Introduces users to Apache Flume and how it can be used to aggregate data from hundreds or thousands of servers to a centralized data store such as ElasticSearch, Apache Solr or HDFS.
It then introduces the users to visualization concepts with the data retrieved from the centralized datastore.
{kind=link}
![(650) 318-‐1195 * [email protected] • Father, Husband, Son and](https://files.speakerdeck.com/presentations/e5317470a1eb013092ef0af45ce6d40d/slide_1.jpg){kind=link}
{kind=link}
{kind=link}
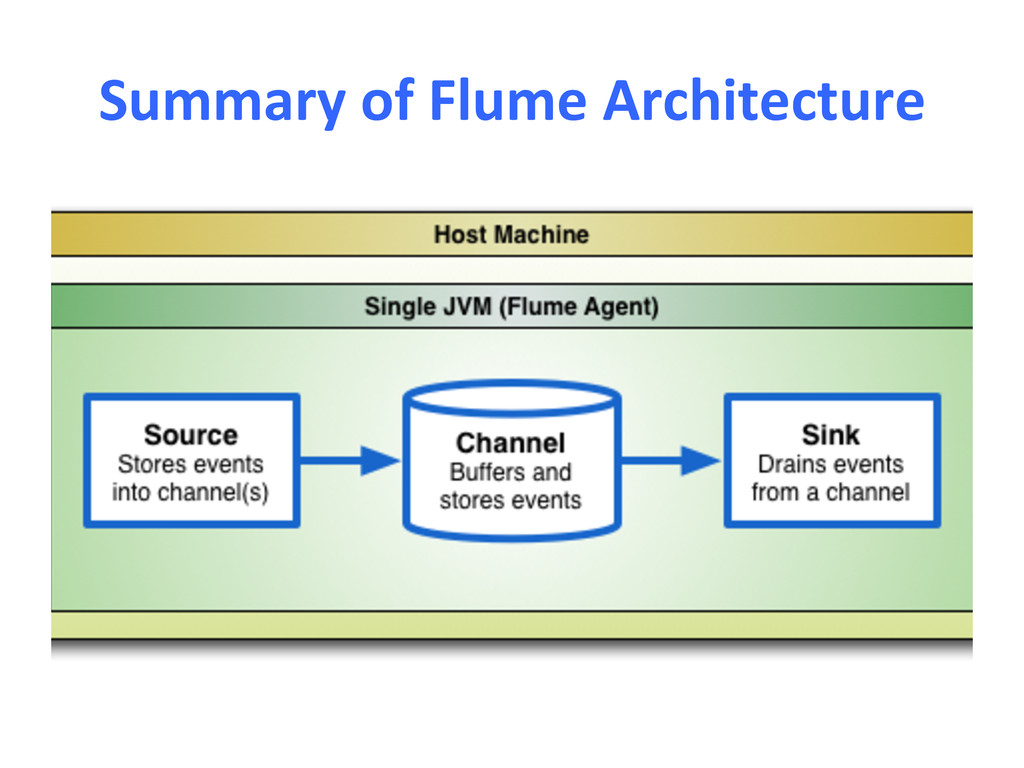{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
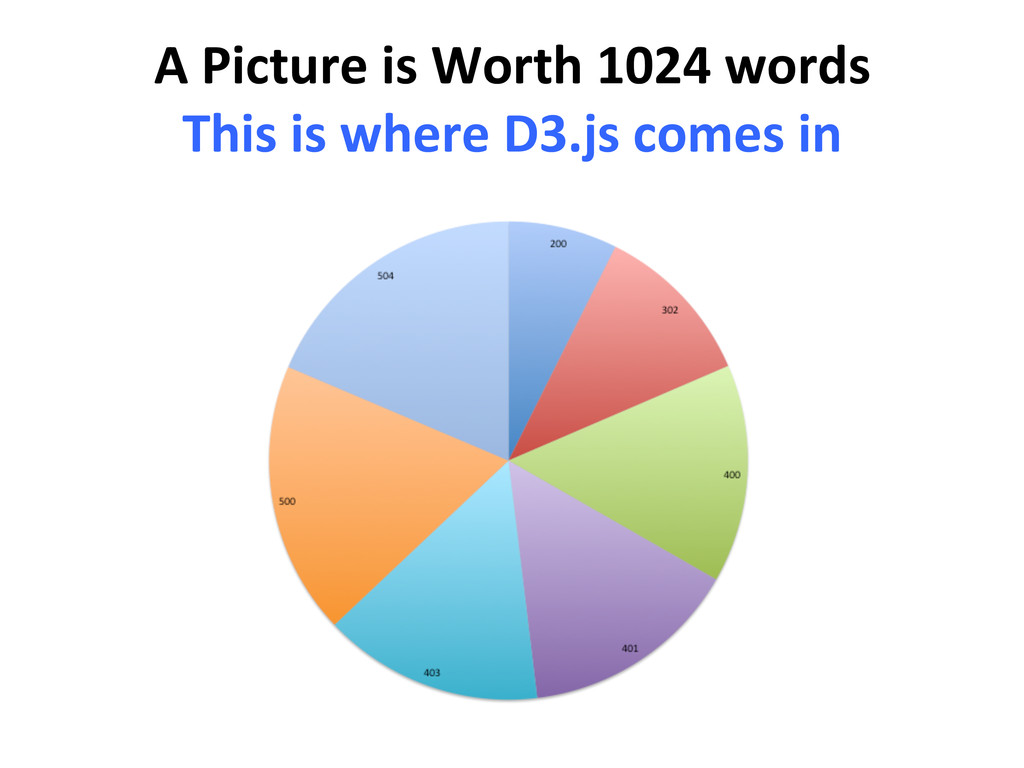{kind=link}
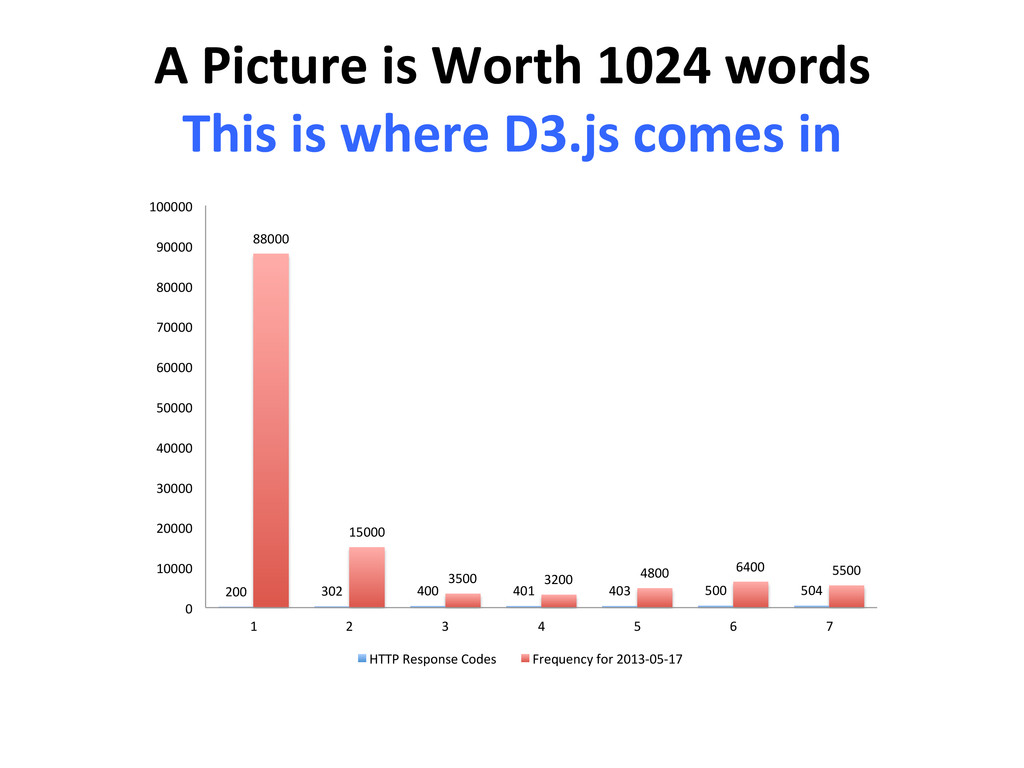{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}