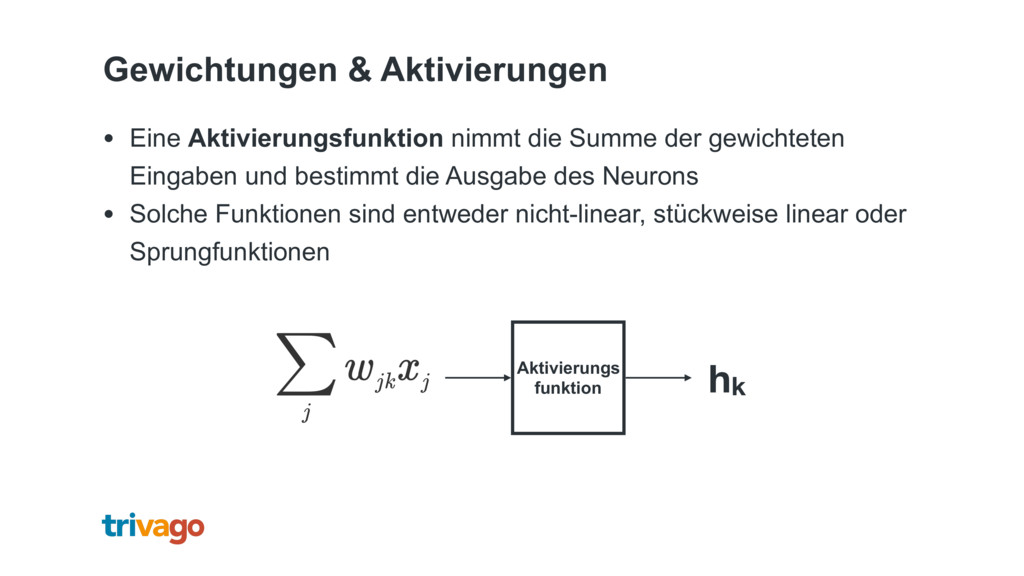{kind=link}
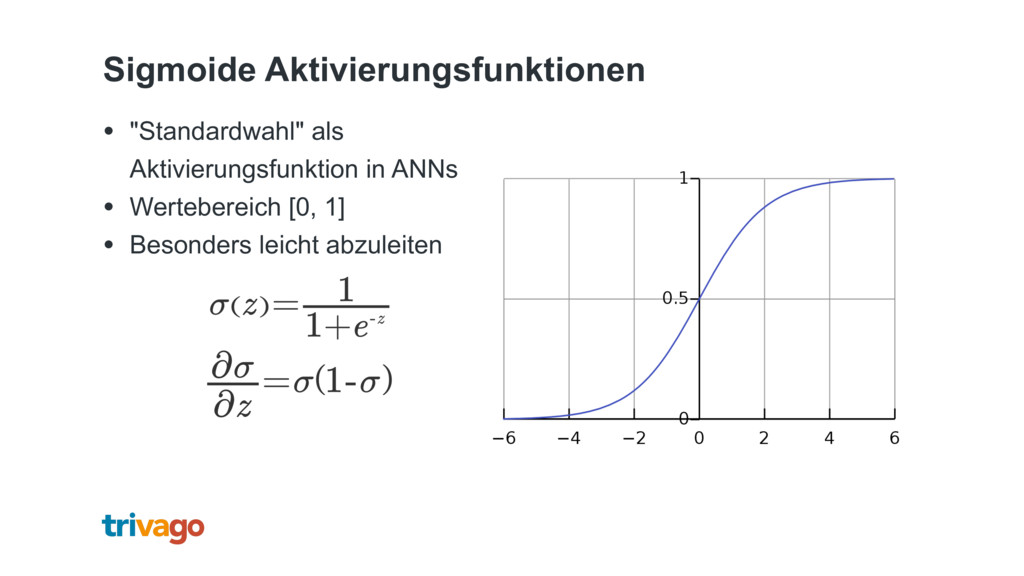{kind=link}
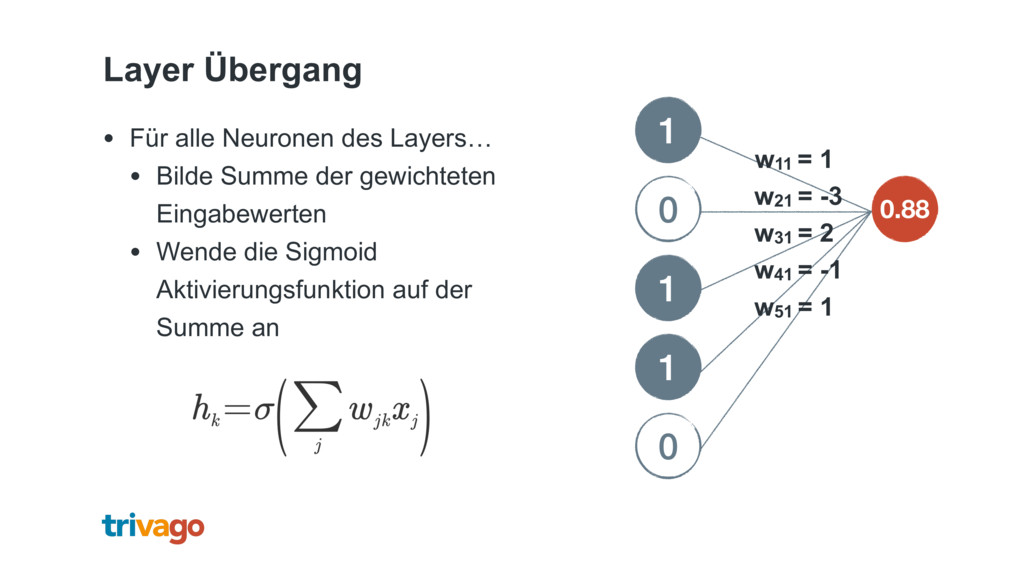{kind=link}
{kind=link}
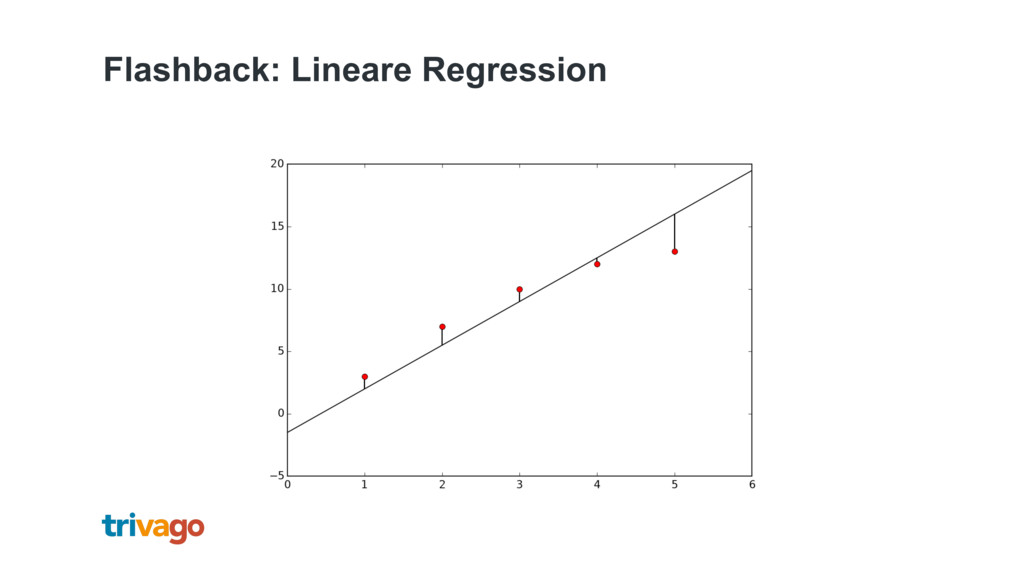{kind=link}
{kind=link}
{kind=link}
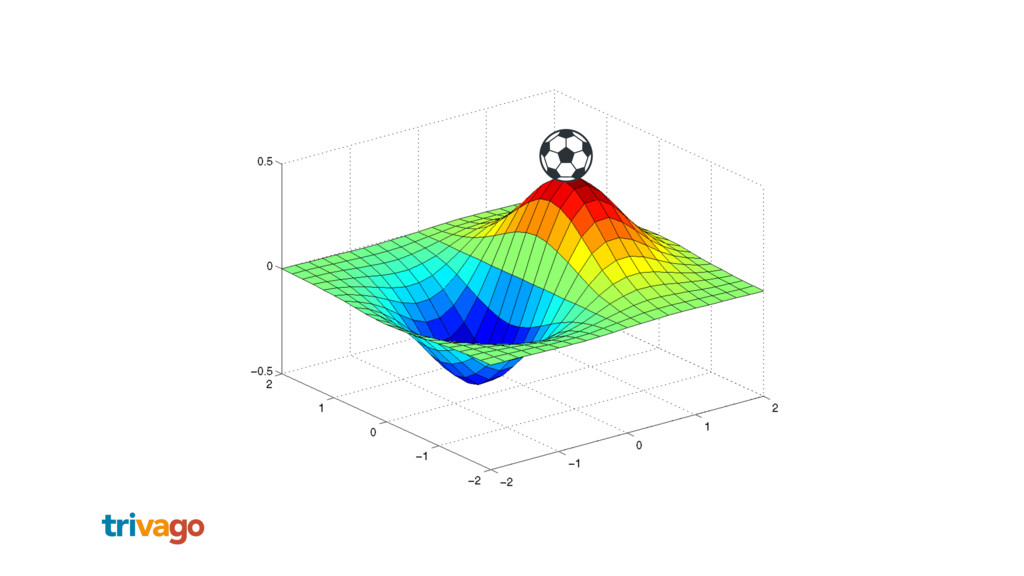{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
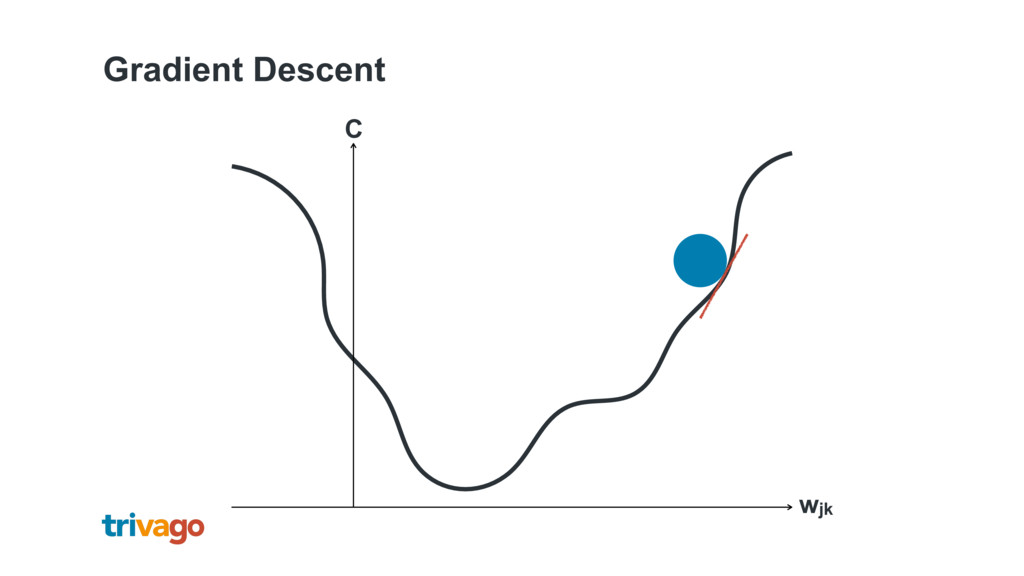{kind=link}
{kind=link}
{kind=link}
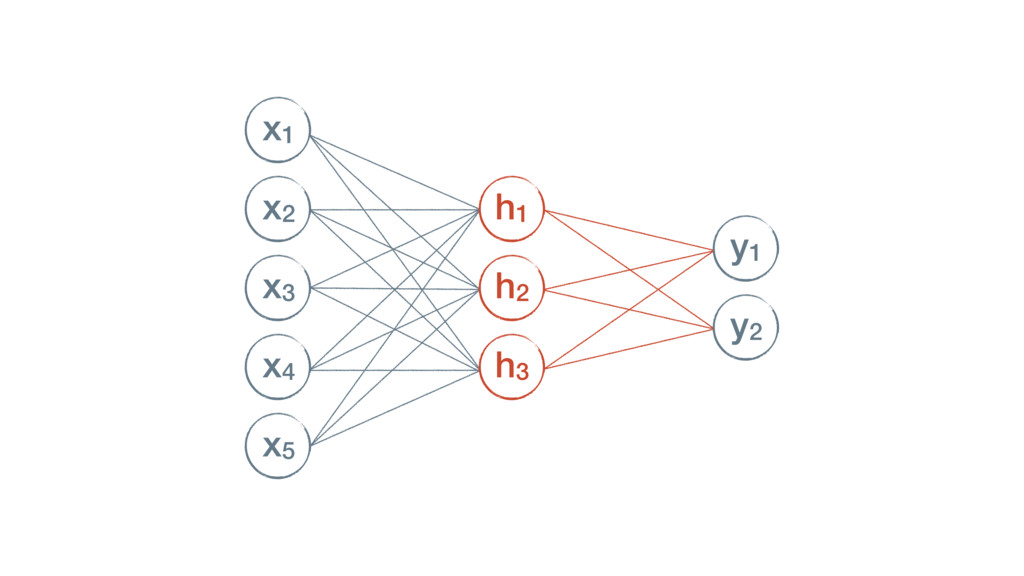{kind=link}
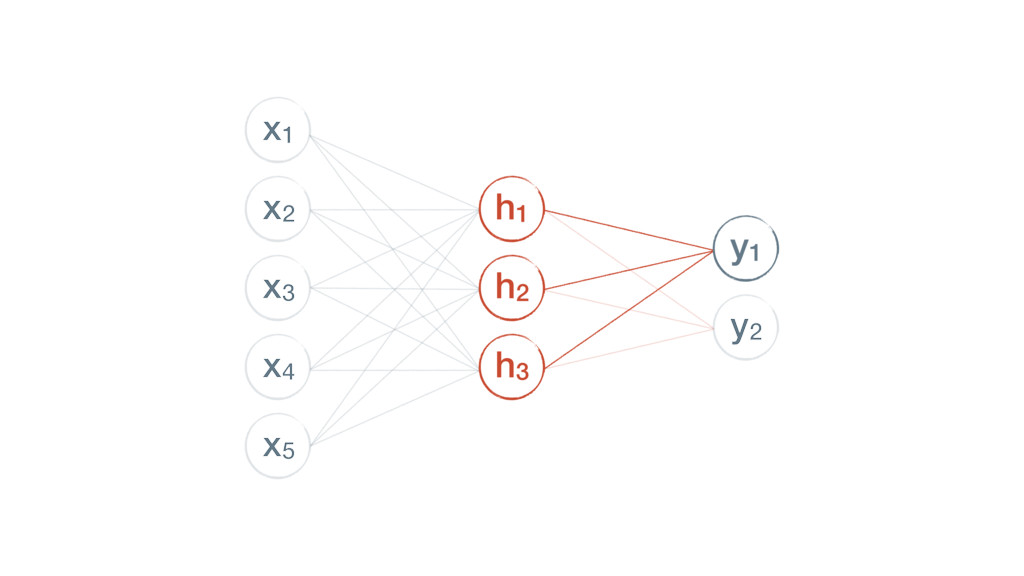{kind=link}
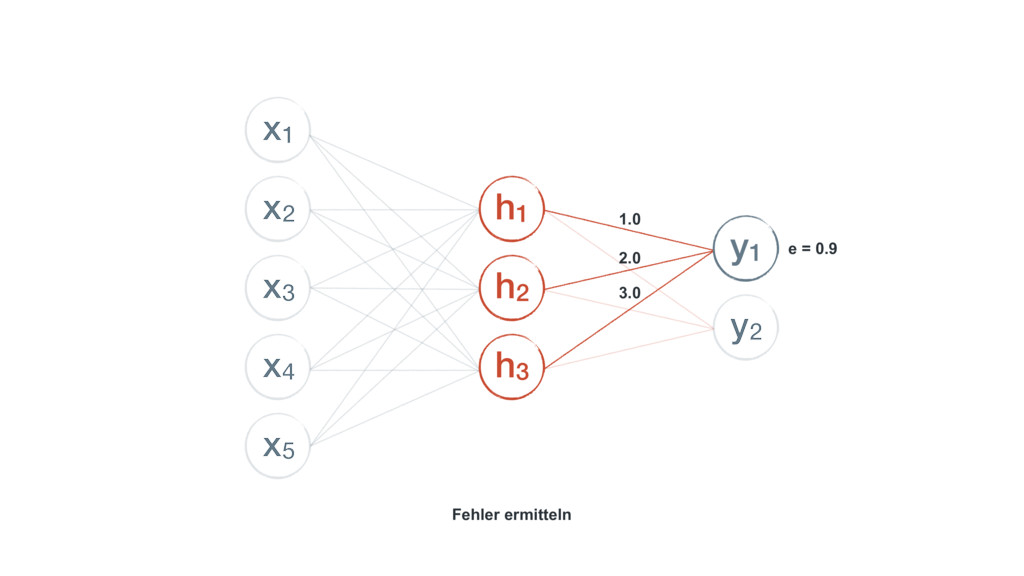{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}