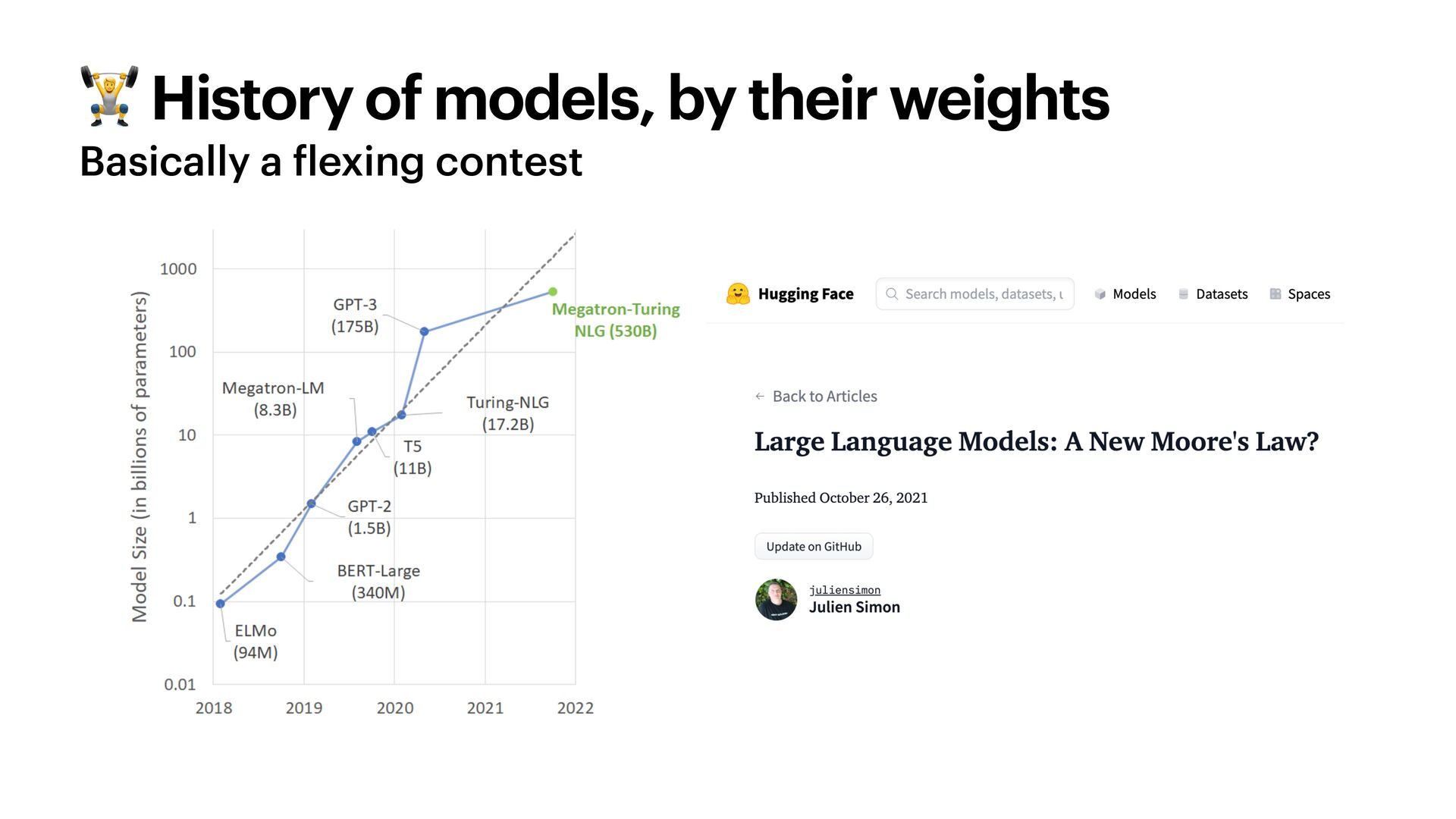
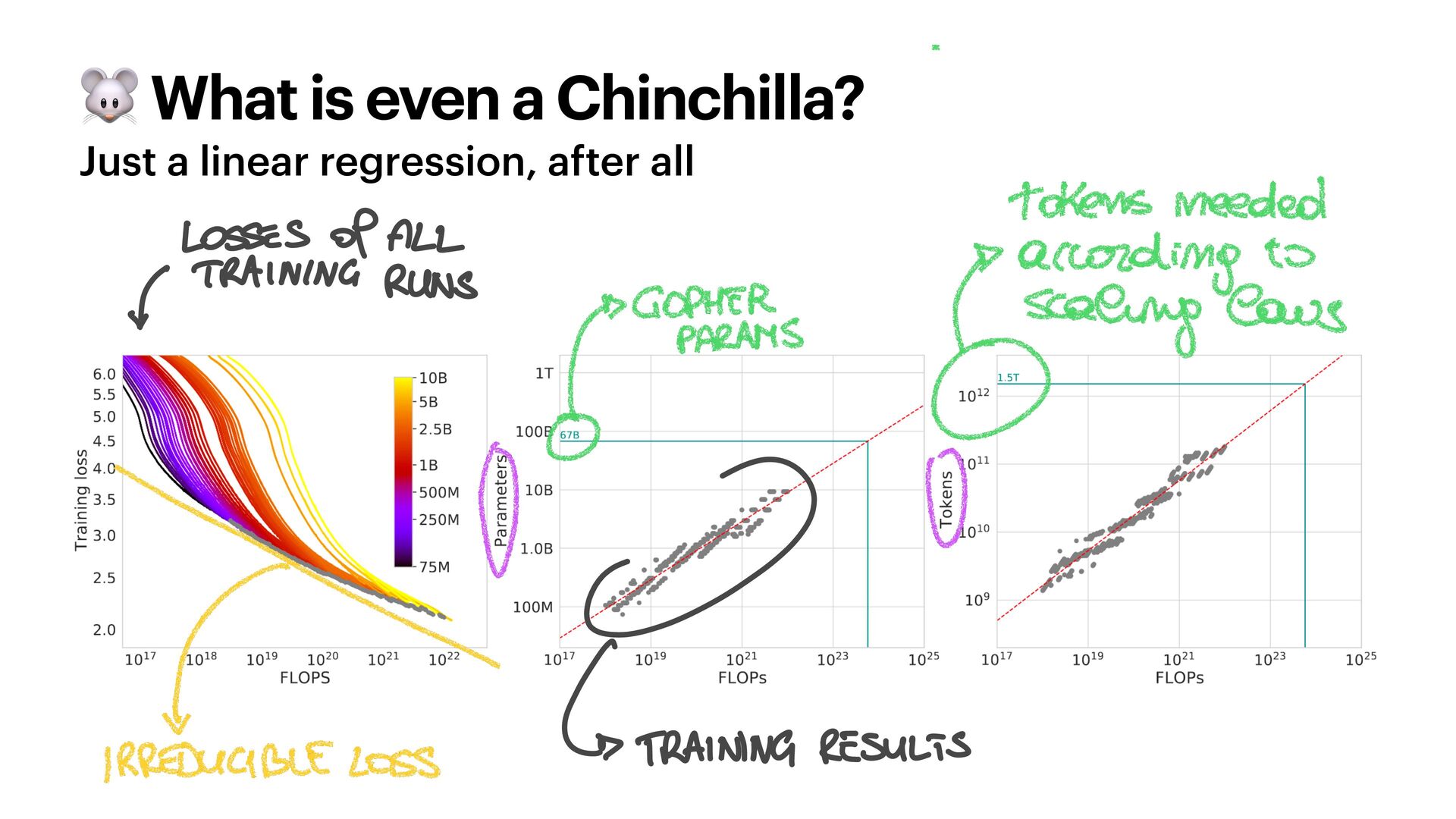
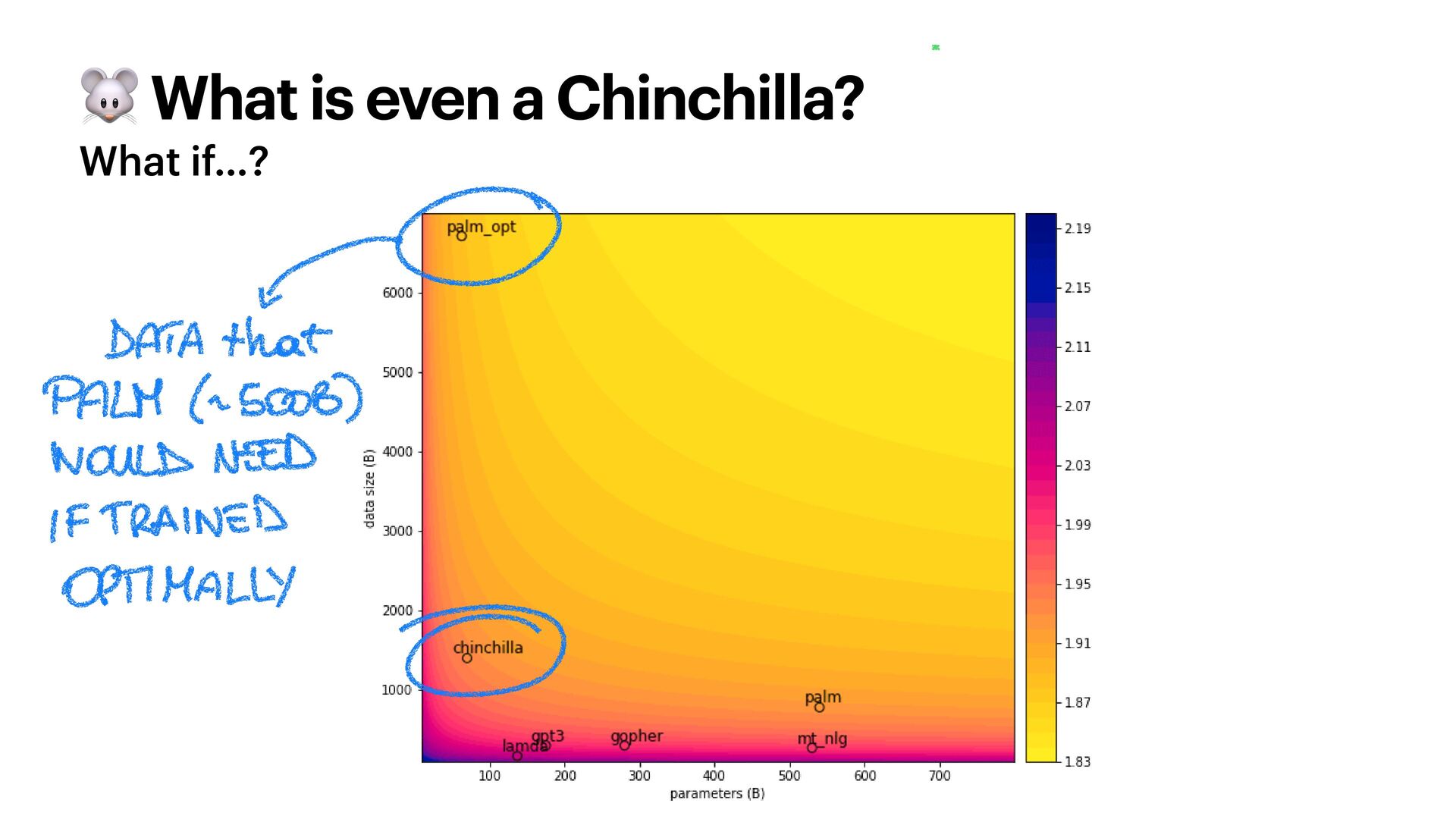
The famous Chinchilla paper changed the way we train LLMs. The authors - including the current Mistral CEO - outlined the scaling laws to maximise your model performance under a compute budget, balancing the number of parameters and training tokens.
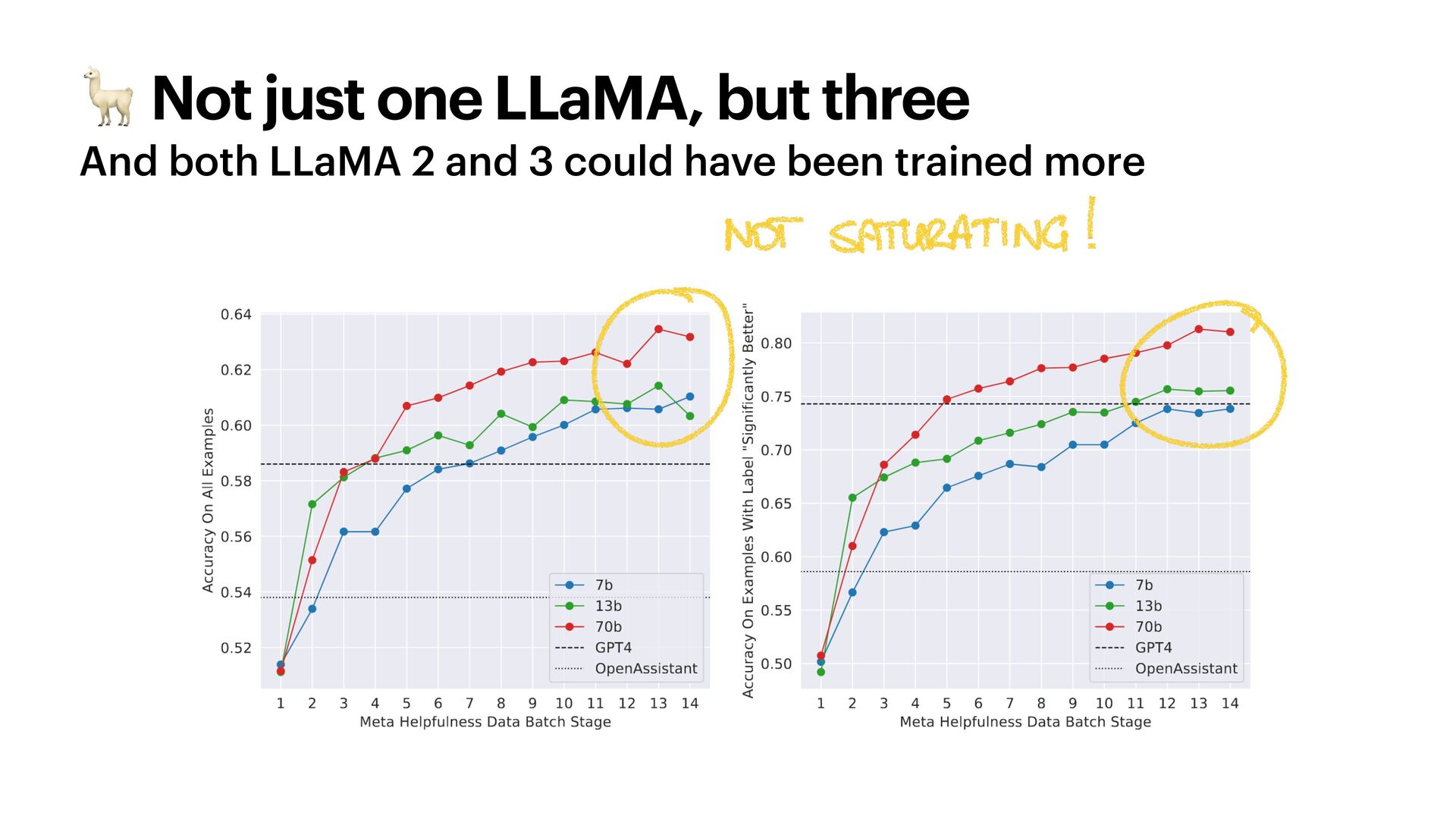
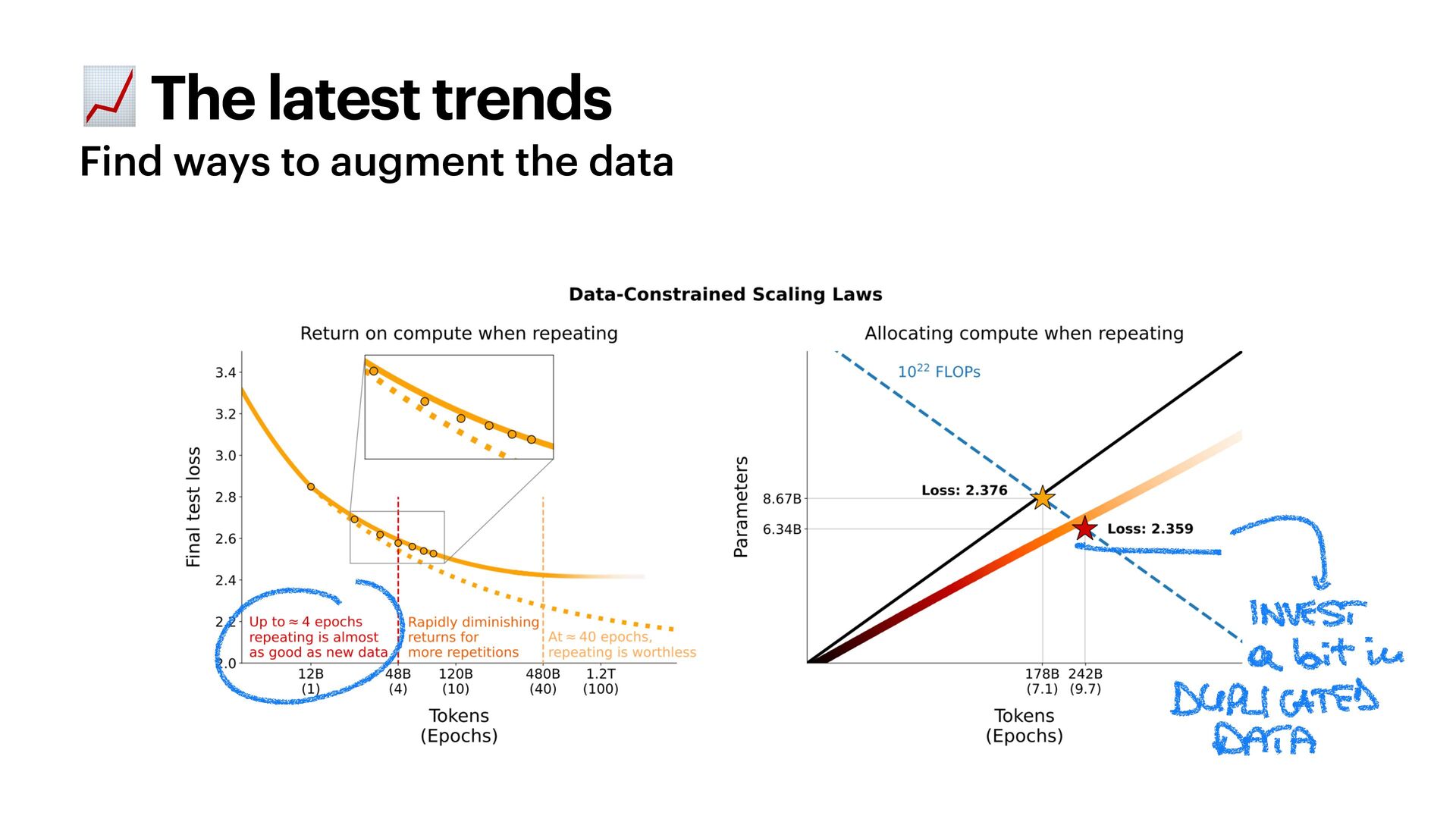
These heuristics are now in jeopardy. LLaMA-3, for one, is trained on an unreasonable amount of tokens of text - but this is why it's so good. How much data do we actually need to train LLMs? How do we use synthetic data? Will we ever run out of data?
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}