Have you ever asked yourself how parameters for an LLM are counted, or wondered why Gemma 2B is actually closer to a 3B model? You have no clue about what a KV-Cache is? (And, before you ask: no, it's not a Redis fork.) Do you want to find out how much GPU VRAM you need to run your model smoothly?
If your answer to any of these questions was "yes", or you have another doubt about inference with LLMs - such as batching, or time-to-first-token - this talk is for you. Well, except for the Redis part.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
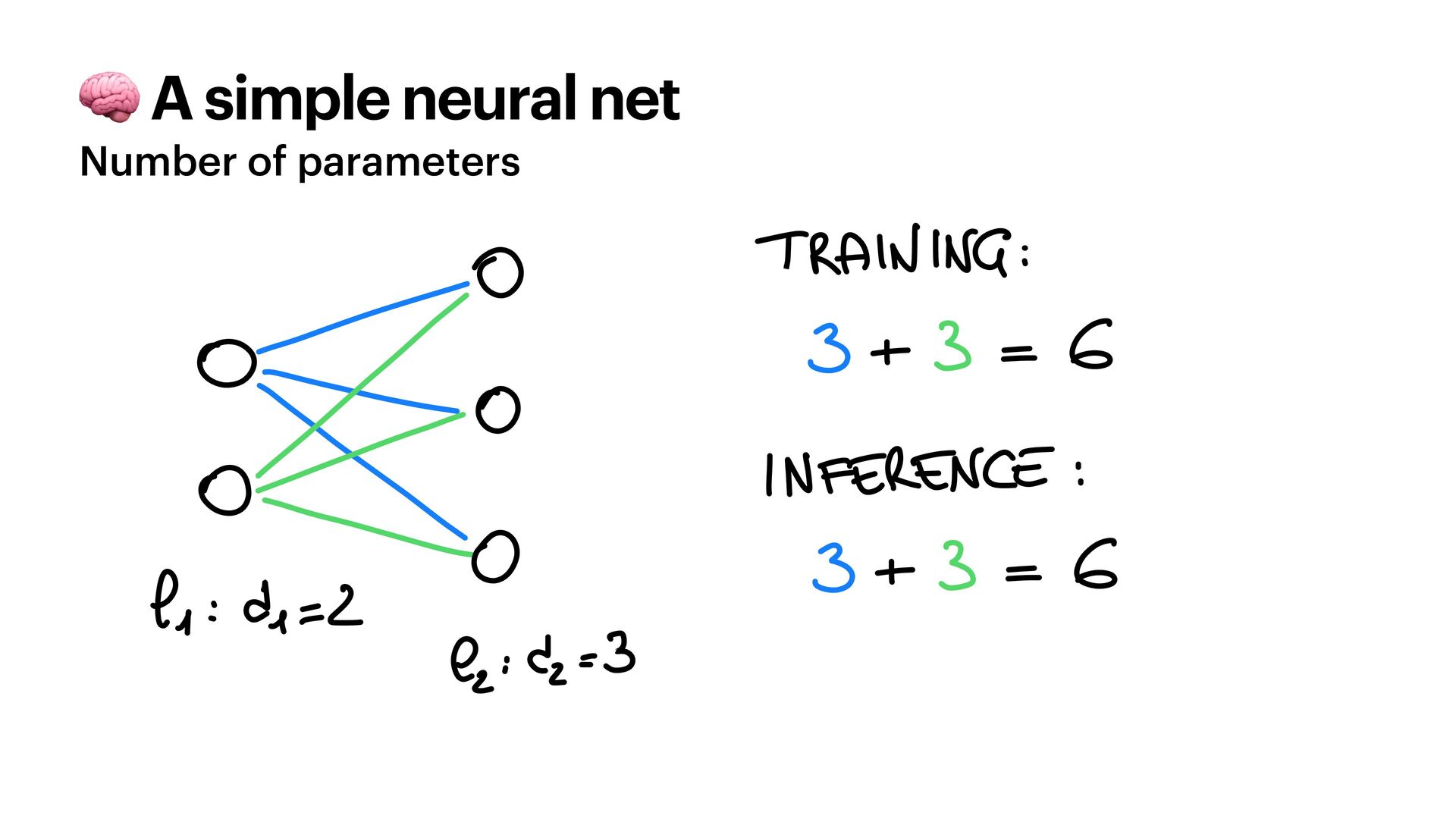{kind=link}
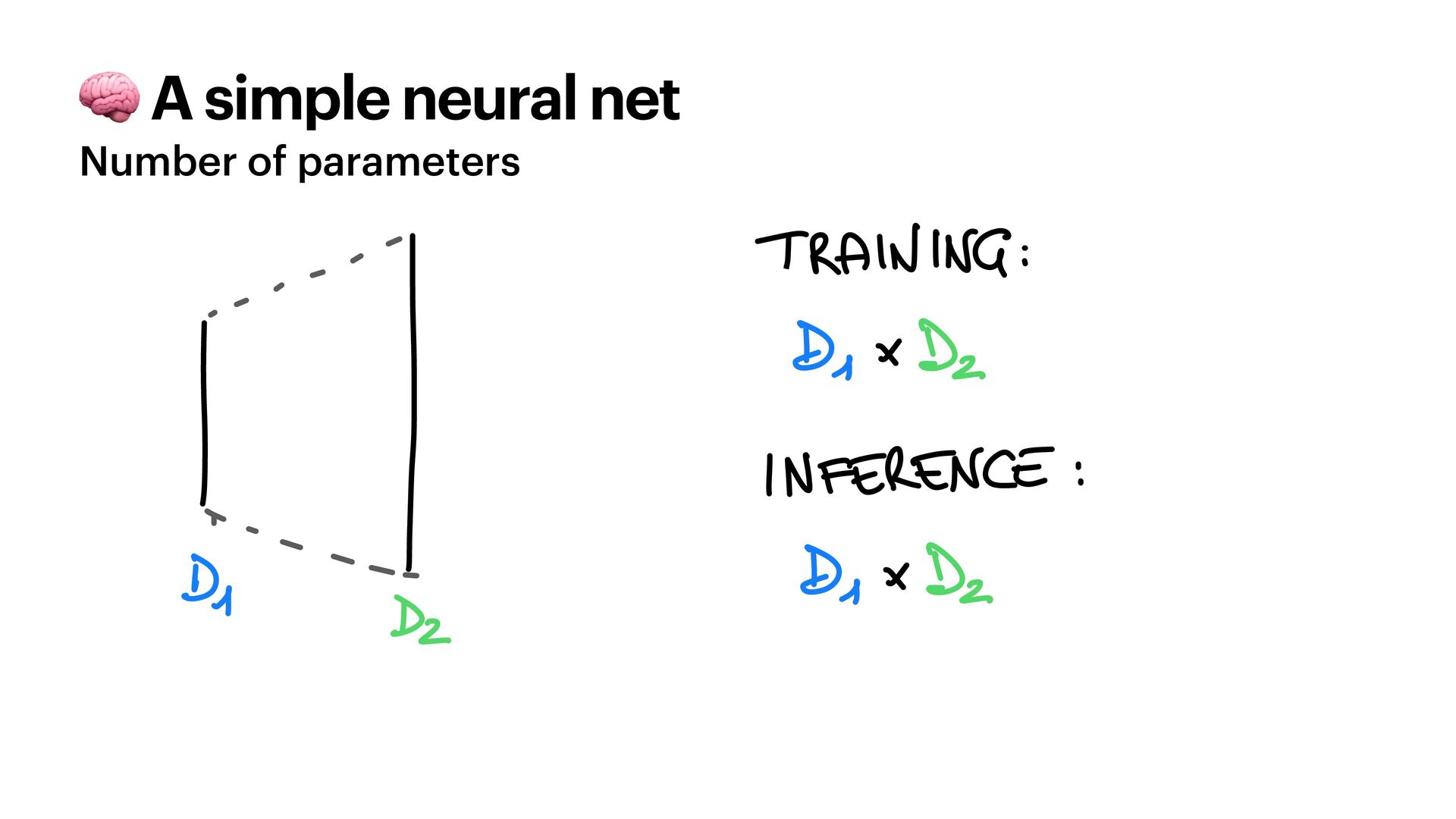{kind=link}
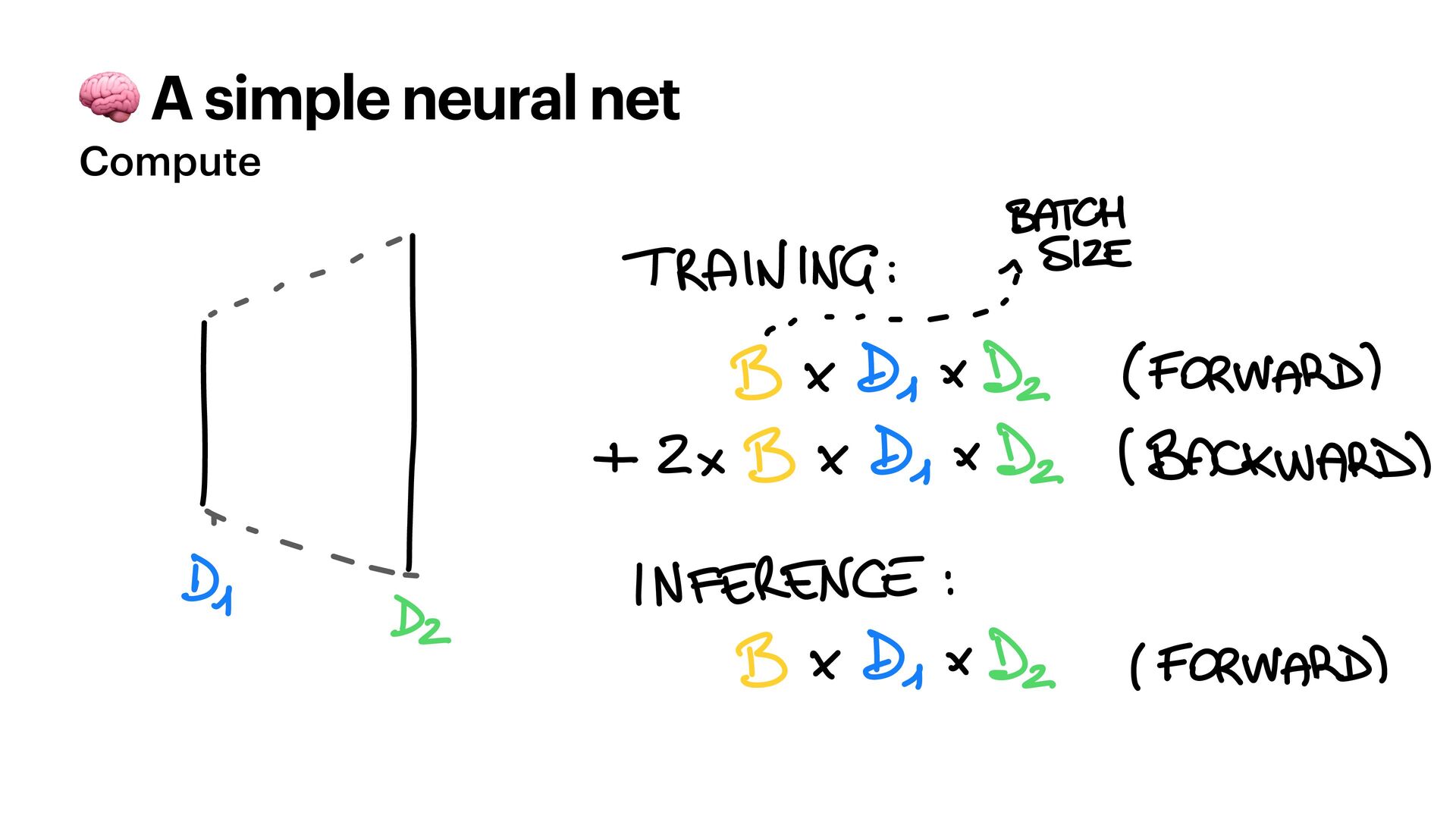{kind=link}
{kind=link}
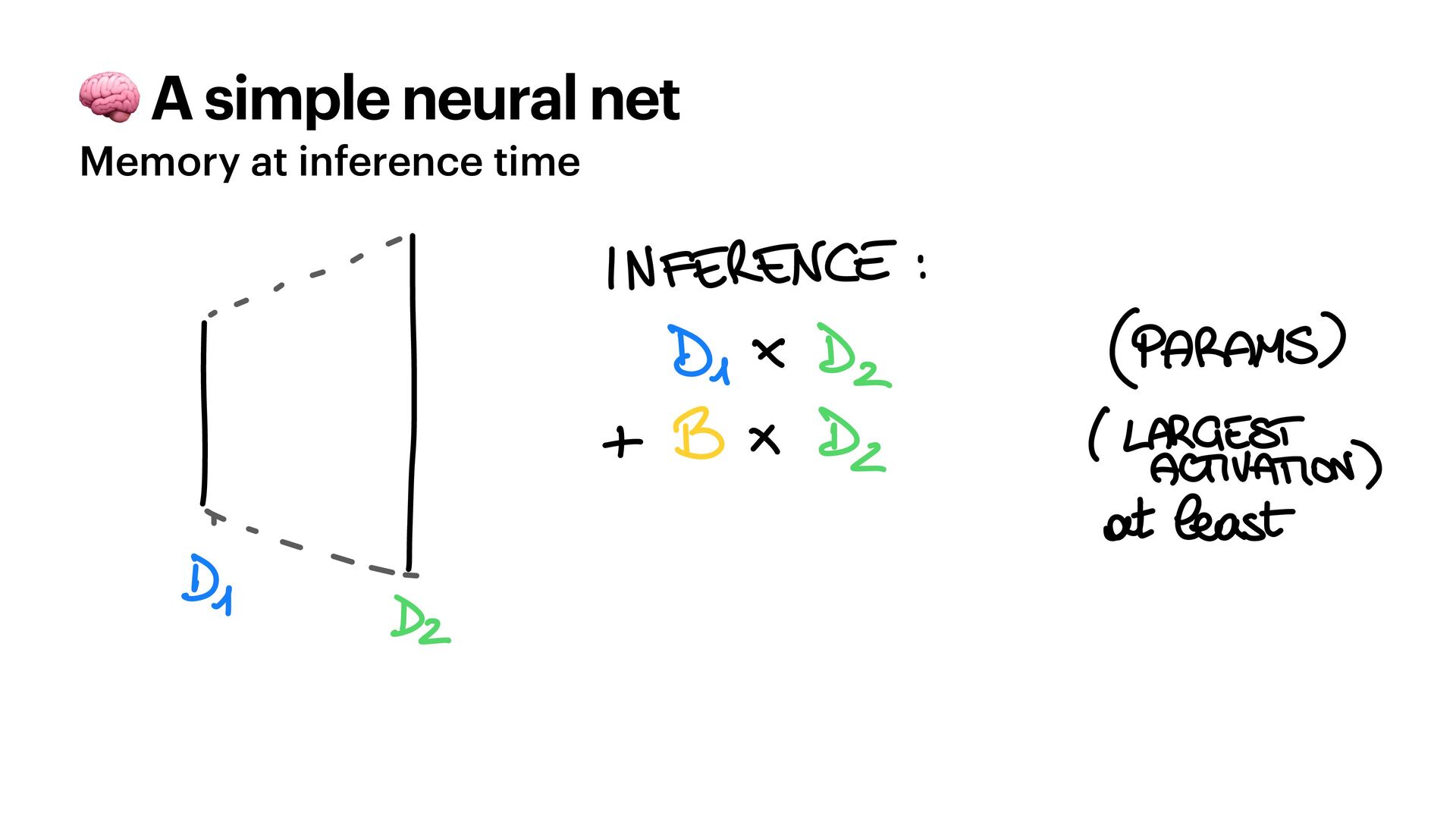{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
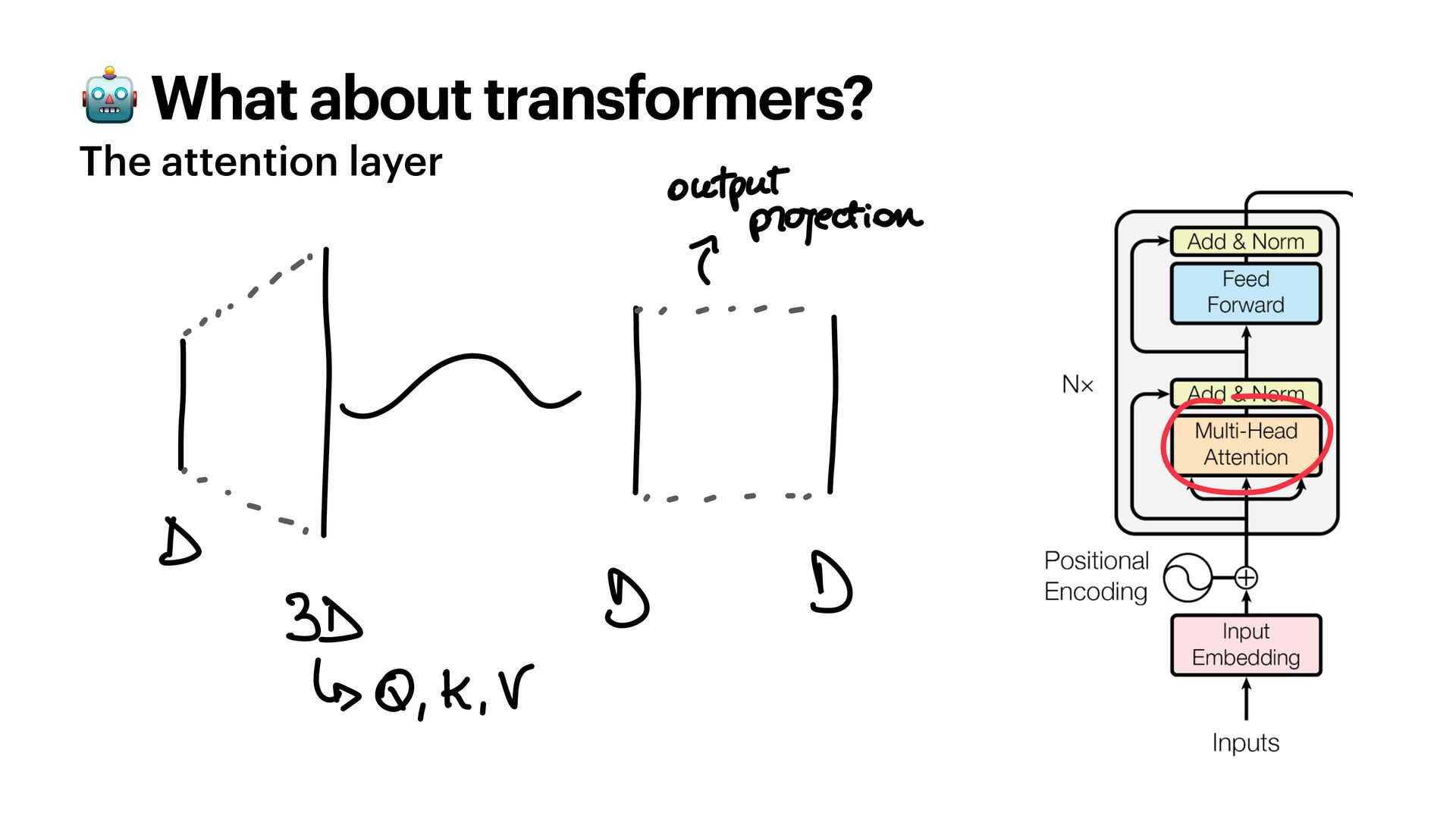{kind=link}
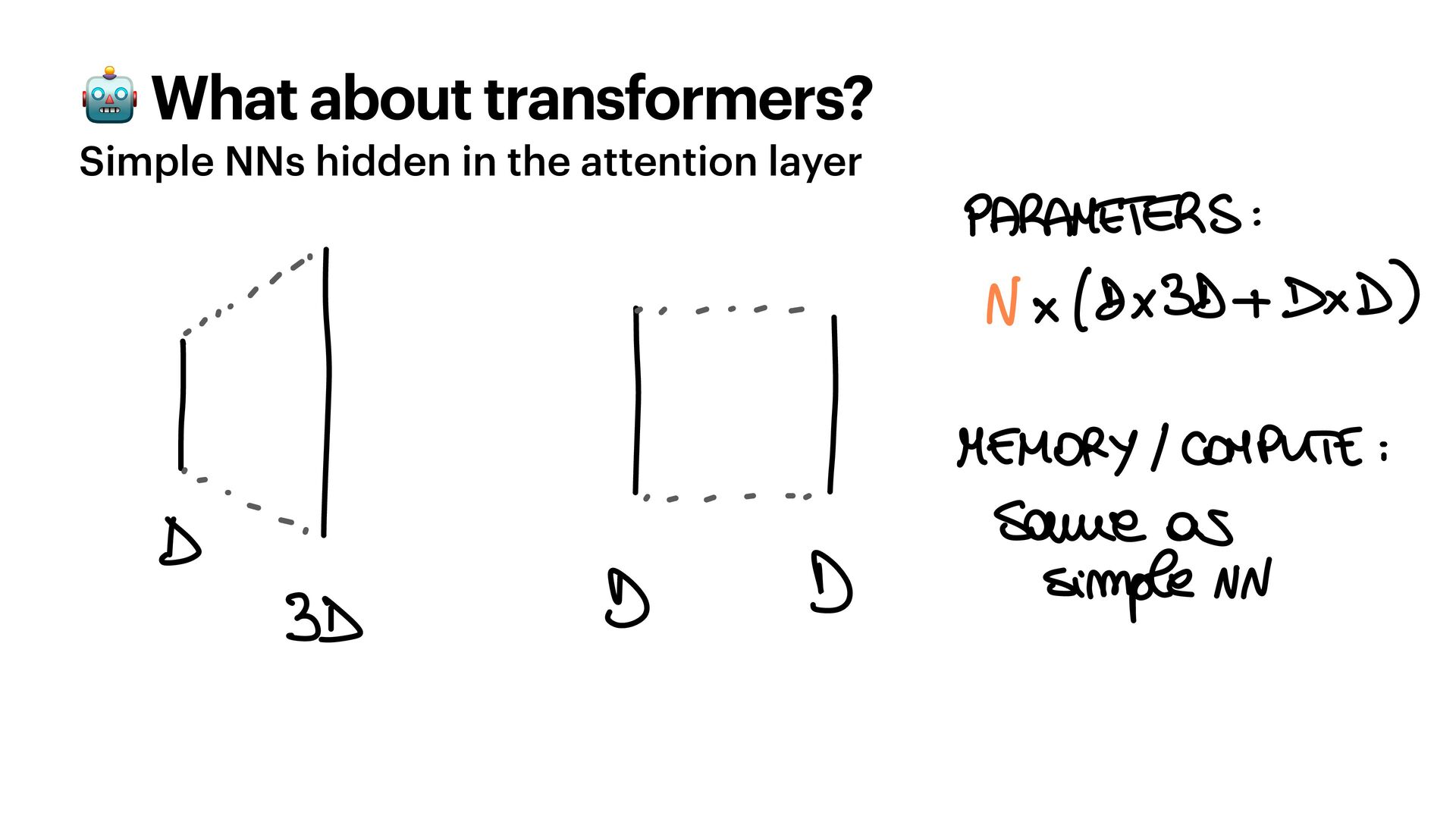{kind=link}
{kind=link}
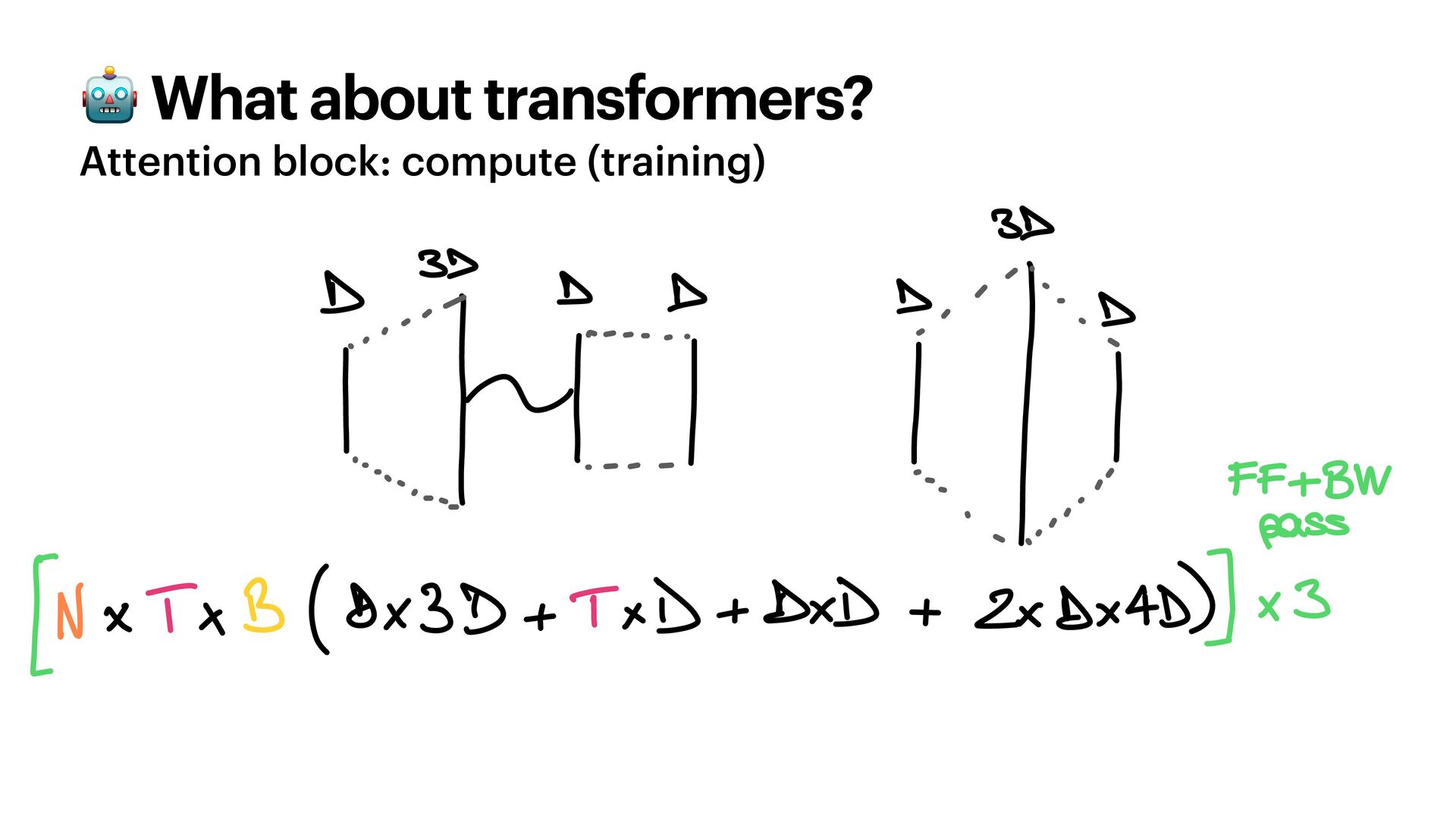{kind=link}
{kind=link}
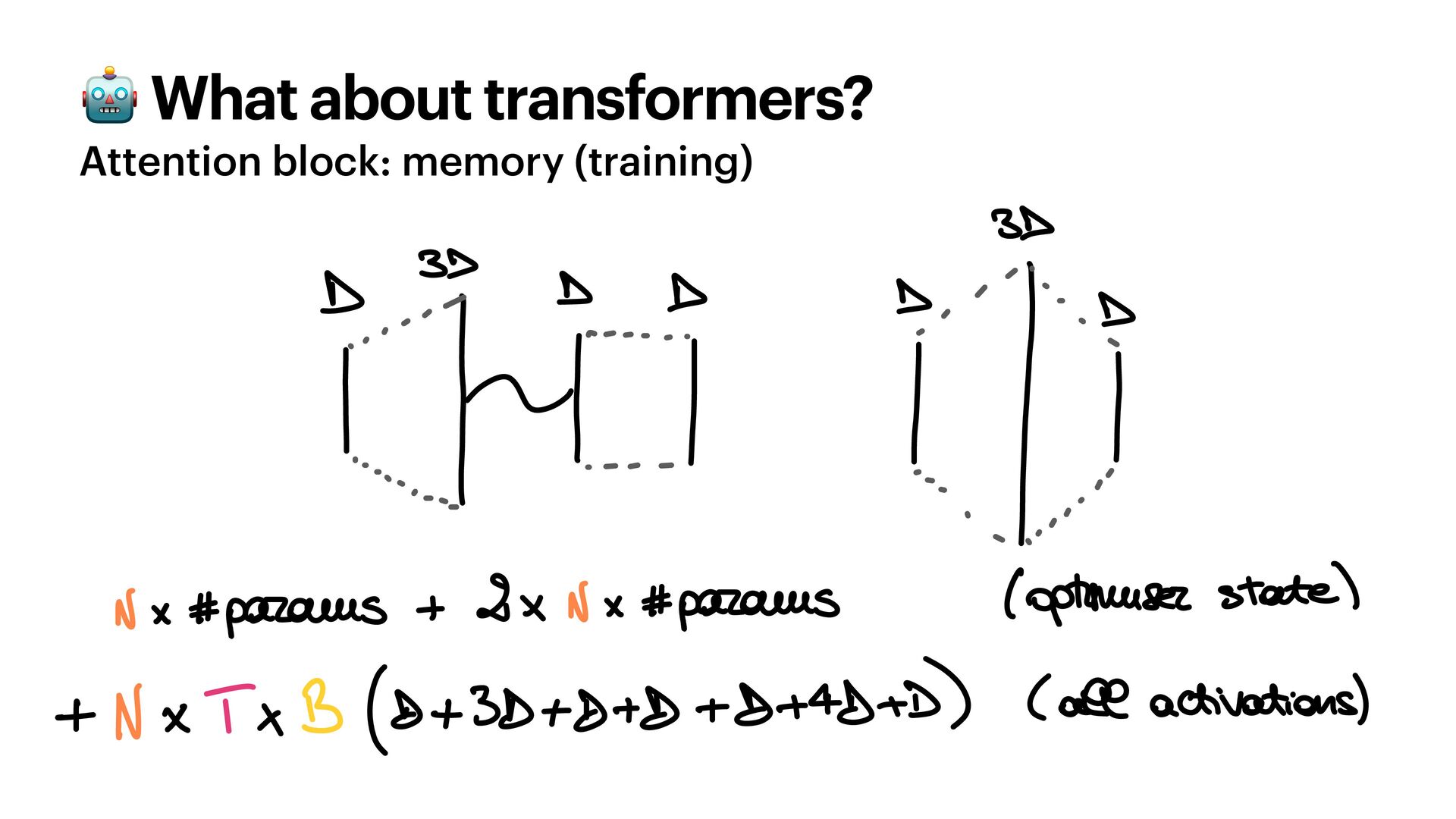{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}