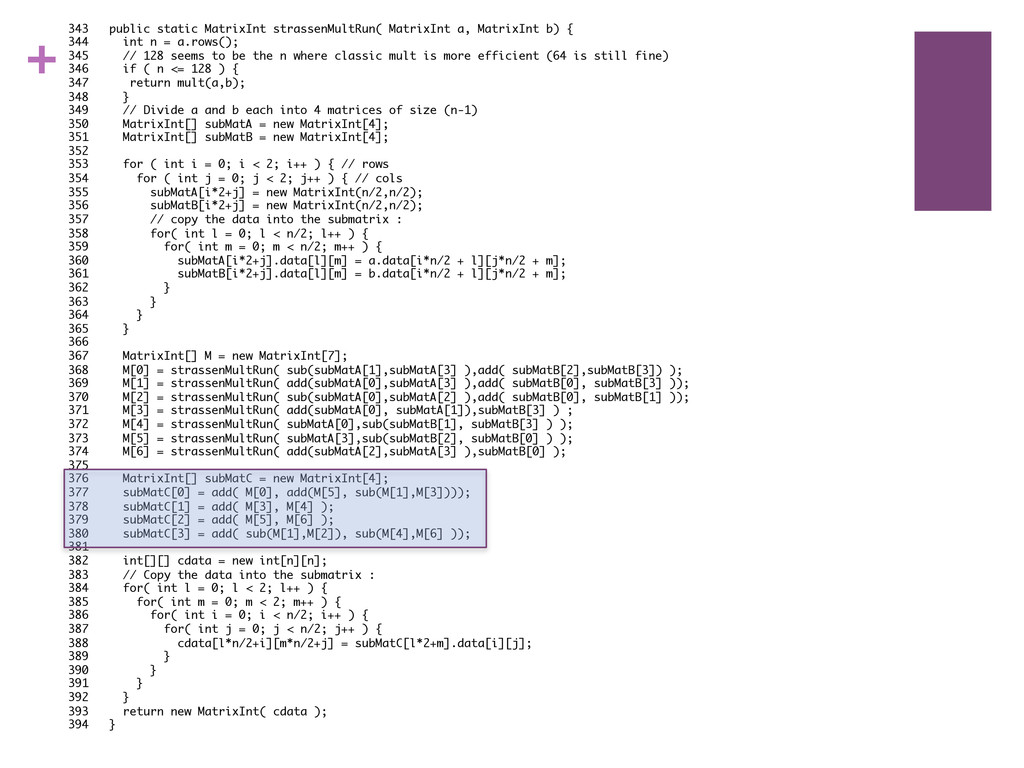
{ 344 int n = a.rows(); 345 // 128 seems to be the n where classic mult is more efficient (64 is still fine) 346 if ( n <= 128 ) { 347 return mult(a,b); 348 } 349 // Divide a and b each into 4 matrices of size (n-1) 350 MatrixInt[] subMatA = new MatrixInt[4]; 351 MatrixInt[] subMatB = new MatrixInt[4]; 352 353 for ( int i = 0; i < 2; i++ ) { // rows 354 for ( int j = 0; j < 2; j++ ) { // cols 355 subMatA[i*2+j] = new MatrixInt(n/2,n/2); 356 subMatB[i*2+j] = new MatrixInt(n/2,n/2); 357 // copy the data into the submatrix : 358 for( int l = 0; l < n/2; l++ ) { 359 for( int m = 0; m < n/2; m++ ) { 360 subMatA[i*2+j].data[l][m] = a.data[i*n/2 + l][j*n/2 + m]; 361 subMatB[i*2+j].data[l][m] = b.data[i*n/2 + l][j*n/2 + m]; 362 } 363 } 364 } 365 } 366 367 MatrixInt[] M = new MatrixInt[7]; 368 M[0] = strassenMultRun( sub(subMatA[1],subMatA[3] ),add( subMatB[2],subMatB[3]) ); 369 M[1] = strassenMultRun( add(subMatA[0],subMatA[3] ),add( subMatB[0], subMatB[3] )); 370 M[2] = strassenMultRun( sub(subMatA[0],subMatA[2] ),add( subMatB[0], subMatB[1] )); 371 M[3] = strassenMultRun( add(subMatA[0], subMatA[1]),subMatB[3] ) ; 372 M[4] = strassenMultRun( subMatA[0],sub(subMatB[1], subMatB[3] ) ); 373 M[5] = strassenMultRun( subMatA[3],sub(subMatB[2], subMatB[0] ) ); 374 M[6] = strassenMultRun( add(subMatA[2],subMatA[3] ),subMatB[0] ); 375 376 MatrixInt[] subMatC = new MatrixInt[4]; 377 subMatC[0] = add( M[0], add(M[5], sub(M[1],M[3]))); 378 subMatC[1] = add( M[3], M[4] ); 379 subMatC[2] = add( M[5], M[6] ); 380 subMatC[3] = add( sub(M[1],M[2]), sub(M[4],M[6] )); 381 382 int[][] cdata = new int[n][n]; 383 // Copy the data into the submatrix : 384 for( int l = 0; l < 2; l++ ) { 385 for( int m = 0; m < 2; m++ ) { 386 for( int i = 0; i < n/2; i++ ) { 387 for( int j = 0; j < n/2; j++ ) { 388 cdata[l*n/2+i][m*n/2+j] = subMatC[l*2+m].data[i][j]; 389 } 390 } 391 } 392 } 393 return new MatrixInt( cdata ); 394 }
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![187 final int STEPS = 7; 188 final MatrixInt[] M](https://files.speakerdeck.com/presentations/4e8154892ad8180060001140/slide_8.jpg){kind=link}
{kind=link}
![230 final int SUB_STEPS = 3; 231 final MatrixInt[] subMatC](https://files.speakerdeck.com/presentations/4e8154892ad8180060001140/slide_10.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
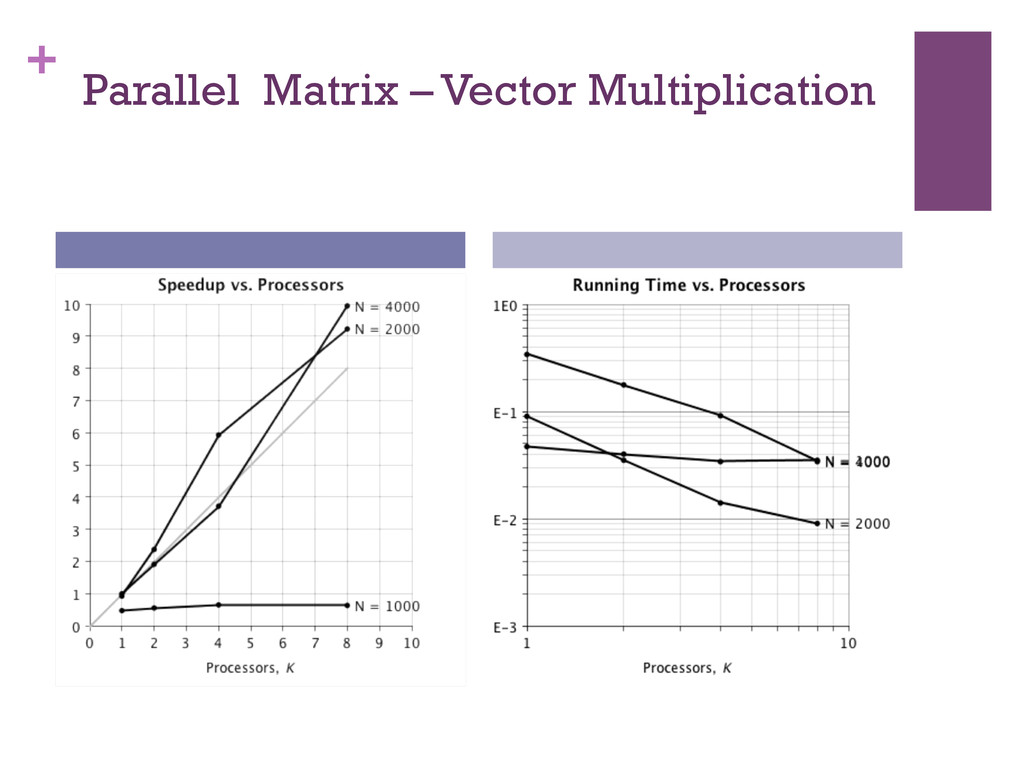{kind=link}
{kind=link}
{kind=link}
{kind=link}
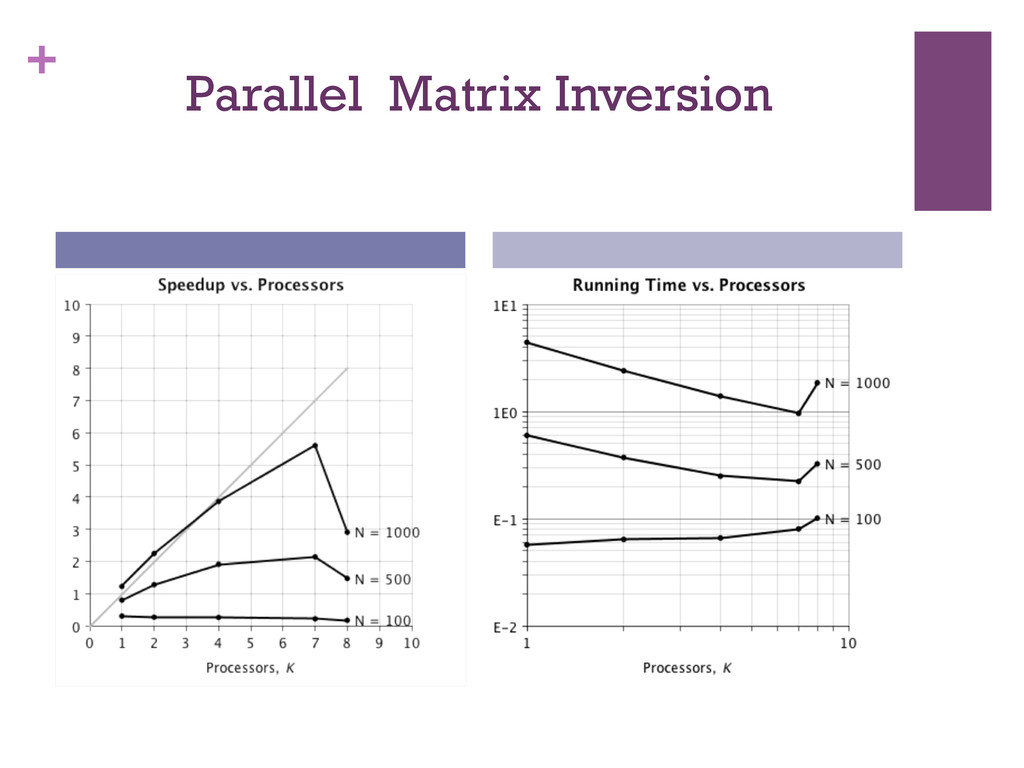{kind=link}
{kind=link}