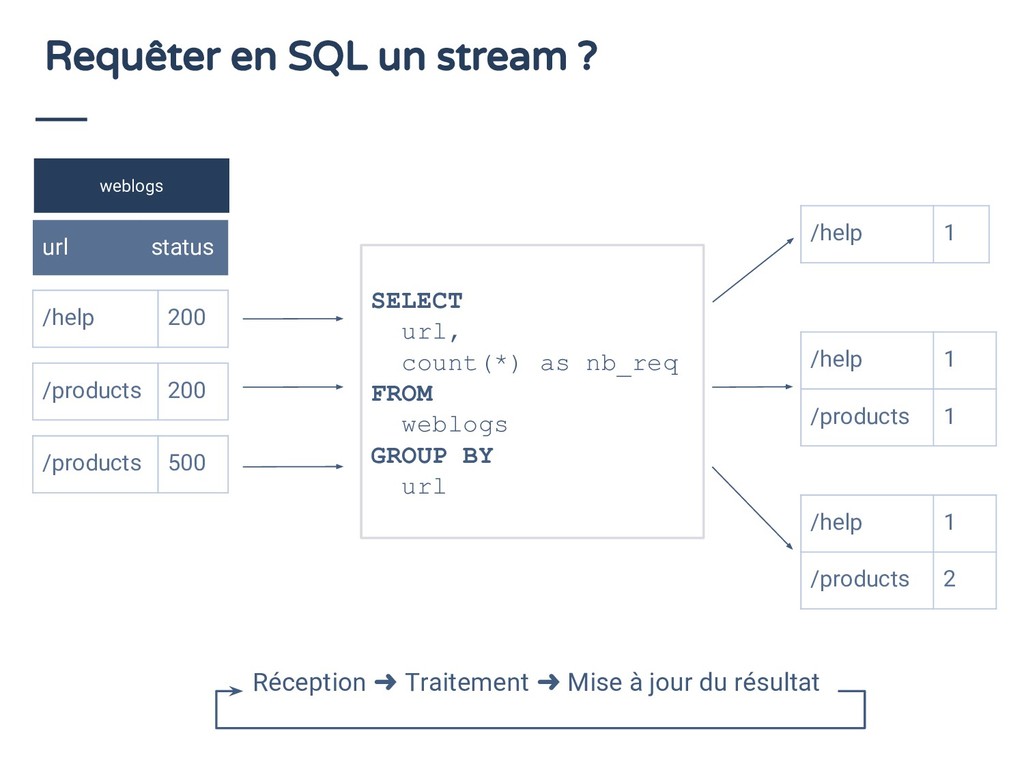
Le SQL est un standard pour accéder vos données, donc, dans un monde orienté flux, quoi de plus normal que de retrouver le SQL pour traiter vos streams. Dans ce talk, vous découvrirez les extensions apportées à SQL par Apache Calcite pour répondre à cette problématique. Allez, un petit exemple pour la route: `select stream * from events`
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
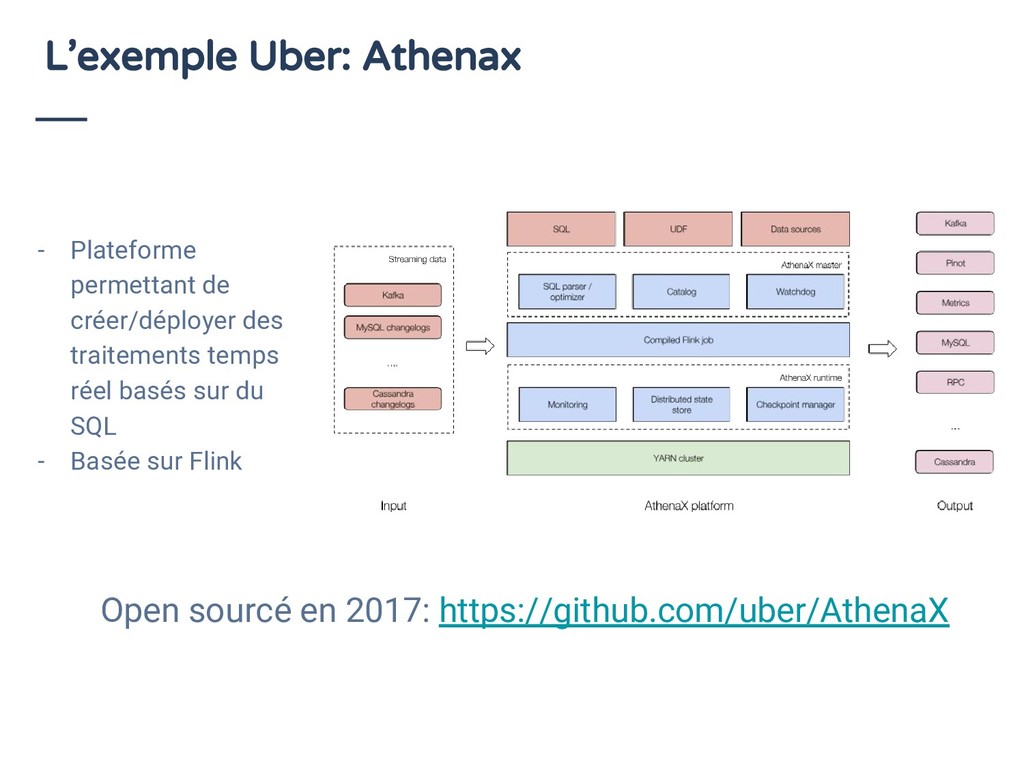{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
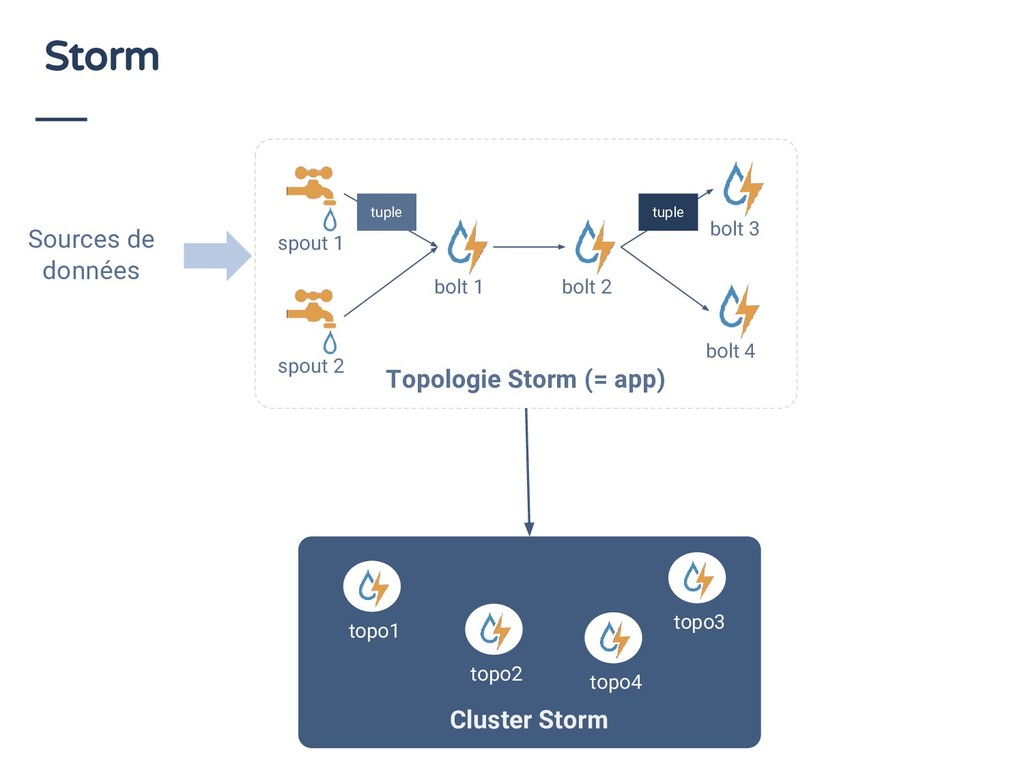{kind=link}
{kind=link}
{kind=link}