world is denormalized! • Has primary and secondary indexes • Great for web applications that have a main data pattern • (e.g. blog posts, tweets, customers, emails) • But what about alternate paths through data? • A built-in Map/Reduce engine using Javascript was the typical way
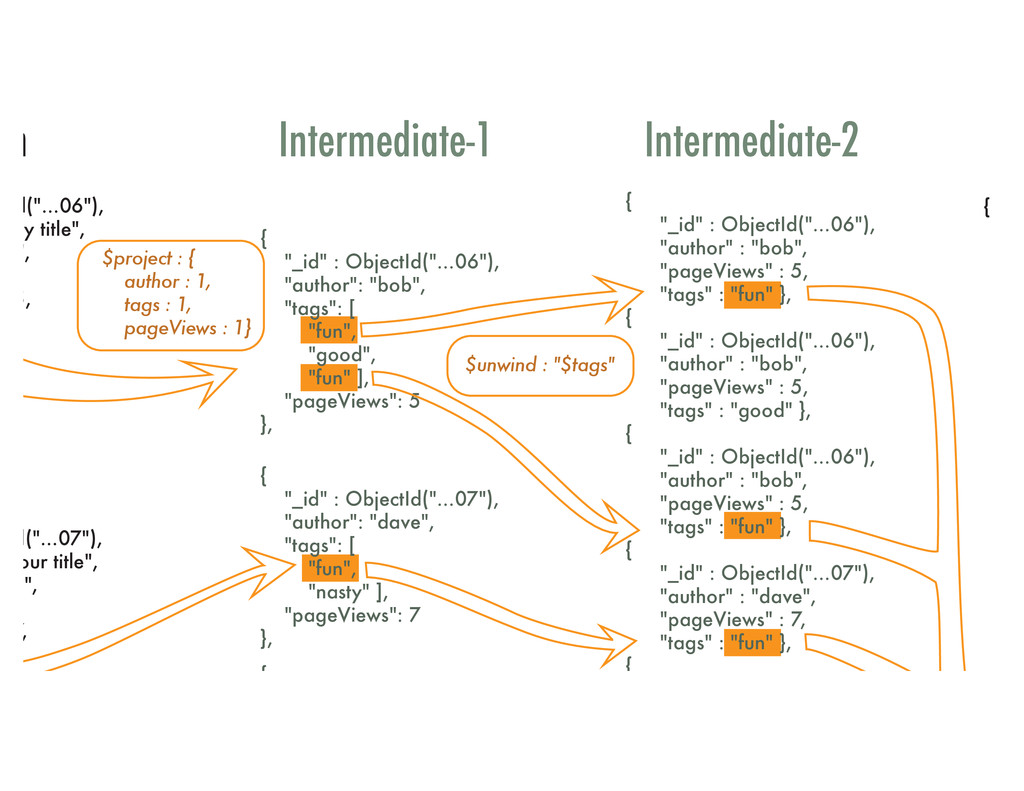
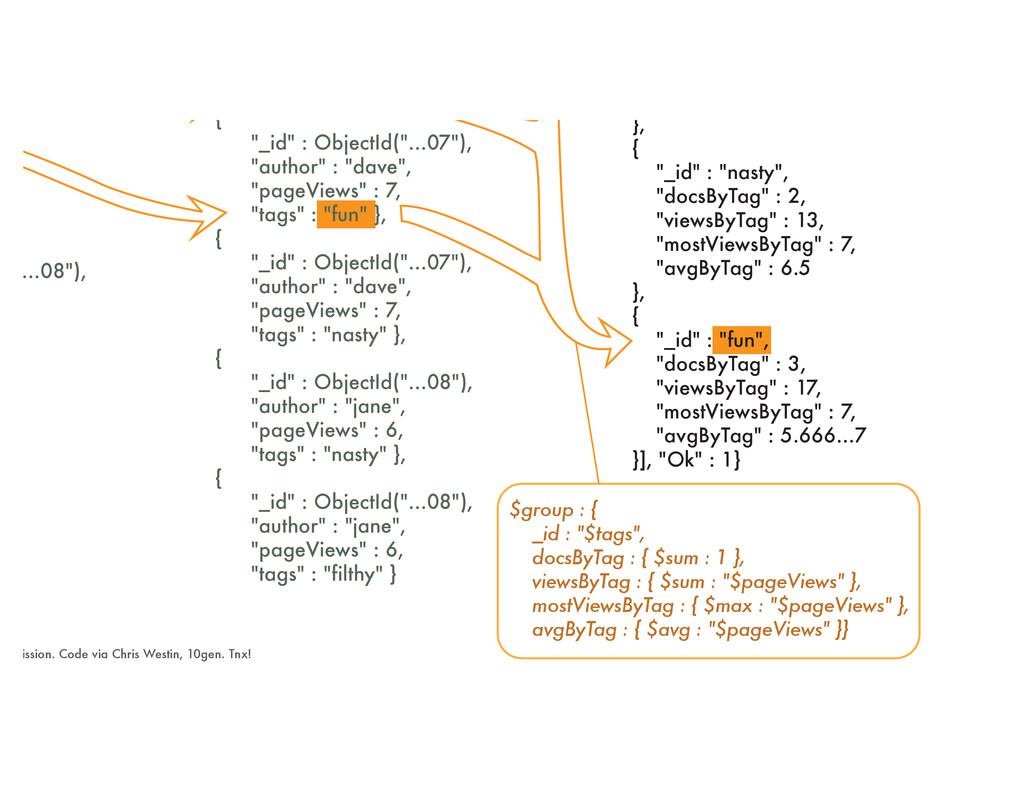
• Some popular calculations include finding averages, maxima and minima, statistics • Can also pivot data from an internal array • Alternate to map/reduce (M/R) • C++ based = better performance over MongoDB M/R • Declarative chained pipeline of operations • Official documentation: http://docs.mongodb.org/manual/ applications/aggregation/
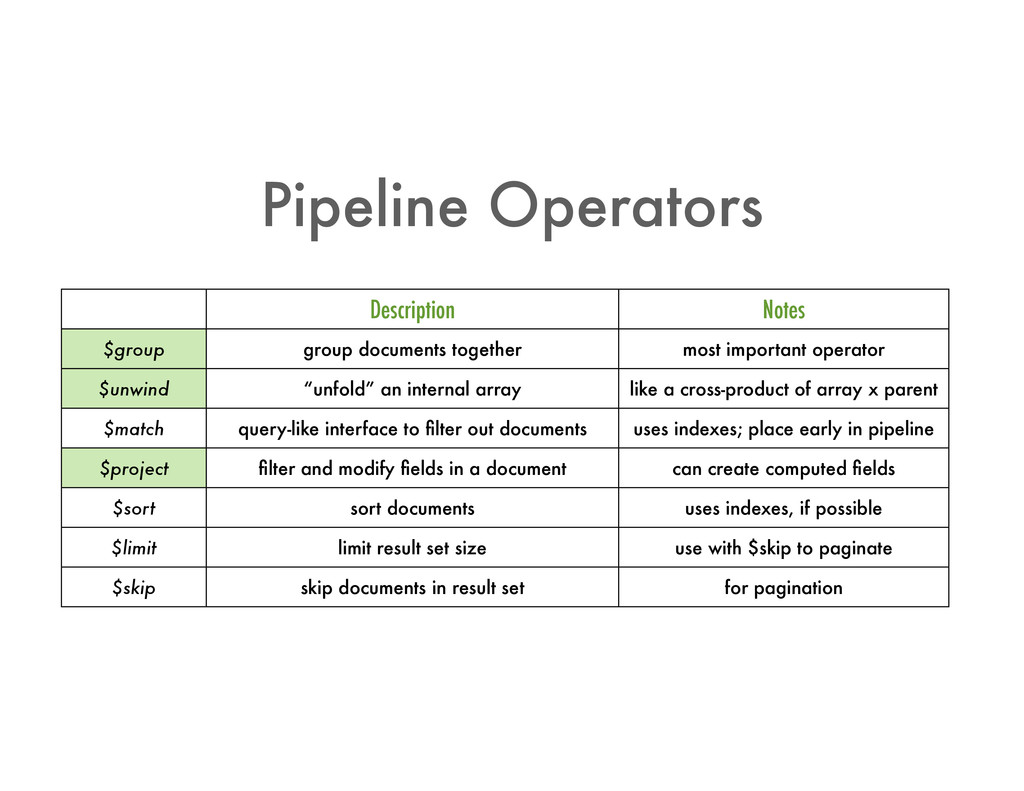
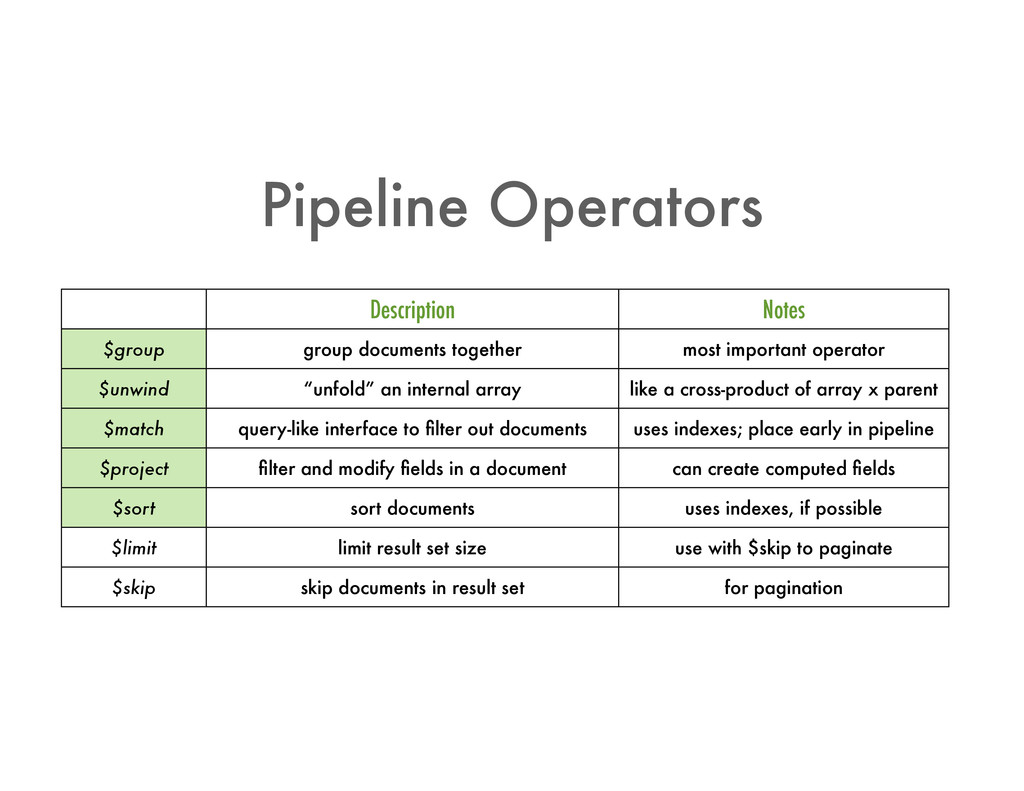
operator $unwind “unfold” an internal array like a cross-product of array x parent $match query-like interface to filter out documents uses indexes; place early in pipeline $project filter and modify fields in a document can create computed fields $sort sort documents uses indexes, if possible $limit limit result set size use with $skip to paginate $skip skip documents in result set for pagination
operator $unwind “unfold” an internal array like a cross-product of array x parent $match query-like interface to filter out documents uses indexes; place early in pipeline $project filter and modify fields in a document can create computed fields $sort sort documents uses indexes, if possible $limit limit result set size use with $skip to paginate $skip skip documents in result set for pagination
operator $unwind “unfold” an internal array like a cross-product of array x parent $match query-like interface to filter out documents uses indexes; place early in pipeline $project filter and modify fields in a document can create computed fields $sort sort documents uses indexes, if possible $limit limit result set size use with $skip to paginate $skip skip documents in result set for pagination
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}