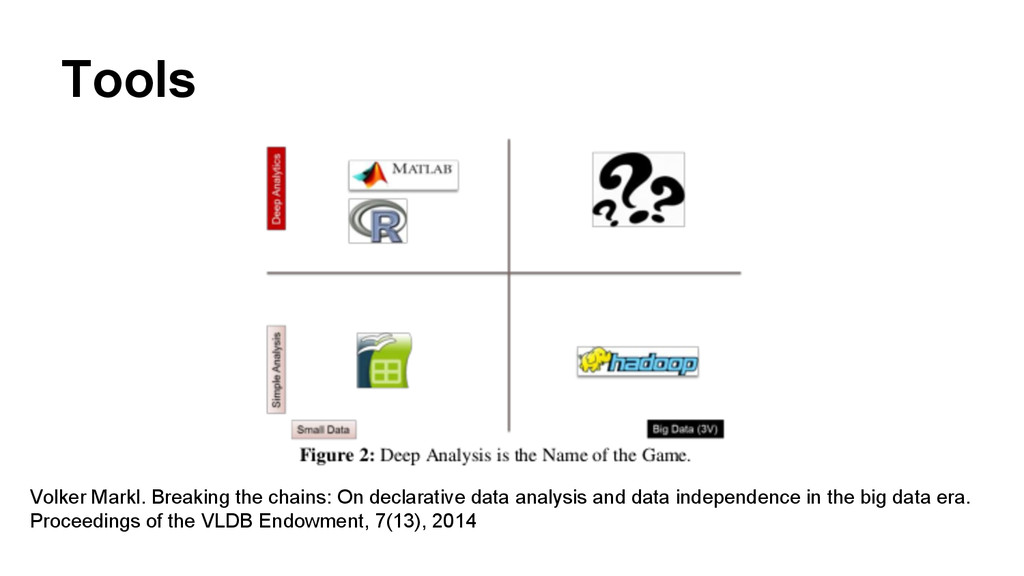
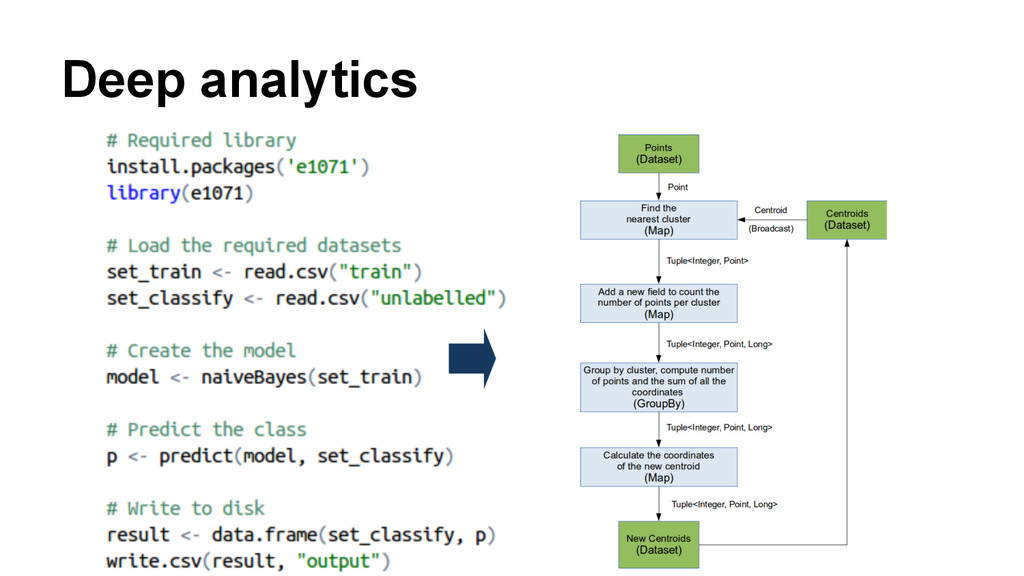
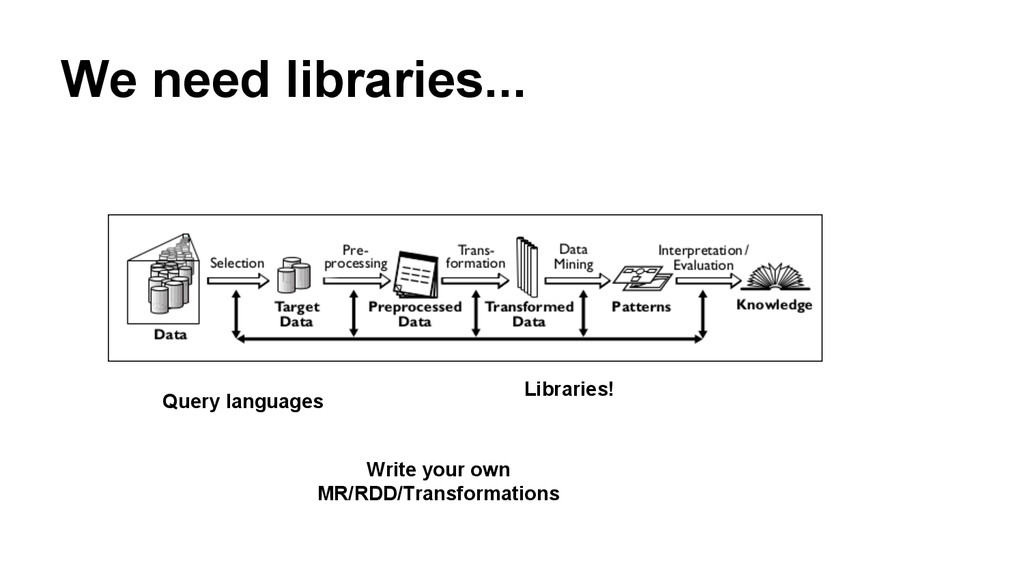
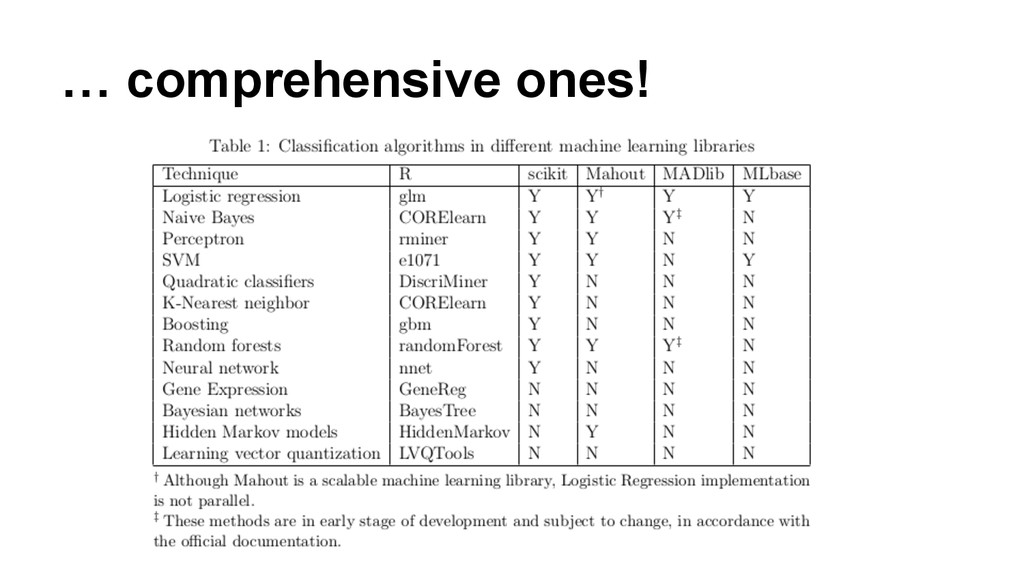
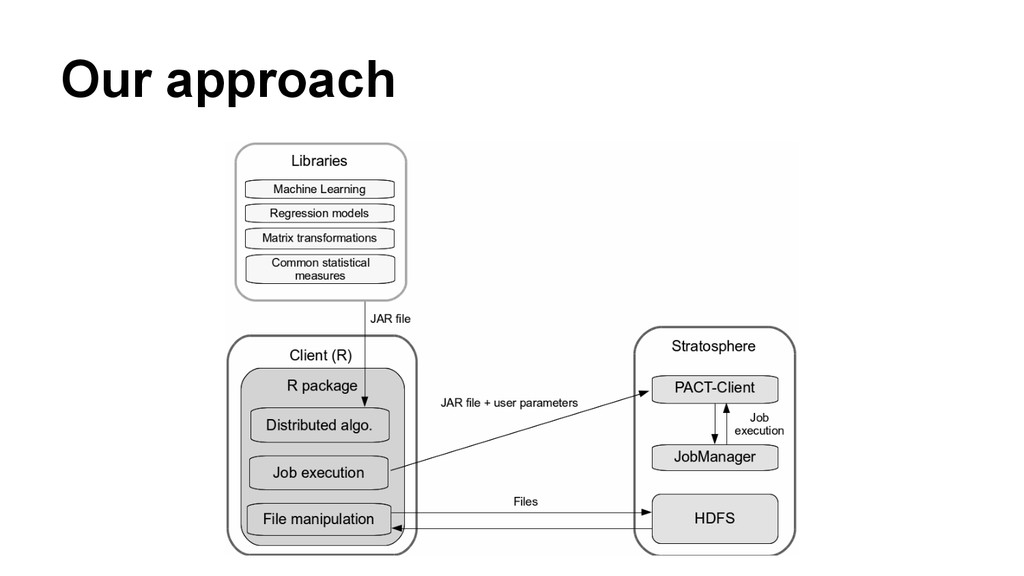
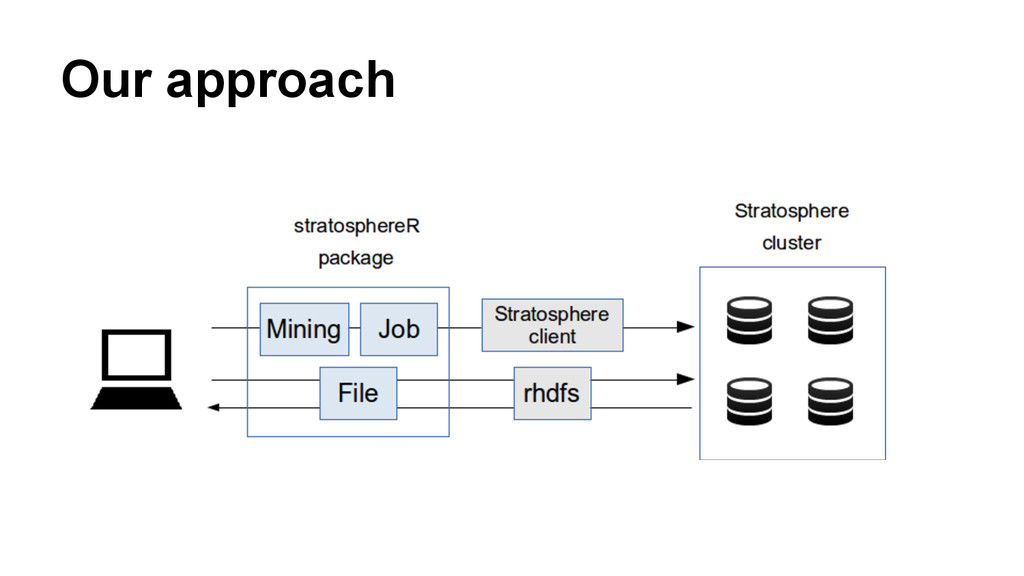
In this talk, we will discuss our approach to bring large scale deep analytics to the masses. R is an extremely popular numerical computer environment, but scientific data processing frequently hits its memory limits. On the other hand, system to execute data intensive tasks like Hadoop or Stratosphere are not popular among R users because writing programs using these paradigms is cumbersome. We present an innovative approach to overcome these limitations using the Stratosphere/Apache Flink big data platform by means of a R package and ready-to-use distributed algorithm.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
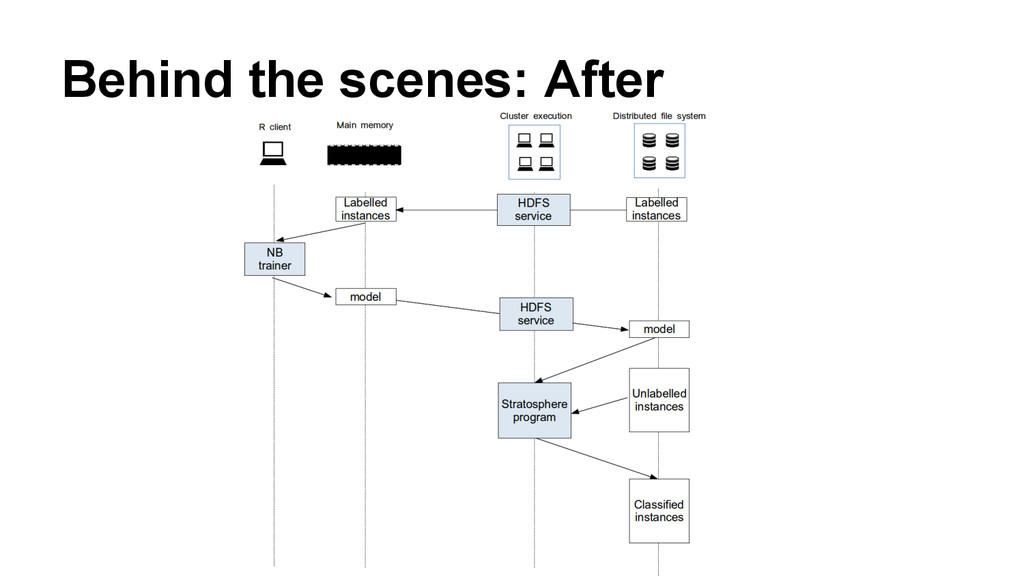{kind=link}
{kind=link}
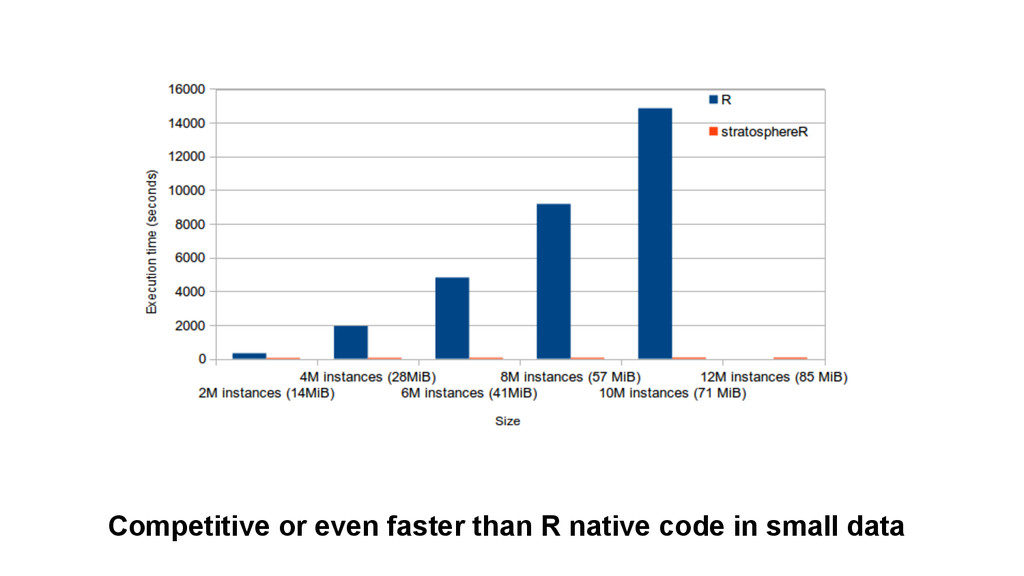{kind=link}
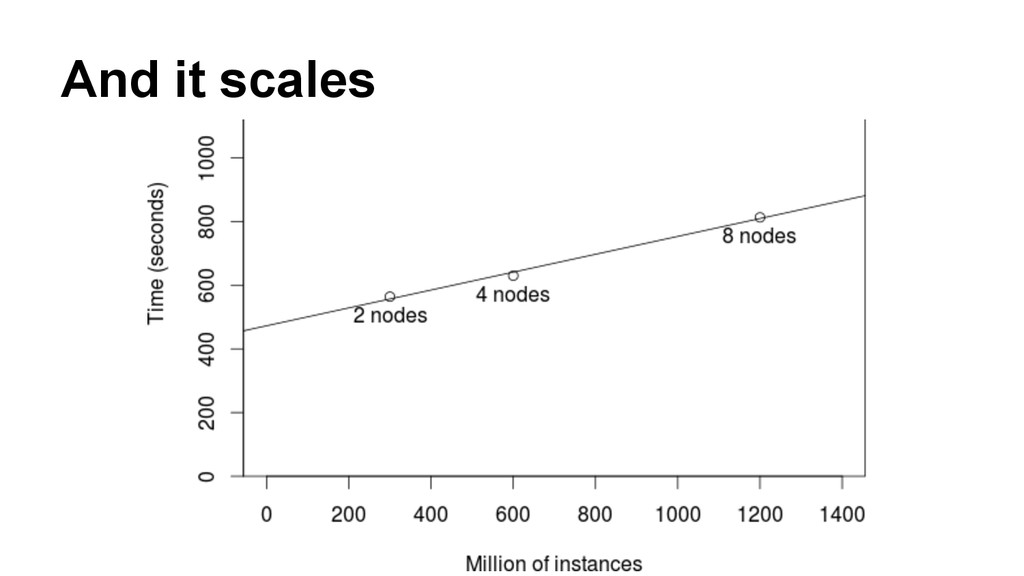{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}