Présentation faite à Devoxx France 2019.
Il s'agit d'une présentation haut niveau sur les concepts d'Apache Pulsar (comment ça marche, développement, ...)
pour compenser certaines limites des solutions de l’époque Pour des apps critiques comme Yahoo Mail, Yahoo Finance, Yahoo Sports, etc Open sourcé en 2016 Devenu Top Level Project de la fondation Apache en sept 2018 Premier déploiement Q2 2015
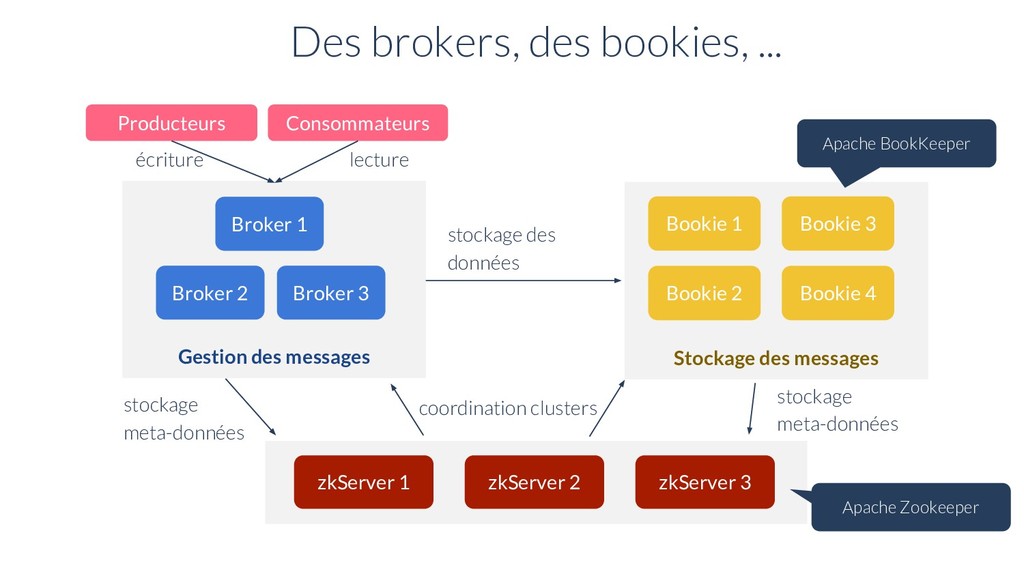
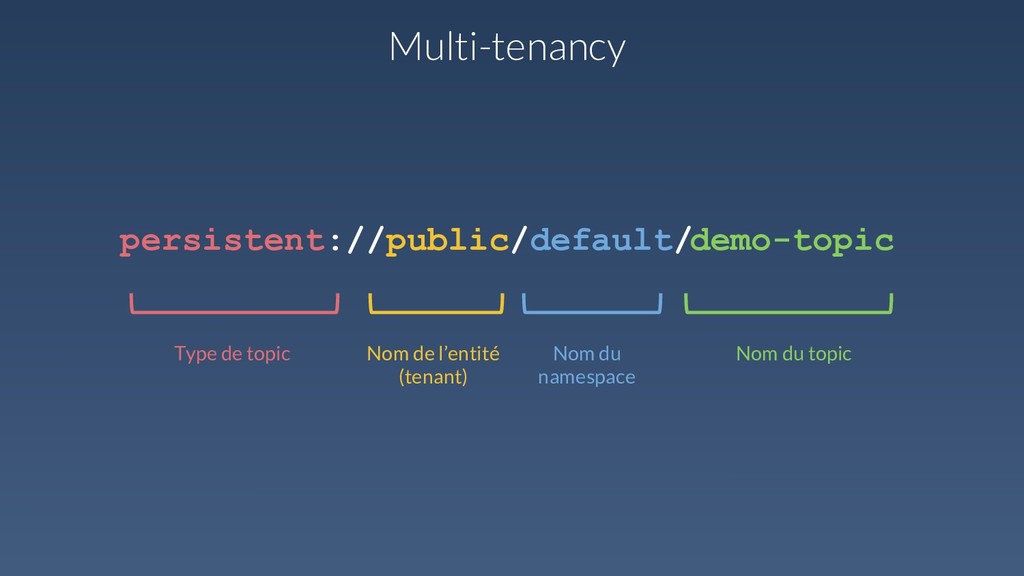
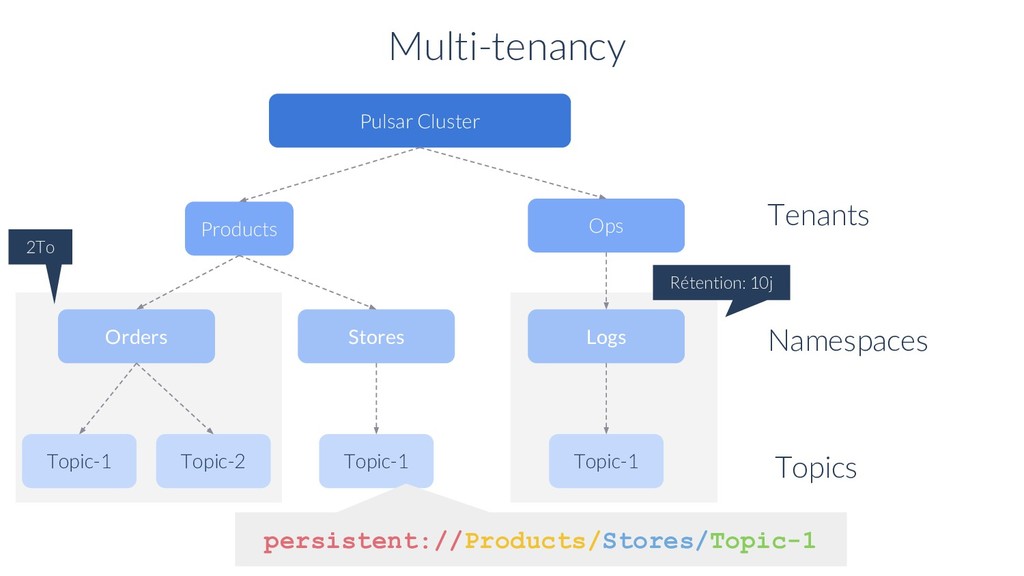
sur disque Garantie d’ordre des messages Réplication géographique des données Multi-entité (tenant) Fort débit / Faible latence Garantie de livraison Hautement scalable
à faible latence Conçu à l’origine comme une solution pour la haute disponibilité du NameNode de HDFS (WAL) Avec Pulsar: stockage des données et des offsets (cursors)
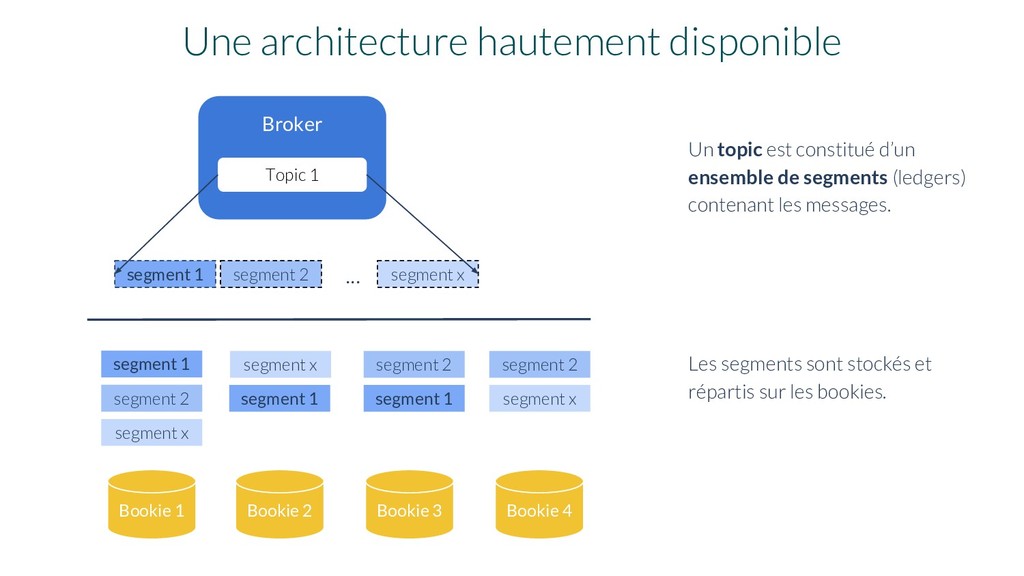
Bookie 1 segment 1 Une architecture hautement disponible segment 1 segment 1 segment x segment x segment 2 segment 2 Bookie 2 Bookie 3 Un topic est constitué d’un ensemble de segments (ledgers) contenant les messages. Les segments sont stockés et répartis sur les bookies. segment x segment 2 Bookie 4
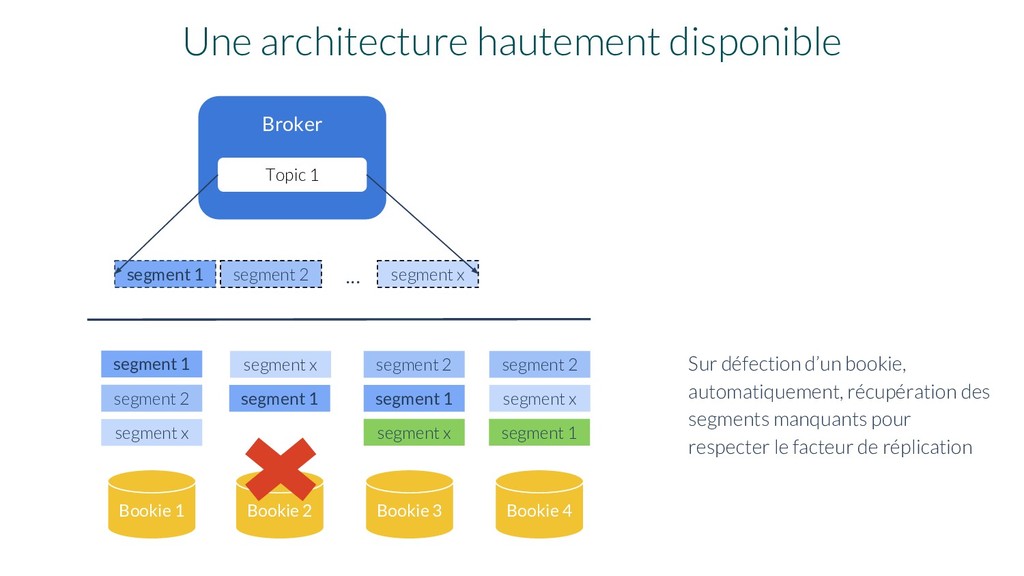
Bookie 1 segment 1 Une architecture hautement disponible segment 1 segment 1 segment x segment x segment 2 segment 2 Bookie 2 Bookie 3 Sur défection d’un bookie, automatiquement, récupération des segments manquants pour respecter le facteur de réplication segment x segment 2 Bookie 4 segment x segment 1
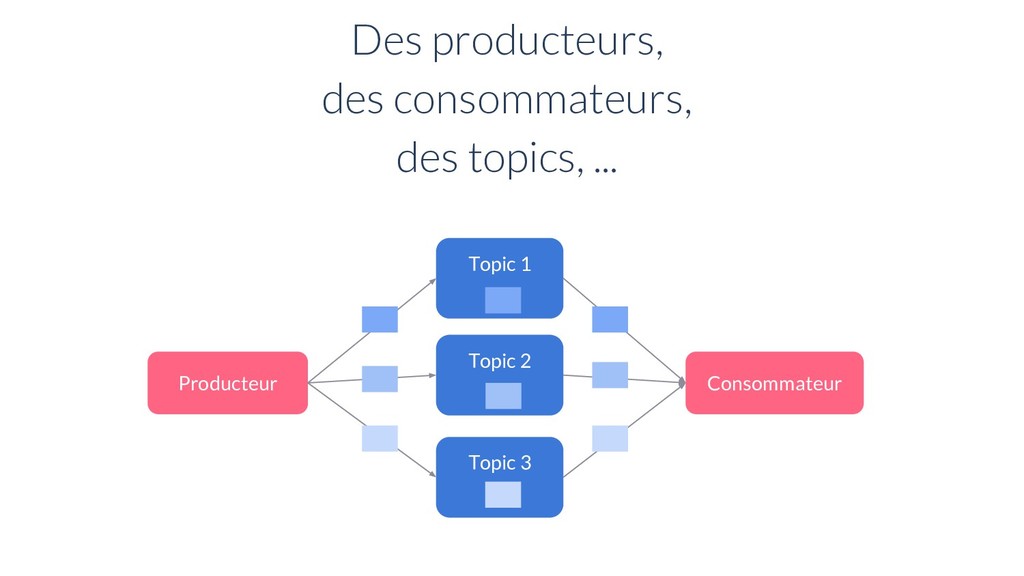
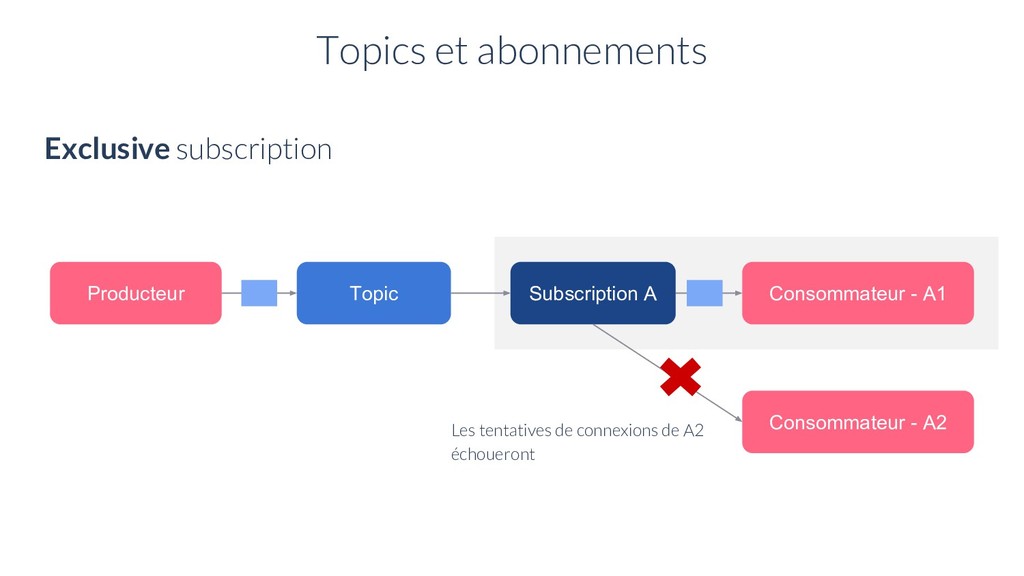
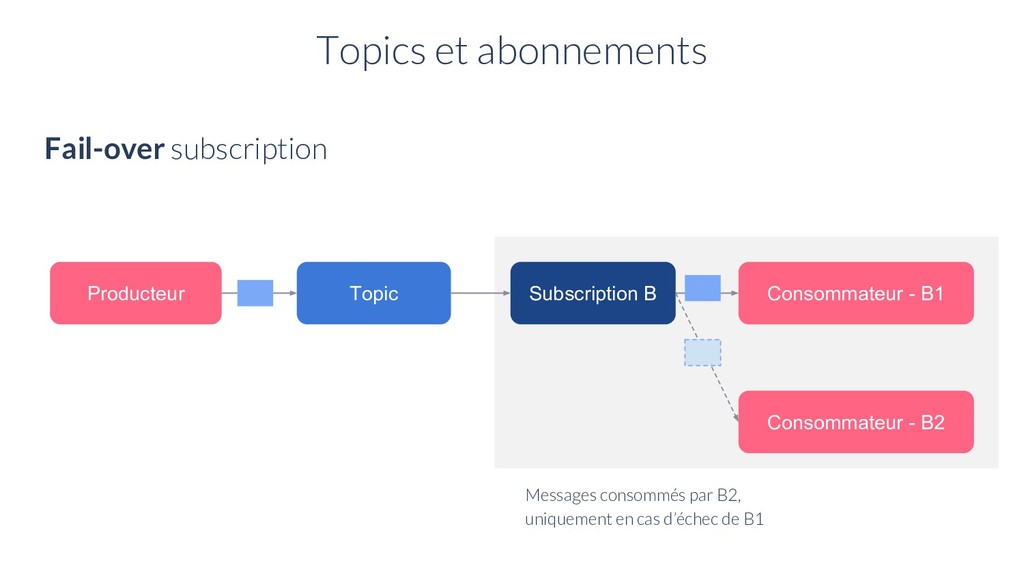
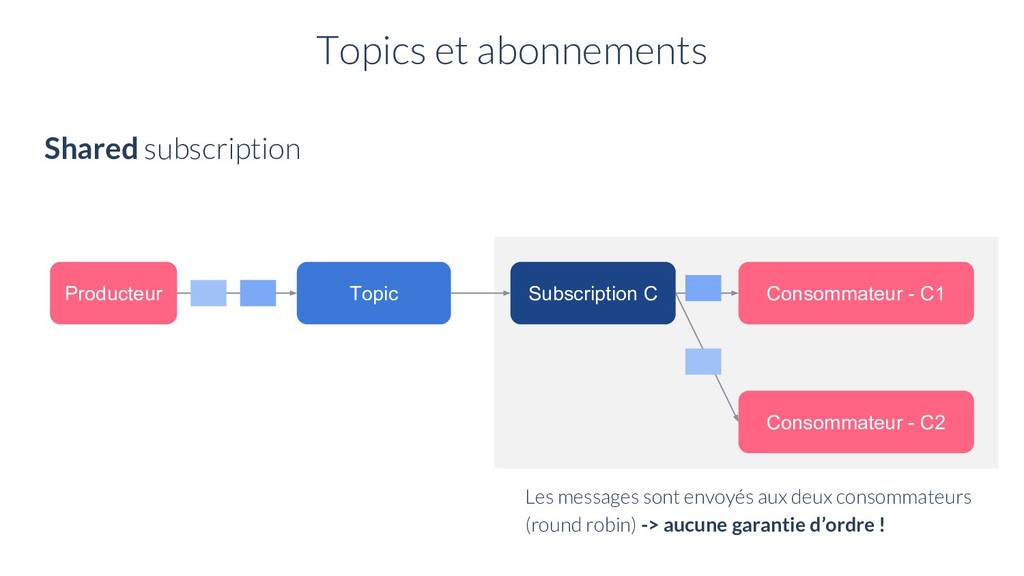
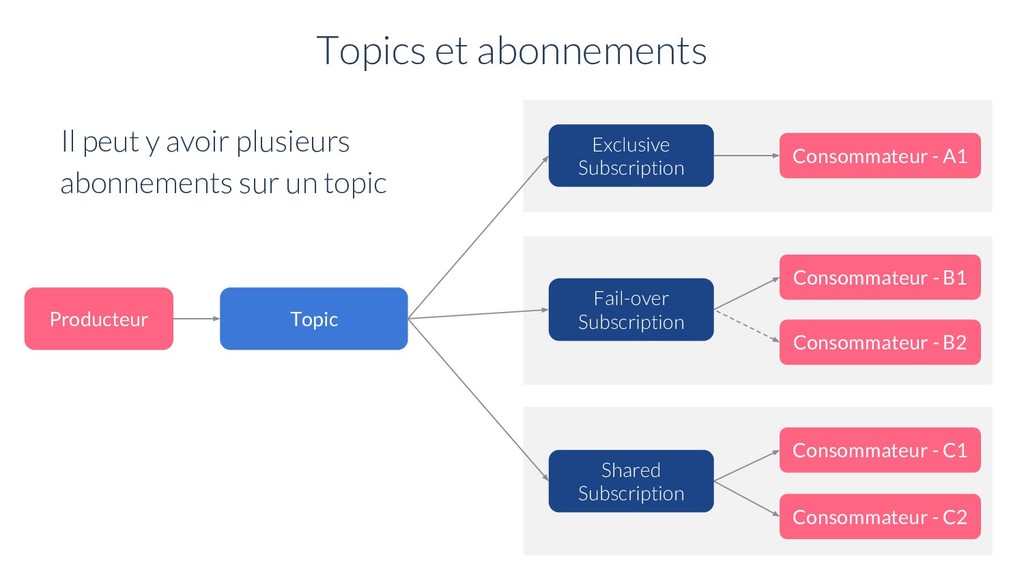
A1 Consommateur - C1 Consommateur - C2 Exclusive Subscription Il peut y avoir plusieurs abonnements sur un topic Fail-over Subscription Shared Subscription Topics et abonnements
à un schéma) - Clé (optionnel) - Ensemble de propriétés (optionnel) - Nom du producteur - Id de séquence (numéro d’ordre dans le topic, attribué par le producteur) - Timestamps
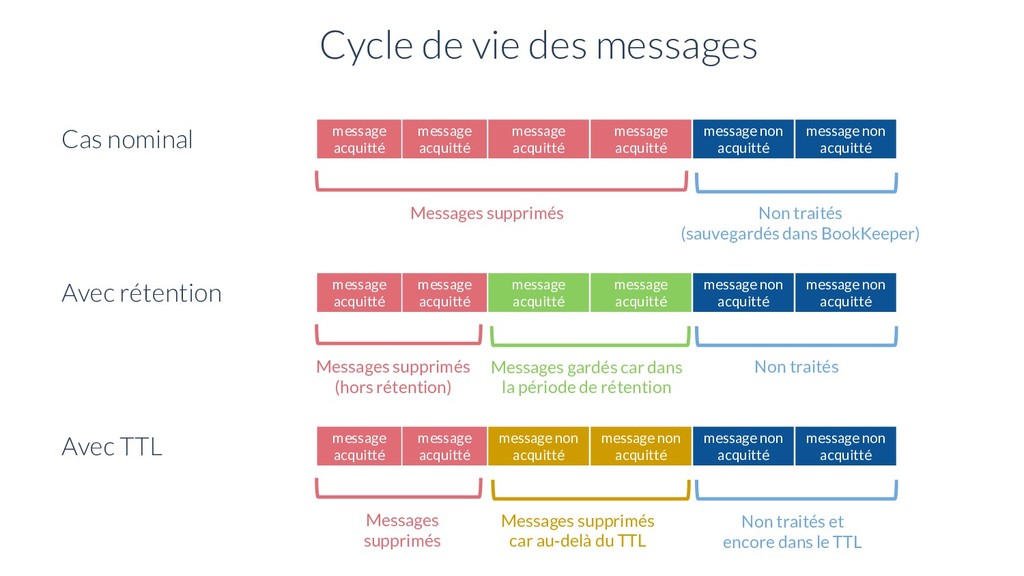
acquitté Messages supprimés (hors rétention) Messages gardés car dans la période de rétention Non traités message acquitté message acquitté message non acquitté message non acquitté Messages supprimés Messages supprimés car au-delà du TTL Non traités et encore dans le TTL message non acquitté message non acquitté message non acquitté message non acquitté message acquitté message acquitté Avec TTL message acquitté message acquitté Messages supprimés Non traités (sauvegardés dans BookKeeper) message non acquitté message non acquitté message acquitté message acquitté Cas nominal
à partir du premier message non acquitté Message msg = consumer.receive(1000, TimeUnit.SECONDS); System.out.printf("Message: %s, from %s with id=%s\n", new String(msg.getData()), msg.getProducerName(), msg.getMessageId()); consumer.acknowledge(msg);
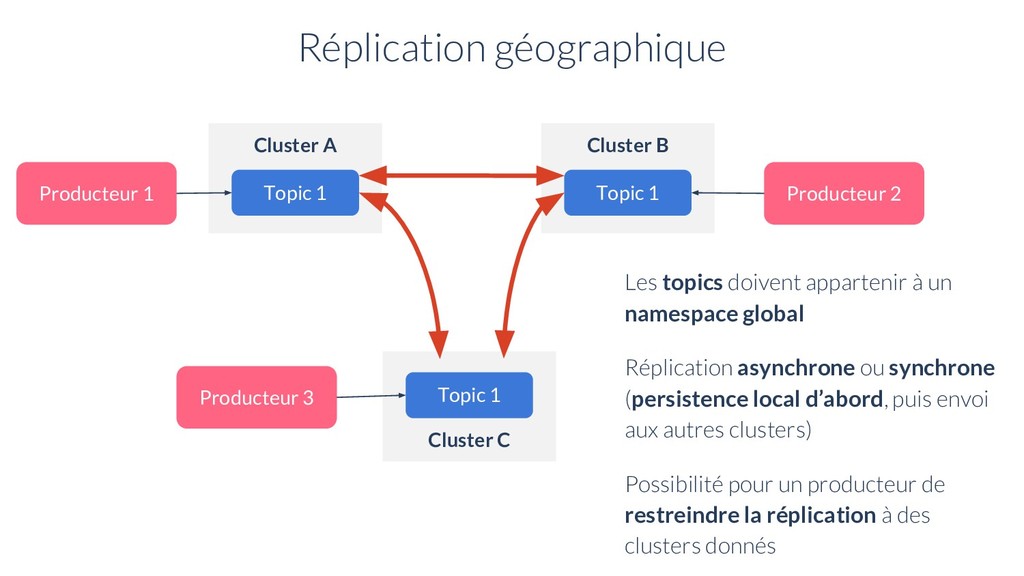
Topic 1 Producteur 2 Cluster C Topic 1 Producteur 3 Les topics doivent appartenir à un namespace global Réplication asynchrone ou synchrone (persistence local d’abord, puis envoi aux autres clusters) Possibilité pour un producteur de restreindre la réplication à des clusters donnés
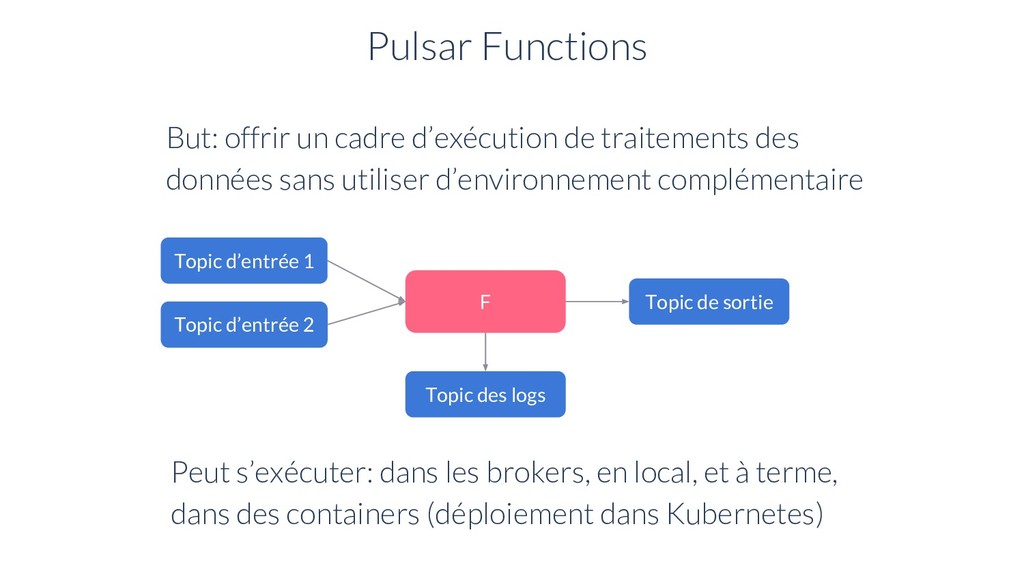
d’exécution de traitements des données sans utiliser d’environnement complémentaire Topic d’entrée 1 Peut s’exécuter: dans les brokers, en local, et à terme, dans des containers (déploiement dans Kubernetes) Topic d’entrée 2 Topic des logs
matures): - découplage broker et stockage - gestion par segments - tier-storage, - geo-replication, - Pulsar IO - Pulsar Functions - Schema registry, - SQL, - … Environnement complet pour couvrir vos besoins en termes de stream processing Aujourd’hui chez Yahoo ! - > 2 millions de topics - > 100 milliards de messages / jour - > 150 brokers Plus d’infos: https://streaml.io/blog
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Producer<byte[]> producer = client.newProducer() .topic("demo-topic") .producerName("demo-producer") .batchingMaxPublishDelay(10, TimeUnit.MILLISECONDS) .sendTimeout(10, TimeUnit.SECONDS)](https://files.speakerdeck.com/presentations/fcdcfb4efdf84e81a6b930539f9cb0e8/slide_24.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}