it’s known that Amazon, Google, Alibaba, Zalando's use transformers in forecasting (in Zalando’s case since 2019). So what’s up? To me, the current most plausible explanation is that the success of transformers in forecasting is a function of the data. With data like Amazon's or Zalando’s demand data sets, transformers make a difference – and scaling laws even seem to kick in.
1. Create an arbitrarily large neural network with a transformer-based architecture 2. Grab all the data that you can: even more than what it would take to train a successful transformer-based model. Any domain, any frequency, any length 3. Train the model 4. Hope the model learns general patterns thanks to the diversity of domains, frequencies, seasonalities, skewness, sparsity...
the training set is broad enough, it should have reasonable performance on unseen data regardless of their granularity, frequencies, sparsity and perhaps even distribution. 2.You don't need to wait until you have enough data to train a model from scratch (e.g. ARIMA but might also apply to a global model such as XGBoost). 3. When the data starts to come in, you can fine-tune the zero-shot model to your domain (or other purposes, e.g. conformal predictions).
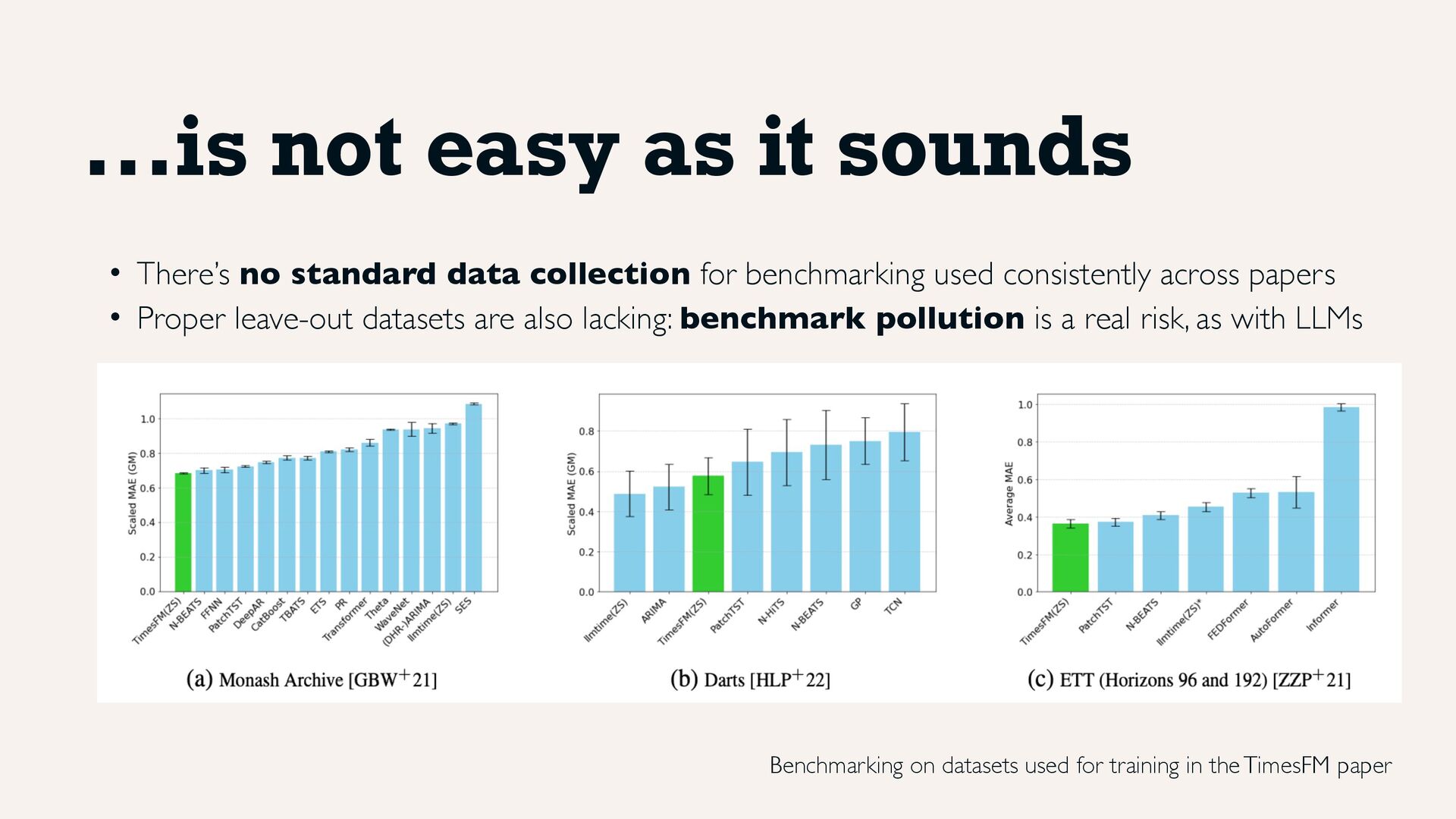
we're getting there. • 🔗 Monash Time Series Forecasting Repository: the OG, <1B observations • 🔗 LoTSA: introduced with Moirai, >27B • 🔗 Timeseries-PILE, introduced with Moment, ~1.23B (though contains Monash) Unfortunately, unlike NLP, there are no datasets specifically designed and/or set aside for evaluation (think of GSMK8...).
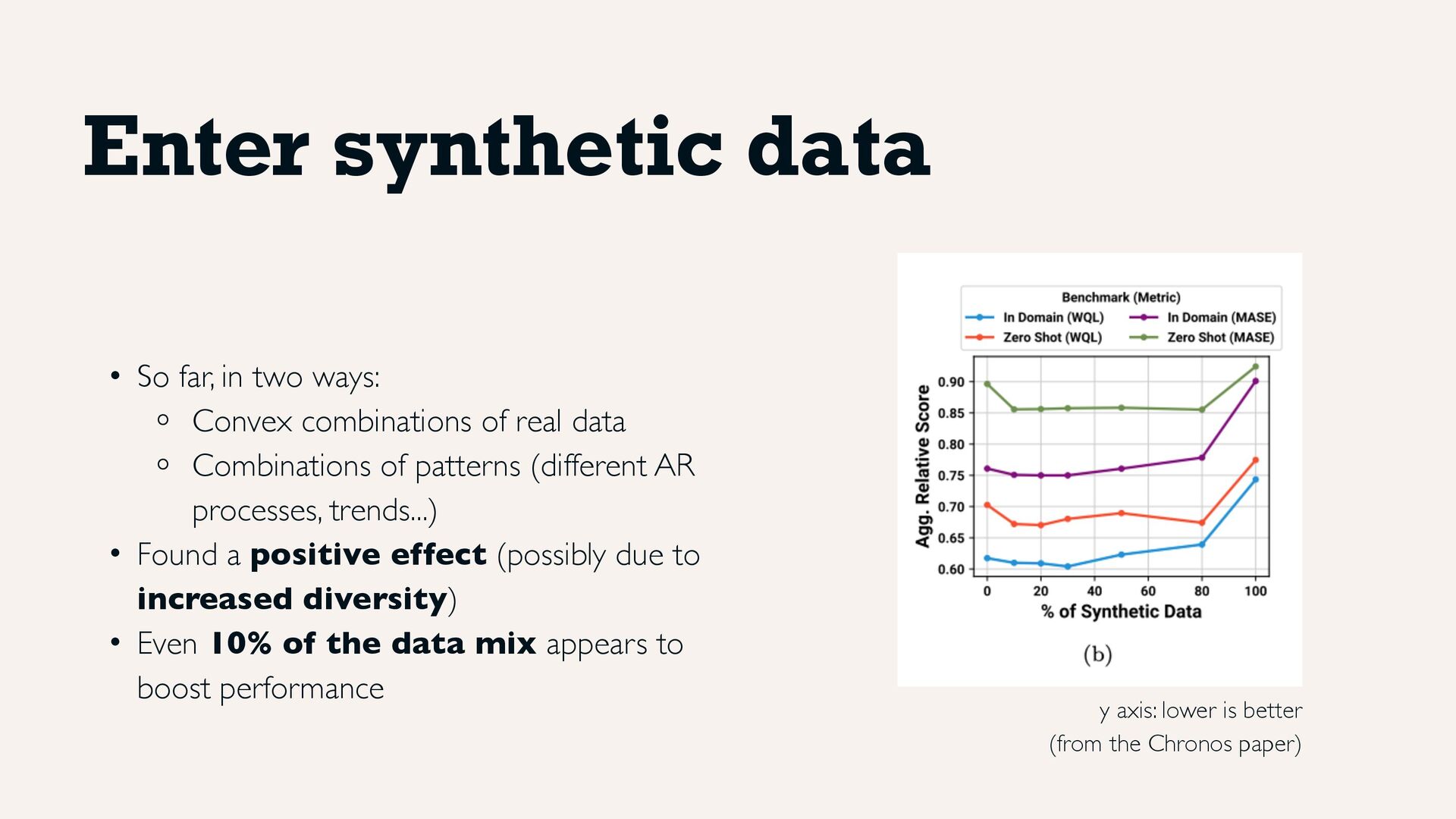
Convex combinations of real data ⚬ Combinations of patterns (different AR processes, trends...) • Found a positive effect (possibly due to increased diversity) • Even 10% of the data mix appears to boost performance y axis: lower is better (from the Chronos paper)
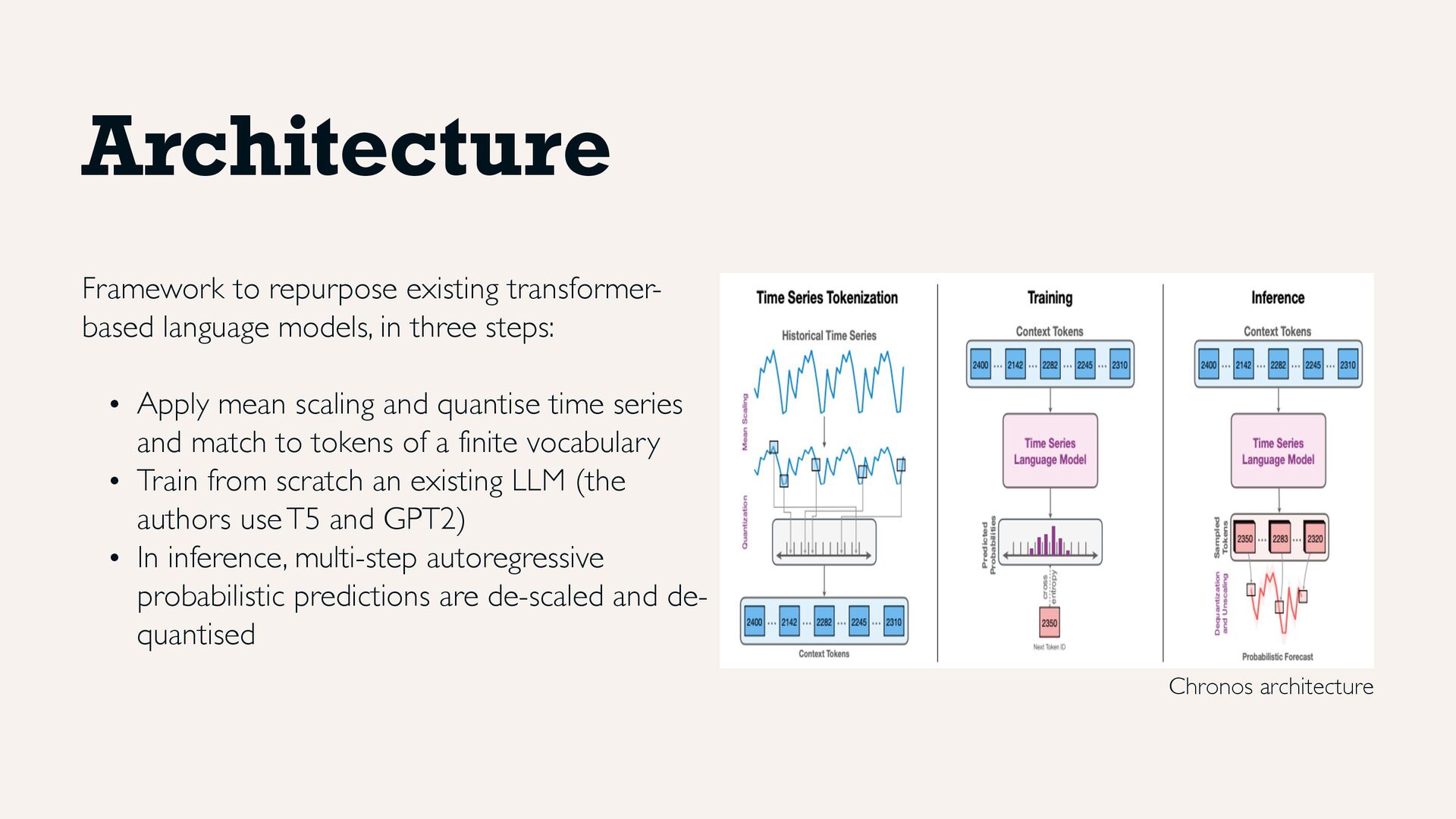
three steps: • Apply mean scaling and quantise time series and match to tokens of a finite vocabulary • Train from scratch an existing LLM (the authors use T5 and GPT2) • In inference, multi-step autoregressive probabilistic predictions are de-scaled and de- quantised Chronos architecture
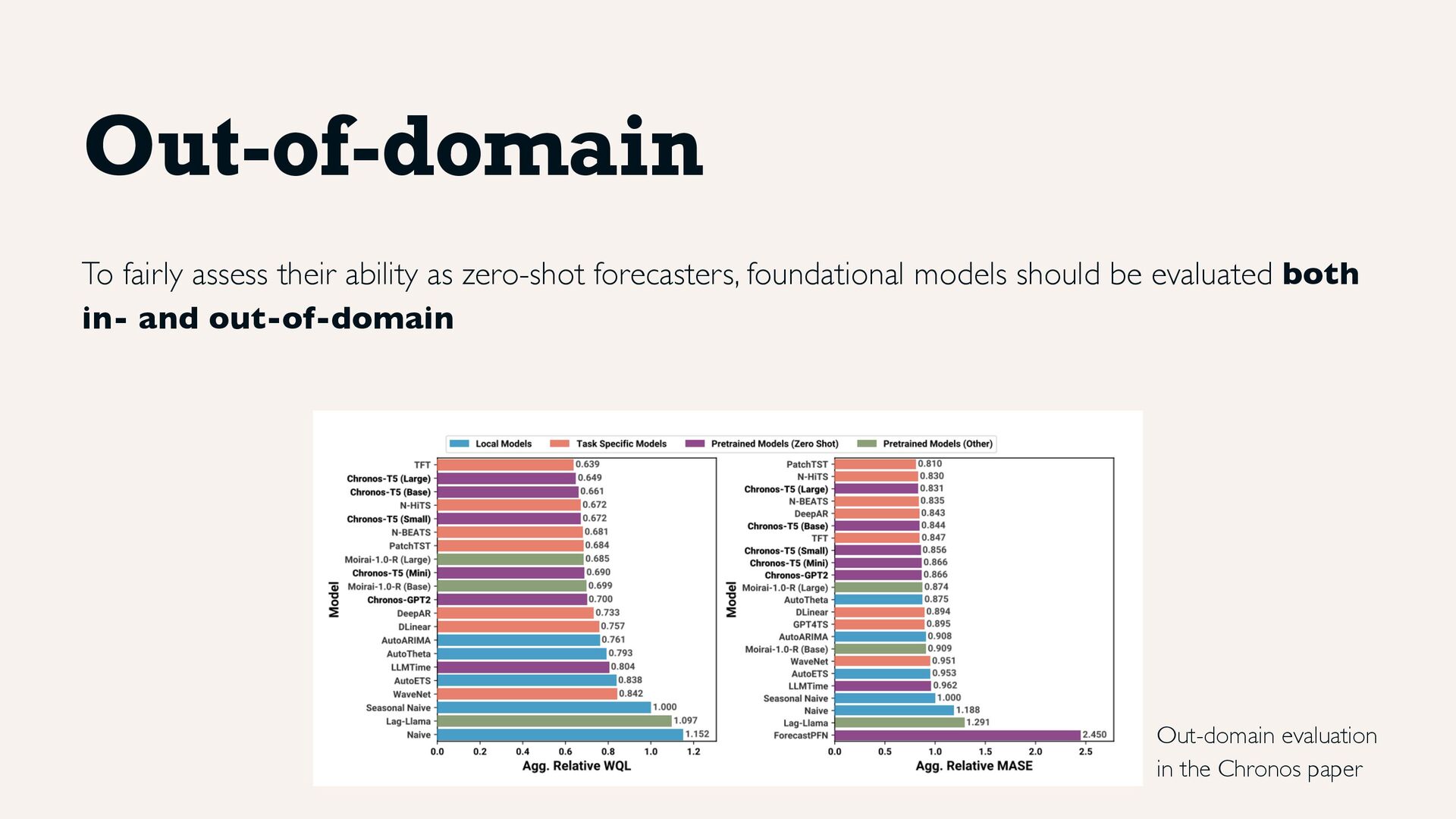
web, weather, finance, and with sampling frequencies ranging from 5 minutes up to yearly", including Monash repository, M competitions and public Kaggle datasets. Datasets are used as follows: • 13 datasets exclusively for training • 15 datasets for training and in-domain evaluation • 27 datasets exclusively for out-of-domain evaluation
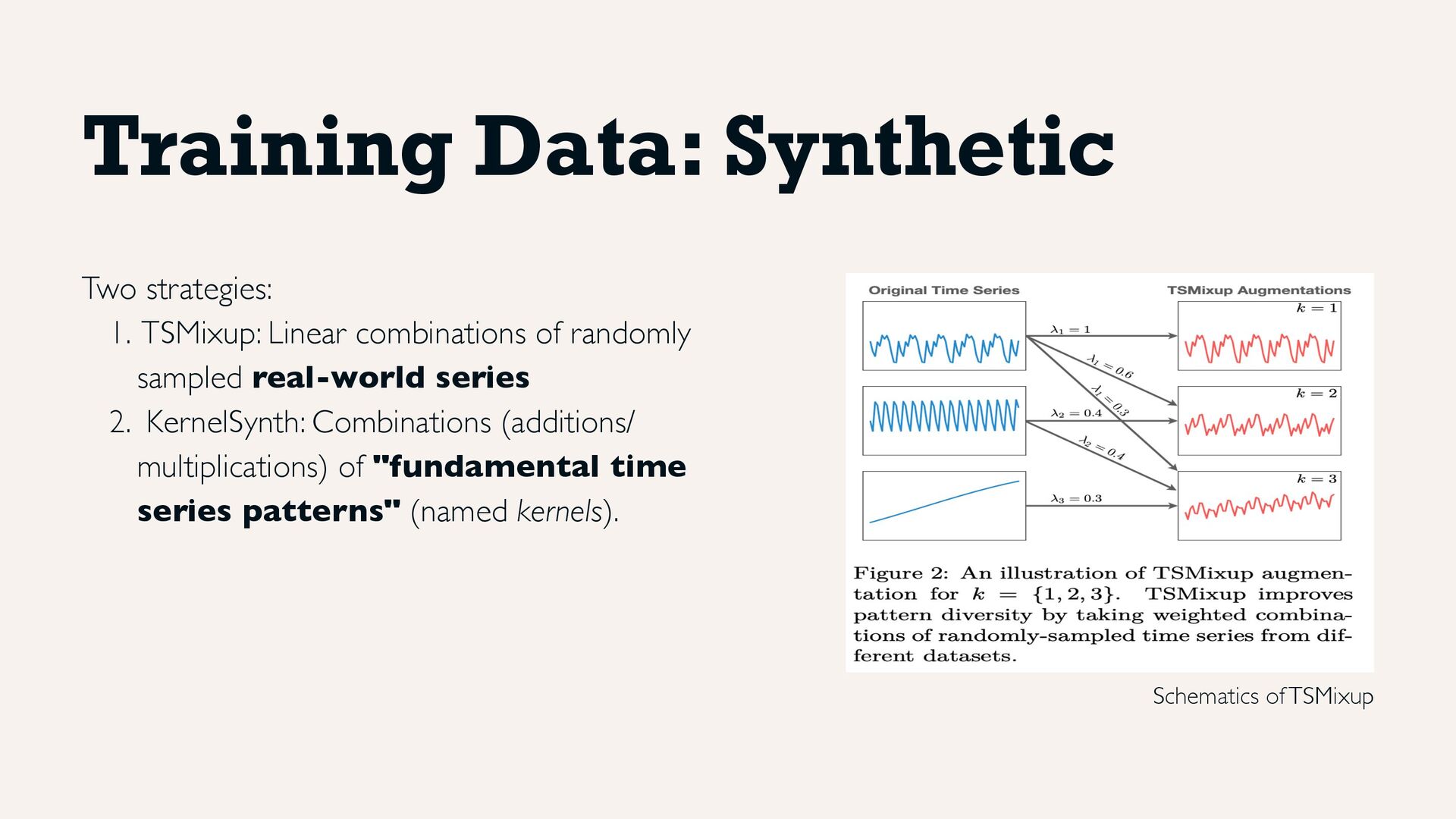
randomly sampled real-world series 2. KernelSynth: Combinations (additions/ multiplications) of "fundamental time series patterns" (named kernels). Schematics of TSMixup
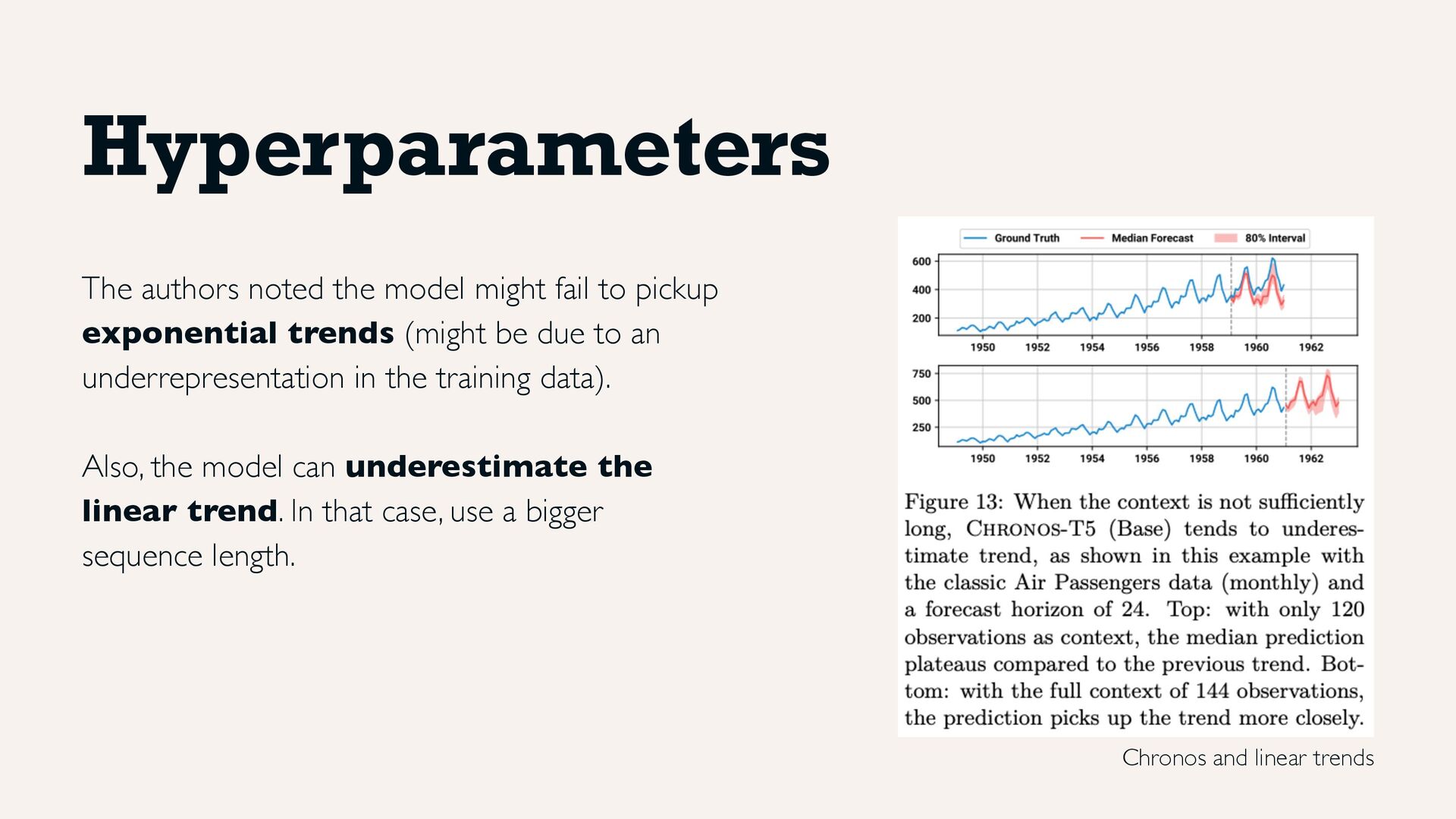
exponential trends (might be due to an underrepresentation in the training data). Also, the model can underestimate the linear trend. In that case, use a bigger sequence length. Chronos and linear trends
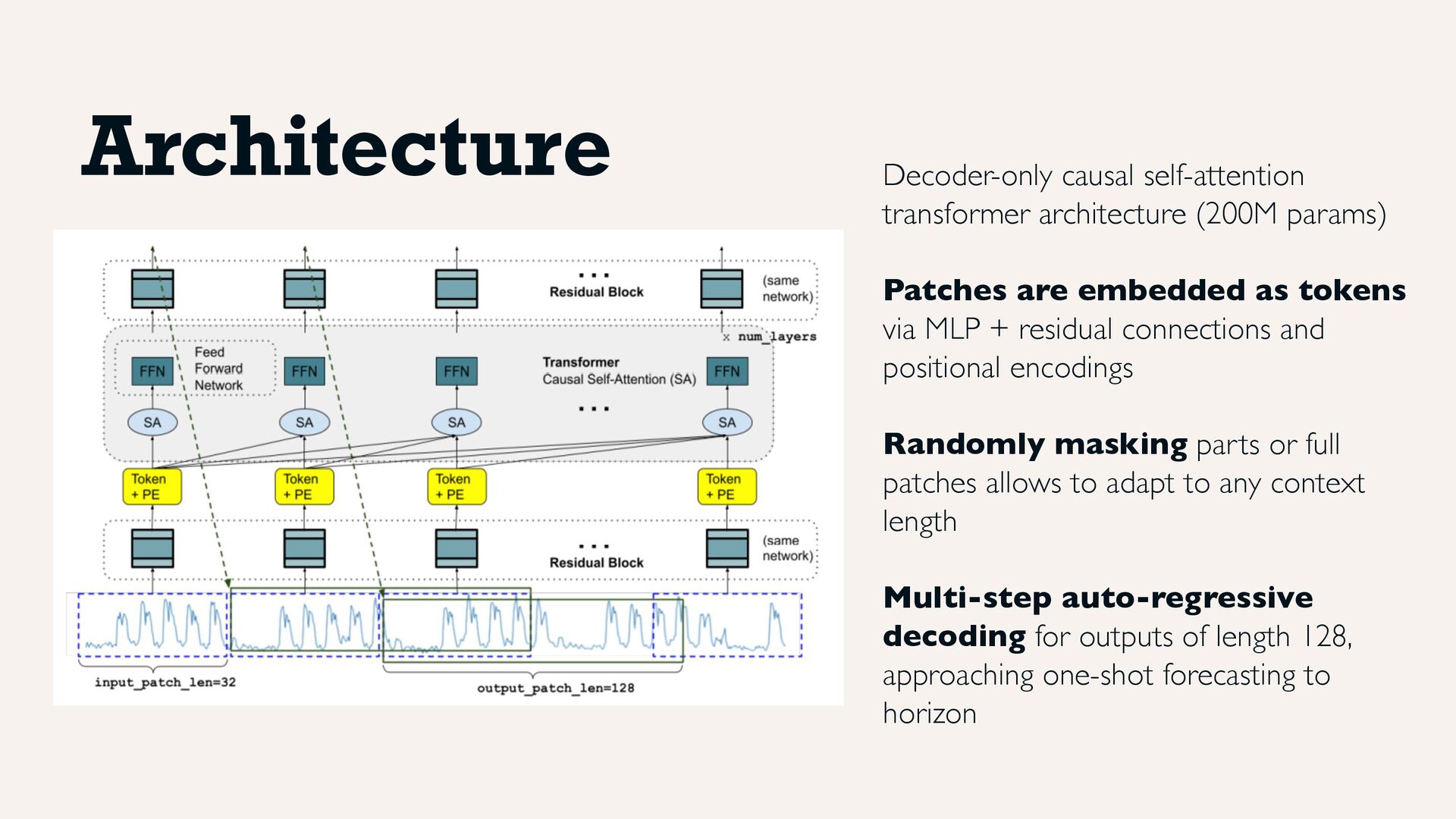
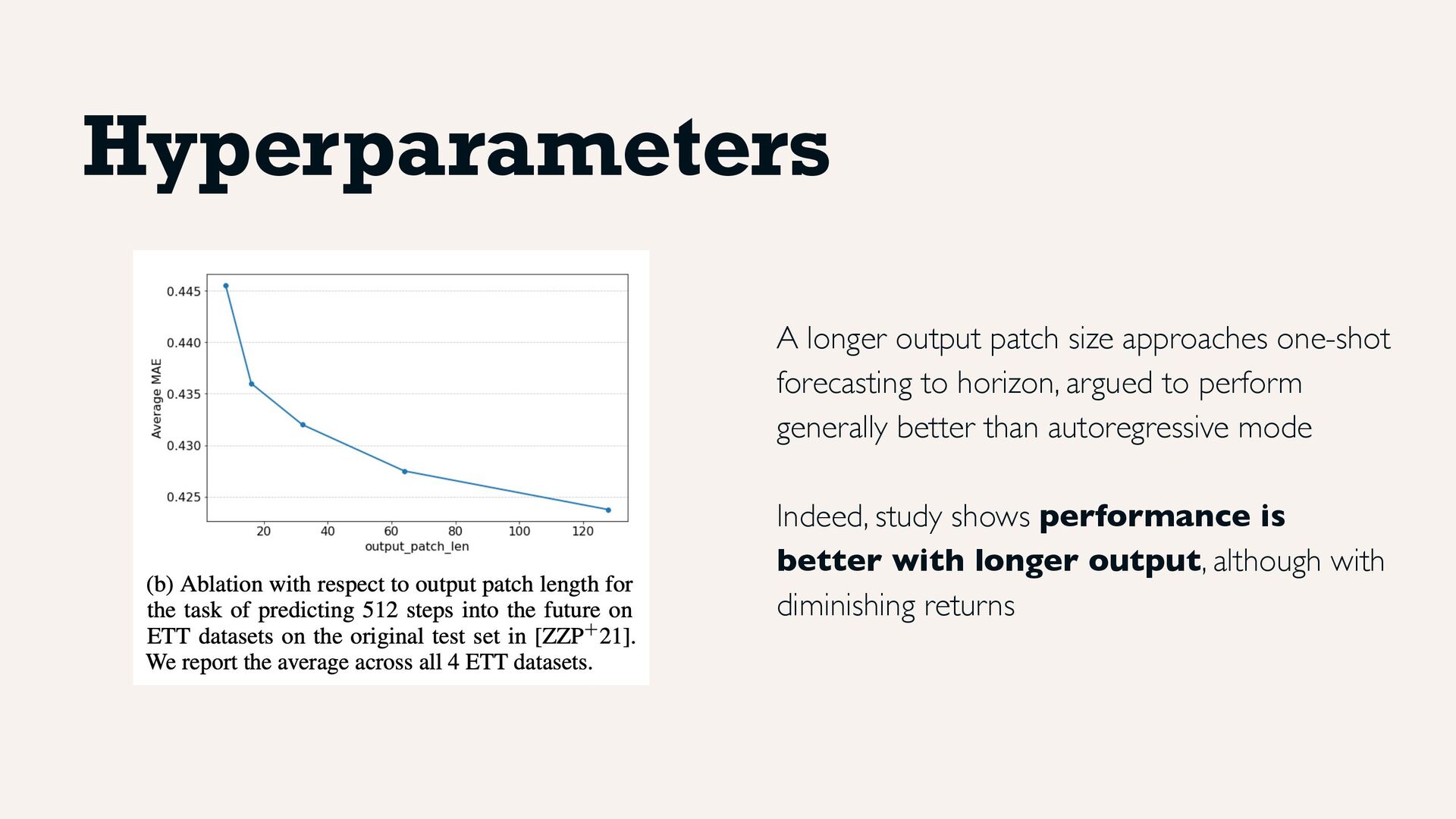
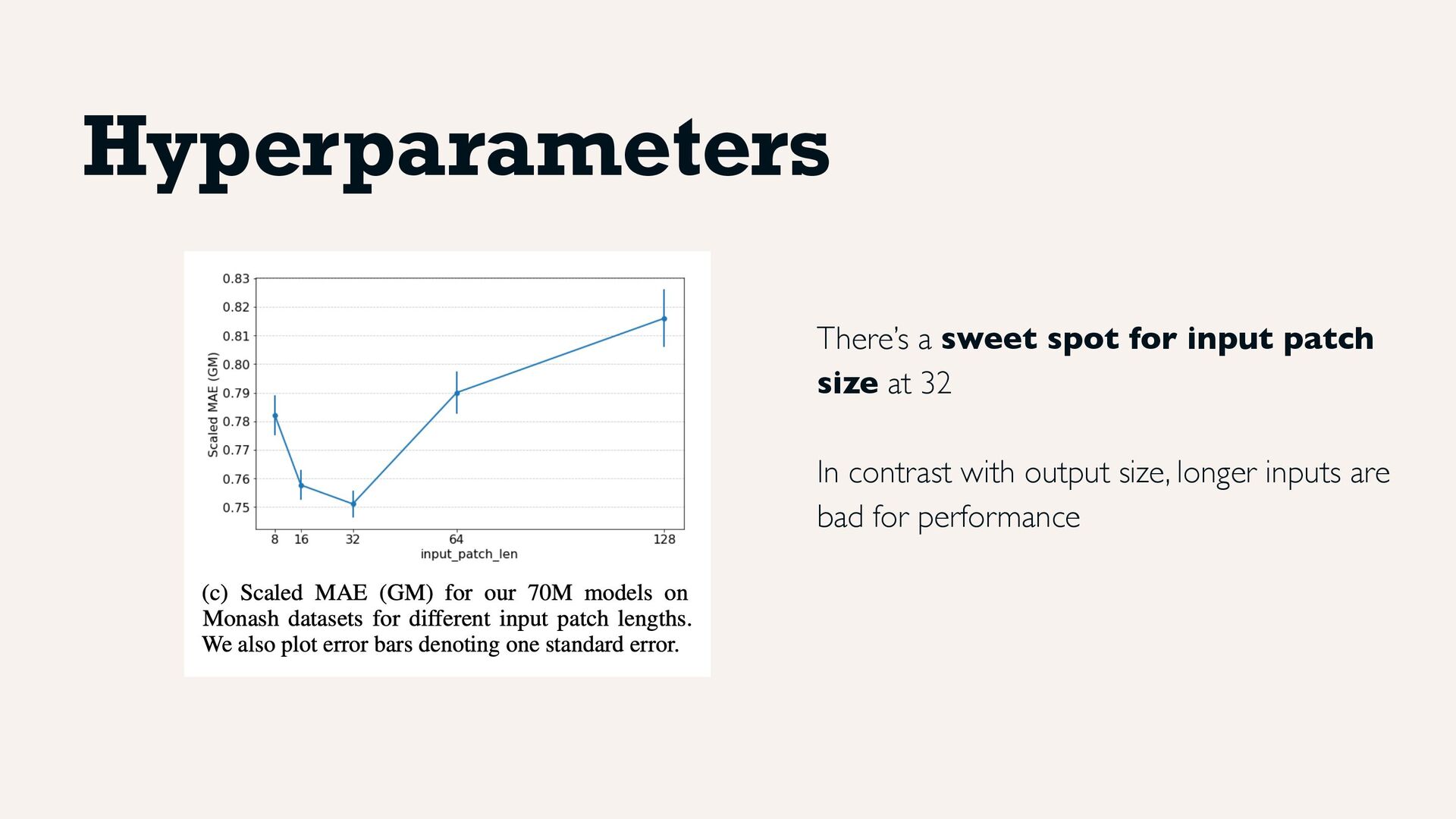
as tokens via MLP + residual connections and positional encodings Randomly masking parts or full patches allows to adapt to any context length Multi-step auto-regressive decoding for outputs of length 128, approaching one-shot forecasting to horizon Architecture
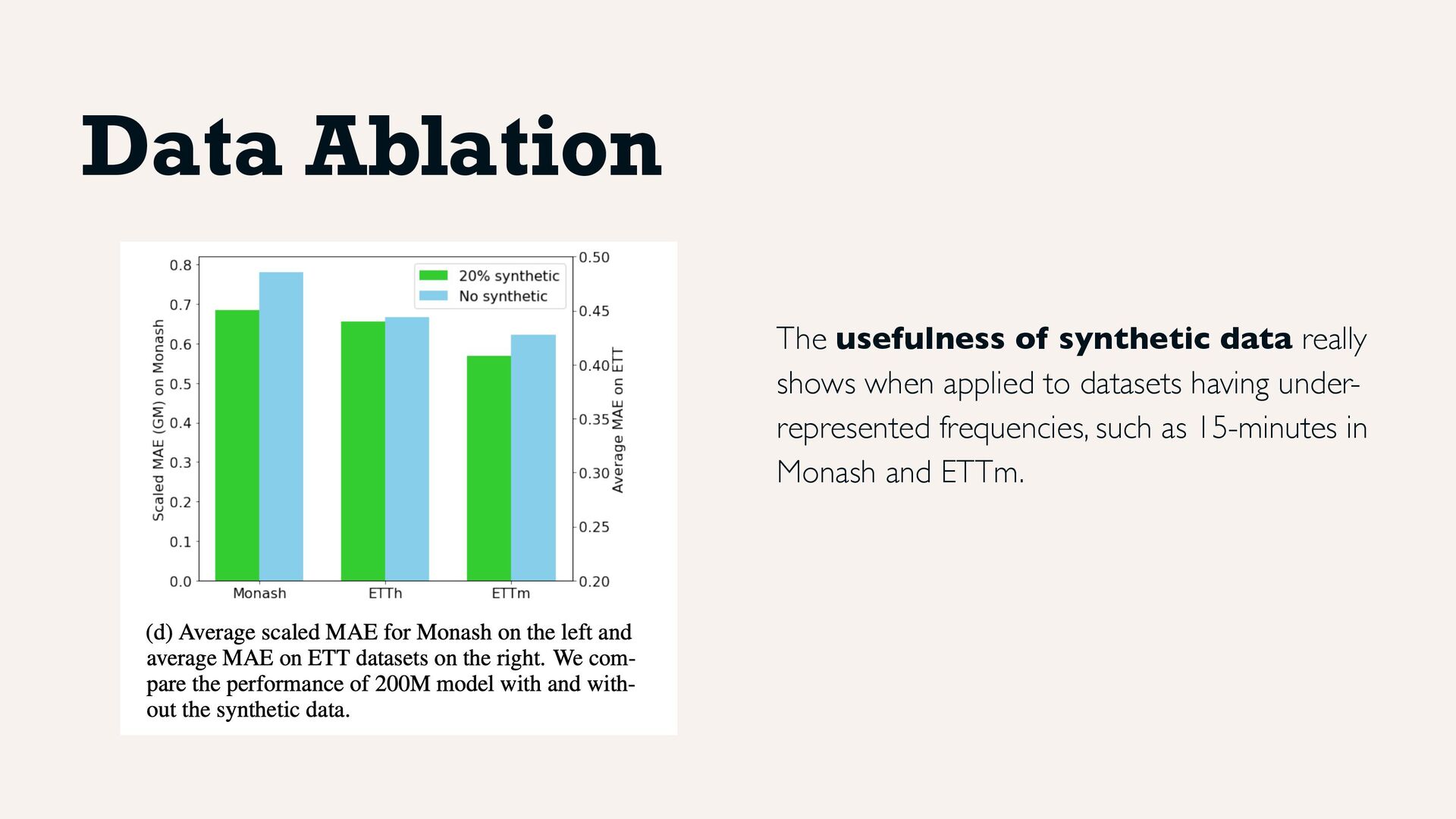
• Google Trends & Wikipedia pageviews at various frequencies, for real-world data spanning all human interests • Synthetic data for “time-series grammar”: ARMA generators, seasonal patterns, trends, step functions... During training, 80% real and 20% synthetic mix sampled from all sources Training Data
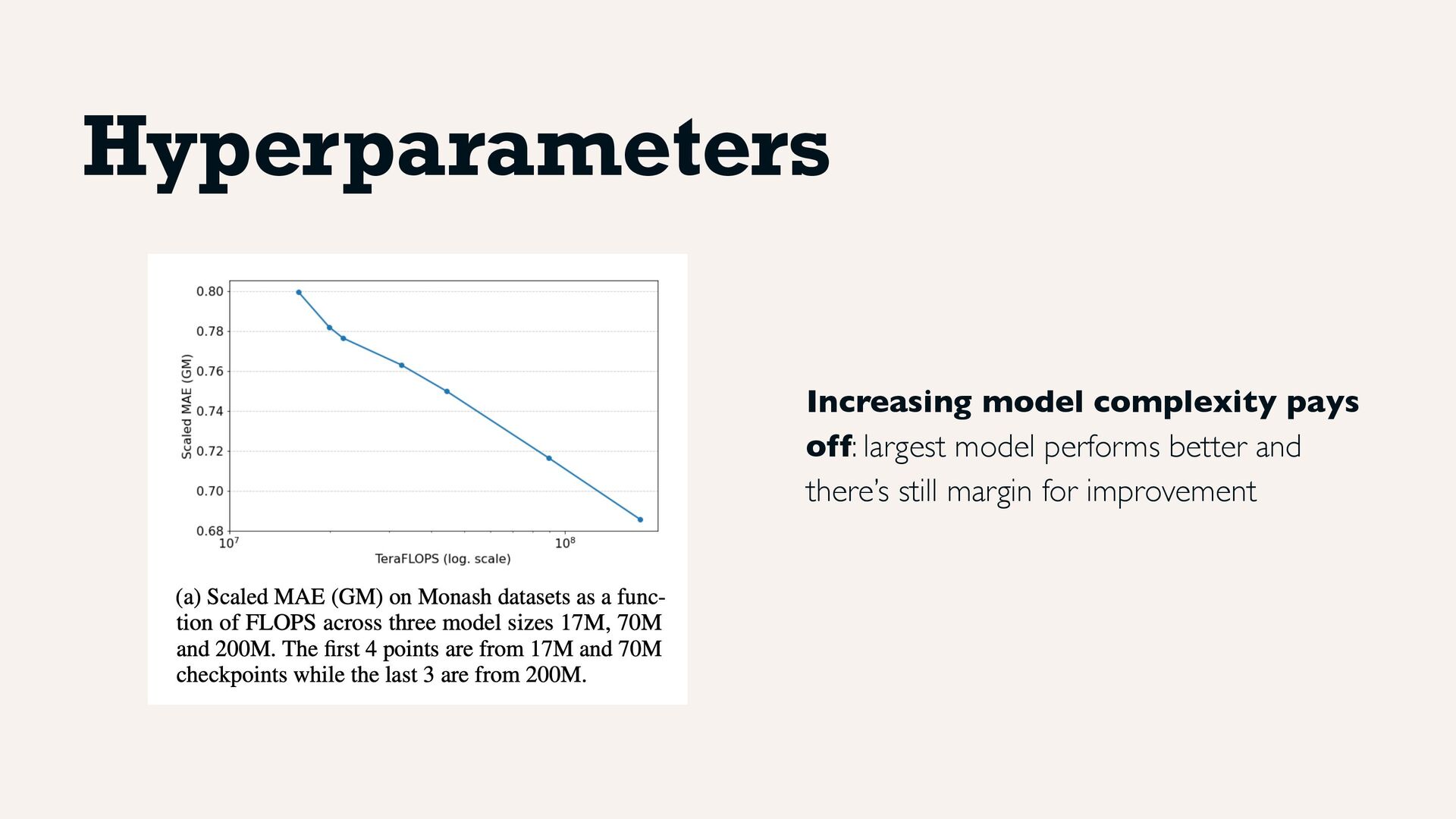
argued to perform generally better than autoregressive mode Indeed, study shows performance is better with longer output, although with diminishing returns Hyperparameters
• There’s no standard data collection for benchmarking used consistently across papers • Proper leave-out datasets are also lacking: benchmark pollution is a real risk, as with LLMs ...is not easy as it sounds
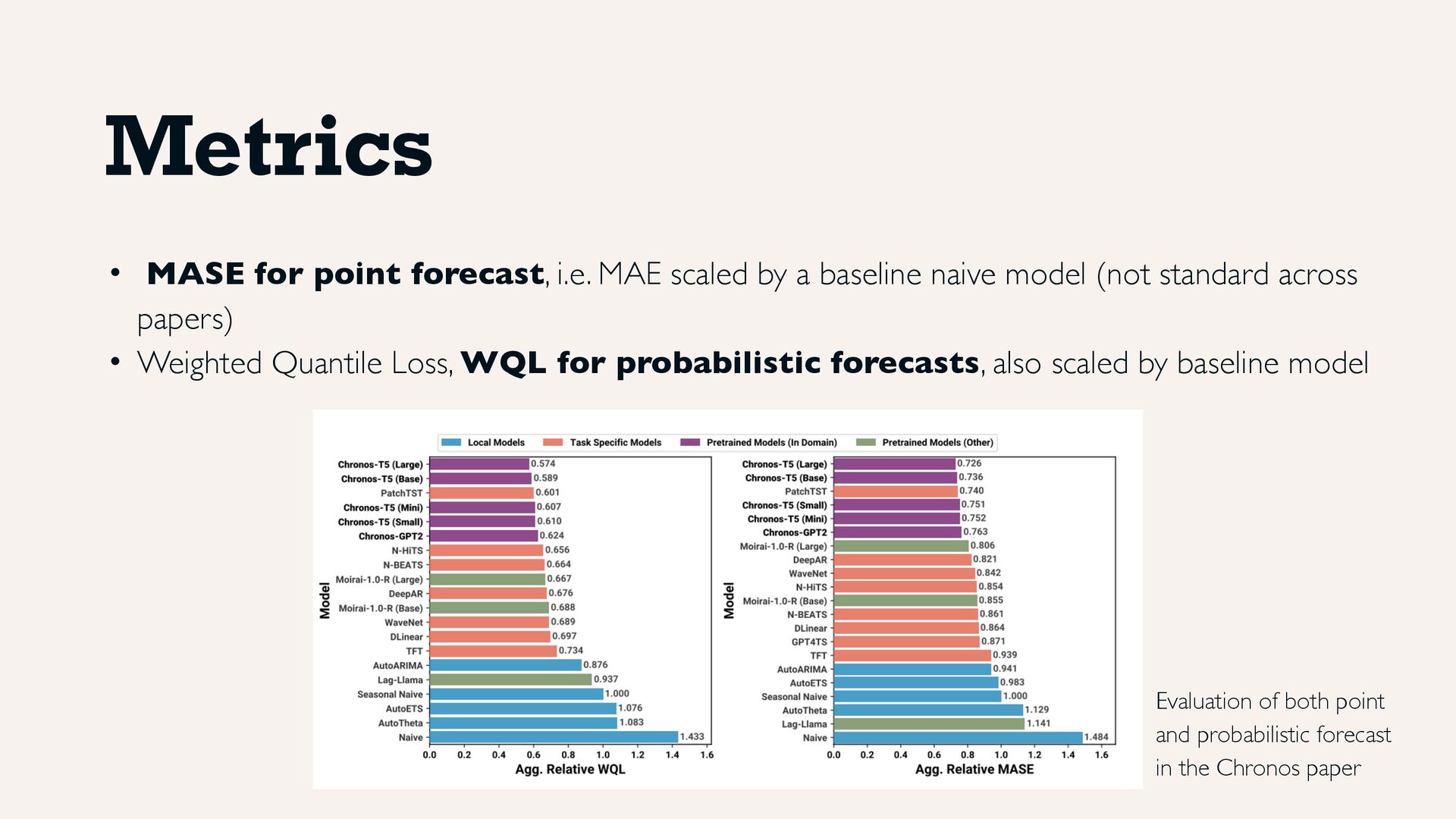
baseline naive model (not standard across papers) • Weighted Quantile Loss, WQL for probabilistic forecasts, also scaled by baseline model Metrics Evaluation of both point and probabilistic forecast in the Chronos paper
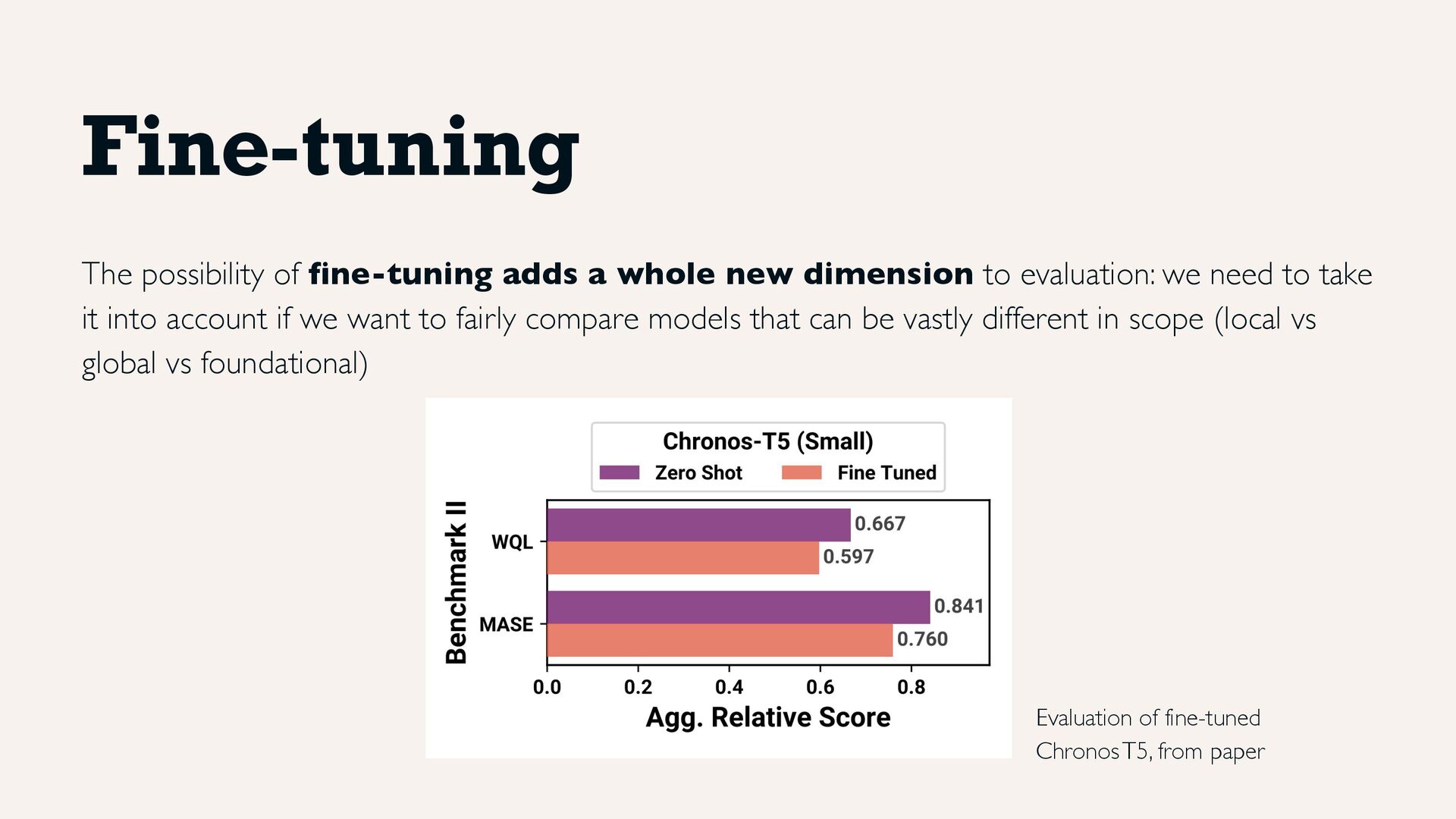
evaluation: we need to take it into account if we want to fairly compare models that can be vastly different in scope (local vs global vs foundational) Fine-tuning Evaluation of fine-tuned Chronos T5, from paper
we’re starting to notice them 2. As we speak, efforts are being made in compiling bigger and bigger collections of data 3.Synthetic data looks promising in teaching the model the most fundamental patterns 4. We’re at the early stages, with lots of room for improvement both in collecting more data and in creating better suited architectures: keep an eye out for those 5.Don’t sleep on fine-tuning: it is still under-developed, could be key for success
to a lack of a standard leave-out data collection 2. Don't just pick the model that ranks highest on benchmarks: do your own testing on the frequency, domain and horizon you’re interested in 3.Publicly available time series are limited, and not nearly as ubiquitous as text 4. We’re not sure that performance will scale with data and model complexity
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}