0.8 Code completion Symbol lookup First class support for Babashka Basic support for sideloading (functionality added in nREPL 0.7) Smarter handling of ClojureDocs data (no downloads the first time you try to use it or automatic data updates) Auto-trimming of REPL buffers (disabled by default) Small improvements
default Bencode transport) Added the ability to sideload Clojure libraries into a running nREPL server Now clients can inject the libraries they need without the need for additional manual setup
No ambiguity No flexibility You can’t work on multiple projects You can’t work easily on a ClojureScript project (typically people use two connections for those)
No ambiguity Only one extra command to mark the “current” connection Some flexibility You can work on multiple projects You get to decide which connection to use when
always clear which connection to use (e.g. you can have connections without project or two connections to the same project) Grouping Clojure and ClojureScript connections together and deciding what to do about things like `cljc` files Lots of flexibility You can work on multiple projects All sorts of workflows are supported out of the box
than before Operate on groups of related connections (sessions) instead of connections Lots of flexibility You can work on multiple projects All sorts of workflows are supported out of the box
before, but now it’s a generic library for session management in Emacs Session management becomes a third-party library Less flexibility You can work on multiple projects Some workflows get broken, as we now have a more rigid session mapping mechanism
of the codebase Connection management in CIDER The choice of a REPL server Request processing API Choice of data structures It’s rarely the same as inherent complexity (which is often rooted in the business domain) It’s the complexity that’s hardest/most expensive to undo
Configuration options Things built on the top of the core APIs Variations of core commands and APIs The stuff that’s nice to have, but you didn’t really need Easy to undo, as it’s typically not coupled with anything important
deps Very basic functionality All implemented in terms of evaluating Clojure code and processing the raw result Few configuration options Works everywhere
predating the birth of cider-nrepl and the modern connection management Dropped the notion of dedicated buffers for things like documentation, macroexpansion, results, etc Not coupled with Clojure as strongly as CIDER Convenience/flexibility vs simplicity
What type of complexity is this? How big of an (positive) impact it would make? Do I want to develop it? Can I develop it (properly)? Does anyone want to develop it? Do I want to maintain this? Can I maintain this?
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
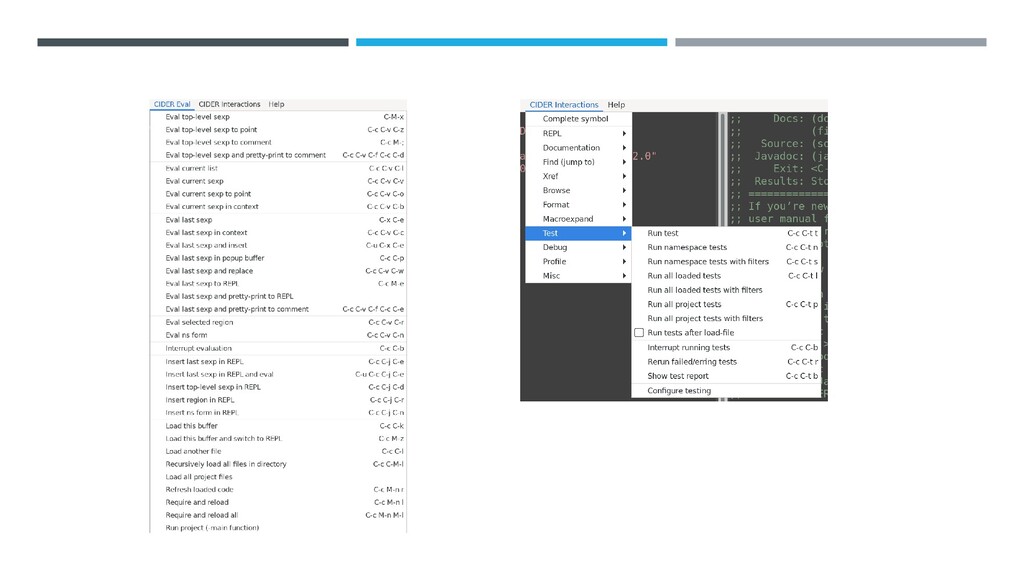{kind=link}
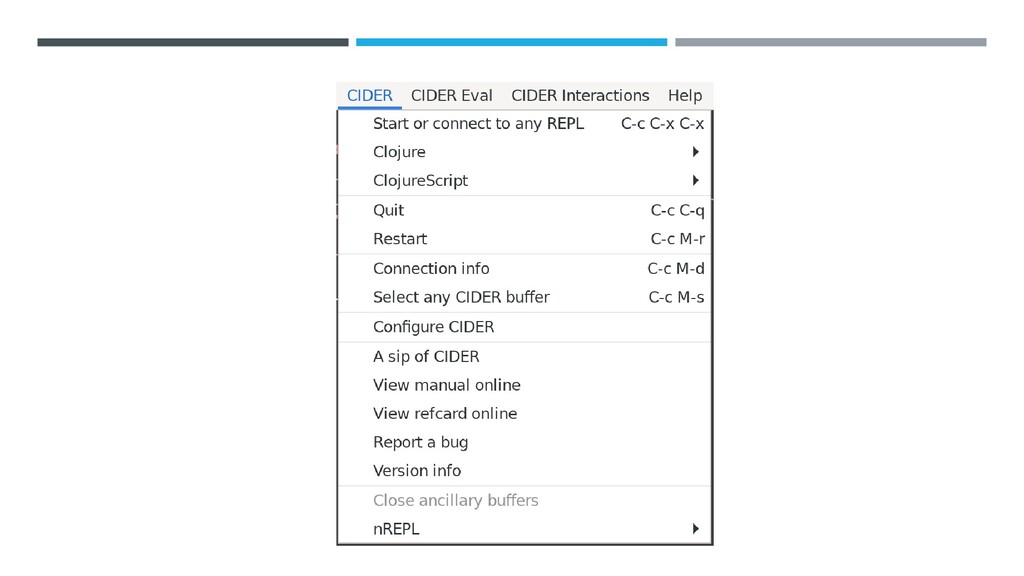{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}